
아직 많이 부족하지만 실전을 통해 체득한 지식과 노하우를 기록해보려고 합니다. 잘못된 내용이 있다면 지적도 부탁드립니다! 🤚
이번 포스팅의 목적 ✍️
바야흐로 MLOps 시대입니다. MLOps 안에서도 AutoML 프레임워크가 상당히 추상화되었을 뿐만 아니라 예측 성능도 많이 좋아진 것 같습니다. 그래서 파라미터 튜닝이나 모델 성능 비교를 위한 코드 개발에 많은 시간을 들이지 않아도 되는 시점에 도래한 것 아닌가 생각해봅니다. 이제는 알고리즘의 이해는 기본이고 프레임워크도 잘 다룰 줄 알아야 하는 게 기본 역량이 되어가고 있습니다.
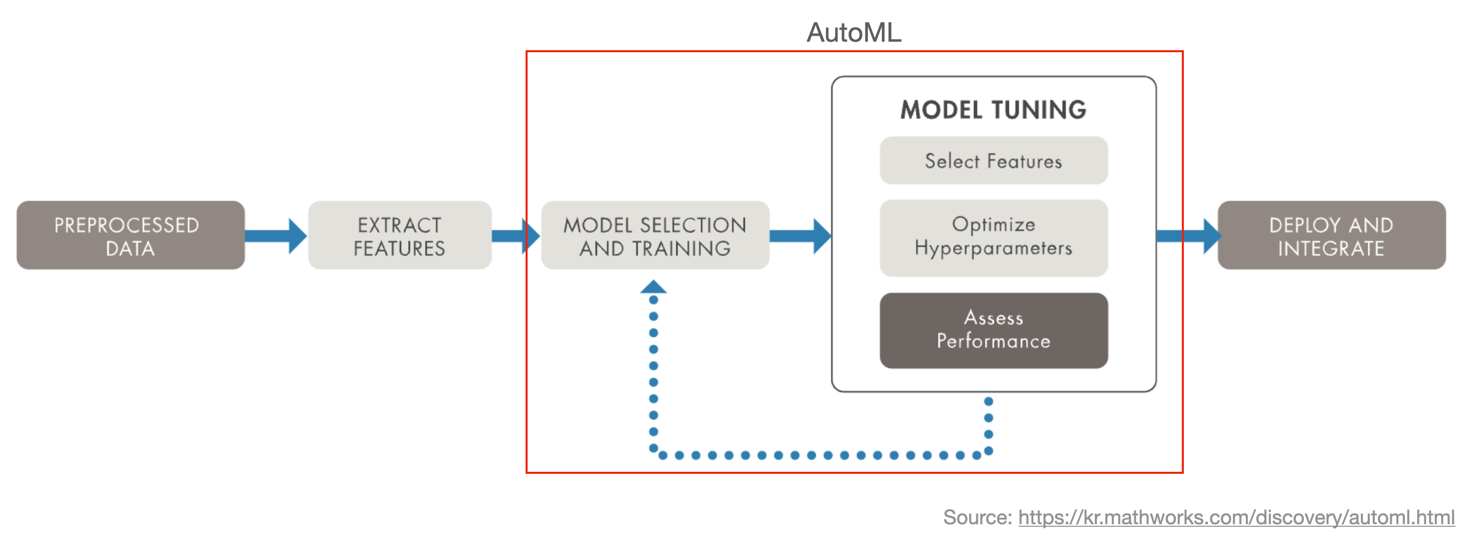
AI 생태계를 이끌어가는 데에는 고도화된 오픈 소스가 한몫하고 있지만 '작고 귀여운 수준일지언정 직접 비슷하게라도 만들어 보자'라는 마음이 아직 한편에 남아 있습니다. ML 알고리즘을 저수준(low level) 코드로 하나씩 직접 개발하는 것은 상당히 도전적인 일이지만, 라이브러리를 적절히 활용한다면 AutoML 비스름하게 만들어 볼 순 있습니다. (그저 객기에 불과할지도..🥲)
AutoML의 목표는 모델 최적화를 위한 반복적인 과정을 자동화하는 것인데, 이 파이프라인을 당장 자동화하긴 어렵다면 적어도 모델별 성능과 Feature Selection을 위한 정보를 간편하게 확인할 수 있는 장치가 필요했습니다. 그래서 이번 포스팅에서는 언젠간 써먹겠지라는 생각으로 만들어 두고 혼자 업무에만 사용하고 있던 기능을 간단히 정리해 봤습니다. 바로 분류 알고리즘 성능 비교 및 하이퍼파라미터 튜닝 모듈입니다.
이런 걸 만들었습니다
AutoML에 필요한 과정을 아래의 단계로 구분했고, 각각에 필요한 함수를 구현했습니다. 이 흐름을 자동화해준다면 AutoML 일 것이지만, 여기서는 직접 실행하면서 Best 모델을 찾아가는 방법을 시도해 봤습니다. (아니 밑장빼기도 아니고 Auto ML이라 했다가 Manual ML로 급선회..)
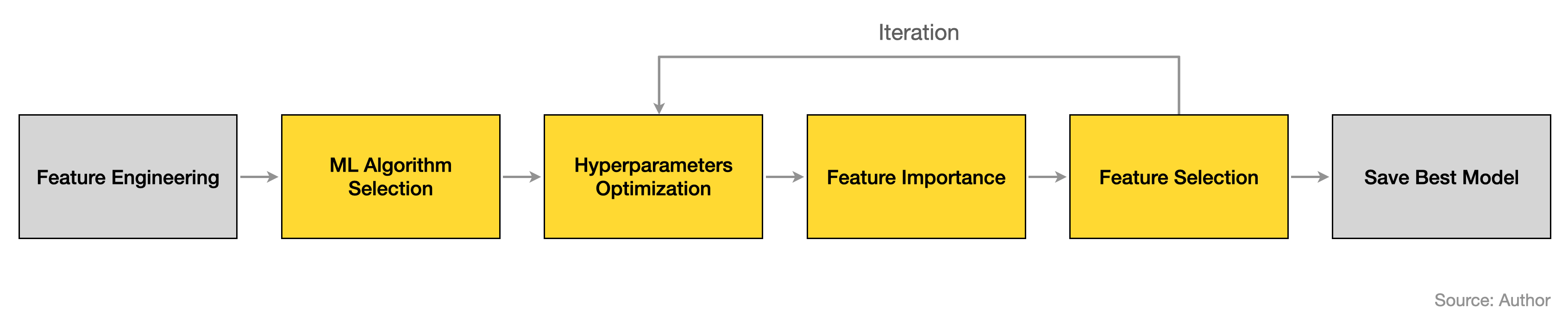
밑에서 다시 자세히 소개하겠지만 모듈에서 각 역할을 수행하는 기능을 나열해 보면 대략 아래와 같습니다.
- 교차 검증 (Cross Validation)
- 교차 검증 결과 시각화
- 하이퍼파라미터 튜닝 (Hyperparameter optimization)
- 하이퍼파라미터 튜닝 결과 시각화
- Feature Importance 시각화
- Permutation Importance 시각화
- Best Model 저장
- (Optional) Deicision Tree 시각화 등
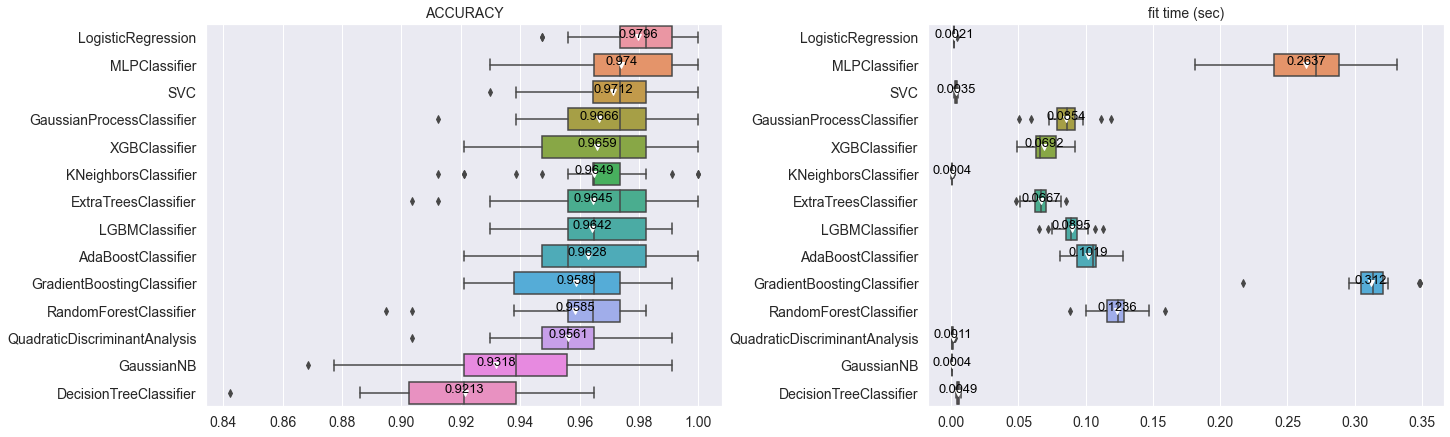
예를 들면 알고리즘별 예측 성능과 수행 시간을 한눈에 비교해 볼 수 있습니다. 여기서 Y 축을 보면 비교하고 있는 알고리즘이 꽤 많은데, '굳이 자주 사용하지 않는 것까지 비교를 해야 하나?' 싶은 생각이 충분히 들 수 있습니다. 당연히 저렇게 많은 알고리즘을 매번 비교하는 건 무리지만, 이 글에서는 단순히 예시를 위해 많이 비교해 봤습니다. (좀 풍부하니까 있어보여서..😂)
마치 거창한 것을 만든 것처럼 얘기했지만 sklearn, xgboost, lightgbm를 활용하여 열심히 조립(?)해서 함수를 만든 것뿐입니다. 헤헤. 에.. 막상 쓰고 보니 제가 봐도 별로인 것 같기도 하고.. (글 망한듯..?)

모듈 소개
코드는 여기에서 확인하실 수 있습니다. 약간의 스압에 주의해주세요! 😋
교차 검증 실행 부분만 보자면 아주 간단합니다. 훈련에 사용할 데이터와 예측하려는 타깃(Y), 그리고 원하는 알고리즘을 지정하여 예측 결과를 비교하도록 설계했습니다. 다른 기능들도 마찬가지로 이런 형태입니다. 즉, 모델 튜닝에 필요한 옵션을 자유롭게 선택만 하도록 의도한 것이라 보면 되겠습니다.
from ml_classifiers import Classifiers
# 객체 생성 (Feature Scaler 지정 가능)
clf = Classifiers(feature_scaler="RobustScaler")
# 알고리즘별 교차검증 실행
clf.run_cross_validation(
estimators=[
"AdaBoostClassifier",
"DecisionTreeClassifier",
"ExtraTreesClassifier",
"GaussianNB",
"GaussianProcessClassifier",
"GaussianProcessClassifier",
"GradientBoostingClassifier",
"KNeighborsClassifier",
"LGBMClassifier",
"LogisticRegression",
"MLPClassifier",
"QuadraticDiscriminantAnalysis",
"RandomForestClassifier",
"SVC",
"XGBClassifier",
]
X=X_train,
y=y_train,
target="target", # 예측할 타겟 변수 컬럼
kfold="KFold", # train, test 분할 방법
n_splits=5, # K-Fold의 K 값
scoring="accuracy", # 모델 성능 지표
)
# 알고리즘별 성능
clf.show_cross_validation_result()사용 예시 💻
여기서 부터는 주피터 노트북에서도 확인할 수 있지만, 좀 더 가벼운 버전으로 적어봤습니다.
Dataset
Scikit-learn에서 제공하는 기본 데이터셋으로, 이진 분류에 자주 사용하는 샘플입니다.
from sklearn.datasets import load_breast_cancer
breast_cancer = load_breast_cancer()
df_breast_cancer = pd.DataFrame(
breast_cancer["data"], columns=breast_cancer["feature_names"]
)
df_breast_cancer["label"] = breast_cancer["target"]
df_breast_cancer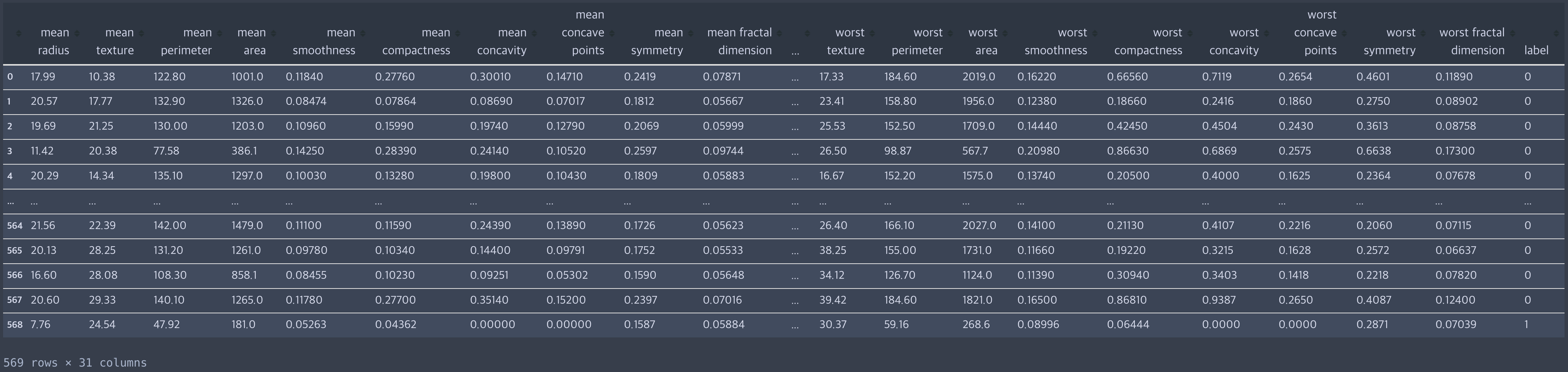
X_train = df_breast_cancer.iloc[:, :-1]
y_train = df_breast_cancer.iloc[:, -1]
feature_names = X_train.columnsPreparation
따로 개발한 모듈을 호출하여 객체를 먼저 생성합니다. 이때 Feature Scaler(StandardScaler, MinMaxScaler, RobustScaler, MaxAbsScaler, Normalizer)를 지정할 수 있습니다. 만약 이 외에 다른 표준화 방법을 적용하려면 데이터에 이미 적용이 되어 있음을 가정합니다.
from ml_classifier import Classifiers
clf = Classifiers(feature_scaler="RobustScaler")Algorithms
모듈에서 사용할 수 있는 알고리즘입니다. 여기에 나온 알고리즘을 한꺼번에 비교하는 건 시간 소요도 크므로 그다지 좋은 방법은 아닙니다. 특히 GradientBoostingClassifier은 시간이 굉장히 오래 걸리는 편이라 실제 사례에서도 많이 사용하는 편은 아니기도 합니다.
원래 의도는 3~4개 알고리즘의 예측 성능과 수행 시간을 수시로 비교하여 최적의 모델을 선택하는 것입니다. 이 중에서 주로 사용하는 알고리즘은 RF, XGB, LGBM 정도입니다. 캐글(Kaggle)에서도 이 세 가지는 자주 사용하는 것을 확인할 수 있고, Decision Tree는 일종의 base model로 여겨지는 경향도 있어서 같이 사용하곤 합니다. 만약 이 외에 추가할 알고리즘이 있다면 모듈을 수정하여 사용할 수 있습니다.
list(clf._get_classifier_models())['AdaBoostClassifier',
'DecisionTreeClassifier',
'ExtraTreesClassifier',
'GaussianNB',
'GaussianProcessClassifier',
'GradientBoostingClassifier',
'KNeighborsClassifier',
'LGBMClassifier',
'LogisticRegression',
'MLPClassifier',
'QuadraticDiscriminantAnalysis',
'RandomForestClassifier',
'SVC',
'XGBClassifier']Cross Validation
이제 위에서 확인한 알고리즘을 통해 교차 검증을 수행할 수 있습니다. 교차 검증은 반드시 필요한 부분이 아닐 순 있지만, 분류 모델을 만들기에 앞서 몇 개의 알고리즘을 선택하여 대략적인 성능을 비교해 보고 싶을 수 있습니다.
만약 하이퍼파라미터 탐색을 여러 개의 알고리즘으로 시도한다면 많은 시간이 필요한데, 저는 먼저 CV를 통해 성능을 비교하여 선택의 폭을 줄여나갈 수 있는 결과가 있으면 좋을 것 같았습니다. 그래서 알고리즘별 파라미터를 직접 지정하거나 혹은 디폴트 값을 그대로 사용하여 대략적인 성능을 보고, 1~2개 알고리즘을 선택하여 하이퍼파라미터 탐색을 시도하기 위해 만든 기능입니다.
# 알고리즘별 하이퍼파라미터 지정 (만약 사용하지 않는다면 디폴트 파라미터로 예측을 수행합니다.)
estimator_fit_params = {
"DecisionTreeClassifier": {
"criterion": "entropy",
"splitter": "random",
"max_depth": 100,
"min_samples_split": 3,
"min_samples_leaf": 3,
"max_features": "sqrt",
},
"RandomForestClassifier": {
"n_estimators": 100,
"criterion": "entropy",
"max_depth": 10,
"min_samples_split": 3,
"min_samples_leaf": 3,
"max_features": "sqrt",
"bootstrap": True,
},
}
# 교차 검증 실행
estimators = [
"DecisionTreeClassifier",
"RandomForestClassifier",
"XGBClassifier",
"LGBMClassifier",
]
scoring = ["accuracy", "recall", "precision", "f1", "roc_auc"]
# 교차 검증 실행
clf.run_cross_validation(
X=X_train,
y=y_train,
estimators=estimators, # 예측 알고리즘
estimator_params=estimator_params, # 알고리즘별 파라미터
scoring=scoring, # 모델 성능 지표
kfold="RepeatedStratifiedKFold", # 훈련, 검증 데이터 분할 방법
n_splits=5, # K-Fold의 K
n_repeats=5, # 교차 검증 반복 횟수
)
# 교차 검증 결과 시각화
clf.show_cross_validation_result()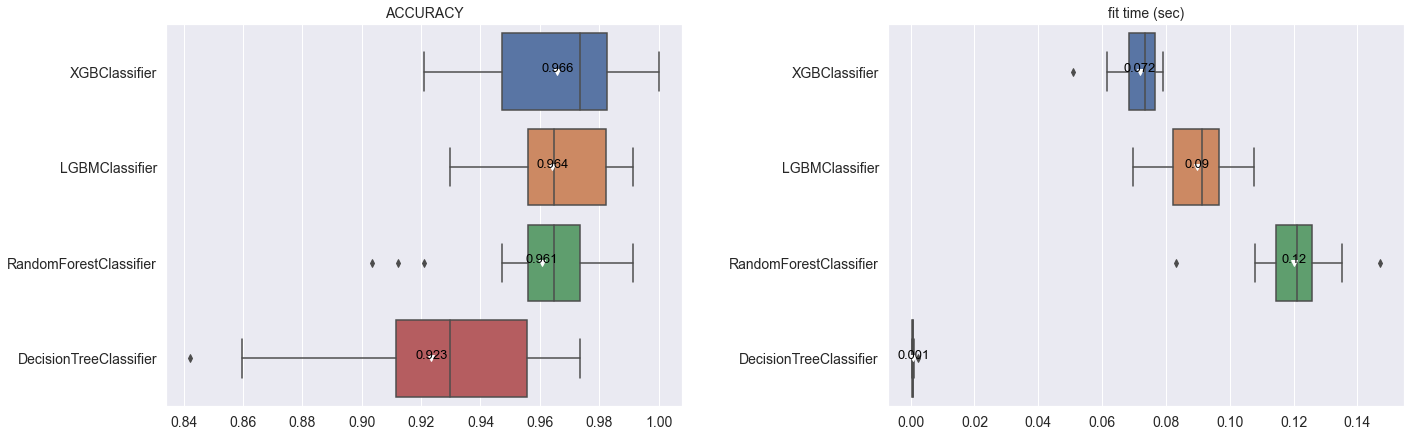
(F1-score, Precision, Recall, ROC-AUC 결과는 생략)
필요하다면 교차 검증 결과도 따로 확인할 수 있습니다.
clf.df_cv_result
Hyperparameters Optimization
교차 검증을 통해 알고리즘 후보군을 좁혔다면 해당 알고리즘별 하이퍼파라미터 튜닝을 통해 성능을 확인하는 단계로 넘어갑니다. 하이퍼파리미터 튜닝은 여러 방법이 있지만, 여기서는 Scikit-learn에서 제공하는 하이퍼파라미터 탐색 방법(GridSearchCV, RandomizedSearchCV, HalvingGridSearchCV, HalvingRandomSearchCV)을 선택할 수 있도록 개발했습니다.
# 알고리즘별 하이퍼파라미터 범위 지정
import numpy as np
hyperparams_space = {
"DecisionTreeClassifier": {
"criterion": ["gini", "entropy"],
"splitter": ["best", "random"],
"max_depth": np.arange(5, 105, 5).astype(int),
"min_samples_split": np.arange(2, 11).astype(int),
"min_samples_leaf": np.arange(2, 11).astype(int),
"max_features": ["sqrt", "log2"],
},
"RandomForestClassifier": {
"n_estimators": np.linspace(100, 1000, 10).astype(int),
"criterion": ["gini", "entropy"],
"max_depth": np.arange(5, 105, 5).astype(int),
"min_samples_split": np.arange(2, 11).astype(int),
"min_samples_leaf": np.arange(2, 11).astype(int),
"max_features": ["sqrt", "log2"],
"bootstrap": [True, False],
},
"XGBClassifier": {
"n_estimators": np.linspace(100, 1000, 10).astype(int),
"learning_rate": np.arange(0.001, 0.1, 0.01),
"max_depth": np.arange(5, 105, 5).astype(int),
"colsample_bytree": sp_uniform(loc=0.4, scale=0.6),
"colsample_bytree": [0.5],
"gamma": [i / 10.0 for i in range(3)],
"fit_params": {"verbose": False},
"eval_metric": ["logloss"],
"early_stopping_rounds": [100],
},
"LGBMClassifier": {
"n_estimators": np.linspace(100, 1000, 10).astype(int),
"learning_rate": np.arange(0.001, 0.1, 0.01),
"max_depth": np.arange(5, 105, 5).astype(int),
"colsample_bytree": [0.5],
"verbose": [-1],
"fit_params": {
"eval_metric": ["binary_logloss"],
"callbacks": [early_stopping(100)],
},
},
}
# 하이퍼파라미터 탐색 실행
clf.search_hyperparameter(
X=X_train,
y=y_train,
search_method="random", # 하이퍼파라미터 탐색 방법 (grid, random, grid_halving, random_halving)
hyperparams_space=hyperparams_space, # 알고리즘별 하이퍼파라미터 범위
scoring="roc_auc", # 모델 성능 지표
kfold="RepeatedStratifiedKFold", # 훈련, 검증 데이터 분할 방법
n_splits=5, # K-Fold의 K
n_repeats=5, # 교차 검증 반복 횟수
# n_iter=10, # 파라미터 조합 수
# factor=3, # 파라미터 선택 수 (`search_method`가 `*_havling`일 때만 적용)
)
# 탐색 결과 시각화
clf.show_hyperparameter_search_result()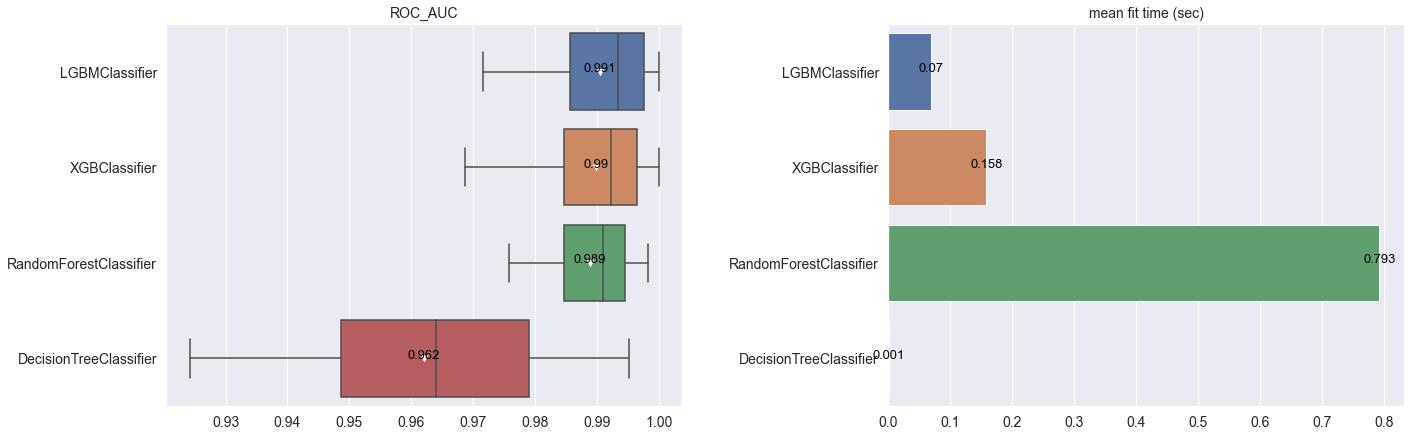
하이퍼파라미터 탐색을 끝내면 다음과 같은 로직을 통해 최적의 모델을 반환하도록 구현했는데, 아래의 코드로 모델의 성능과 파라미터를 조회해 볼 수 있습니다.
- 검증 데이터의 분류 성능(
mean_test_score)이 가장 높은 모델 - 만약 동점의 모델이 있을 경우 검증 데이터의 분류 성능 표준편차(
std_test_score)가 낮은 모델 - 두 번째에서도 동점이라면 모델 적합 시간(
mean_fit_time)이 가장 짧은 모델
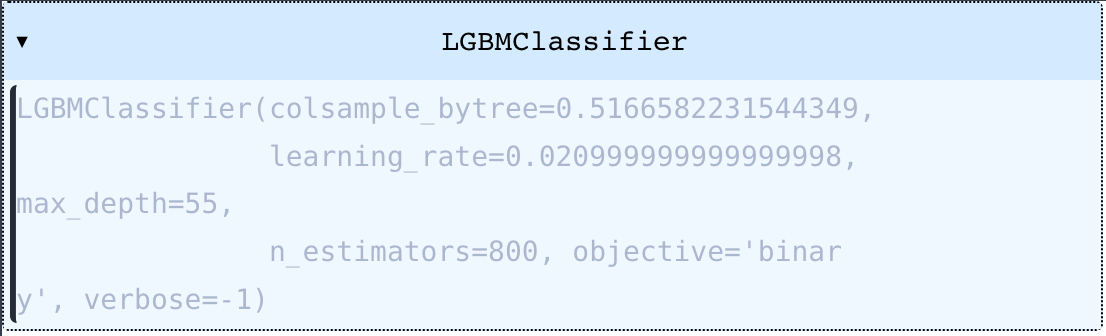
clf.get_best_model_info()
{'mean_test_score': 0.9906190645773979,
'std_test_score': 0.01117774544765023,
'mean_fit_time': 0.2448660612106323,
'estimator_name': 'LGBMClassifier',
'params': {'colsample_bytree': 0.5166582231544349,
'learning_rate': 0.020999999999999998,
'max_depth': 55,
'n_estimators': 800,
'objective': 'binary',
'verbose': -1}}위의 로직으로 반환된 최종 모델을 출력해 보면 다음과 같이 나타납니다. 만약 여기에서 끝낸다면 이 모델을 저장해놓고 인퍼런스로 사용할 수 있게 됩니다.
clf.get_best_classifier()
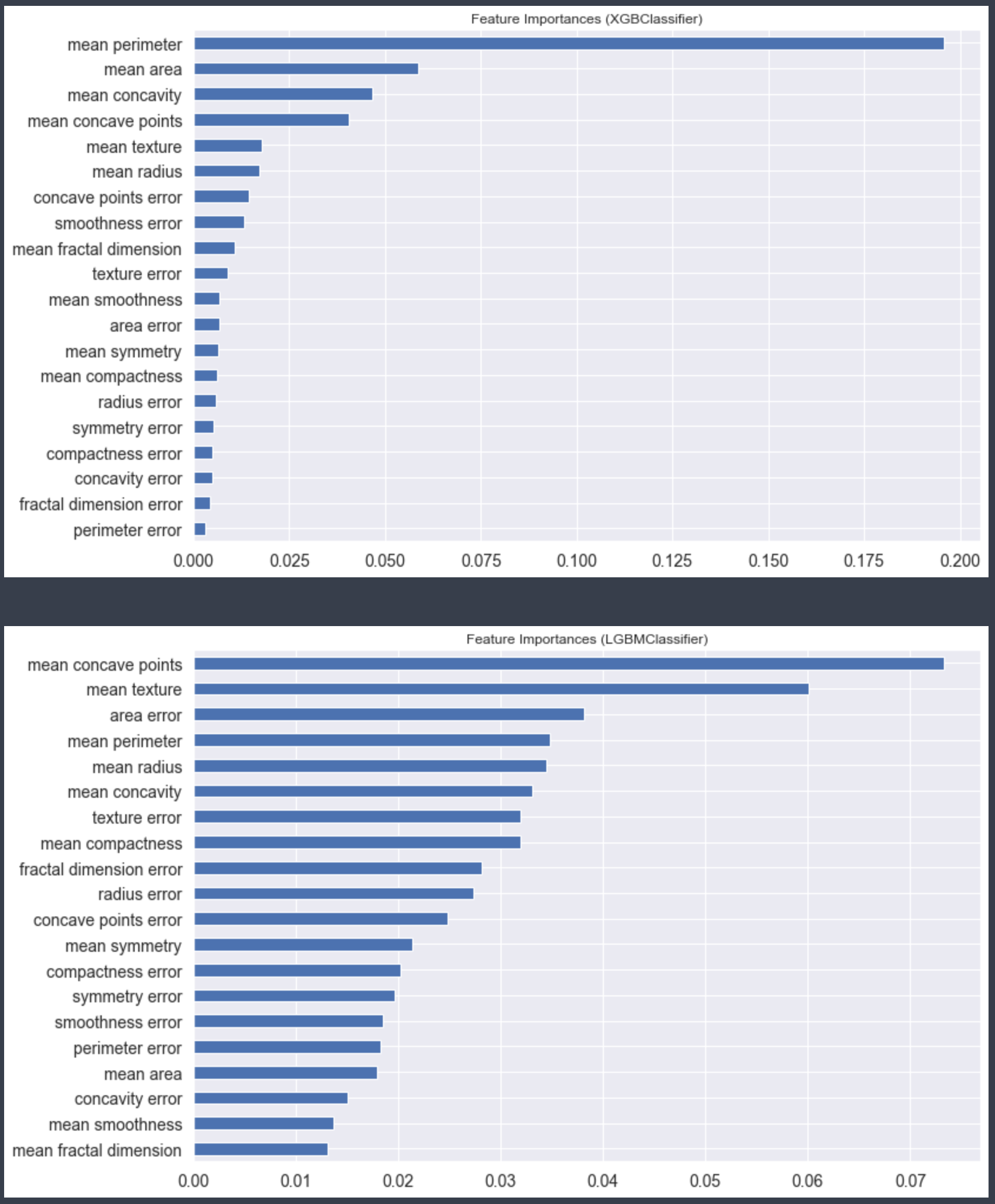
Feature Importance
자, 튜닝까지 끝났으면 Feature Importances를 확인해 봐야죠. 불필요 변수가 있을지, 있다면 제거를 할지 판단해야 합니다. 보통 이쯤되면 여러 개의 알고리즘을 계속 비교하진 않습니다. 거의 한 개의 모델로 추려지는데, 여기에서는 예시로 두 개의 알고리즘별로 Feature Importance를 각각 출력해봤습니다.
# 만약 `estimators`를 지정하지 않는다면 하이퍼파라미터 탐색을 실행한 모든 알고리즘의 Feature Importance가 출력됩니다.
clf.show_feature_importances(
estimators=["XGBClassifier", "LGBMClassifier"], # 알고리즘 선택
n_features=20, # 중요도가 높은 순으로 Feature 개수
)
Permutation Importance
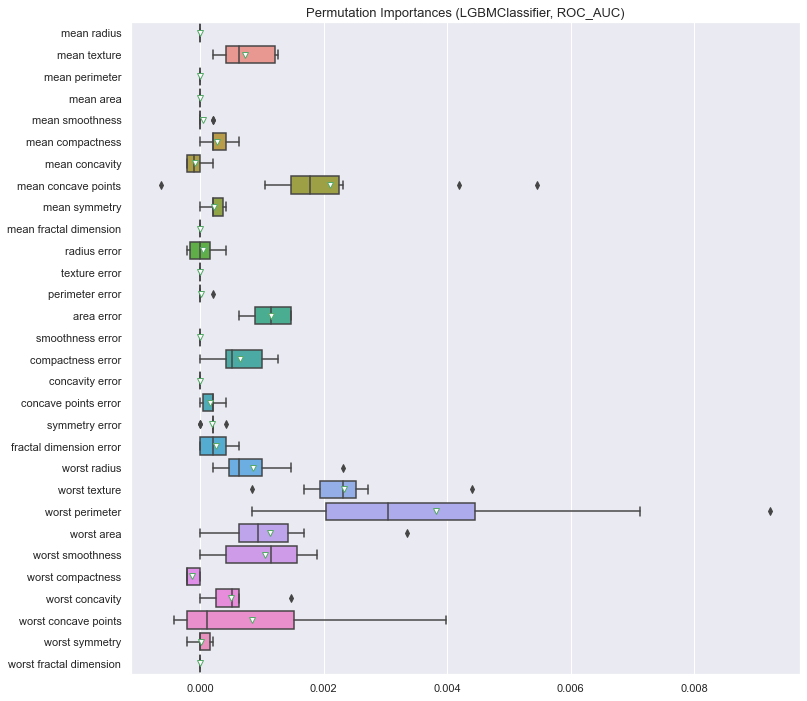
마지막으로 Permutation Importance입니다. 훈련된 모델에서 특정 Feature를 사용하지 않을 때 이것이 성능 하락에 미치는 영향을 파악하는 방법으로, 모델 입장에서의 개별 Feature의 의존도를 확인하는 것입니다. Feature Importance까지만 보고 이것은 안 보는 경우가 종종 있는데, 오히려 이게 도움이 되는 정보라고 생각합니다. 추출 과정은 아래와 같습니다.
- 기존 검증 데이터셋에서 하나의 변수(Feature)를 선택하여 값의 순서를 무작위로 섞은 후 새로운 검증 데이터셋을 생성
- 새로운 검증 데이터셋으로 성능(score)을 측정
- 기존 검증 데이터셋에 의한 성능 대비 새로운 검증 데이터셋에 의한 성능 비교
- 성능 감소 ➡ 해당 변수가 중요하다는 의미
- 성능 큰 변화 없음 ➡ 해당 변수는 그닥 중요하진 않다는 의미
따라서 성능 감소가 없는 변수 발견 시, 해당 변수를 제와한다면 두 가지 효과를 기대할 수 있습니다.
- 모델 성능 개선
- 변수 제거에 따른 추가 리소스 확보 (특히 변수가 상당히 많을 때 유용)
# 모델과 score를 따로 지정할 수 있습니다.
clf.show_permutation_importances(
estimators=["LGBMClassifier"],
X=X_train,
y=y_train,
target="label",
scoring="roc_auc", # or ["f1", "roc_auc"]
)
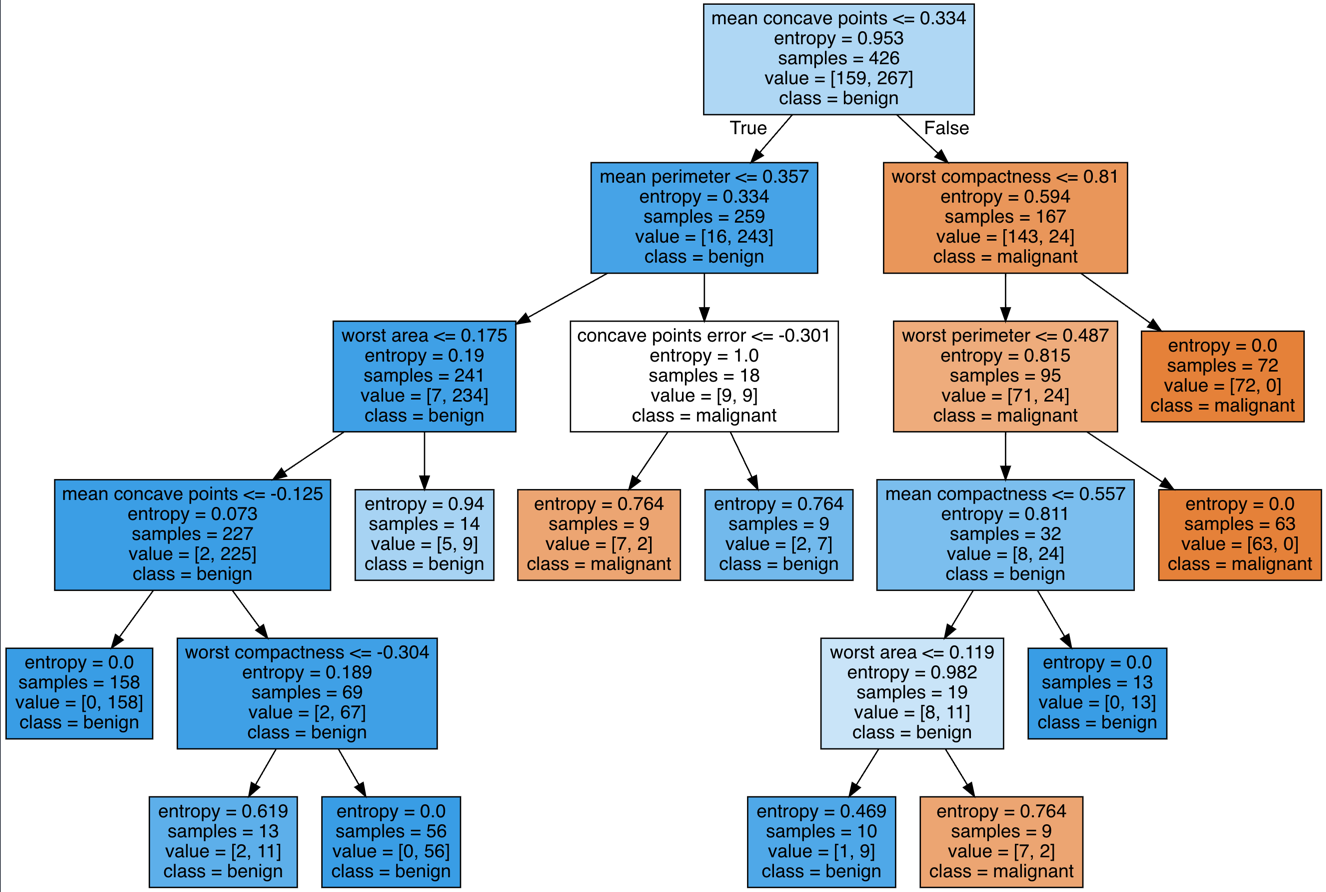
(Appendix) Decision Tree 시각화
중요한 기능은 아니지만 Decision Tree를 튜닝한 경우, 트리 구조를 볼 수 있는 것도 만들어 두었습니다. 의사결정나무는 base model 성능으로 보는 경향도 있기 때문에 일반적으로 많이 사용하는데요, 분류 결과를 시각화할 수 있어서 설명하기 용이한 형태이기에 현업에서도 종종 사용하는 편입니다.
clf.show_decision_tree(
feature_names=df_breast_cancer.columns[:-1], # DT 모델에 적용한 Feature
class_names=breast_cancer.target_names # Target 변수의 클래스(Label) Unique 값
)
어떻게 활용하면 좋을까 🤔
모델 튜닝, 변수 선택의 반복을 조금이라도 편하게 해보자 이겁니다!
분류 모델을 처음 시도한다면 3대장(LightGBM, XGBoost, RandomForest)과 그리고 Deicision Tree의 성능을 먼저 확인해 보면 좋은 것 같습니다. 그러면 어떤 알고리즘을 최종으로 사용할만할지, 그리고 어떤 파라미터를 튜닝하면 좋을지 대략 '감'이 잡히는 것 같습니다. 그래서 예시에서도 네 가지 알고리즘을 사용하여 비교했던 것이기도 합니다.
그 이후 하이퍼파라미터 튜닝과 변수 선택을 몇 번 반복하다 보면 그 상황에 맞는 최적의 모형을 도출할 수 있을 것이라 기대합니다. 개인적인 의견으로는 이 글에서 제시한 단계를 모두 거쳤다면 어느 정도 괜찮은 모델이 나오는 편입니다. 저 역시 이렇게 활용하고 있고요! 단지, 이것을 자동화하지 못해 슬펐을 뿐(...) 이 과정 덕택에 분류 문제 해결을 위한 노하우도 약간은 생긴 것 같습니다.
물론 여기에서 제공하는 알고리즘 보다 더 나은 방법은 항상 존재합니다. 그래서 저는 분류 모델을 만들 때 이 글에서 제시한 방법으로 먼저 시도해 보고, 이후에 딥러닝을 사용하여 업그레이드 하는 편입니다. 근데 솔직히 이제는 다 딥러닝으로 시작해도 괜찮은 것 같습니다. 😅
(아 그래서 Kaggle 몇 점이냐고요?.. 혼자 있고 싶네요..)

추가로 개발할 기능
아직 개발한 것은 아니지만 추가로 있으면 좋을 법한 기능을 나열해 봤습니다.
- 하이퍼파라미터 탐색 방법에
hyperopt,optuna를 사용할 수 있도록 추가 - Feature Importance, Permutation Importance 결과로부터 Feature Selection 자동화 함수 추가
마무리 ⌛️
예측 모형을 만들 때 때마다 느끼는 것이지만 하이퍼파라미터 탐색의 범위는 데이터 분석가나 데이터 과학자가 직접 정의하는 편이 많습니다. 저는 이것을 염두에 두고 모델링 할 때 약간의 편의성을 도모하고자 만들어 봤습니다. 쓰고 보니 AutoML까진 전혀 아니었지만(..) 모델 훈련, 변수 선택의 반복적인 과정을 쉽게 할 수 있는 기능이 있으면 좋겠다는 가벼운 호기심에서 출발한 게 이렇게 되었네요. (이런 호기심은 이제 그만 가지겠습니다..)
요즘 MLOps에 계속 관심을 갖고 있다 보니 이런 것(?)을 만드는 게 즐겁습니다. 그래봐야 머신러닝 라이브러리를 오픈 소스로 만들어 주신 훌륭한 분들 덕택에 저도 레고 조립하듯 가져다 쓴 것이지만요.😛 그래도 토이 프로젝트 처럼 나름 심도 있게 기능을 개발하고자 노력했기 때문에 정리를 하고 보니 약간의 뿌듯함이 있네요. 물론 여전히 리팩토링할 게 많고, 추가해야 할 것도 많으니.. 저는 부족한 부분을 더 채워서 AutoML의 A까지는 따라한다고 볼법한 기능으로 무장하여 다시 돌아오겠읍니다!


코드 잘 사용해보겠습니다!!!
(Regressor version도 기대할게요)