
읽을때 마다 새로운 지식을 알게되는 책이지만, 다음 챕터로 넘어 갈수록 너무 어려워져서 손이가지 않는 책으로 최대한 많이 이해하고 완독을 목표로 정리를 하기위해서 글을 작성하게 되었다.
처음에는 2부 부터 읽다가 왜 1을 읽지 않느냐는 질문을 받고 1부를 읽게되었고 1부 부터 읽는게 필수라고 할정도로 난이도 차이가 있다.

잘근잘근 씹어먹듯, 많은 지식을 남길 수 있도록 열심히 정리해보자!
가상 면접 사례로 배우는 대규모 시스템 설계 기초 - 예스24
안정 해시 설계
안정 해시 설계는 수평적 규모 확장을 위해서 모든 데이터를 균등하게 나누는것 중요하기 떼문에, 이 목표를 달성하기 위해 보편적으로 사용하는 기술입니다.
해시키 재배치 (rehash) 문제
N개의 해시키를 균등배치하는 보편적 방법은 아래의 로직을 사용하는 방법입니다.
N 은 서버의 수
총 4개의 서버를 갖고 있을때는 아래와 같이 처리됩니다.
| key 명 | 해쉬값 (예시) | 수식 적용 값 ( N = 4 ) |
|---|---|---|
| k1 | 24 | 0 |
| k2 | 26 | 2 |
| k3 | 40 | 0 |
| k4 | 33 | 1 |
| k5 | 43 | 3 |
| k6 | 38 | 2 |
| k7 | 27 | 3 |
| k0 | 41 | 1 |
| 서버인덱스 | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 서버 | s0 | s1 | s2 | s3 |
| 할당 키 | k1, k3 | k4, k0 | k2, k6 | k5, k7 |
하지만 서버가 추가 되고, 삭제시 문제가 생기는 현상을 확인할수 있습니다. 삭제 되었을 경우 아래와 같이 처리됩니다. (총 3개의 서버를 갖고 있을 때)
| key 명 | 해쉬값 (예시) | 수식 적용 값 ( N = 3 ) |
|---|---|---|
| k1 | 24 | 0 |
| k2 | 26 | 2 |
| k3 | 40 | 1 |
| k4 | 33 | 0 |
| k5 | 43 | 1 |
| k6 | 38 | 2 |
| k7 | 27 | 0 |
| k0 | 41 | 2 |
| 서버인덱스 | 0 | - | 1 | 2 |
|---|---|---|---|---|
| 서버 | s0 | s1 ( 제거) | s2 | s3 |
| 할당 키 | k1, k3, k7 | - | k3, k5 | k2, k6, k0 |
장애가 있어 제거된 S1의 할당 키 뿐만 아니라, 대규모 캐시 미스가 일어나는 것을 확인할 수 있습니다.
안정 해시는 이 문제를 해결하기 위해 사용됩니다. (consistent hash) 재 배치 되었을때, 평균적으로 k/n 개의 키만 재배치 되도록 설정되어 설계 되있습니다. ( k 는 키/ n 서버수 ) 전통적 해시는 서버 수량이 변경되면, 대부분의 키를 재배치 합니다.
해시 공간 & 해시링
해시 함수로 SHA-1을 사용하고, 출력값의 범위는 라고 가정합니다. 여기서 SHA-1 의 해시 공간은 입니다.
은 0 으로, 은 으로 두었을때 각각 은 그 사이값을 갖게 됩니다. 아래 이미지 처럼 구부려 접는다면 해시링이 생성되겠죠.
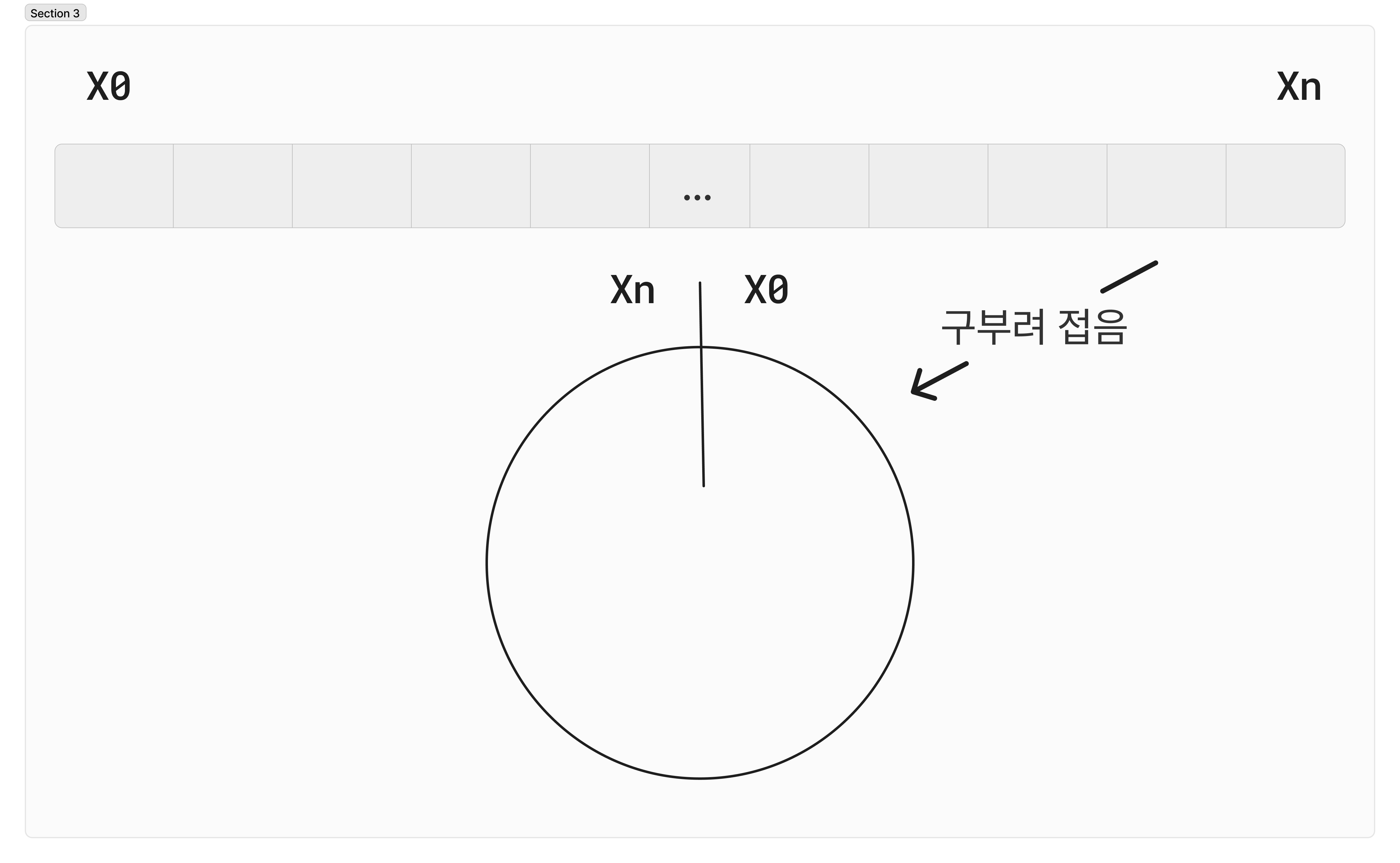
해시 서버
이 해시 함수 f(x) 를 사용하면 서버IP, 이름 등 을 기준으로 링위의 위치에 대응하여 사용할 수 있습니다.
나머지를 구하는 연산을 하지 않고, 해시 키 위 어느 위치, 지점에 배치가 가능합니다. 해시 키를 f(x) 함수에 적용해서, 각각 해시 링 위로 적용할 수 있습니다. 어떤 키가 저장 되는 서버를 정하는 방법은 해시 키가 시계방향으로 탐색해 나가면서 처음 만나는 방법으로 적용됩니다.
아래 이미지에서 보면 조금 더 명확하게 확인할 수 있습니다.
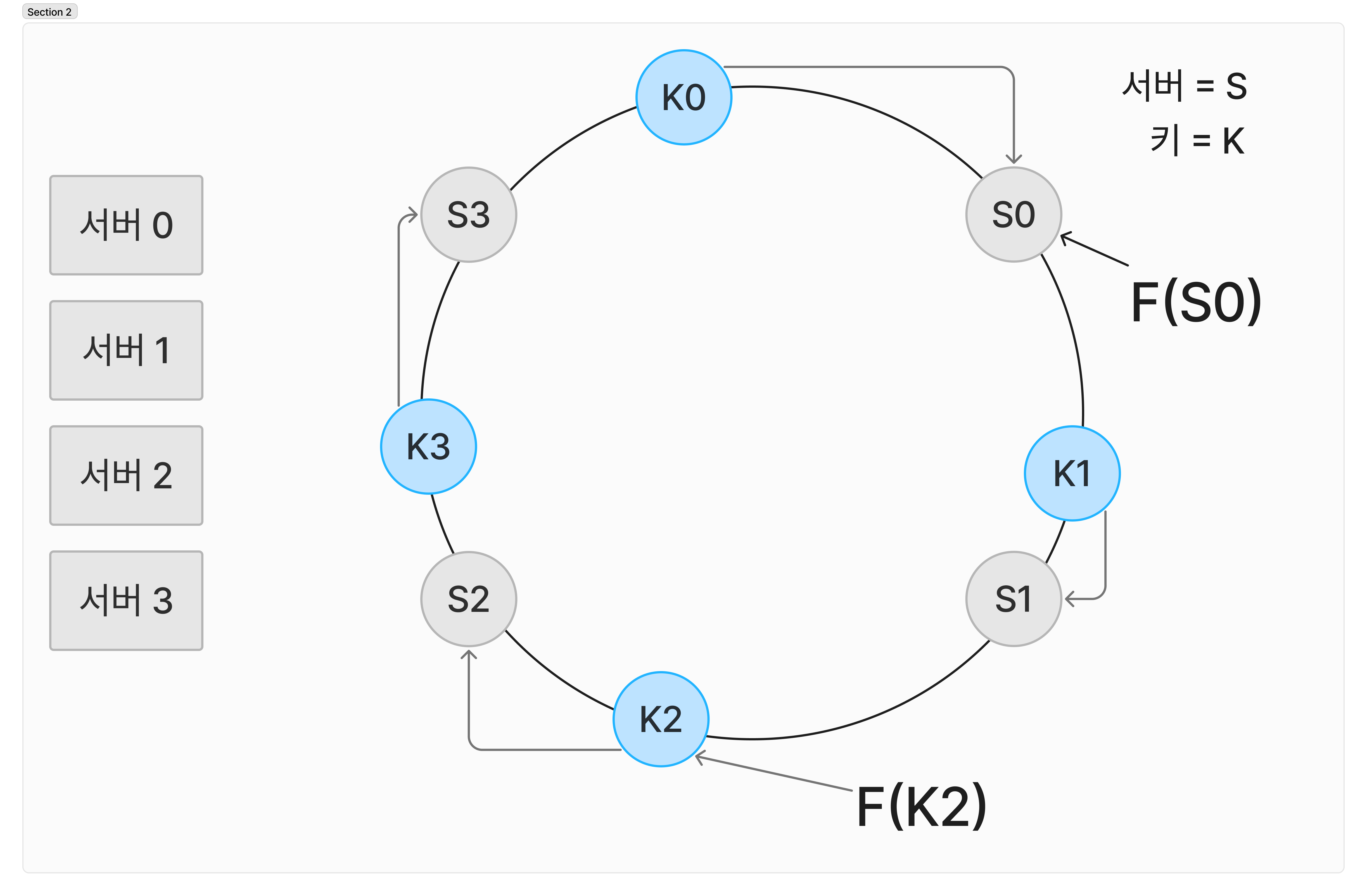
서버가 추가/종료 될 때의 상황
전통적 해시 서버와 다르게 키 중, 일부만 재배치 하면 됩니다. 추가 될 때를 기준으로 보면, 우선 S4 의 새로운 서버가 생기고 배치가 진행됩니다. k0이 시계 방향으로 순회될때, 처음 만나는 서버가 S4로 변경되었으므로 S0 -> S4 로 K0 만 재배치 됩니다.
제거 될 때를 기준으로 보면, S1 이 종료되어 해시링에서 제거됩니다. S1에 저장되어있던, k1 만 순회 한다면 처음만나는 서버인 S3로 이동 배치 되는 것을 확인할 수 있죠.
두가지 문제점
다시 기본절차를 정리하면 다음과 같습니다.
- 서버와 키를 균등 분포 해시함수를 사용해 해시링에 배치한다.
- 키의 위치에서 링을 시계방향으로 탐색하다 만나는 최초에 서버가 키가 저장될 서버이다.
다만, 이렇게만 안정해시가 설계된다면 문제되는 지점이 두개가 존재합니다.
[1] 서버가 추가되거나 삭제시, 파티션의 크기를 유지하는 게 불가능한 문제가 존재
- 아래 이미지 중 처음 이미지를 보면 S1 이 제거되는 바람에 S2 가 거의 두배로 커지는 상황이 보여집니다.
[2] 키의 균등 분포를 달성하기 어렵다.
- 배치가 오른쪽 이미지와 같이 되었을때 서버 1, 서버3 에 키가 하나도 배치되지 않는 모습을 확인할 수 있습니다.
이 문제를 해결하기 위해 제안된 기법이 다음 방법으로 해결할수 있습니다.
가상노드 - 복제 ( virtual node - replica )
가상 노드는 실제노드, 서버를 가르키는 노드로 하나의 서버는 링위에 여러개의 가상노드를 갖고 있습니다.
두개의 서버가 각각 3개씩 (임의설정) 가상노드를 갖고있다고 가정해보죠
- S0-0, S0-1, S0-2 (S0)
- S1-0, S1-1, S1-2 (s1)
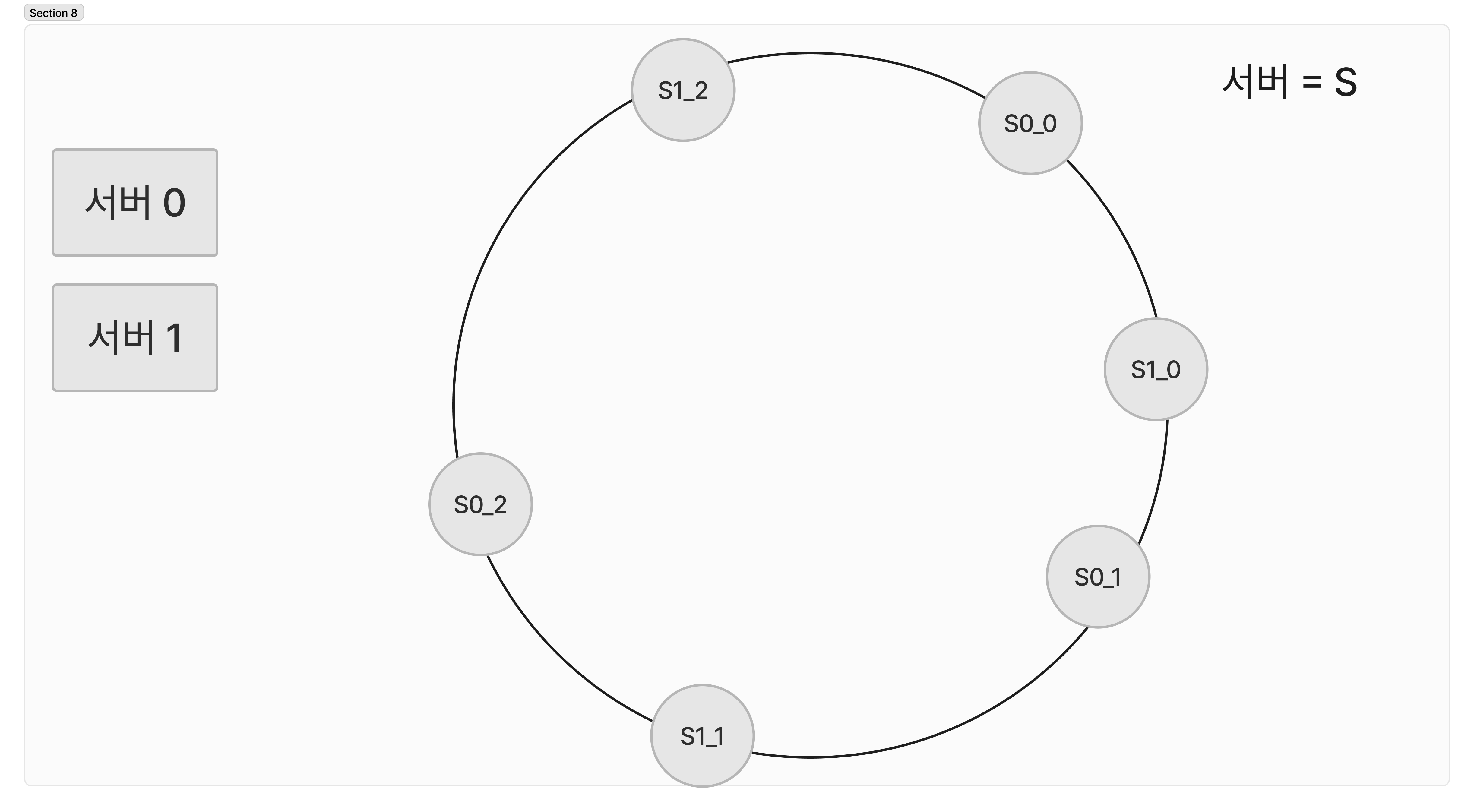
해당 하는 이미지 처럼 분할 배포되어 있는 것으로 조금 더 균등하게 배포된것을 확인할 수 있습니다.
가상 노드의 개수를 늘리면, 키의 분포는 점점 더 균등해진다.
100개 - 200 개 -> 표준편차 값은 평균의 5% - 10% 로 적용된다.
더 많이 늘리면 균등하게 분포되겠지만, 가상 노드의 데이터를 저장할 공간은 더 많이 필요해서, 중간 지점을 잘 선택해서 적용이 필요합니다.
마무리
안정 해시의 이점은 다음과 같습니다.
- 서버가 추가되거나 삭제될때, 재배치 되는 키의 수의 최소화
- 데이터가 보다 균등하게 분포하게되므로, 수평적 규모 확장성을 달성하기 쉽다.
- 핫스팟 키 문제를 줄인다. (특정한 샤드에 대한 접근이 지나치게 빈번한 문제)
해당 하는 방법이 실제로 쓰이는 곳도 많아서 중요한 개념으로 정리하면 좋습니다.
