
상관계수
포트폴리오를 어떤 종목으로 구성할까?
이전 포스팅에서 포트폴리오를 구성해서 리벨런싱을 할 경우 벤치마크보다 안정성도 좋으면서 수익률까지 좋아지는것을 확인하였다.
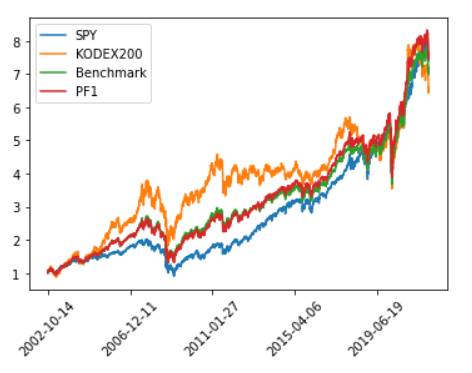
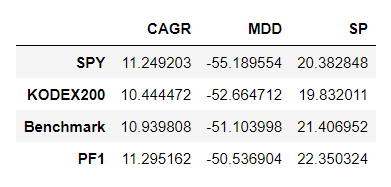
리벨런싱은 상대적으로 많이 오른자산을 일부 팔아서 상대적으로 저평가된 자산을 지속적으로 살 수 있다. 그로 인해 지속적인 알파를 창출하는것이 목표이다.
위 개념을 잘 생각해보면 비슷하게 오르고 내리는 두 종목을 리벨런싱하면 효과가 별로 없음을 알 수 있다. 떨어질때 같이 떨어지고 오를때 같이 오르면 고가매도 저가매수의 장점이 없어지기 때문이다.
그렇기 때문에 2종목을 포트폴리오로 구성할 경우 리벨런싱의 효과를 극대화 하기 위해서는 낙폭(DrawDown)의 시점이 서로 달라야한다. 즉, 서로 비슷하게 움직이는것보다 반대로 움직이는 두 종목을 리벨런싱 해야 수익이 높아진다.(장기적으로 두 종목다 올랐다는 전제하에)
안비슷하게 오르는 종목 고르기
예제로는 아래와 같이 사람들이 대표적으로 생각하는 자산군의 ETF 등을 사용한다.
- SPY: 미국 SNP500 ETF
- KODEX200: 한국 KOSPI 200 ETF
- USO: 원유 선물 ETF
- SGOL: 금 선물 ETF
- USDKRW: 환율
2016.05 ~ 2019.05 3년간 차트 비교
import pandas as pd
# sql = """
# SELECT
# A.TICKER
# ,A.DATE
# ,A.ADJ_CLOSE PRICE
# FROM
# DAILY_CHART A
# WHERE
# A.TICKER IN ('SPY', 'KRX.069500', 'USDKRW', 'USO', 'SGOL')
# AND A.DATE BETWEEN '20020101' AND '20220131'
# """
# cur.execute(sql)
# data = cur.fetchall()
# pd.DataFrame(data).set_index(['TICKER', 'DATE']).to_csv('05_cc_01.csv')
df = pd.read_csv('05_cc_01.csv').set_index(['TICKER', 'DATE'])
data = {
'SPY': df.loc['SPY', :]['PRICE'],
'KODEX200': df.loc['KRX.069500', :]['PRICE'],
'USO': df.loc['USO', :]['PRICE'],
'SGOL': df.loc['SGOL', :]['PRICE'],
'USDKRW': df.loc['USDKRW', :]['PRICE']
}
chart = pd.DataFrame(data)
# 빈값은 앞의 값으로 채운다.(특정 나라에만 공휴일로 휴장일 경우), 앞의값이 없는경우 해당날짜 제외
chart = chart.fillna(method='ffill').loc[
chart['SPY'].notnull() &
chart['KODEX200'].notnull() &
chart['USO'].notnull() &
chart['SGOL'].notnull() &
chart['USDKRW'].notnull()
]
chart1 = chart['2016-05-01':'2019-05-01'] # 2021년 이후부터
chart1 = chart1 / chart1.iloc[0] # 기준가 1로 동일화
chart1.plot(rot=45)
cagr1 = (chart1.iloc[-1]/chart1.iloc[0]).pow(1/(2019 - 2016)) - 1
mdd1 = ((chart1 - chart1.cummax()) / chart1.cummax()).min()
sp1 = -cagr1/mdd1
print('단위(%)')
table1 = pd.DataFrame.from_dict(cagr1.to_dict(), orient='index', columns=['CAGR']) * 100
table1['MDD'] = mdd1 * 100
table1['SP'] = sp1 * 100
table1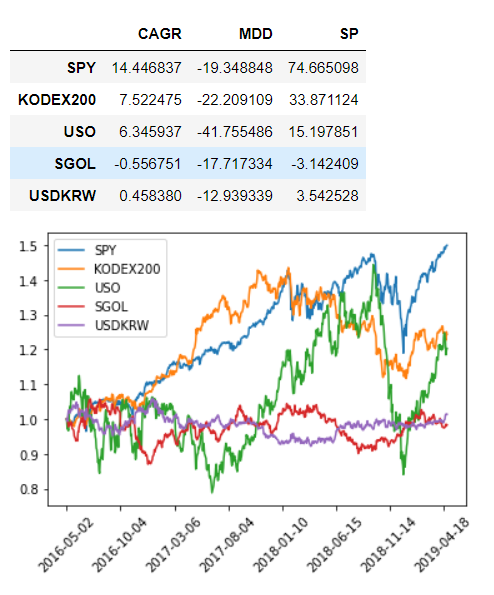
눈으로 대충 보았을때 전반적으로 환율이 내리면 KOSPI200과 금이 오르고 환율이 오르면 KOSPI200과 금이 내리는것 같다.
우리가 2019년 5월에 해당 과거 차트를 보고 안비슷한 자산인 달러와 KOSPI200 또는 달러와 금을 포트폴리오로 구성하면 효과가 좋을 것이라 추측할 수 있다.
과연 그럴까?
2019.05 ~ 2021.05 백테스팅
- BM: 달러 30%, KOSPI200 70%
- PF: BM구성으로 연 2회 리벨런싱
백테스팅 함수 구현
def backtesting(chart, acc, target_ratio, rb_months):
idxs = chart.index
hist = []
info = {'LAST_RB_YYMM': '0000-00'}
st_yy = idxs[0][:4]
ed_yy = idxs[-1][:4]
for i, (date, row) in zip(range(len(chart)), chart.iterrows()):
month = date.split('-')[1]
yymm = "{}-{}".format(date[0], date[1])
eval_amt = {'TOT': 0}
# 최초셋팅
if i == 0:
tot_bid_amt = 0
for ticker, tr in target_ratio.items():
bid_amt = acc['CASH'] * tr / row[ticker]
acc[ticker] = bid_amt
tot_bid_amt += bid_amt
acc['CASH'] -= tot_bid_amt
print(acc)
for ticker, tr in target_ratio.items():
eval_amt[ticker] = acc[ticker] * row[ticker]
eval_amt['TOT'] += eval_amt[ticker]
# print(row[ticker], acc[ticker])
eval_amt['TOT'] += acc['CASH']
# 리벨런싱
if month in rb_months:
if info['LAST_RB_YYMM'] != yymm:
for ticker, tr in target_ratio.items():
target_amt = eval_amt['TOT'] * tr
diff_amt = target_amt - eval_amt[ticker]
diff_qty = diff_amt / row[ticker]
acc[ticker] += diff_qty
# 리벨런싱 후 평가금 재산정
eval_amt['TOT'] = 0
for ticker, tr in target_ratio.items():
eval_amt[ticker] = acc[ticker] * row[ticker]
eval_amt['TOT'] += eval_amt[ticker]
# print(row[ticker], acc[ticker])
eval_amt['TOT'] += acc['CASH']
# print(eval_amt)
# 평가금 기록
# print(acc)
hist.append({'DATE': date, 'PF1': eval_amt['TOT']})
pf1 = pd.DataFrame(hist).set_index('DATE')
print(acc)
# print(hist)
c = chart.copy()
c['BM'] = 0
for ticker, tr in target_ratio.items():
c['BM'] += c[ticker]*target_ratio[ticker]
c['PF1'] = pf1
c = c[['BM', "PF1"]]
cagr = (c.iloc[-1]/c.iloc[0]).pow(1/max(int(ed_yy) - int(st_yy), 1)) - 1
mdd = ((c - c.cummax()) / c.cummax()).min()
sp = -cagr/mdd
table = pd.DataFrame.from_dict(cagr.to_dict(), orient='index', columns=['CAGR']) * 100
table['MDD'] = mdd * 100
table['SP'] = sp * 100
return c, table백테스팅 결과
acc = {'CASH': 1, 'KODEX200': 0, 'USDKRW': 0}
target_ratio = {'KODEX200': 0.7, 'USDKRW': 0.3}
rb_months = ['05', '11']
c, table = backtesting(chart1, acc, target_ratio, rb_months)
c.plot(rot=45)
table{'CASH': 0.0, 'KODEX200': 0.7, 'USDKRW': 0.3}
{'CASH': 0.0, 'KODEX200': 0.6721120387896082, 'USDKRW': 0.34352355442210225}
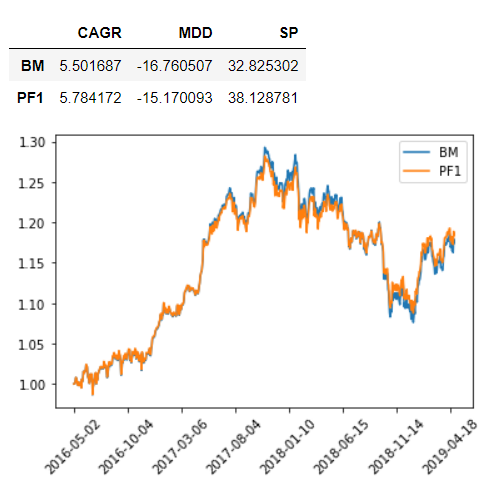
수익률과 MDD 모두 벤치마크 대비 좋은것을 알 수 있다.
하지만 실제 투자에 있어서 여러가지 종목이 있는데 직접 차트를 눈으로 보고 한땀한땀 상관관계가 적어보이는 종목을 고르는 번거로움이 있다. 그리고 눈으로 고르면 우리 뇌의 편향성 때문에 정확하지도 않다.
상관계수
우리는 상관계수라는 아래의 수식을 통해 실제 종목간의 상관성이 얼마나 있는지 알 수 있다.
- : 상관계수는 -1에서 1사이의 값을 가지며
- -1에 가까울수록 서로 반대로 움직이는 경향
- 1에 가까울수록 서로 같은 방향으로 움직이는 경향
- 0이면 두 종목은 아무런 상관관계가 없이 움직인다.
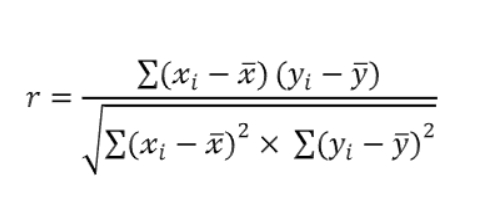
Python Pandas를 이용하여 상관계수 구하기
chart1.corr()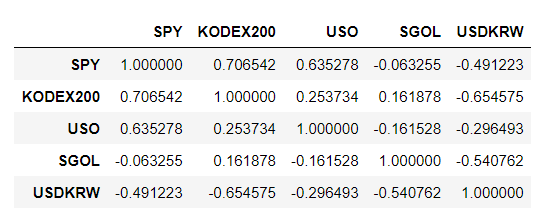
위 상관계수 표를 통하여 우리는 KODEX200과 환율이 해당기간동안 가장 반대방향으로 움직이는 경향이 있음을 알 수 있다.
우리는 해당 상관계수를 활용해서 보다 정교한 포트폴리오를 구성 할 수 있다.
