Low-Rank Adaptation
-
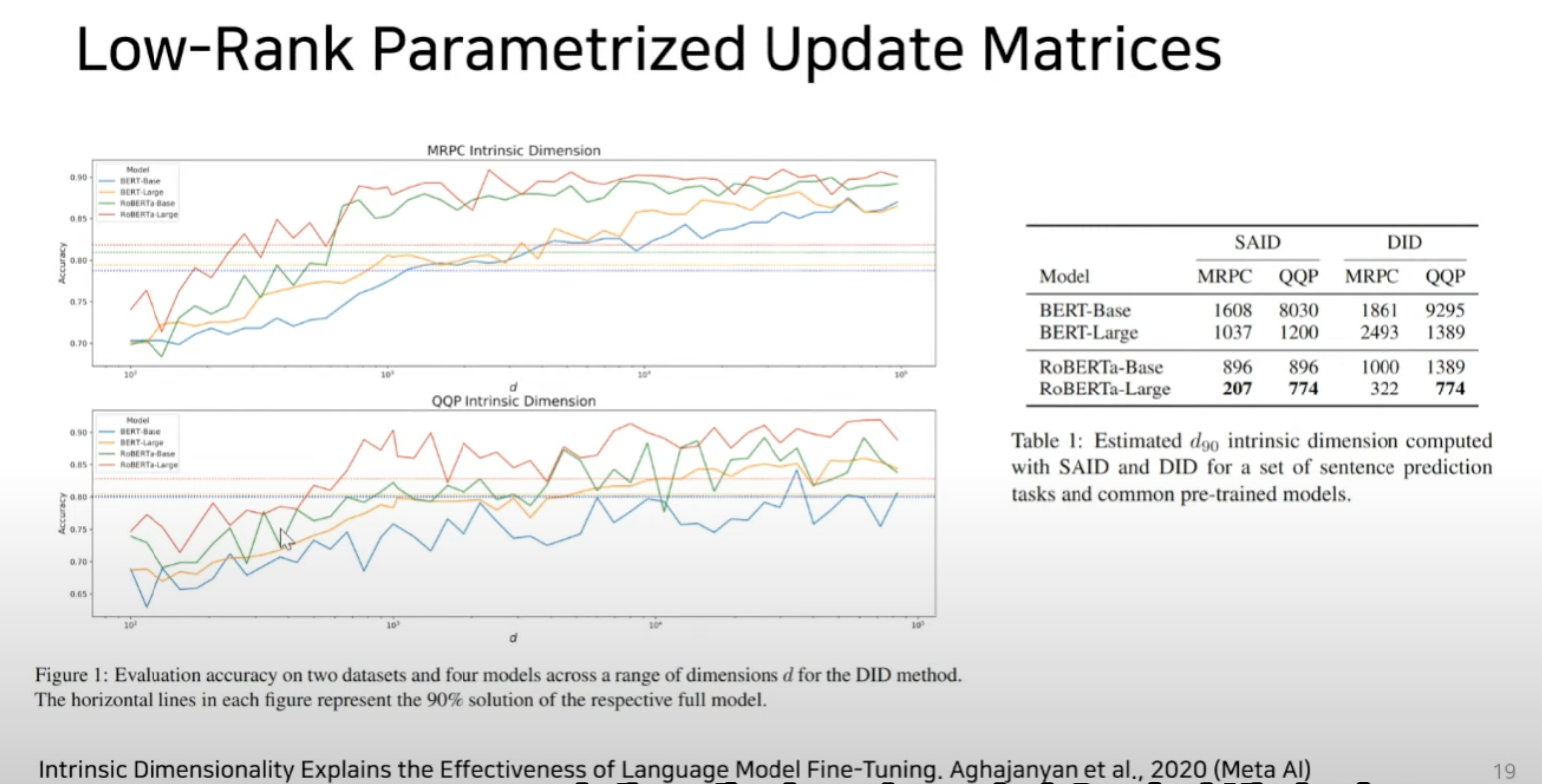
over-parameterized model이 실제로 low intrinsic dimension에 있다는 논문들에 영향을 받음
- low intrinsic dimension = 과연 파라미터 수에 대해 밥값을 하고 있느냐라고 생각하면 됨
-
LoRA를 사용하면
-
Pre-trained weight를 고정된 상태로 유지하면서
-
Adaptation 중 dense layer의 변화에 대한 rank decomposition metrices를 최적화
-
이를 통해 신경망의 일부 dense layer를 간접적으로 훈련 시키는 것이 가능
-
-
LoRa는 trainable parameter의 수가 적고 학습 처리량이 높으며 inference latency(input → output)가 이전 연구 대비 적지만 GPT-2, GPT-3 같은 LLM에서 fine-tuning(fully)보다 같거나 더 나은 성능을 보여줌
Introduction
-
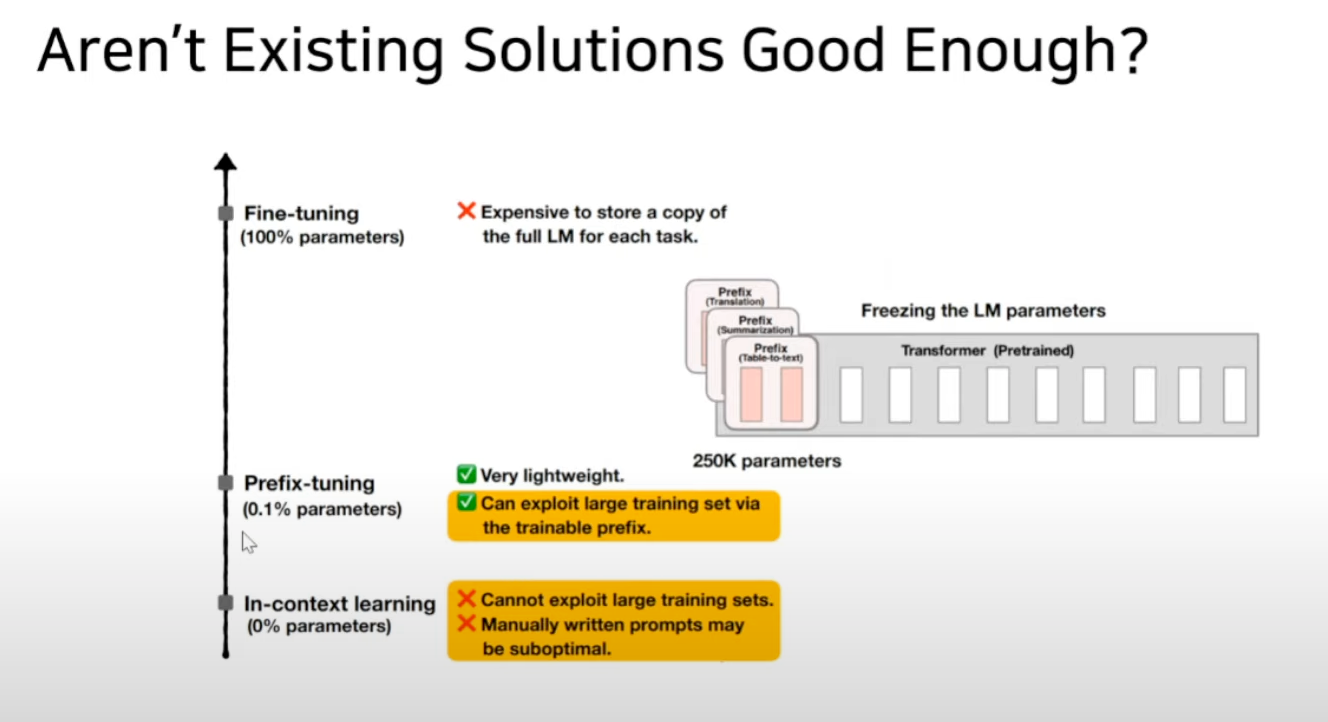
PLM(Pretrained Language Model)은 fine tuning기법을 통해 다양한 task에 적용되어 왔다.
-
하지만 정작 업데이트에 사용되는 파라미터는 극히 일부기 때문에 비효율적으로 자원을 사용하게 된다.
-
Adapter 방법이나 prefix tuning은 inference latency와 model quality같은 문제가 발생하기 때문에 finetuning baseline에 적합하지 않다.
-
본 논문 저자는 over-parameterized model이 실제로 낮은 고유차원에 있음을 보여주는 논문에 영감을 받아 모델 adaptation하는데 가중치의 변화 또한 low intrinsic rank를 가지고 있다고 가정 하고 LoRA를 제안.
-
LoRA는 사전 훈련된 가중치를 고정시키고 Adaptation 동안 dense layer변화의 rank decomposition matrix를 최적화 하여 신경망에서 dense layer를 간접적으로 학습시킴.
-
GPT-3 175B를 예를 들면, 전체 rank(d=12888)가 매우 낮은 rank(r=1 or 2)로 충분하며, 이로써 스토리지와 컴퓨팅 자원의 효율성 또한 높일 수 있음을 보여줌.
-
Adaptation 이란 ? → 새로운 데이터에 대해 조정되거나 적응되는 과정을 의미
-
Benefits
-
Replace LoRA for each downstream task, not finetuning all parameters
사전 학습된 모델은 LoRA 모듈이 서로 다른 task에 빌드하도록 공유되고 사용될 수 있습니다. 사전 학습 모델의 매개변수를 동결시키고 이를 행렬 A와 B로 대체함으로써 스토리지 요구 사항과 작업 전환 오버헤드를 크게 줄일 수 있습니다. -
no store gradient & just optimize low rank decomposition matrice
LoRA는 adaptation 옵티마이저를 사용해서 대부분의 매개변수에 대한 옵티마이저 상태를 유지하거나 그래디언트를 계산할 필요가 없기 때문에 학습을 보다 효율적으로 만들고 진입에 대한 하드웨어 장벽을 최대 3배까지 낮춥니다. 대신 추가된 low-rank 행렬을 최적화시킵니다. -
no inference latency
간단한 선형 구조로 추가적인 inference latency (input이 들어가서 모델이 예측을 하기까지 걸리는 시간)없이 훈련 가능한 행렬을 동결시킨 가중치와 병합할 수 있습니다. -
Combining LoRA with prefix tuning
LoRA는 기존에 존재하는 많은 방식들과 직교하기 때문에 prefix 기반 접근과 함께 사용될 수 있습니다.

- Language Modeling의 경우 Transfer learning의 붐이 시작된 이래로 여러가지 연구들 중에서 크게 두가지 중요한 strategy로 나뉨
-
Add adapter layers
- adapter layer를 각각 레이어에 삽입하는 방법
-
Optimizing some forms to the input layer activations
- p 튜닝 처럼 영감을 받은 prefix튜닝과 같이 input layer activation의 어떤 특정한 폼을 최적화 시키는 기법
Add adapter layer
-
MAM 어댑터
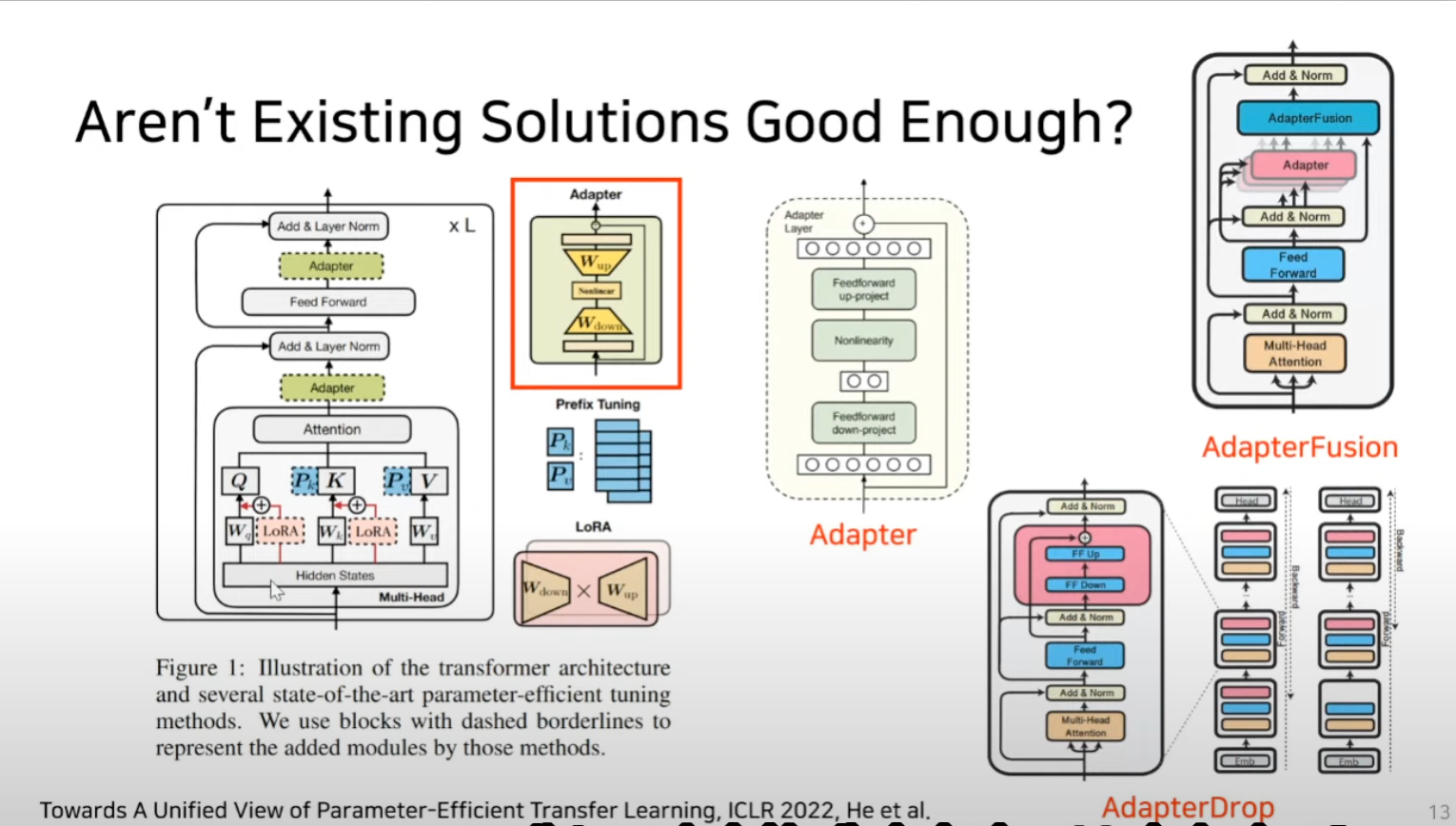
-
Add adapter layer : Feedforward down-projection과 Feedforward up-projection 이 두가지 matrix종류만 새롭게 학습하는 기법을 일컬음
-
문제점
-
multihead attention의 결과값을 받아야 어댑터에서 연산을 할 수 있는데 그렇기 때문에 inference latency가 추가적으로 발생함
- 그렇기 때문에 adapterdrop이라는 기법에서는 layer pruning을 통해서 특정 레이어에만 어댑터를 추가 하거나 adapter fusion같은 논문에서는 멀티태스크세팅을 통해서 이런 latency를 줄이겠다는 기법도 생김.
-
-
-
LoRa이전까지는 구조적인 문제를 붙이는 것은 불가능했다 라고 언급함.
Prefix 튜닝
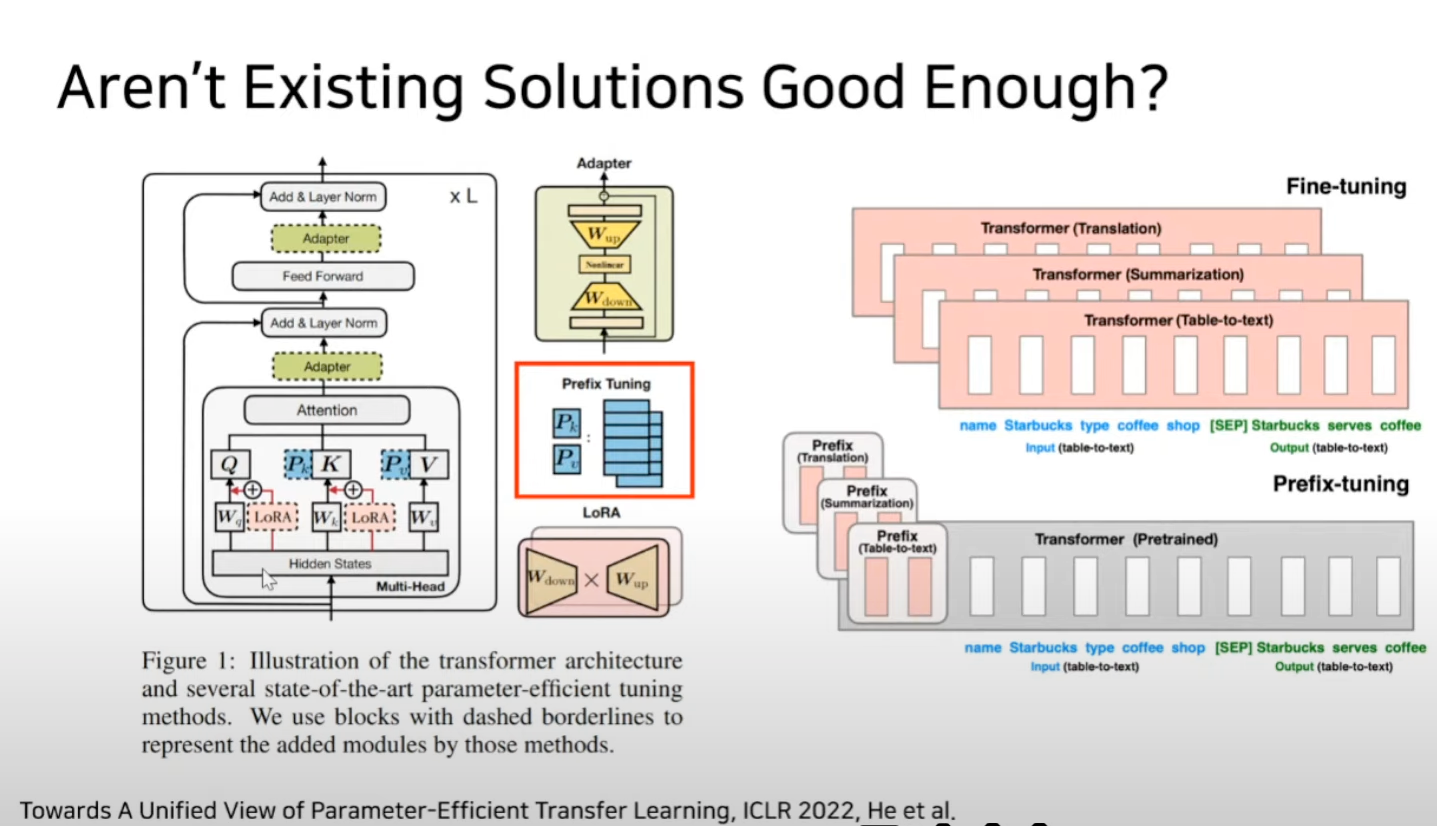
 -> manually ~ 가 말하는 것은 사람이 쓴 prompt가 차선책이 아닐 수 있다라는 뜻
-> manually ~ 가 말하는 것은 사람이 쓴 prompt가 차선책이 아닐 수 있다라는 뜻
Directly Optimizing the Prompt is Hard
- Prefix-tuning은 최적화하기 어렵고 그 성능이 trainable parameter non-monotonically 하게 변한다는 것을 관찰
- monotonically : 우상향하거나 우하향 하는 것 <--> non-monotonically : 수렴하지 않고 진동한다.(최적화 하기 어렵다)
- Adaptation을 위해 Sequence length의 일부를 미리 떼어놔야 하기 때문에 downstream task를 처리하는데 사용할 수 있는 sequence length가 줄어듦

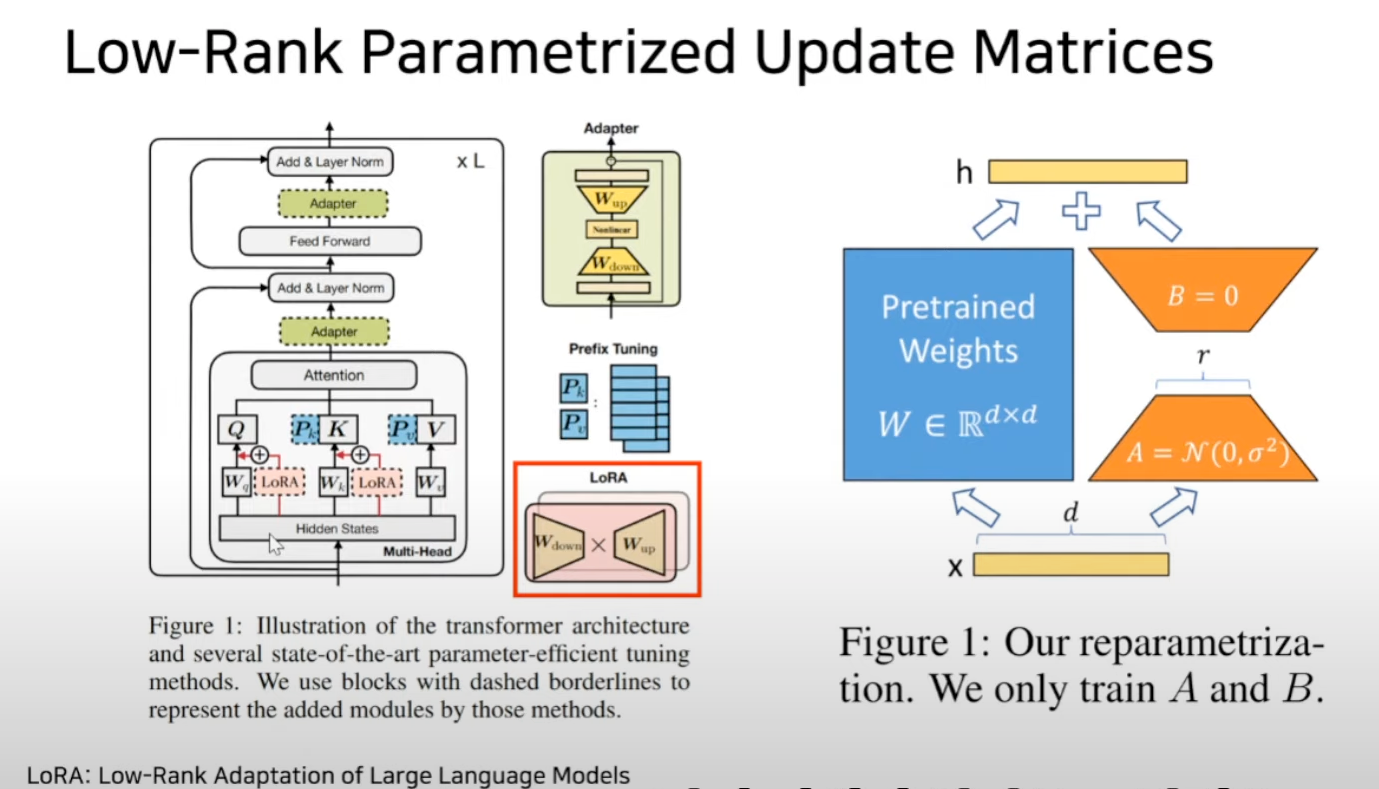

-
Hypothesis : 가중치에 대한 update도 adaptation중 instrinsic rank가 낮다.
-
가중치에 대한 update, 즉 gradient descent로 얼마만큼 변할지에 대한 델타 w를 업데이트 하는 것인데, 근데 그 델타 w값 변화량 또한 adaptation 중 intrinsic rank가 낮다. 라는 가정을 깔고 들어감.
- 앞서서 주장한 것은 over parameterized model이 instrinsic rank가 낮다라고 주장을 한 거고 LoRA에서는 델타 w 또한 adaptation 중에 intrinsic rank가 낮을 것이다.
-
-
W0 = 175 billion ; 델타 w를 BA로 근사 하겠다.
-
우측 하단 figure를 보면 A로 down projection을 하고 B로 Up projection을 해서 Rank decomposition matrix multiplication을 통해서 델타 변화량 값을 근사하겠다. 라고 언급
-
오직 A,B,만 학습을 한다.
-
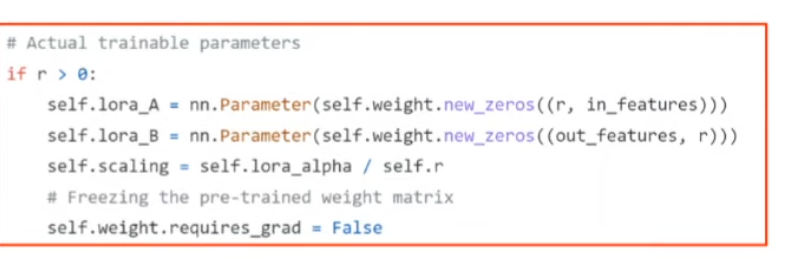
A는 랜덤 가우시안 초기화 B는 영행렬로 초기화
- 하지만 A의 실제 구현은 kaiming-uniform으로 초기화 되어 있다.
-

-
model.eval()을 호출하게 되면 PLM은 그대로 두고 LoRA A와 LoRA B의 weight만 불러오게 된다.
-
그리고 load_state_dict를 하고 evaluation을 하게 되면 원래 evaluation을 overriding한 것이 된다.
-
if 문을 타고 self.r > 0 이라면 원래 A B 값을 새롭게 더해주어서 merged weight에 fine tuning시킨 값이 적용이 된 것.
-
adapter기법은 transformer 레이어 사이에 adapter레이어를 끼워넣었기 때문에 연산이 시퀀셜하게 증가한다는 단점이 있었는데 LoRA는 A와 B를 weight에다가 합치기 때문에 연산이 증가하지 않음.
-
-
원래는 weight에 아무것도 업데이트가 되어있지 않았지만 새로운 downstream task의 weight를 merge함.
-
해제하는 방법도 매우 단순한게, 새로운 모델을 학습시키고 싶으면(새로운 downstream task를 한다면) 원래 가지고 있던 weight 값들을 빼주기만 하면은 원래 weight값으로 복원할 수 있다.
- 이런 편의성을 가지고 있다고 LoRa는 주장한다.
Conclusion
-
LLM을 효율적으로 튜닝하는 LoRA 제안
-
Adapter류의 기법과 다르게 inference latency가 발생하지 않음
-
prefix-tuning과 다르게 usable sequence length를 줄일 필요가 없음
-
가용할 수 있는 문장길이를 줄일 필요가 없다.
-
가중치 업데이트 행렬의 변화량이 low intrinsic rank를 가진다고 가정하고 방법을 제안.
-
논문에서는 LM에 초점을 맞췄지만 이론적으로는 모든 dense layer에 적용이 가능하다.
Opinion
- 대부분 adapter 기법이나 prefix 튜닝보다는 뒤쳐지는 성능을 보이지만 작은 parameter셋으로만 학습을 한다는 관점으로 보았을 때에는 뛰어난 fine tuning 기법인 것 같다.
Github: microsoft/LoRA
Paper: LoRA: Low-Rank Adaptation of Large Language Models
