
🎯 1절 표준 조인
1) STANDARD SQL
-
일반 집합 연산자
-
UNION 연산 -> UNION 기능 : 합집합 (공통 교집합의 중복 없앰)
-
INTERSECTION 연산 -> INTERSECT 기능 : 교집합 (공통집합 추출)
-
DIFFERENCE 연산 -> EXCEPT(Oracle은 MINUS) 기능
: 차집합 (공통집합 제외) -
PRODUCT 연산 -> CROSS JOIN 기능 : 곱집합
(JOIN 조건이 없는 경우 생길 수 있는 모든 데이터의 조합) -
[그림] E.F.CODD 일반 집합 연산자
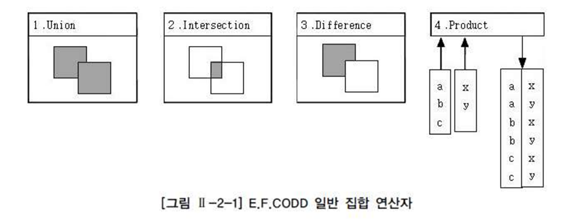
-
-
순수 관계 연산자
-
SELECT 연산 -> WHERE 절 : SQL 문장에서 WHERE 절의 조건절 기능
(주의 : SELECT 절과 의미 다름) -
PROJECT 연산 -> SELECT 절 : SQL 문장에서 SELECT 절의 칼럼 선택 기능
-
(NATURAL) JOIN 연산 -> 다양한 JOIN 기능
: WHERE 절의 INNER JOIN 조건과 함께 FROM 절의 NATURAL JOIN,
INNER JOIN, OUTER JOIN, USING 조건절, ON 조건절 등으로 다양하게 발전 -
DIVIDE : 나눗셈과 비슷한 개념 (현재 사용 X)
-
[그림] E.F.CODD 순수 관계 연산자
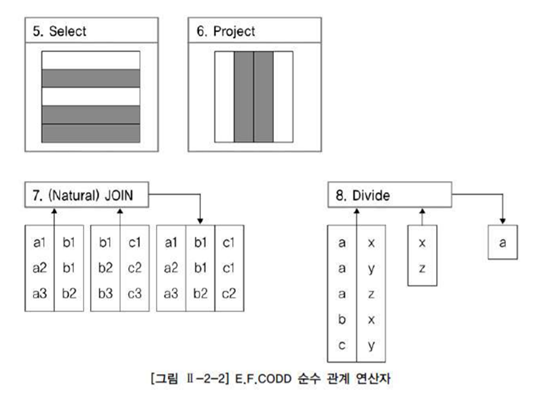
-
2) FROM 절 JOIN 형태
- INNER JOIN – NATURAL JOIN – USING 조건절
– ON 조건절 – CROSS JOIN – OUTER JOIN
3) INNER JOIN
- JOIN 조건에서 동일한 값이 있는 행만 반환
(USING 조건절이나 ON 조건절 필수적으로 사용)
4) NATURAL JOIN
- 두 테이블 간의 동일한 이름을 갖는 모든 칼럼들에 대해 EQUI(=) JOIN을 수행
(SQL Server에서는 지원하지 않음) - USING 조건절, ON 조건절, WHERE 절에서 JOIN 조건 정의할 수 없음
- JOIN에 사용된 칼럼들은 같은 데이터 유형이어야 하며,
ALIAS나 테이블명과 같은 접두사를 붙일 수 없음
예 : SELECT DEPTNO, EMPNO, ENAME, DNAME FROM EMP NATURAL JOIN DEPT;
5) USING 조건절
- 같은 이름을 가진 칼럼들 중에서 원하는 칼럼에 대해서만
선택적으로 EQUI JOIN을 할 수 있음 (SQL Server에서는 지원하지 않음) - JOIN 칼럼에 대해서는 ALIAS나 테이블명과 같은 접두사를 붙일 수 없음
예 : SELECT * FROM DEPT JOIN DEPT_TEMP USING (DEPTNO);
6) ON 조건절
- 칼럼명이 다르더라도 JOIN 조건을 사용할 수 있음
- ON 조건절을 사용한 JOIN의 경우는 ALIAS나 테이블명과 같은 접두사를 사용하여
SELECT에 사용되는 칼럼을 논리적으로 명확하게 지정해주어야 함 - ON 조건절과 WHERE 검색 조건은 충돌 없이 사용할 수 있음
예 : SELECT E.NAME, E.DEPTNO, D.DEPTNO, D.DNAME FROM EMP E
JOIN DEPT D ON (E.DEPTNO = D.DEPTNO);
7) CROSS JOIN
- 테이블 간 JOIN 조건이 없는 경우 생길 수 있는 모든 데이터의 조합
(= CARTESIAN PRODUCT)
8) OUTER JOIN
: 특정 기업이나 조직 또는 개인이 필요에 의해
데이터를 일정한 형태로 저장해놓은 것
9) INNER vs OUTER vs CROSS JOIN 비교
- [그림] INNER vs OUTER vs CROSS JOIN 문장 비교
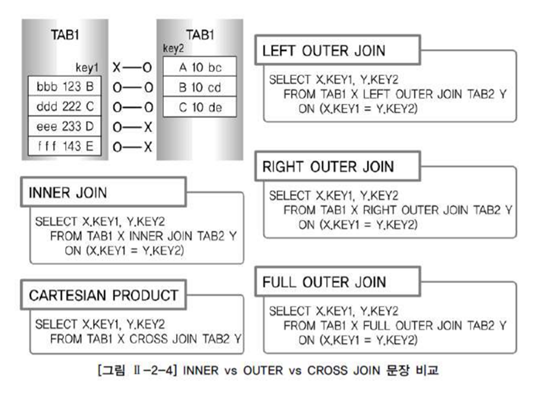
- INNER JOIN의 결과 : B-B, C-C (2건)
- LEFT OUTER JOIN의 결과 : B-B, C-C, D-NULL, E-NULL (4건)
- RIGHT OUTER JOIN의 결과 : NULL-A, B-B, C-C (3건)
- FULL OUTER JOIN의 결과 : A-NULL, B-B, C-C, D-NULL, E-NULL (5건)
- CROSS JOIN의 결과 : B-A, B-B, B-C, C-A, C-B, C-C, D-A, D-B, D-C, E-A, E-B, E-C (12건)
🎯 2절 집합 연산자
1) 집합 연산자
: 2개 이상의 질의 결과를 하나의 결과로 만들어줌
-
두 개 이상의 테이블에서 조인을 사용하지 않고 연관된 데이터를 조회하는 방법
-
집합 연산자를 사용하기 위한 제약조건
: SELECT 절의 칼럼 수가 동일,
SELECT 절의 동일 위치에 존재하는 칼럼의 데이터 타입이 상호 호환 가능-
집합 연산자의 종류
- UNION : 합집합
- UNION ALL : 합집합 (중복된 행도 그대로 결과로 표시)
- INTERSECT : 교집합
- EXCEPT : 차집합
-
[그림] 집합 연산자의 연산

-
🎯 3절 계층형 질의와 셀프 조인
1) 계층형 질의
-
계층형 데이터 : 동일 테이블에 계층적으로 상위와 하위 데이터가 포함된 데이터
-
테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해서 계층형 질의를 사용
-
[그림] 계층형 데이터
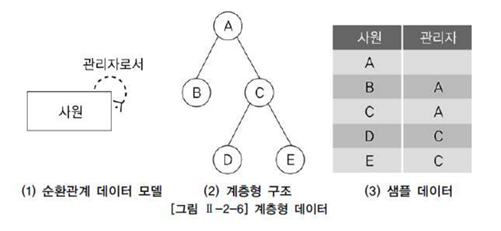
-
Oracle 계층형 질의
SELECT … FROM 테이블 WHERE condition AND condition …
START WITH condition CONNECT BY [NOCYCLE] condition AND condition
[ORDER SIBLINGS BY column, column, …]-
START WITH 절 : 계층 구조 전개의 시작 위치를 지정하는 구문
-
CONNECT BY 절 : 다음에 전개될 자식 데이터를 지정하는 구문
-
PRIOR : 현재 읽을 칼럼을 지정, CONNECT BY절에 사용
(PRIOR 자식 = 부모 : 자식 → 부모 순방향 전개
/ PRIOR 부모 = 자식 : 부모 → 자식 역방향 전개) -
NOCYCLE : 사이클이 발생한 이후의 데이터는 전개하지 않음
-
ORDER SIBLINGS BY : 형제 노드(동일 LEVEL) 사이에서 정렬을 수행
-
[표] 계층형 질의에서 사용되는 가상 칼럼

-
[표] 계층형 질의에서 사용되는 함수

-
-
SQL Server 계층형 질의
- CTE (Common Table Expression) 재귀 호출
- [그림] 조직도 예제

2) 셀프 조인
: 동일 테이블 사이의 조인
- 테이블과 칼럼명이 모두 동일하기 때문에 식별을 위해 반드시 테이블 별칭(Alias)을 사용
예 : SELECT E1.사원, E1.관리자, E2.관리자 차상위_관리자 FROM 사원 E1, 사원 E2
WHERE E1.관리자 = E2.사원 ORDER BY E1.사원;
🎯 4절 서브쿼리
1) 서브쿼리 (Subquery)
: 하나의 SQL문 안에 포함되어 있는 또 다른 SQL문 (괄호로 감싸서 사용)
-
서브쿼리는 메인쿼리의 칼럼을 모두 사용할 수 있지만
메인쿼리는 서브쿼리의 칼럼을 사용할 수 없다. -
서브쿼리는 단일 행 (Single Row) 또는 복수 행 (Multiple Row)
비교 연산자와 함께 사용 가능하다. -
서브쿼리에서는 ORDER BY를 사용하지 못한다.
(메인쿼리의 마지막 문장에 위치) -
[표] 동작하는 방식에 따른 서브쿼리 분류

-
[표] 반환되는 데이터의 형태에 따른 서브쿼리 분류

2) 단일 행 서브쿼리
- 서브쿼리가 단일 행 비교 연산자(=, <, <=, >, >=, <>)와 함께 사용할 때는
결과 건수가 반드시 1건 이하여야 함.
3) 다중 행 서브쿼리
- 특정 기업이나 조직 또는 개인이
필요에 의해 데이터를 일정한 형태로 저장해놓은 것
4) 다중 칼럼 서브쿼리
-
서브쿼리의 결과가 2건 이상 반환될 수 있다면
반드시 다중 행 비교 연산자(IN, ALL, ANY, SOME)와 함께 사용 -
[표] 다중 행 비교 연산자

5) 연관 서브쿼리
- 서브쿼리 내에 메인쿼리 칼럼이 사용된 서브쿼리
6) 그 밖의 위치에서 사용하는 서브쿼리
-
SELECT 절에 서브쿼리 사용하기
- 스칼라 서브쿼리 : 한 행, 한 칼럼(1 Row 1 Cloumn)만을 반환하는 서브쿼리
-
FROM 절에서 서브쿼리 사용하기
- 인라인 뷰 (Inline View) : SQL문이 실행될 때만 임시적으로 생성되는 동적 뷰
-
HAVING 절에서 서브쿼리 사용하기
-
UPDATE문의 SET 절에서 사용하기
-
INSERT문의 VALUES 절에서 사용하기
7) 뷰 (View)
: 실제 데이터를 가지고 있지 않은 가상테이블
-
뷰 사용의 장점
-
독립성 : 테이블 구조가 변경되어도
뷰를 사용하는 응용 프로그램은 변경하지 않아도 된다. -
편리성 : 복잡한 질의를 뷰로 생성함으로써 관련 질의를 단순하게 작성할 수 있다.
-
보안성 : 숨기고 싶은 정보가 존재한다면,
해당 칼럼을 빼고 생성함으로써 사용자에게 정보를 감출 수 있다.
-
🎯 5절 그룹 함수
1) ROLLUP 함수
- ROLLUP의 인수는 계층 구조이므로 인수 순서가 바뀌면 수행 결과도 바뀌게 됨
예 : SELECT DNAME, JOB, COUNT(*) ‘Total Empl“, SUM(SAL) ”Total Sal“
FROM EMP, DEPT WHERE DEPT.DEPTNO = EMP.DEPTNO GROUP BY ROLLUP (DNAME, JOB);
2) CUBE 함수
- 결합 가능한 모든 값에 대하여 다차원 집계 생성
- 평등한 관계이므로 인수의 순서가 바뀌어도 결과는 같음
3) GROUPING SETS 함수
- GROUPING SETS에 표시된 인수들에 대한 개별 집계를 구할 수 있음
- 평등한 관계이므로 인수의 순서가 바뀌어도 결과는 같음
