SegGPT란 ?
Segment everything with a Generalist Painter 의 약자로 Painter 라는 아키텍쳐에 기반으로 image의 semantic 정보를 학습해서 segmentation 을 해주는 모델.
→ GPT(Generative pre-trained Transformer)랑은 관련이 없다.
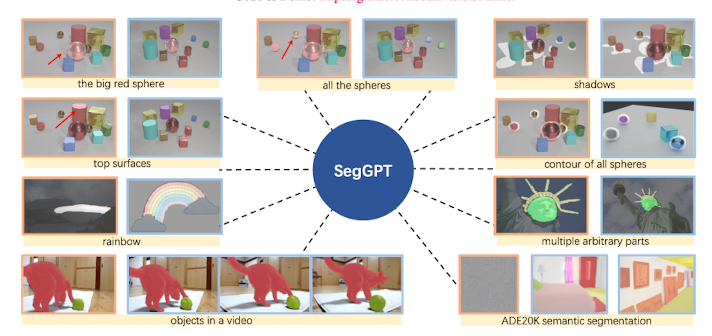
SegGPT는 이런 여러가지 segmentation을 단 하나의 모델로 수행할 수 있다.
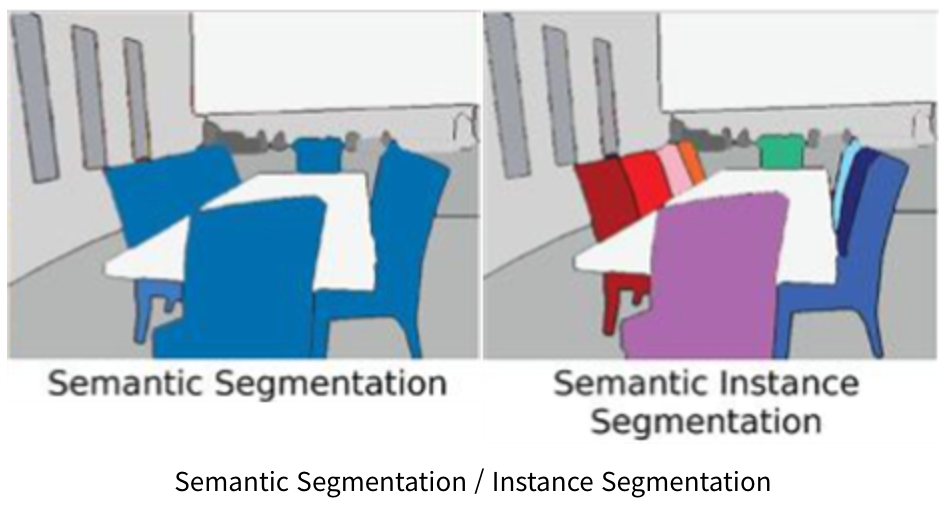
Panoptic Segmentation
Semantic Segmentation과 Instance Segmentation을 합쳐놓은 것.
Smooth L1 loss

기본적으로는 L1 Loss이고 예측값과 실제값에 대해서 차이가 매우 적은 부분에 대해서만 L2 처럼 부드럽게 치환된 것.
L1 Loss 가 L2 Loss 에 비해 Outlier 에 대하여 더 Robust(덜 민감 혹은 둔감) 하다.
Abstract
-
SegGPT는 여러가지 Segmentation Task들의 output을 동일한 format으로 맞추어서 In-context learning framework로 만들었다.
-
In-context learning ?
- in-context learning은 모델이 컨텍스트에 주어진 태스크에 대한 설명이나 예시를 통해 어떤 태스크를 수행해야 하는지를 추론 단계에서 '유추'해내는 것을 의미한다. (논문에서 말하는 in-context는 이것으로 추정)
- Downstream task의 데이터 일부만 사용하고 모델을 업데이트 하지 않는 것
-
Training 이후에는 어떤 임의의 Segmentation도 잘 수행할 수 있게 되었다.
-
평가도 마찬가지로 few-shot semantic segmentation, video object. segmentation, semantic segmentation, panoptic segmentation에 대해서 평가를 진행하였다.
-
in-domain과 out-domain에 대해서 정성/정량적 평가를 진행하였고 높은 능력을 보였다.
-
Introduction
-
지난 몇 년동안 Foreground segmentation, interactive segmentation, semantic segmention, instance segmentation, panoptic segmentation에 대해서 더 높은 정확도와 빠른 알고리즘으로써 매우 큰 진전이 있었다.
-
하지만 이러한 Segmentation모델들은 하나의 Task에 종속되어 있어서 다른 Task를 진행하려고 한다면 다시 Train을 시켜야 했고 매우 큰 라벨링 비용을 필요로 하였고 많은 Segmentation task에 유지를 할 수 없었다.
-
In this work, 한 모델로 위에서 언급한 여러가지 Segmentation을 해결할 수 있도록 training하는 것을 목표로 하였다.
-
Main Challenges은 2개가 있었다.
- 여러 Segmentation Tasks의 data types를 포함하는 것이다.
- e.g. part, semantic, instance, panoptic, person, medical image, aerial image, etc..
- 전통적인 multi-task learning과는 다르게 task definition에 flexible하고 ood에도 handling할 수 있도록 일반화된 training scheme을 디자인 하는 것.
- 여러 Segmentation Tasks의 data types를 포함하는 것이다.
-
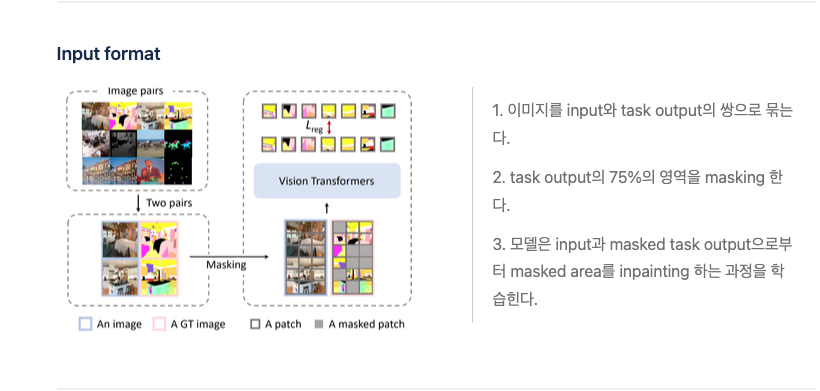
위와 같은 Challenges를 극복하기 위해 SegGPT는 모든 Segmentation data를 same format으로 변환 시켰다.
-
Painter에서 문제가 되었던 고정된 Color를 사용하지 않고 Random Color mask를 사용하였다.
- Painter에서는 라벨마다 고정된 색이 부여되었는데 그러다보니 모델이 contextual information을 학습하는 것이 아닌 색을 학습시켜서 성능이 떨어졌다고 한다.
- 같은 context에 대해서 색을 무작위로 바꿔가면서 모델이 학습하게 하였다.
- 같은 label 값을 가지더라고 이미지에 따라서 다른 색으로 coloring 될 수도 있다.
- 일종의 Augmentation
-
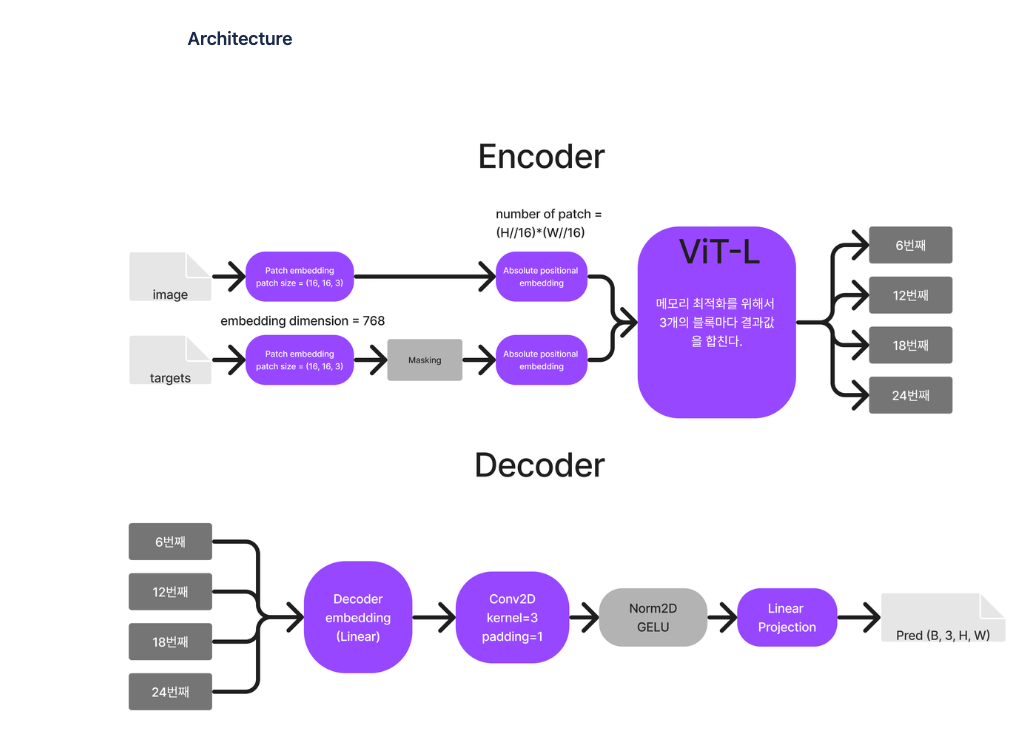
SegGPT는 Painter를 고도화 한 것이기 때문에 Vanilla ViT와 smooth L1 Loss를 사용하였다.
-
one-shot도 가능하지만 few-shot(multi prompt)으로 했을 때 성능을 효과적으로 내기 위해 feature ensemble을 사용
Main Contribution
-
처음으로 다양한 Segmentation을 자동으로 수행할 수 있는 하나의 모델을 만들었다.
- Instance Segmentation인지 Semantic Segmentation인지 등등, 명시해줄 필요 없이 prompt로 파악.
-
fine-tuning없이 다양한 task ( including few shot)로 SegGPT를 실험하였다.
-
정성/정량적으로 SegGPT는 in-domain과 out-domain에서 뛰어난 성능을 보였다.
Related Work
-
Visual Segmentation
- Semantic/Instance/Panoptic Segmentation의 Parent
-
Vision Generalist

-
In-Context Visual Learning
- 위에서 언급했듯이 GPT-3에서 사용되었던 In-Context Learning을 사용
Approach
-
SegGPT는 Painter Framework의 Special version이다.
- Painter도 마찬가지로 image에 mask에 씌운다음 복원하는 방식으로 학습하므로 따로 아키텍쳐에 수정을 할 필요가 없었다.
- 그래서 vanilla Vit와 Smooth L1 Loss를 사용
- 하지만 In-Context learning의 더 좋은 일반화 능력을 위하여 new random colorizing을 사용하였다.
-
Train 때에는 Random Colorizing을 하지만 결국 inference에서는 학습을 바탕으로 유사한 Instance or 카테고리는 같은 색으로 mapping된다.
-
효율적으로 Multiple example(Multiple Prompt Image)를 사용하기 위해서 2가지 ensemble approaches를 제안한다. (Inference Time)
- Spatial Ensemble
- n*n grid로 concat하고 하나의 example에서 동일한 크기를 뽑아 subsample로 사용한다.
- Feature Ensemble
- 독립적으로 수행된 Attention 계산을 하고 나온 features를 평균을 낸다.
- Spatial Ensemble
Experiment