
읽을때 마다 새로운 지식을 알게되는 책이지만, 다음 챕터로 넘어 갈수록 너무 어려워져서 손이가지 않는 책으로 최대한 많이 이해하고 완독을 목표로 정리를 하기위해서 글을 작성하게 되었다.
처음에는 2부 부터 읽다가 왜 1을 읽지 않느냐는 질문을 받고 1부를 읽게되었고 1부 부터 읽는게 필수라고 할정도로 난이도 차이가 있다.
잘근잘근 씹어먹듯, 많은 지식을 남길 수 있도록 열심히 정리해보자!
가상 면접 사례로 배우는 대규모 시스템 설계 기초 - 예스24
분산 시스템을 위한 유일 ID 생성기
유일하고, 정렬기능을 갖춘 ID정보 생성이 필요하다.
특이점은 이번에는 숫자로만 이용해야하고 64bit 를 기준으로 생성되어야한다.
다음과 같은 방법이 있는데, 같이 확인해보자.
1. 다중 마스터 복제 (multi-master replication)
auto-increment 기능을 활용하여 각각의 ID 아이디 값을 구할때 DB 의 서버 수만큼 증가시키는 방법으로 적용하는 방법
1만큼 증가하지 않고 K 만큼 증가하며 K 는 DB 의 서버 수와 같다. 이러한 방법으로 규모 확장성 문제를 어느정도 해결할 수 있다.
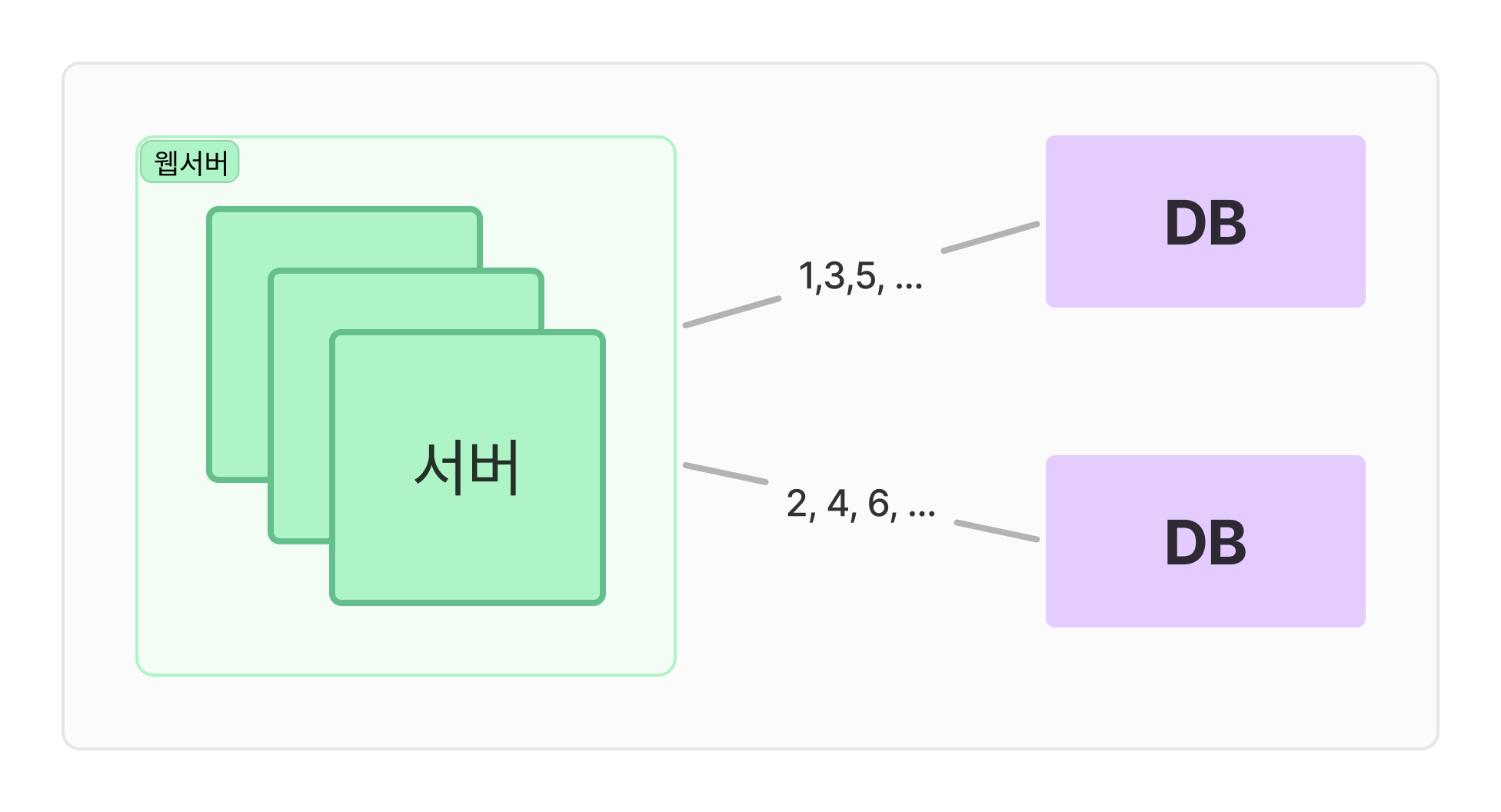
다만 간편한 만큼 뚜렷한 문제가 있는데,
- 여러 데이터 센터에 걸처서 규모를 늘리기가 어렵고, 서버를 추가하거나 삭제시 잘동작하기 어려운 문제가 존재한다.
- 유일성은 보장하지만, 시간의 흐름에 맞게 커지도록 보장할 수 없다. (첫번째 DB 가 먼저 증가한다면, 숫자에 기반하여 데이터의 순서를 보장할 수 없다.)
2. UUID
저장되는 데이터를 유일하게 식별하기 위한 128bit의 값이다.
UUID 의 형태는 다음과 같다.
특징 중 하나는, 충돌가능성이 작은 것이다. 위키피디아 기반으로 보면 중복1개가 발생할 확률을 50% 까지 올리려면 초당 10억개의 UUID 를 계속해서 100년동안 만들어야 가능하다고 한다.
또한 다른 특징은 서버 구분없이 독립적으로 생성가능하다는 점이다.
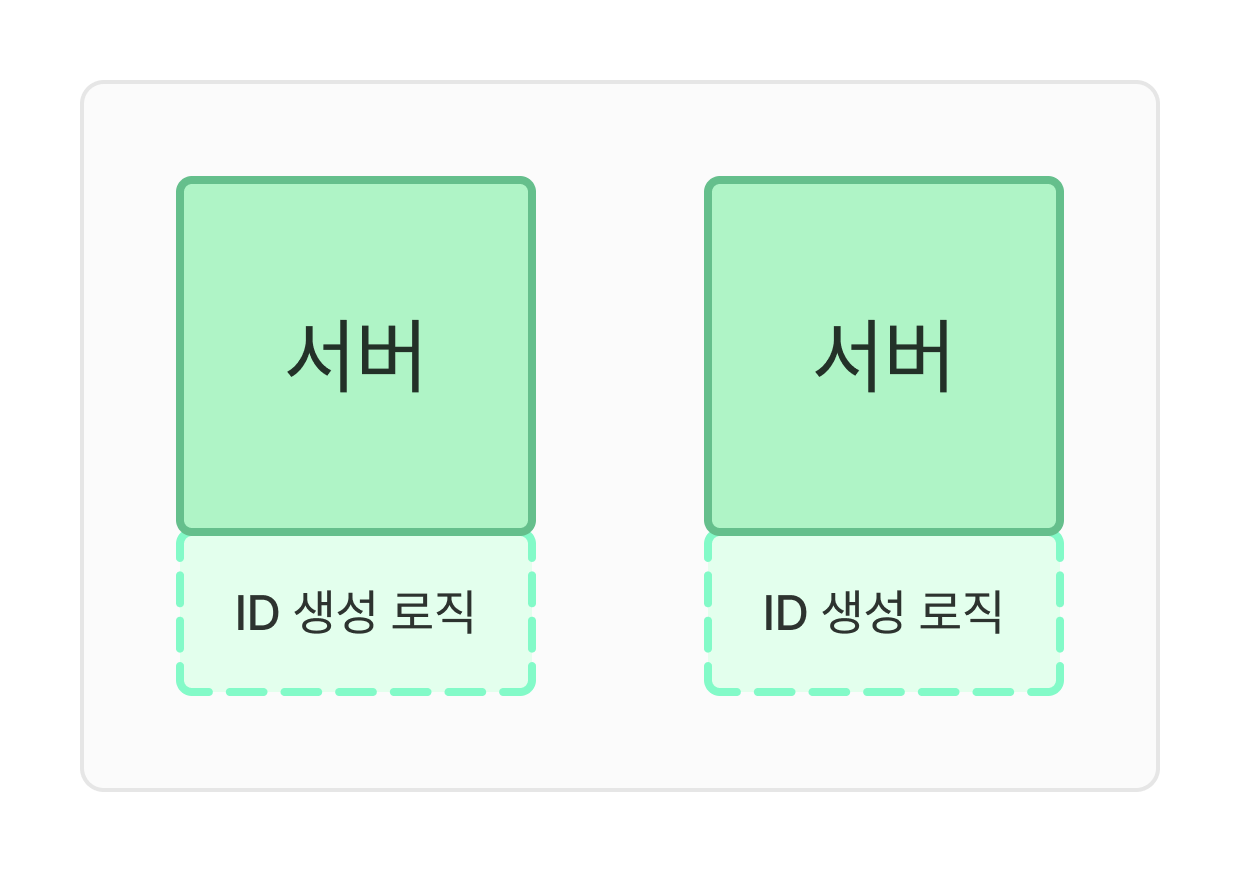
장점은 다음과 같다.
UUID 생성이 단순하다는 장점이 있다. 각 웹서버가 생성하므로 규모 확장도 간단하게 진행할 수 있다.
단점은
- ID 값이 128bit 로 길고, 시간 순서대로 정렬할 수 가 없다는 부분이 있다.
- 숫자가 아닌값이 포함될 수 있는 부분도 있어 조건에 맞지 않는다.
3. 티켓 서버 (ticket server)
이 아이디어의 핵심키는 auto-increment 기능을 갖춘 데이터서버 (티켓서버)를 중앙 집중형으로 하나만 사용하는 것이다.
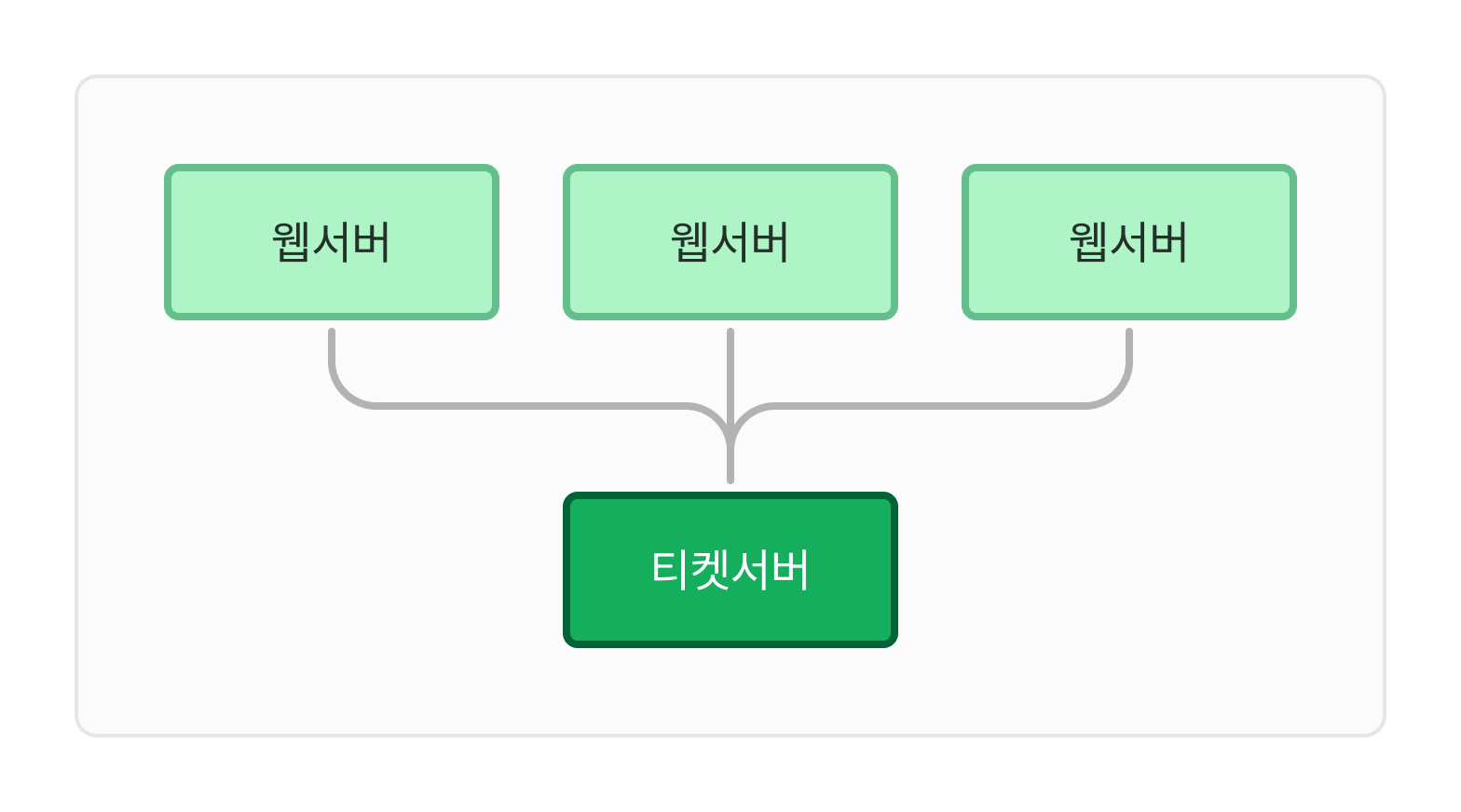
장점
- 유일성이 보장되는 오직 숫자로만 구성된 ID를 쉽게 만들 수 있다.
- 구현하기 쉽고 중소 애플리케이션에 적합하다.
단점 - 티켓 서버가 SPOF(sigle-point-of-failure) 가 된다.
장애 발생시 모든 시스템에 영향이 되고, 티멧 서버가 늘어나면 데이터 동기화에 대한 이슈도 있다.
4. 트위터 스노플레이크(snowflake) 접근법
이전의 방법에서는 조건을 만족시키는 것이 없었다. 따라서 트위터(X)에서 사용하는 기법을 기반으로 정리해보도록 해보자.

우선 각각의 ID는 64bit로 구성되어있는데 해당 부분부터 정리하면 다음과 같다.
| 이름 | bit | 설명 |
|---|---|---|
| sign bit | 1 | 나중을 위한 유보 |
| timestamp | 41 | 기원시간 이후 몇 밀리초가 지나갔는지를 나타내는 값 |
| 데이터 센터 ID | 5 | 32개의 데이터 센터를 지원한다. |
| 서버 ID | 5 | 32개의 서버를 이용할 수 있게 한다. |
| 일련번호 | 12 | 각 서버 별로 ID 생성할때 마다 1씩 증가한다. timestamp가 변경되는 1 밀리초가 경과될때마다 0으로 리셋된다. 총 4096개의 값을 가질 수 있다. |
다만 해당 timestamp는 총 69년 동안 동작한다. 기준점에서 69년이 지나면 기원시간을 변경하거나, ID 체계를 이전해야 한다.
체크해야 될 부분은 다음과 같다.
- 서버별로 시계가 동기화 해야되는 부분이 존재한다. 시간이 다르면 데이터의 정렬이 잘못될 수 있다.
- 각 절의 길이를 사용환경에 따라서 일련번호 등 값을 줄이고 타임스템프를 늘려서 시간을 늘리는 것이 효과적일 수 있다.
