<기초 프로젝트>
00. 데이터 마운트
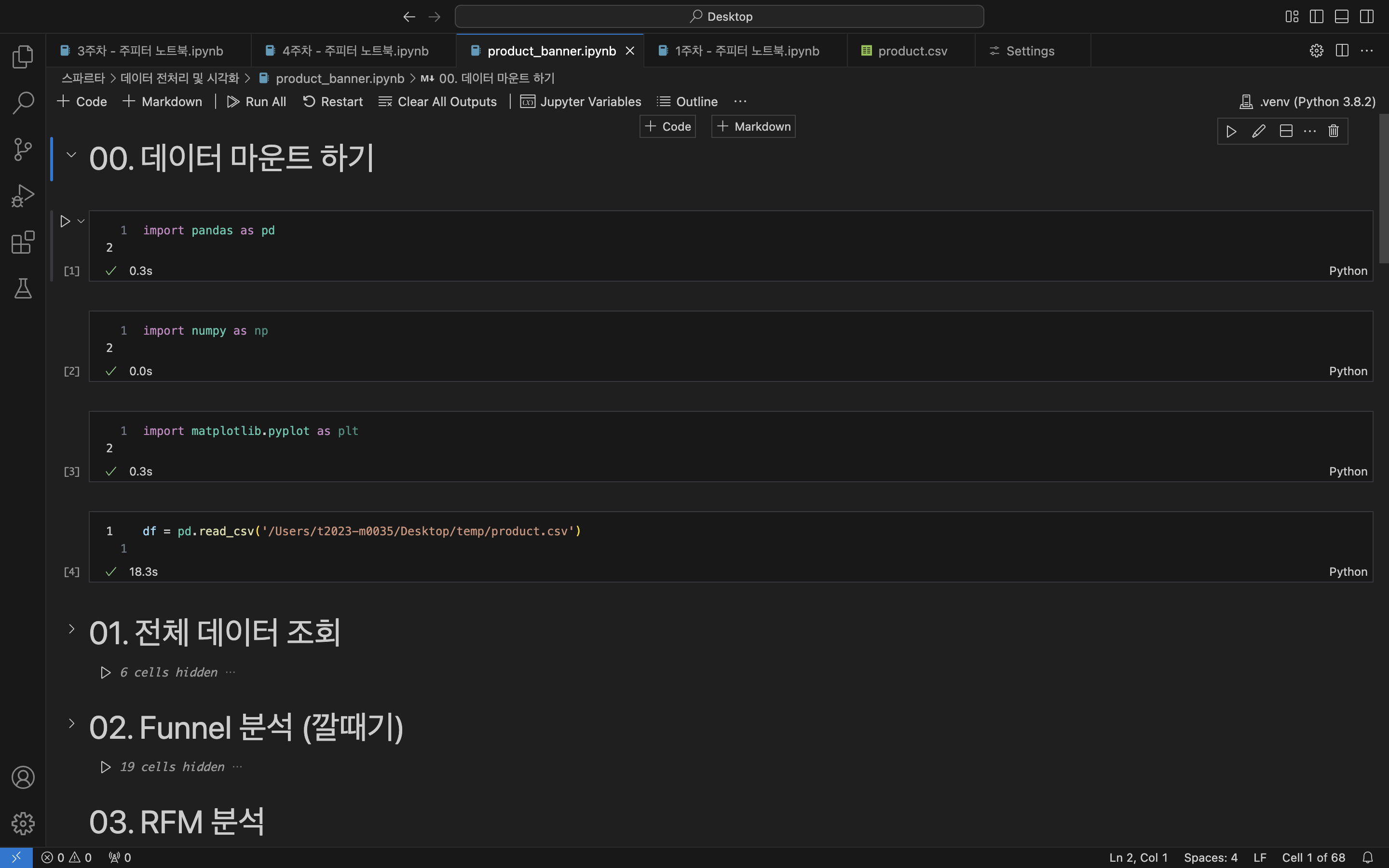
- 데이터 마운트 필요한 기초 코드
# 파이썬, 시각화 드라이버 가져오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# csv 데이터 읽어오기 (product.csv)
df = pd.read_csv('File Path')잘 실행돼었다고 뜨면 데이터가 들어간것❗
01. 전체 데이터 조회
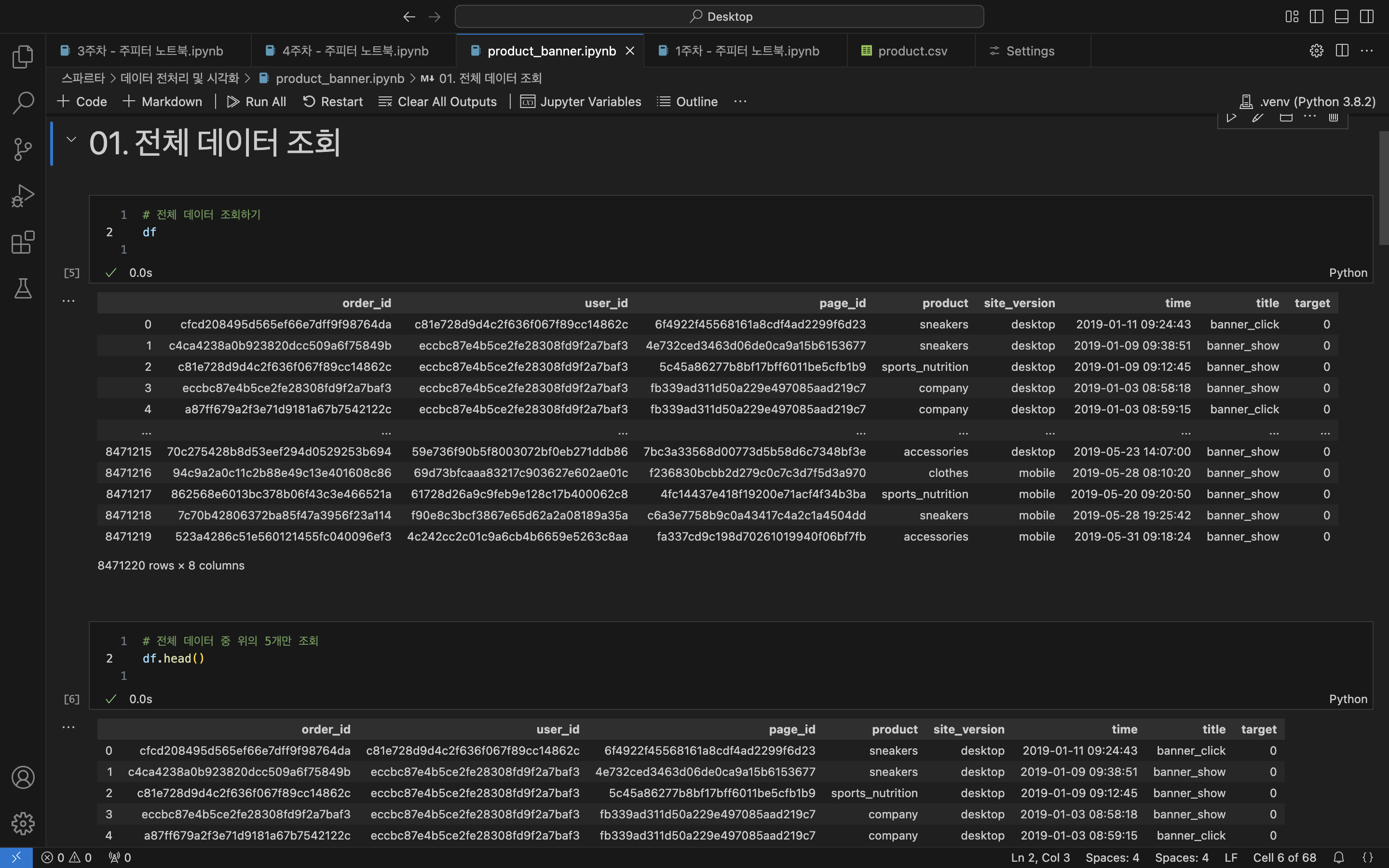
- 기본 데이터 조회
# 어떤 데이터가 들어가 있는걸까?
df # 전체 데이터 조회
/* (id들은 너무 길어서 데이터 앞 5글자로 축약!!)
ordr_id user_id page_id product site_version time title target|
0 cfcd2 c81e7 6f492 sneakers desktop 2019-01-11 09:24:43 banner_click 0
1 c4ca4 eccbc 4e732 sneakers desktop 2019-01-09 09:38:51 banner_show 0
2 c81e7 eccbc 5c45a sports_nutrition desktop 2019-01-09 09:12:45 banner_show 0
3 eccbc eccbc fb339 company desktop 2019-01-03 08:58:18 banner_show 0
4 a87ff eccbc fb339 company desktop 2019-01-03 08:59:15 banner_click 0
... ... ... ... ... ... ... ... ...
8471220 rows * 8 columns
*/
# 너무 많다!! 앞 5개만 보고 싶어ㅠㅠ
df.head() # 전체 데이터 첫 5행만 조회
/* (id들은 너무 길어서 데이터 앞 5글자로 축약!!)
ordr_id user_id page_id product site_version time title target|
0 cfcd2 c81e7 6f492 sneakers desktop 2019-01-11 09:24:43 banner_click 0
1 c4ca4 eccbc 4e732 sneakers desktop 2019-01-09 09:38:51 banner_show 0
2 c81e7 eccbc 5c45a sports_nutrition desktop 2019-01-09 09:12:45 banner_show 0
3 eccbc eccbc fb339 company desktop 2019-01-03 08:58:18 banner_show 0
4 a87ff eccbc fb339 company desktop 2019-01-03 08:59:15 banner_click 0
*/
# 표 말고 그냥 전체가 몇개로 구성되어있는지 알고 싶어!
df.shape # 전체 데이터의 형태 조회
-- (8471220, 8) # 8,471,220 행, 8 열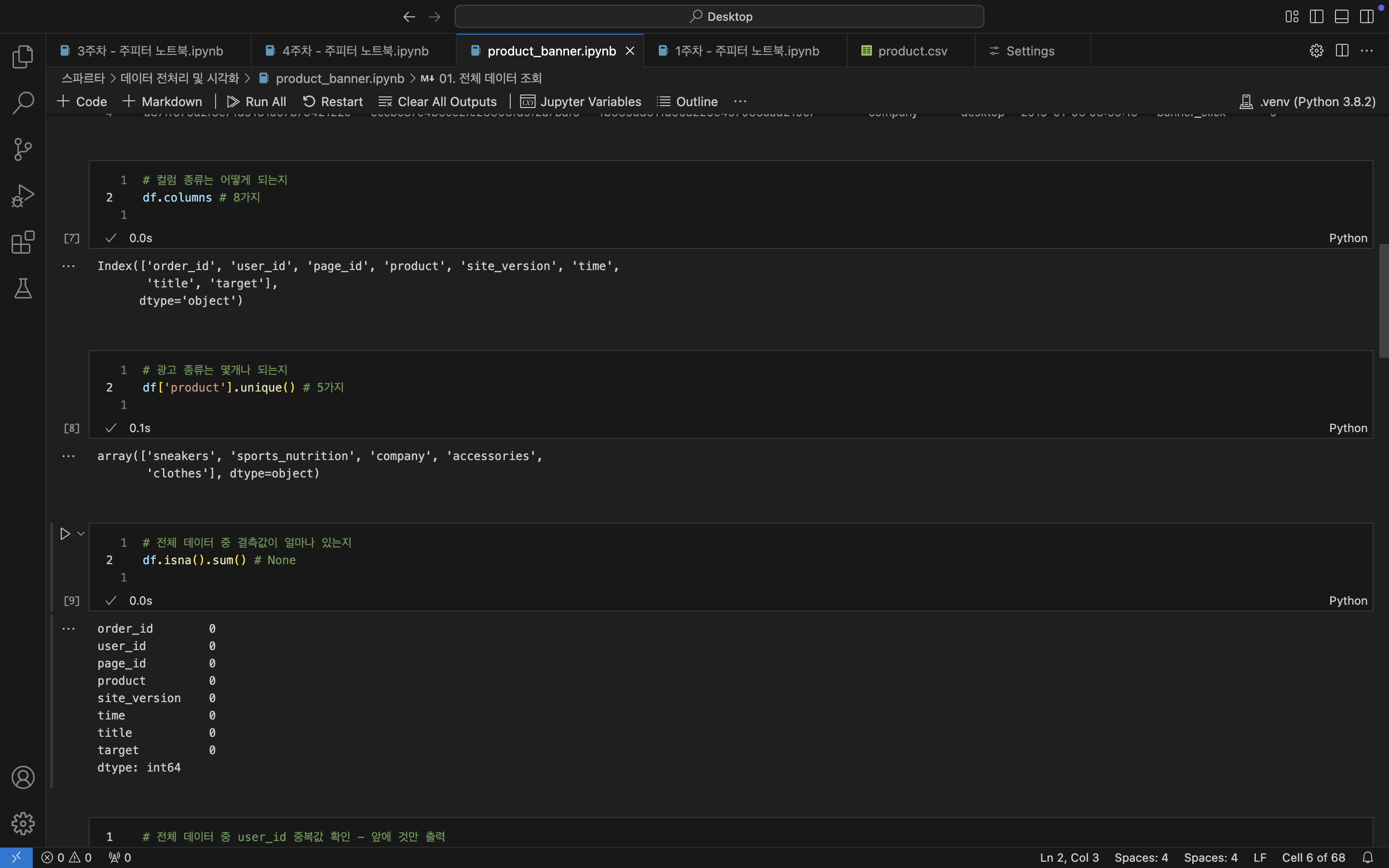
- DataFrame 뜯어보기
# 그럼 8 열의 이름들은 뭘까??
df.columns # 컬럼 종류 조회
/* 8가지 컬럼명
Index(['order_id', 'user_id', 'page_id', 'product', 'site_version', 'time',
'title', 'target'],
dtype='object')
*/
# product의 종류가 배너 광고에서 중요하지 않을까?
df.['product'].unique() # product 컬럼의 데이터 값 조회
/* 5가지 종류의 데이터
array(['sneakers', 'sports_nutrition', 'company', 'accessories',
'clothes'], dtype=object)
*/
# 혹시 비어있는 데이터는 없나??
df.isna().sum() # 전체 데이터 중 결측치 합계
/* 결측치 0개
order_id 0
user_id 0
page_id 0
product 0
site_version 0
time 0
title 0
target 0
dtype: int64
*/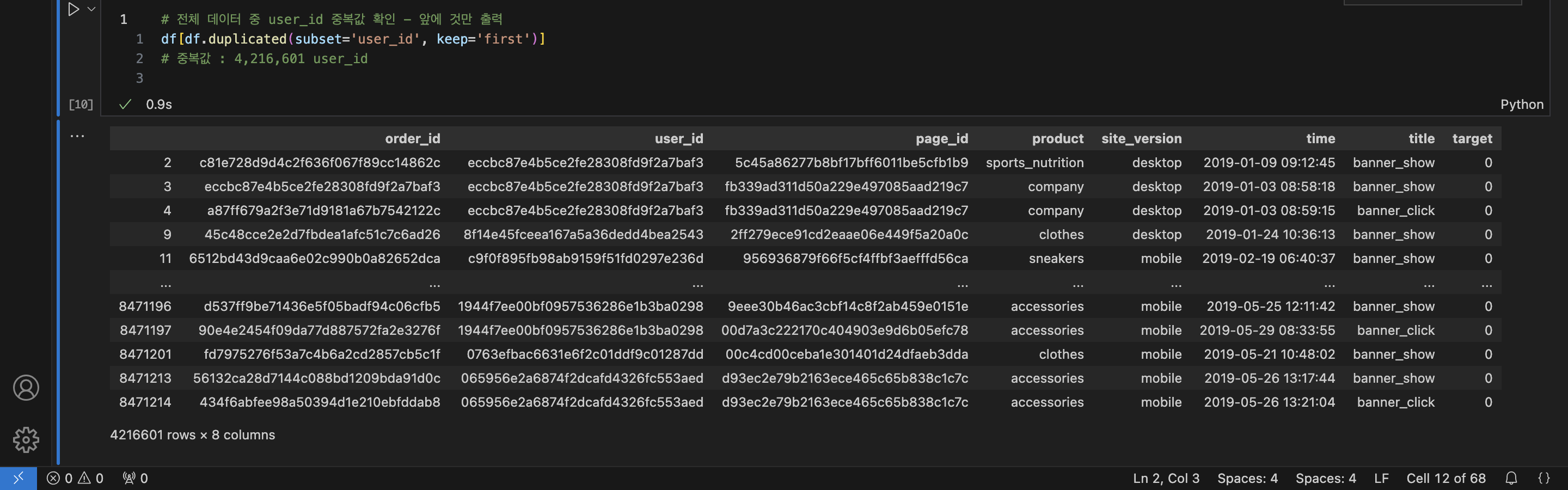
user_id기준 중복값 확인
# 근데 한사람이 여러개의 배너를 보지 않을까?? 중복값이 있다면 먼저 나오는 것만 보고 싶어!
df[df.duplicated(subset='user_id', keep='first'] # user_id 기준 중복값 중 첫번째만 보여주기
/* 4,216,601 개의 user_id가 중복됨
order_id user_id page_id product site_version time title target
2 c81e7 eccbc 5c45a sports_nutrition desktop 2019-01-09 09:12:45 banner_show 0
3 eccbc eccbc fb339 company desktop 2019-01-03 08:58:18 banner_show 0
4 a87ff eccbc fb339 company desktop 2019-01-03 08:59:15 banner_click 0
9 45c48 8f14e 2ff27 clothes desktop 2019-01-24 10:36:13 banner_show 0
11 6512b c9f0f 95693 sneakers mobile 2019-02-19 06:40:37 banner_show 0
... ... ... ... ... ... ... ... ...
4216601 rows × 8 columns
*/❗전체 데이터를 조회하여 알 수 있는 것❗
df: 총 8,471,220 개의 데이터와 8 columns 들로 이루어져 있음
-> 결측치는 없음
8가지컬럼명, 광고5가지분류를 알 수 있음
총8,471,220데이터 중에서4,216,601개의 고객 아이디가 중복 되어있음
02. 퍼널 분석
- 카테고리별로 분류
# 전체 데이터가 바뀌진 않았는지 항상 확인
df.shape -- 이하 결과 생략
# 제품별로 묶으면 몇개의 데이터가 있을까?
product_group = df.groupby('product')['user_id'].count() # 제품별 그룹화 해서 조회
product_group
/*
product
accessories 1621759
clothes 1786438
company 1725056
sneakers 1703342
sports_nutrition 1634625
Name: user_id, dtype: int64
*/
- 세부 단계 분류
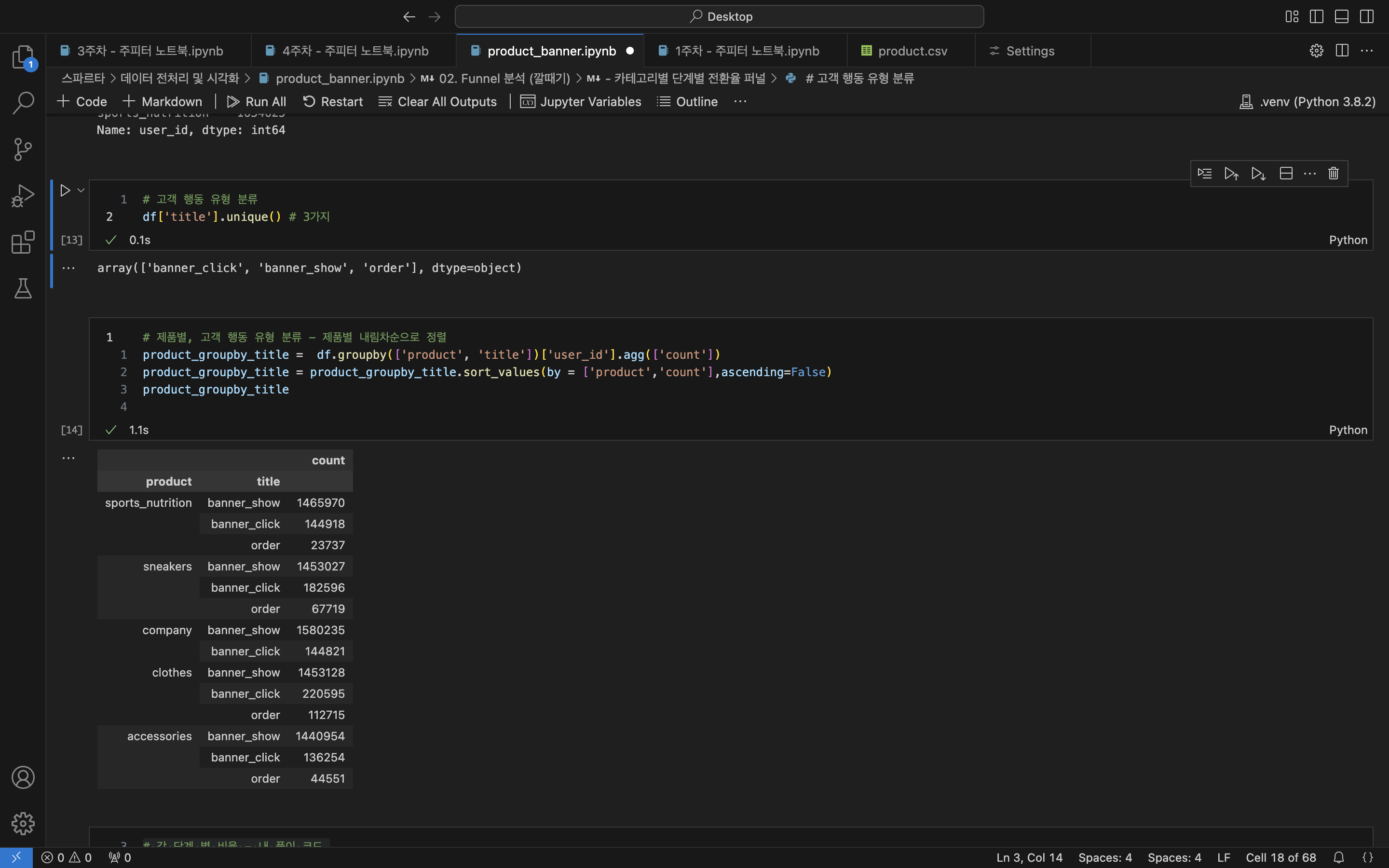
# 제품별도 좋지만 고객들이 배너광고를 통해 어디까지 행동했는지 알고 싶어!
df['title'].unique() # 행동 유형 분류
/* 고객 행동 3가지로 구분
array(['banner_click', 'banner_show', 'order'], dtype=object)
*/
# 제품별 고객 행동별 2가지 기준으로 집계된 데이터를 보고 싶어
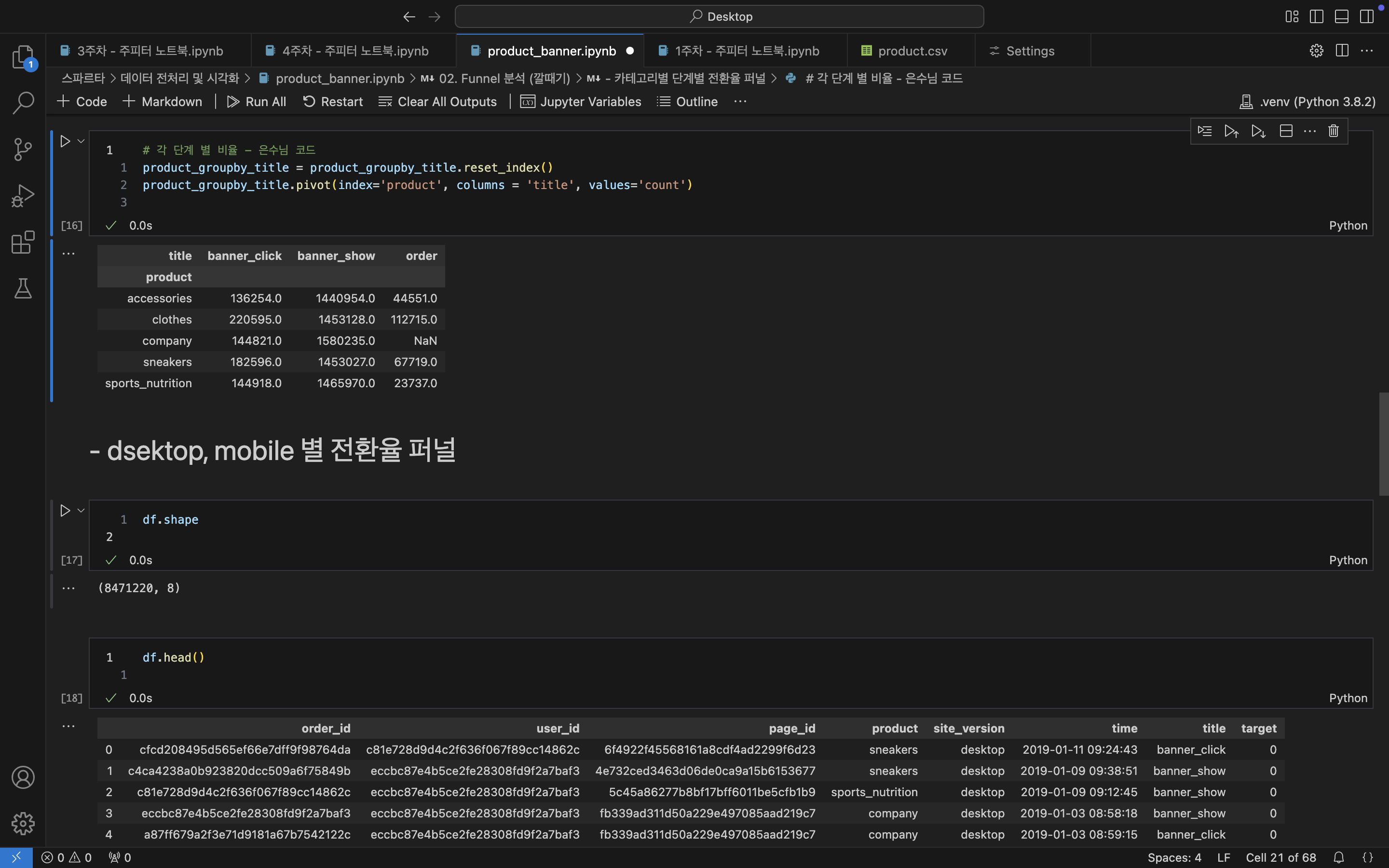
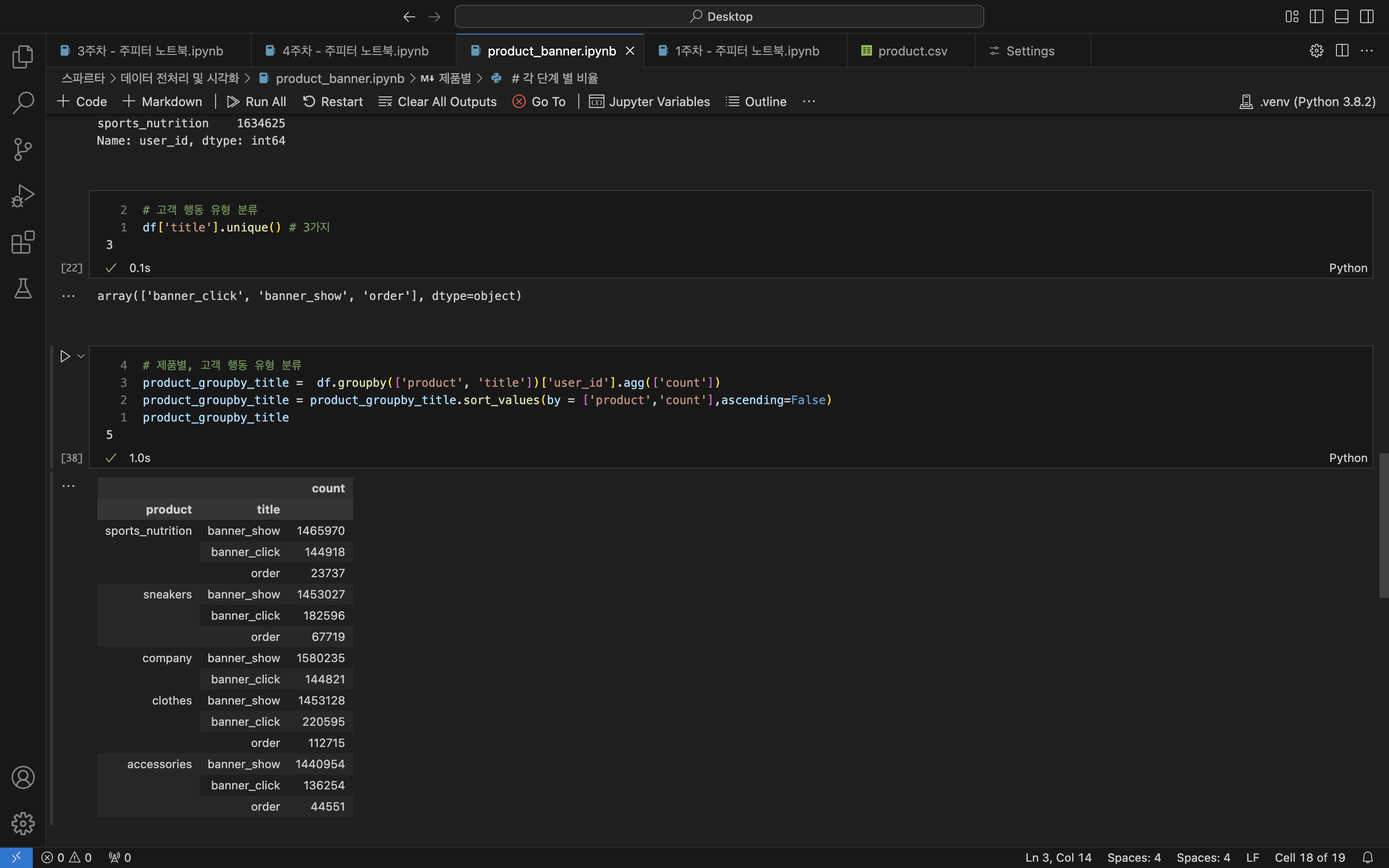
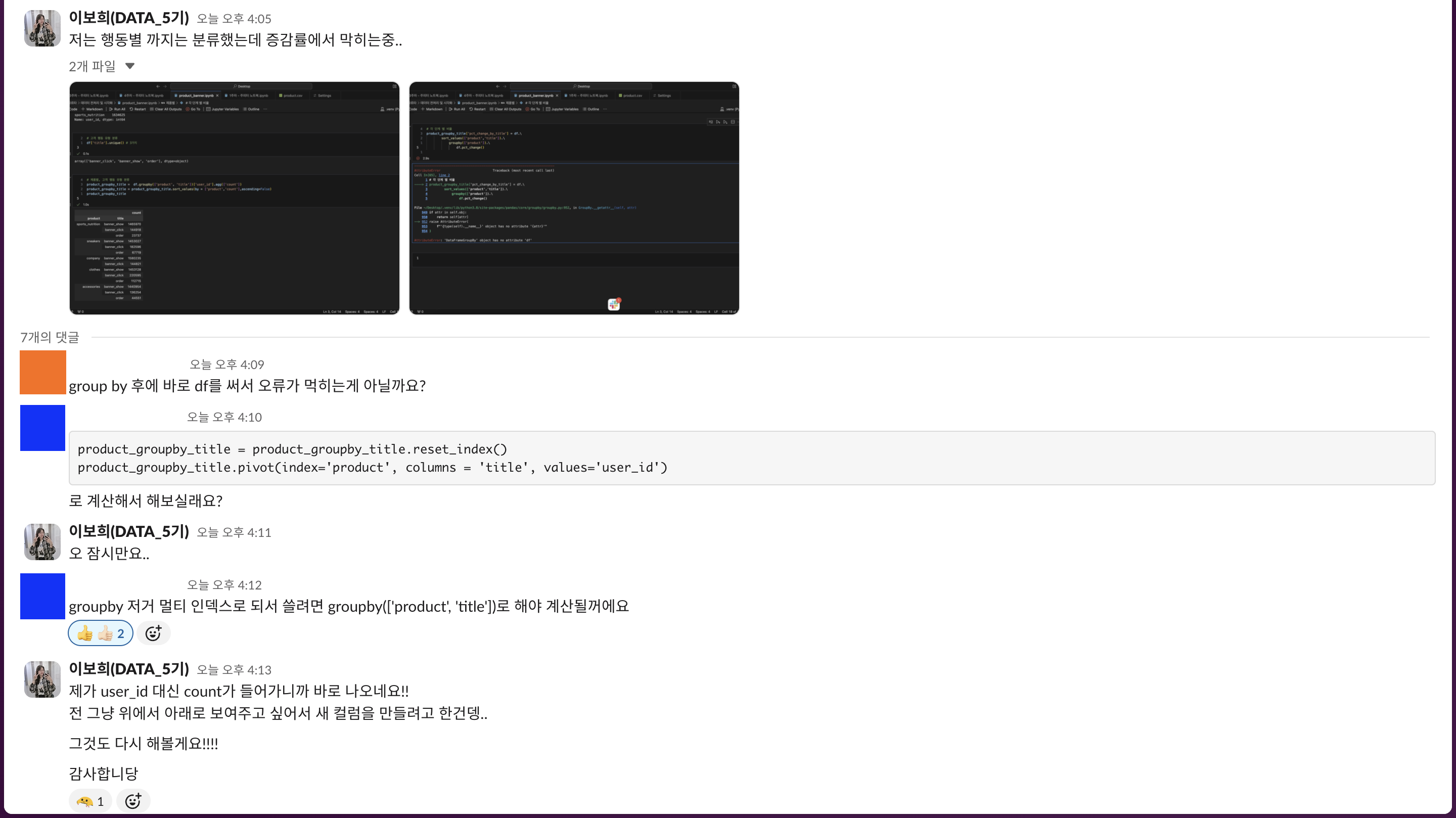
# 제품별, 고객 행동 유형 분류 - 제품별 내림차순으로 정렬
product_groupby_title = df.groupby(['product', 'title'])['user_id'].agg(['count'])
product_groupby_title = product_groupby_title.sort_values(by = ['product','count'],ascending=False)
product_groupby_title
/*
product title count
---------------------------------------------
sports_nutrition banner_show 1465970
banner_click 144918
order 23737
---------------------------------------------
sneakers banner_show 1453027
banner_click 182596
order 67719
---------------------------------------------
company banner_show 1580235
banner_click 144821
---------------------------------------------
clothes banner_show 1453128
banner_click 220595
order 112715
---------------------------------------------
accessories banner_show 1440954
banner_click 136254
order 44551
*/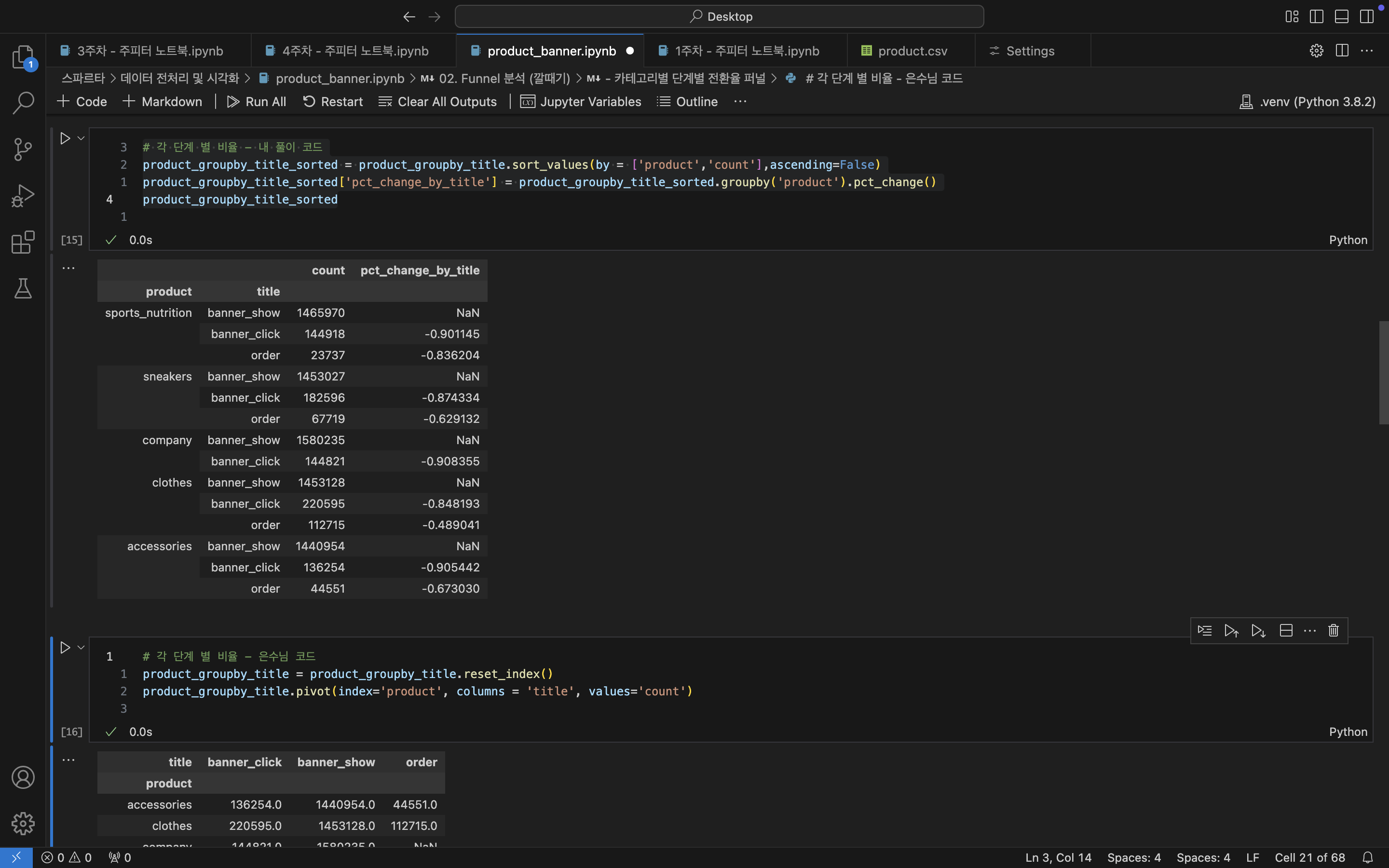
- 카테고리 고객 행동단계별 증감률
# 배너 광고 노출에서 주문까지 얼마나 줄어드나 알고 싶어
# 각 단계 별 비율 - 내 풀이 코드
product_groupby_title_sorted = product_groupby_title.sort_values(by = ['product','count'],\
ascending=False)
product_groupby_title_sorted['pct_change_by_title'] = product_groupby_title_sorted\
.groupby('product').pct_change()
product_groupby_title_sorted
/*
product title count pct_change_by_title
--------------------------------------------------------------------
sports_nutrition banner_show 1465970 NaN
banner_click 144918 -0.901145
order 23737 -0.836204
--------------------------------------------------------------------
sneakers banner_show 1453027 NaN
banner_click 182596 -0.874334
order 67719 -0.629132
--------------------------------------------------------------------
company banner_show 1580235 NaN
banner_click 144821 -0.908355
--------------------------------------------------------------------
clothes banner_show 1453128 NaN
banner_click 220595 -0.848193
order 112715 -0.489041
--------------------------------------------------------------------
accessories banner_show 1440954 NaN
banner_click 136254 -0.905442
order 44551 -0.673030
*/
- 사이트 별로 나눠보기 전에 혹시 데이터가 바뀌진 않았는지 확인해보자
# 전체 데이터 조회
df.shape
df.head()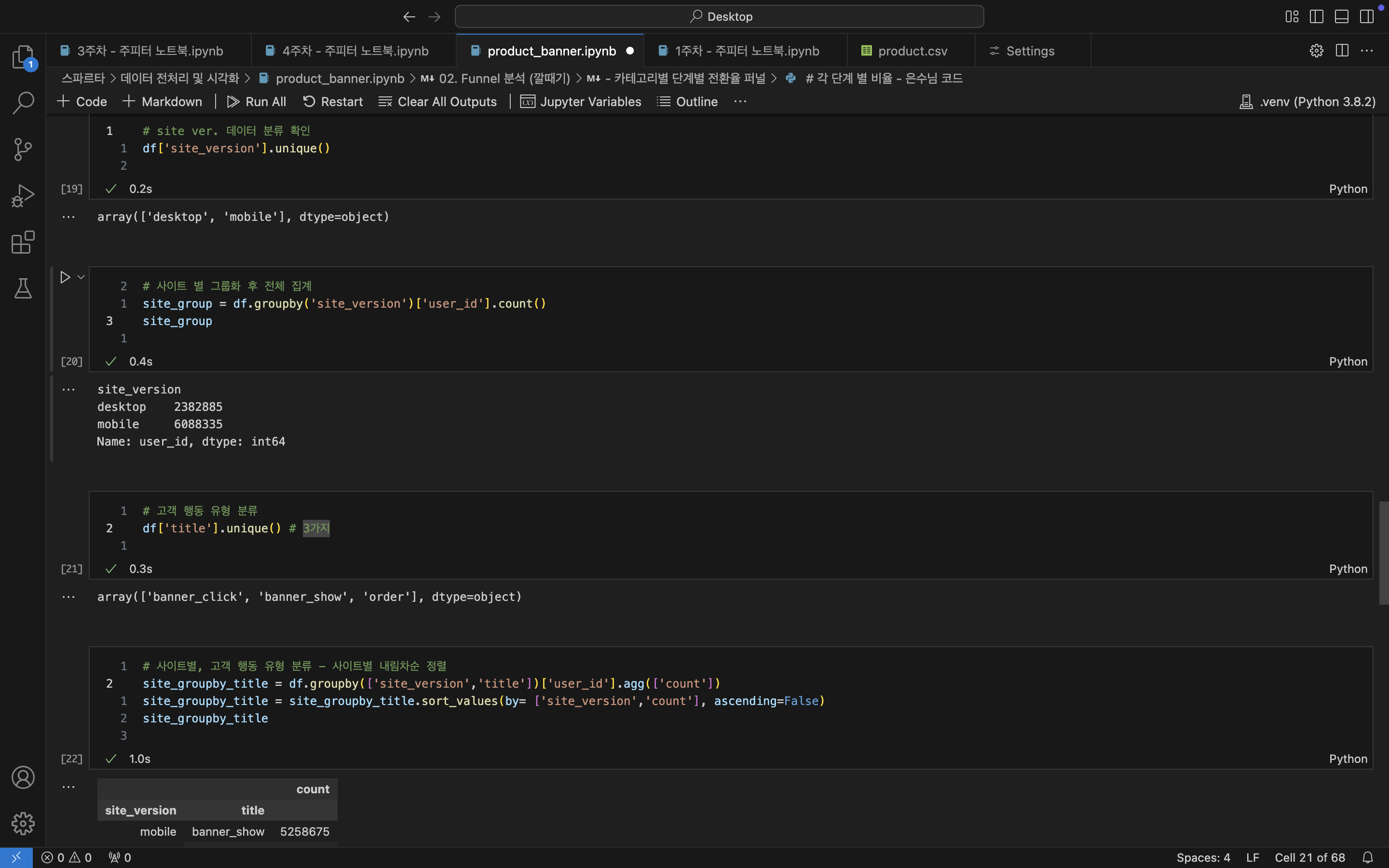
- 사이트를 종류별로 나눠보는건 어떨까?
# site ver. 데이터 분류 확인
df['site_version'].unique()
-- array(['desktop', 'mobile'], dtype=object)
# 사이트 별로 나눠보자
site_group = df.groupby('site_version')['user_id'].count()
site_group
site_version
/*
desktop 2382885
mobile 6088335
Name: user_id, dtype: int64
*/
# 고객 행동 유형 분류는 몇가지 일까?
df['title'].unique() # 3가지 (결과 생략)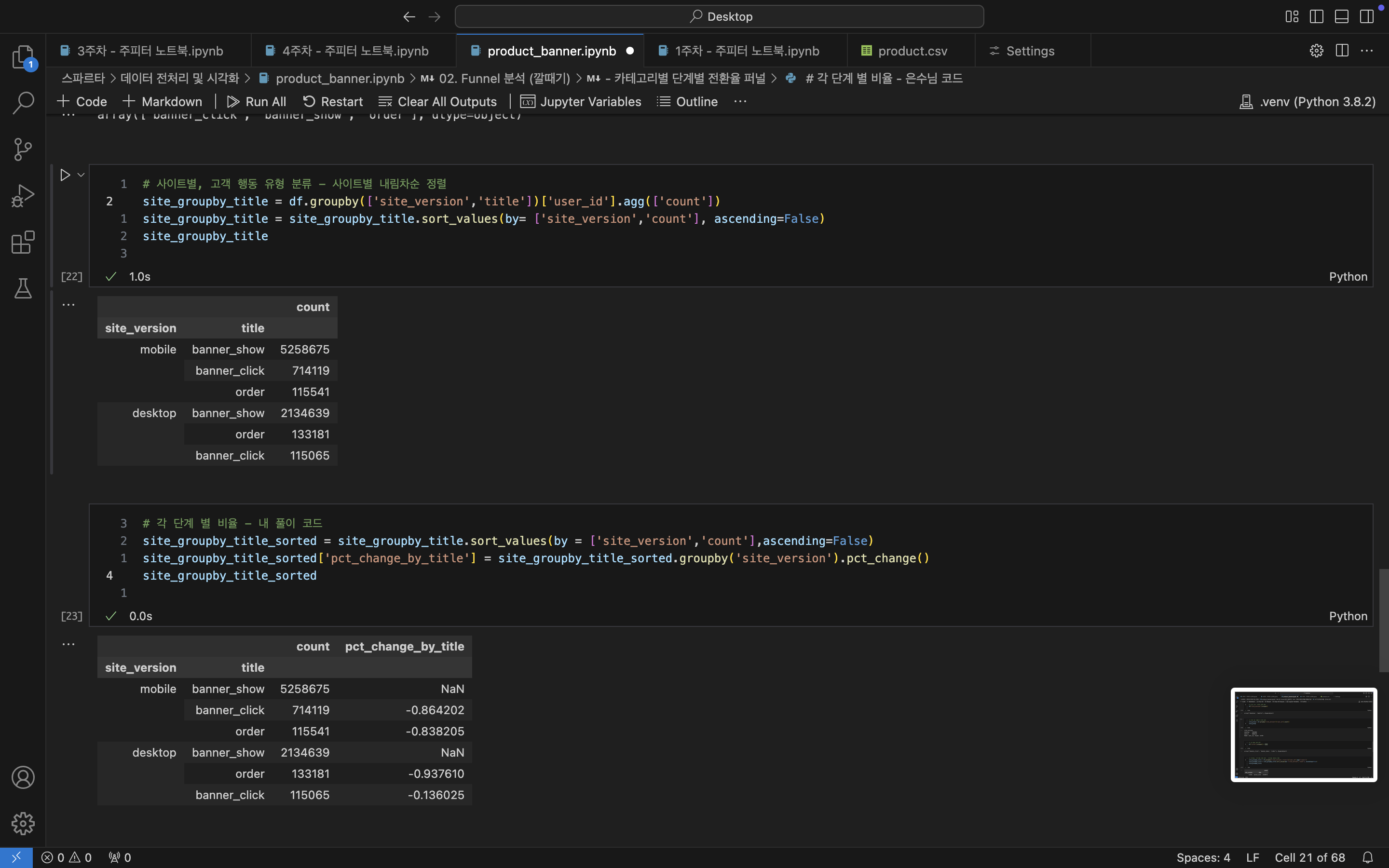
- 사이트별 고객 행동 유형별로 나눠서 증감률을 알아보자!!
아.. 지금 보니 site_groupby_title에서 'title'의 순서가 잘못된걸 발견했다!! 그래서 site_groupby_title_sorted도 증감률이 잘못계산된듯 하다. 메모해놓고 추후에 고쳐야 하겠다.
# 사이트별, 고객 행동 유형별로 나눠보자 - 대신 사이트별 내림차순으로 정렬하고 싶어!!
site_groupby_title = df.groupby(['site_version','title'])['user_id'].agg(['count'])
site_groupby_title = site_groupby_title.sort_values(by= ['site_version','count'], \
ascending=False)
site_groupby_title
/* # sorted 기준을 count의 내림차순으로 해서 잘못된 결과가 나왔다
🛑부분이 틀린 것
site_version title count
------------------------------------------
mobile banner_show 5258675
banner_click 714119
order 115541
------------------------------------------
desktop banner_show 2134639
🛑 order 133181
🛑 banner_click 115065
*/
# 각 단계 별 비율 - 내 풀이 코드
site_groupby_title_sorted = site_groupby_title.sort_values(by =['site_version','count']\
,ascending=False)
site_groupby_title_sorted['pct_change_by_title'] \
= site_groupby_title_sorted.groupby('site_version').pct_change()
site_groupby_title_sorted
/* # sorted 기준을 count의 내림차순으로 해서 잘못된 결과가 나왔다
🛑부분이 틀린 것
site_version title count pct_change_by_title
-----------------------------------------------------------------
mobile banner_show 5258675 NaN
banner_click 714119 -0.864202
order 115541 -0.838205
-----------------------------------------------------------------
desktop banner_show 2134639 NaN
🛑 order 133181 -0.937610
🛑 banner_click 115065 -0.136025
*/제품별 고객행동 단계별 증감률 / 사이트별 증감률을 알 수 있음!!
🛑가장 큰 오류해결
- '제품별 고객 행동 단계별 집계' 까지는 문제 없이 잘했음
- 그런데?
AttributeError: 'DataFrameGroupBy' object has no attribute 'df'
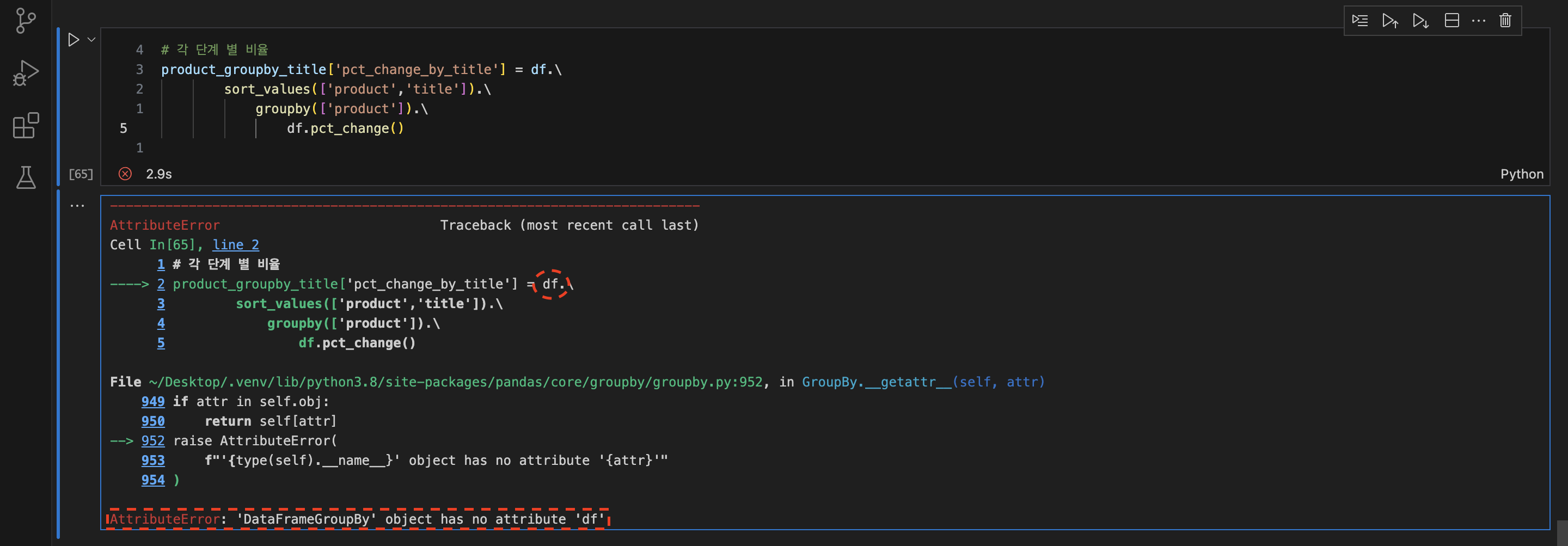
- 에러문 해석 : 'df'라고 하는 object가 없다!!
# df값 변경
'df'` -> 'product_groupby_title'- 그래도
AttributeError: 'DataFrameGroupBy' object has no attribute 'product_groupby_title'
-> 에러문 다시 해석 : DataFrameGroupBy 객체로 처리되고 있어서, 이 객체에서 pct_change() 메서드를 호출하려 할 때 문제가 발생한 것 - 코드 전체 변경
# 코드를 전체 변경 (너무 길어서 어디가 틀렸는지 알 수 없기 때문에 나누기!!)
product_groupby_title_sorted = product_groupby_title.sort_values(['product', 'title'])
product_groupby_title_sorted['pct_change_by_title'] = product_groupby_title_sorted.groupby(['product', 'title'])['count'].pct_change() -> pct_change_by_title 컬럼의 데이터가 전체 NaN으로 출력....
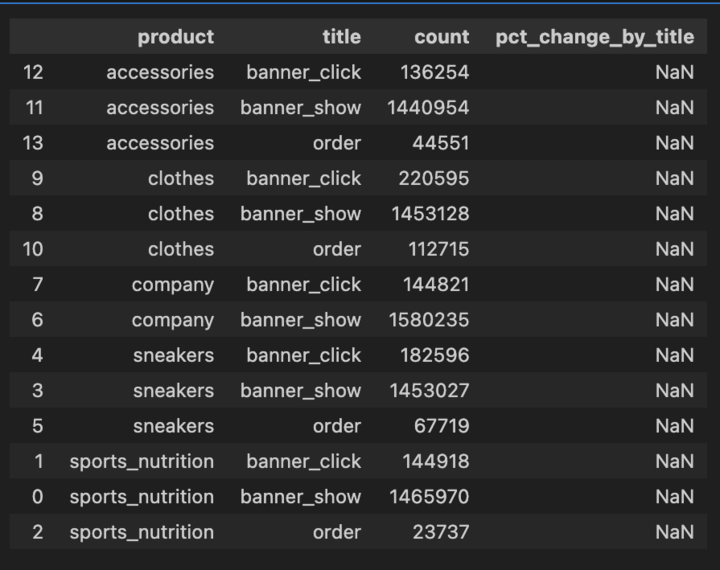
- 혹시 groupby의 index가 2개라서 그런가? 'title'하나 삭제
# 'title' 삭제
groupby(['product', 'title']) -> groupby(['product'])- 원하는 증감률로 나오긴 했지만 순서가 잘못되었음!! (배너 노출 - 배너 클릭 - 주문 순)
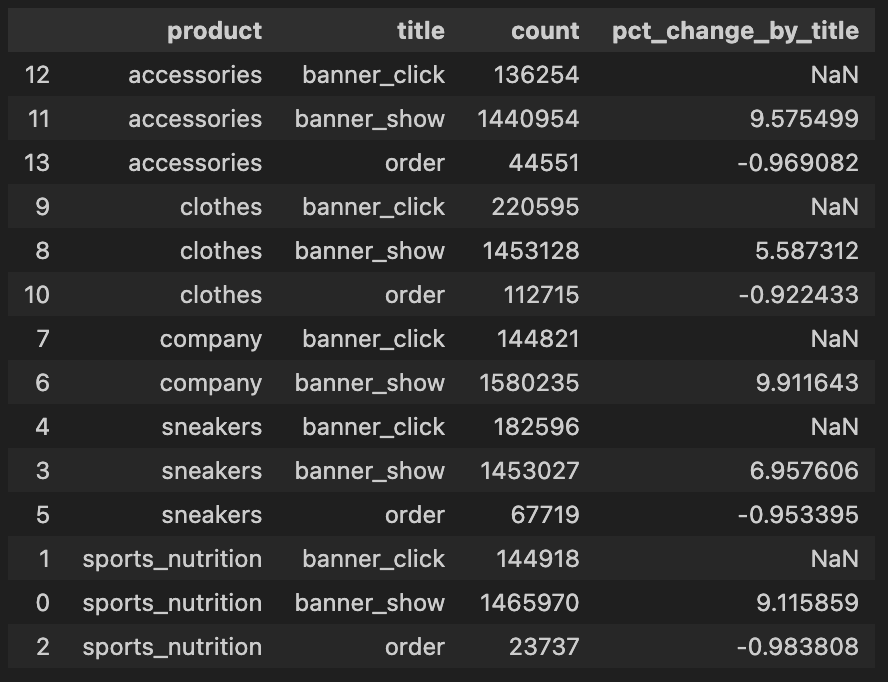
- 'product', 'count'를 기준으로 데이터 내림차순 후 'product'별 증감률 계산
- 'count'는 2차 기준으로 데이터 정렬하기 때문에 추후 증감률에서는 'product'별로 계산
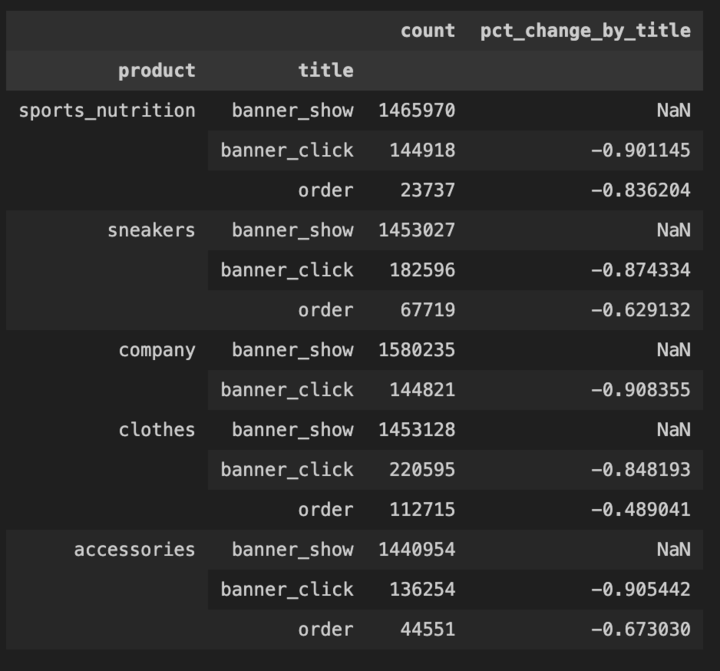
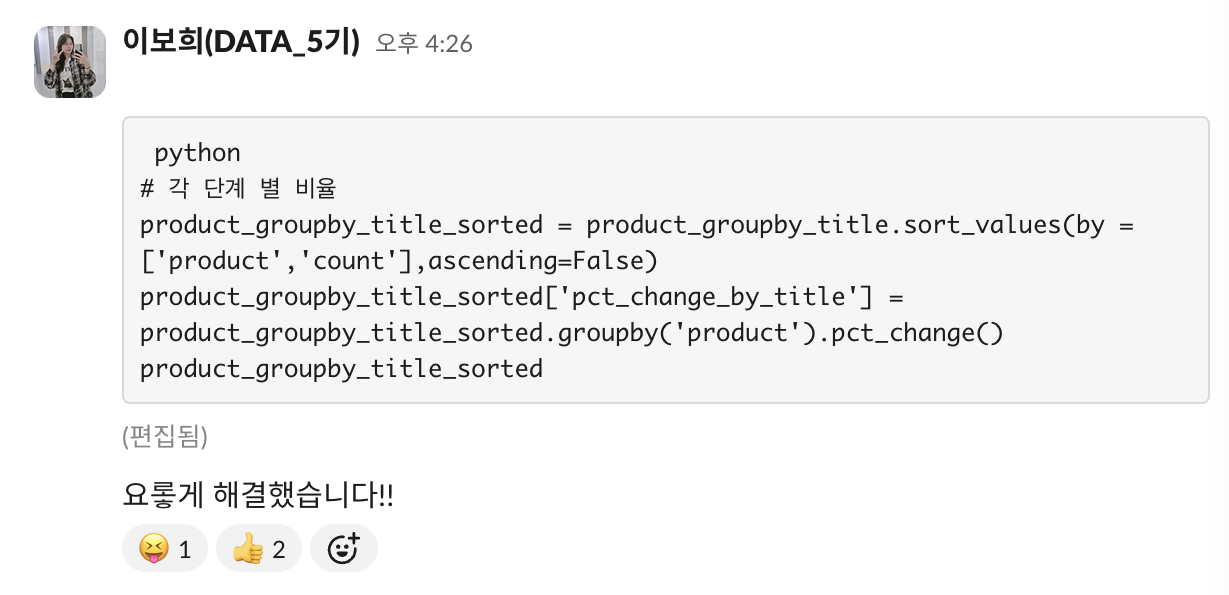
# 코드 부분 변경
product_groupby_title_sorted = product_groupby_title.sort_values(by = ['product', 'count']\
, ascending=False)
-- (문자열) by = [a,b] 기준 양식 추가
-- 'title' -> 'count' 로 변경
-- ascending = False 양식 추가
product_groupby_title_sorted['pct_change_by_title'] = product_groupby_title_sorted\
.groupby(['product']).pct_change() -- 'product'별 증감률 계산하고 싶은거니까 'count'삭제- 해결😮💨
사실 팀원들에게 물어봤지만.. 내 풀이로 해보고 싶어서 끝까지 디버깅을 해서 결국 해냈다!!
뿌듯한 마음에 팀원들에게 이 기쁜 소식을 공유한 나!! 귯..!!
03. RFM 분석
- 참고자료
RFM Segmentation with Python- Github - RFM Segmentation에 대하여...

- 기초 데이터 확인
# 전체 데이터 조회
df.shape
df.head()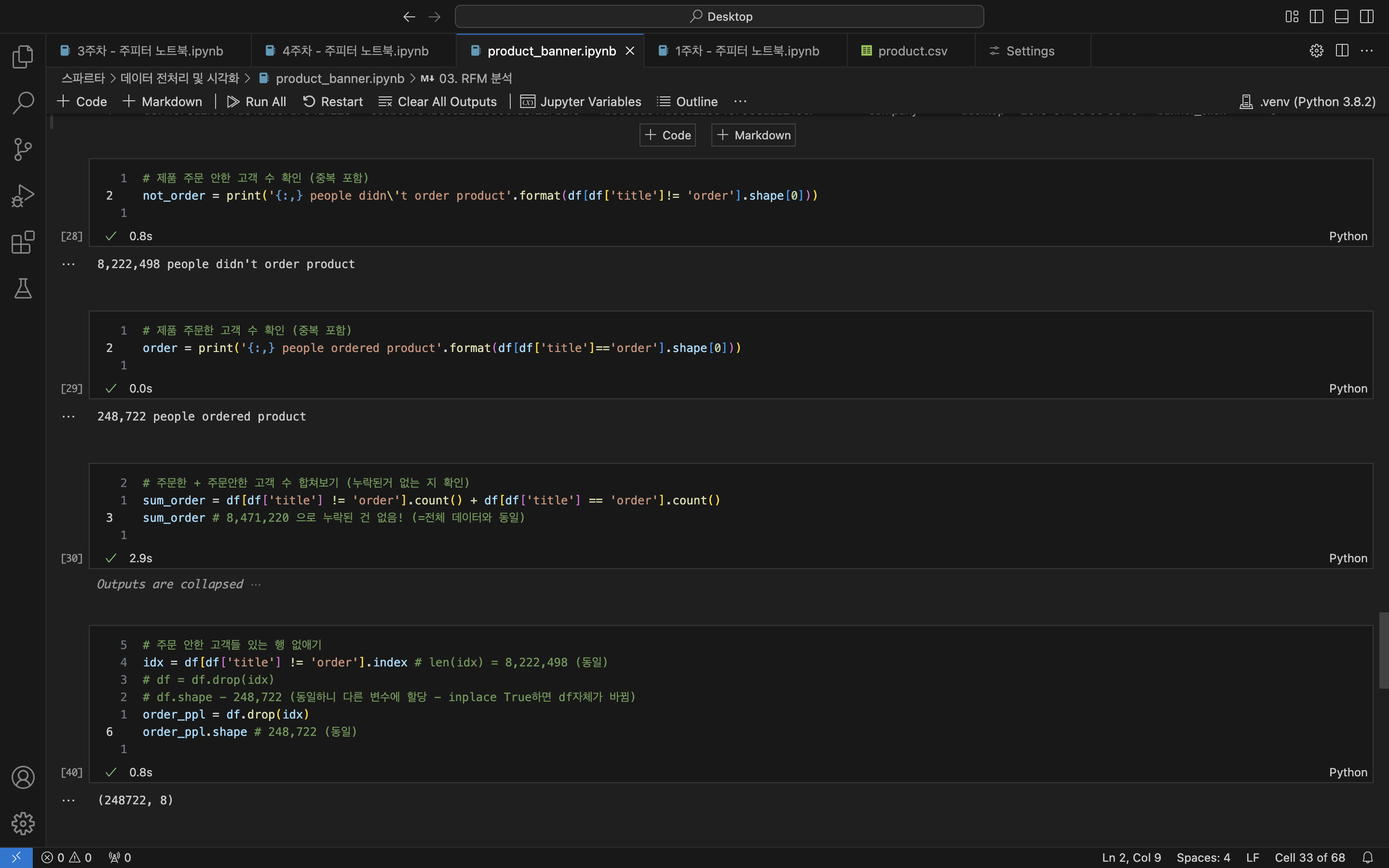
- 주문한 고객만 따로 빼기
# 제품 주문 안한 고객 수 확인 (중복 포함)
not_order = print('{:,} people didn\'t order product'.format(df[df['title']!= 'order'].shape[0]))
-- 8,222,498 people didn't order product
# 제품 주문한 고객 수 확인 (중복 포함)
order = print('{:,} people ordered product'.format(df[df['title']=='order'].shape[0]))
-- 248,722 people ordered product
# 주문한 + 주문안한 고객 수 합쳐보기 (누락된거 없는 지 확인)
sum_order = df[df['title'] != 'order'].count() + df[df['title'] == 'order'].count()
sum_order # 8,471,220 으로 누락된 건 없음! (=전체 데이터와 동일)
/*
order_id 8471220
user_id 8471220
page_id 8471220
product 8471220
site_version 8471220
time 8471220
title 8471220
target 8471220
dtype: int64
*/
# 주문 안한 고객들 있는 행 없애기
idx = df[df['title'] != 'order'].index # len(idx) = 8,222,498 (동일)
# df = df.drop(idx)
# df.shape - 248,722 (동일하니 다른 변수에 할당 - inplace True하면 df자체가 바뀜)
order_ppl = df.drop(idx)
order_ppl.shape # 248,722 (동일)
-- (248722, 8)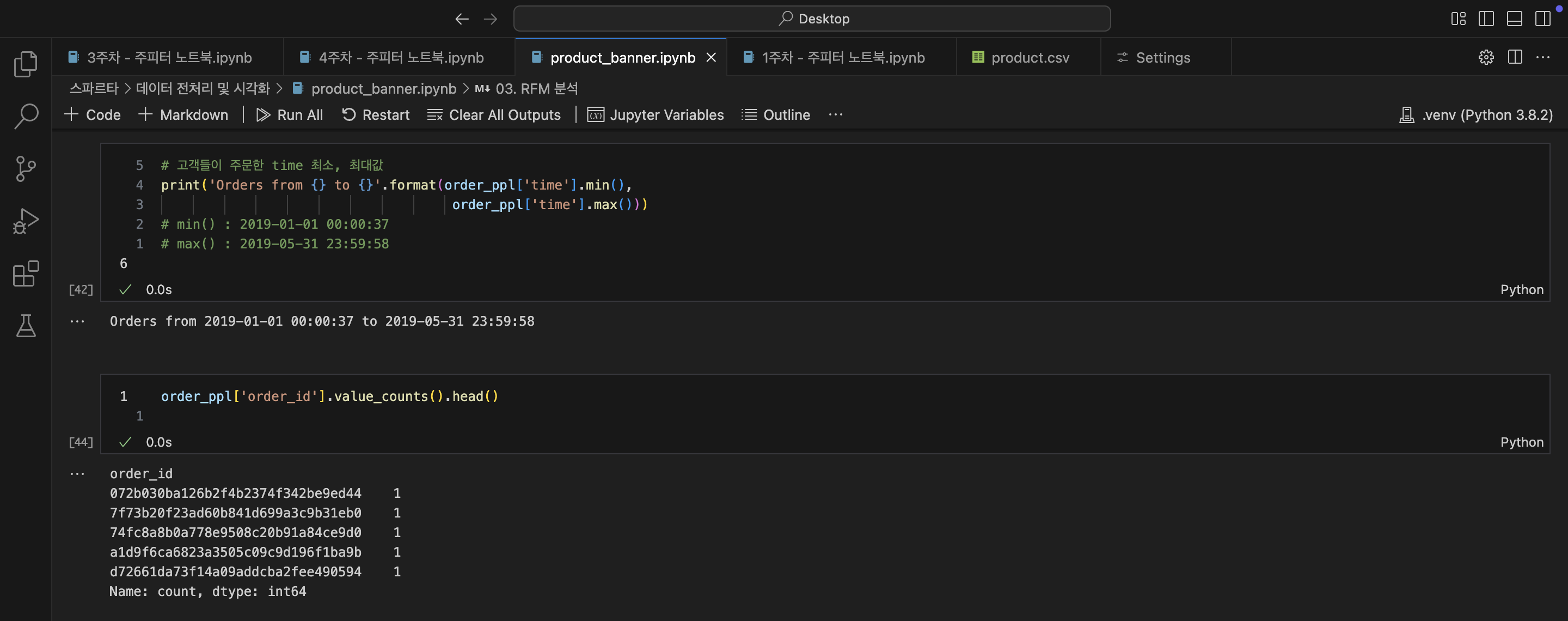
- 주문한 고객의 데이터 확인하기
# 고객들이 주문한 time 최소, 최대값
print('Orders from {} to {}'.format(order_ppl['time'].min(),
order_ppl['time'].max()))
# min() : 2019-01-01 00:00:37
# max() : 2019-05-31 23:59:58
-- Orders from 2019-01-01 00:00:37 to 2019-05-31 23:59:58
# order_id 중복 확인
order_ppl['order_id'].value_counts().head()
/*
order_id
072b030ba126b2f4b2374f342be9ed44 1
7f73b20f23ad60b841d699a3c9b31eb0 1
74fc8a8b0a778e9508c20b91a84ce9d0 1
a1d9f6ca6823a3505c09c9d196f1ba9b 1
d72661da73f14a09addcba2fee490594 1
Name: count, dtype: int64
*/RFM 하면서 궁금했던 것❓
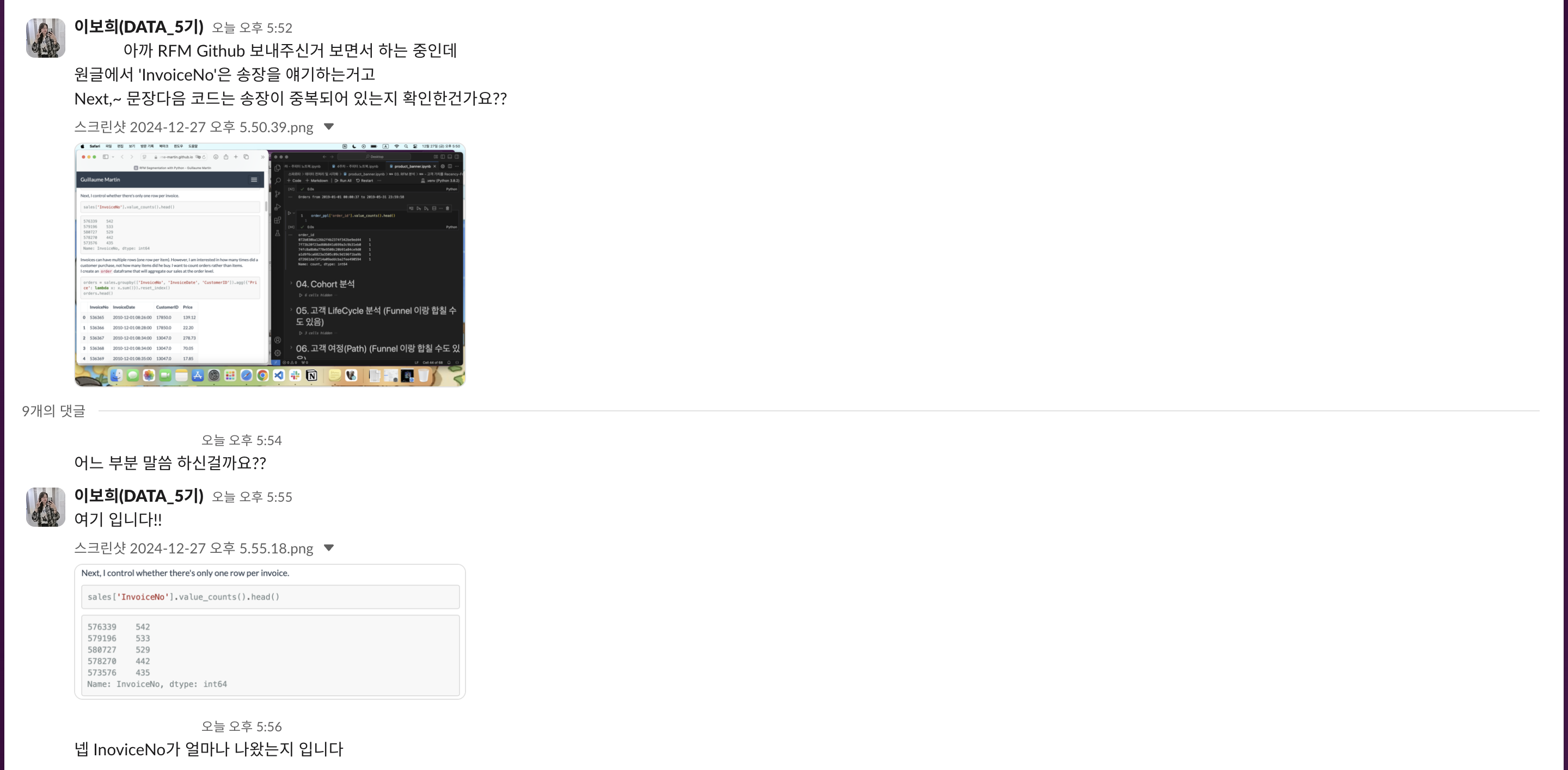
아티클(이하 글)을 읽으면서 잘 이해가 안가는 부분이 있어서 자료를 공유해주신 팀원에게 궁금한 사항을 여쭤보았다
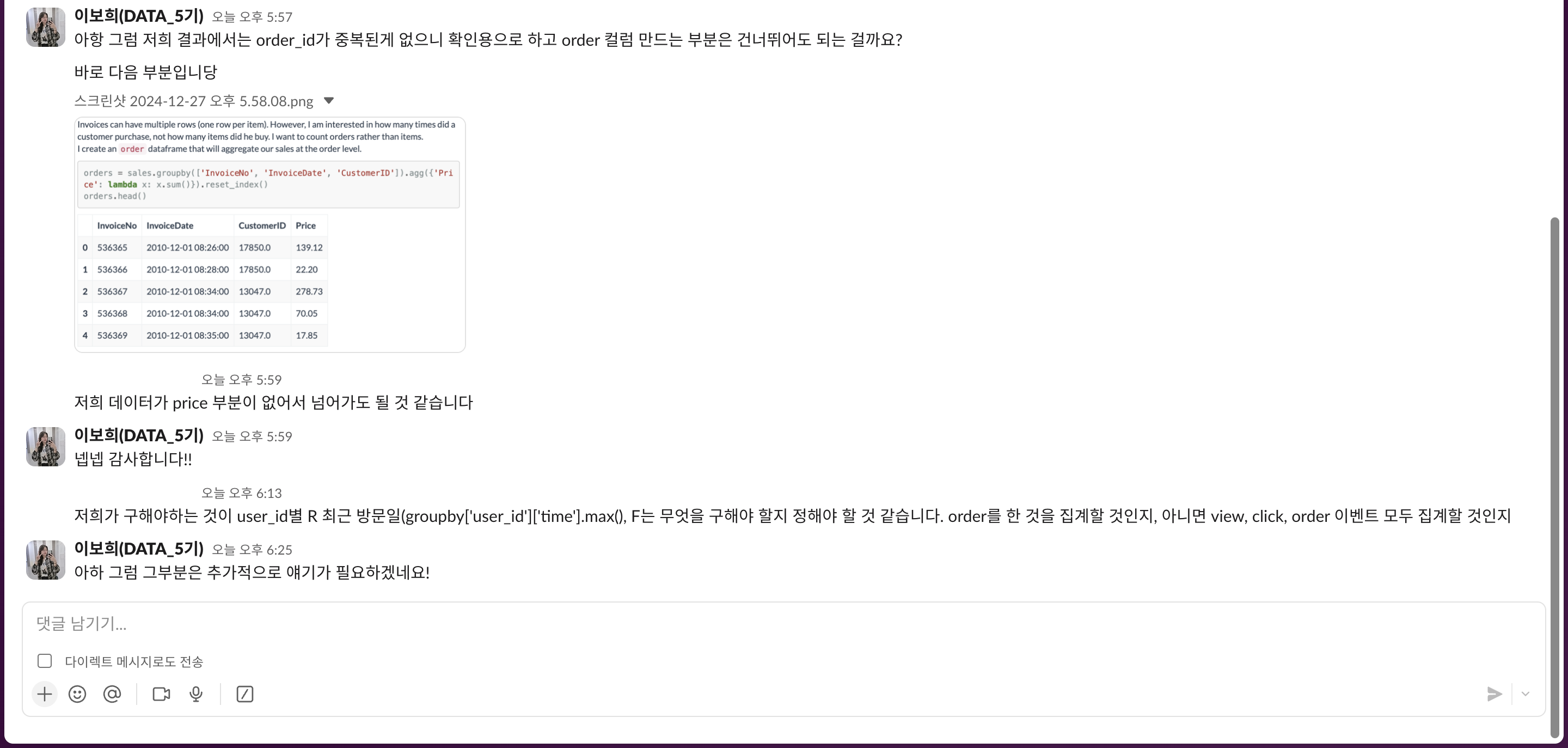
글에서는 InvoiceNo컬럼의 데이터가 중복되는지 확인하였고, 중복이 있어서 그부분을 제거해주는 작업을 하였다.
그러나 우리가 가지고 프로젝트를 하는 데이터는 확인 결과 중복이 존재하지 않기 때문에 중복 확인용으로만 참고하고 그 후 나오는 작업은 할 필요가 없다고 했다.
-> 이때, product.csv 파일은 Monetary(=Money)에 관한 지표가 없는데 RF만으로도 충분히 가능한건 알지만 RF/RFM을 잘 진행하려면 어떤 지표를 활용해야 하는걸까?
피드백
아쉽지만 분량이 너무 길어진 관계로 튜터님의 피드백과 추후 논의사항은 WIL에서 계속...
TIL 마무리...
오늘한 분석을 좀 기록하면서 정리해두고 싶었는데 너무 욕심부린듯 하다...
다음부터는 처음~끝 보다는 집중적으로 한 분석의 내용, 처음 알게 된 내용,분석을 진행하면서 궁금한점, 디버깅 프로세스 등을 적어야 할듯 하다!
피드백을 간략히 말하자면
'레퍼런스를 공부해서 주제를 다시 세세하게 짜고 데이터 분석과 시각화를 진행해야 할 것 같다' 라고 말씀해주셔서 토요일에 각자 찾아온 자료 공유 후 주제에 대한 의견을 나눠볼 예정이다... (이 내용이 WIL로 들어갈 예정>~<)
오늘은 이만 마무리하고 자료 찾으러~~