Best model vs Distilation models

Model Selection 과정에서 timm 라이브러리에 있는 distilation model들만 학습해서 비교해 보았다.
distilation 모델을 선택해 탐구해 본 이유는 기본적으로 distilation model이 다른 모델에 비해 많은 데이터에 대해 학습하기 때문에, overfitting에 강한 general한 모델일거라 예측했기 때문이다.
Train Loss / Accuracy
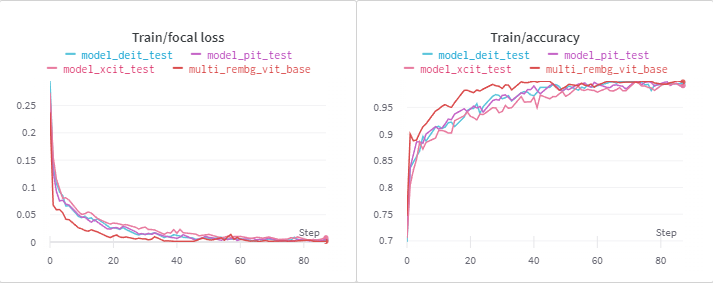
vit_base에 비해 거의 모든 dist 모델이 수렴 속도가 느린데,
Base, Medium model 사용 시 OOM 에러가 유발되기 때문에 tiny, small model을 선택한 이유일 수 있다.
Validation Loss / Accuracy
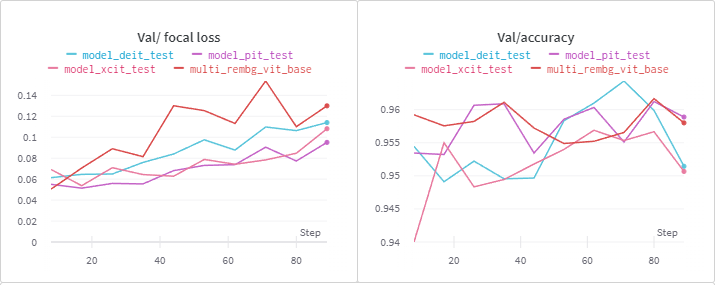
val loss는 best model과 비슷한 형태로 발산하는 모습을 보여주었고
accuracy 같은 경우 다소 어지럽지만 "pit" model이 best model과 비슷한 형태를 보인다.
대부분의 모델이 8~10 epochs에서 best model을 출력하는 것으로 보인다.
Confusion Matrix 비교
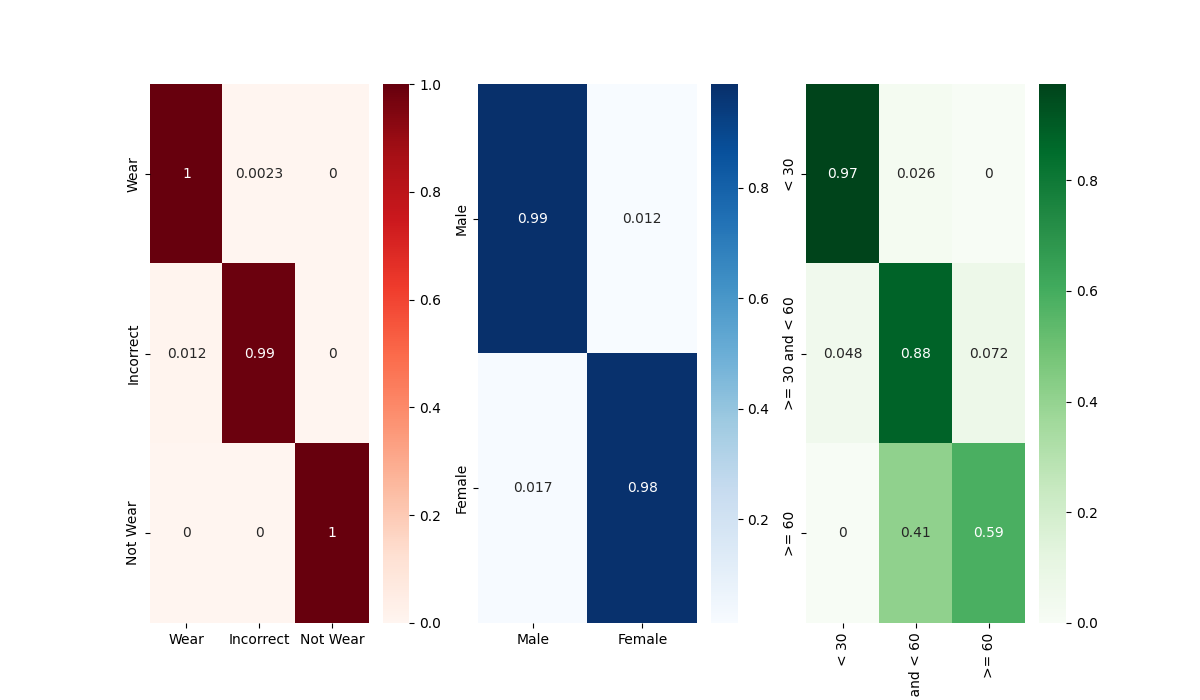 vit Base의 Best Model Confusion Matrix
vit Base의 Best Model Confusion Matrix
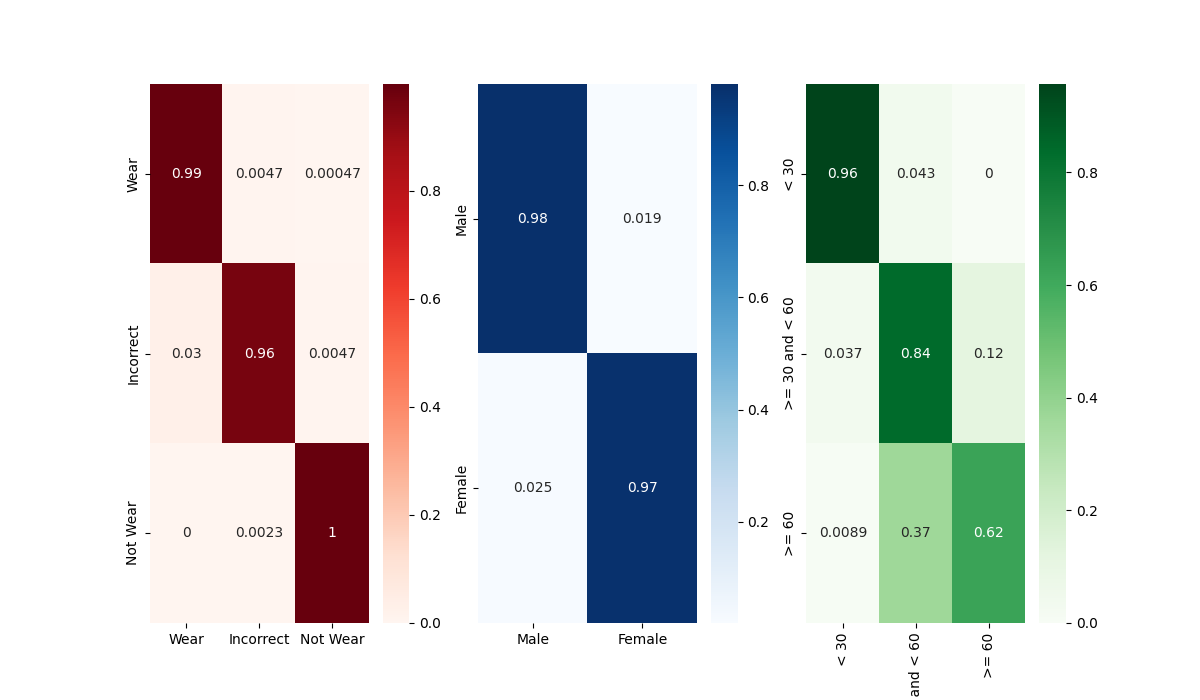 xcit model의 Best model Confusion Matrix
xcit model의 Best model Confusion Matrix
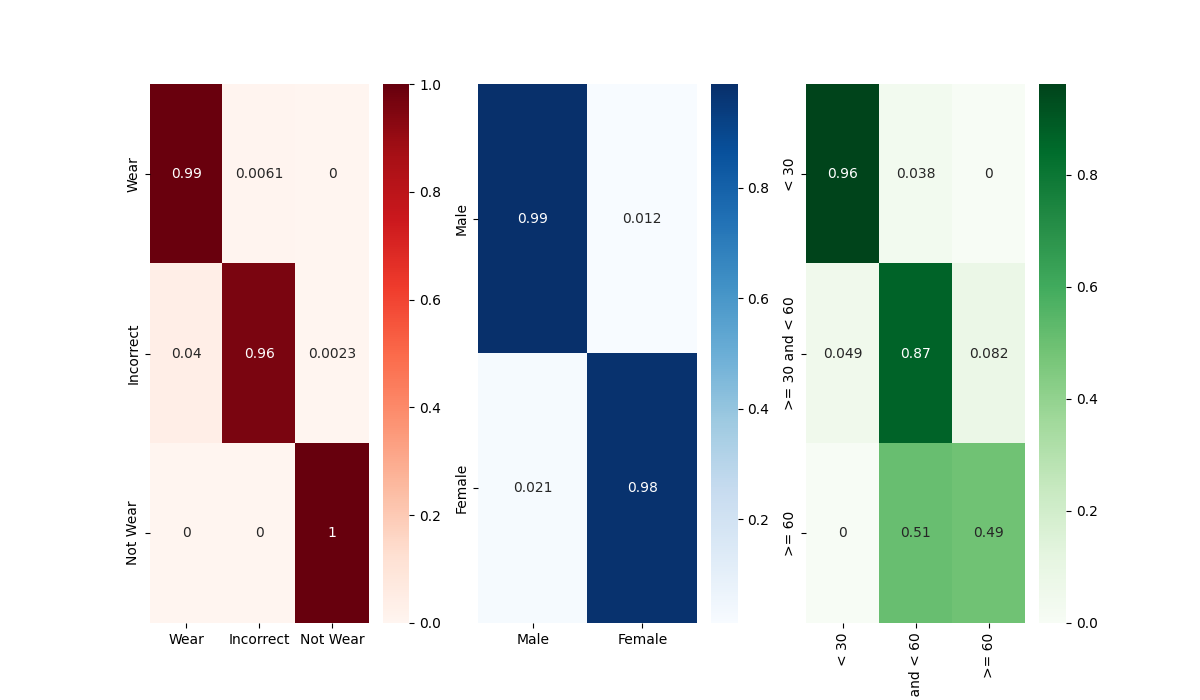 pit model의 Best model Confusion Matrix
pit model의 Best model Confusion Matrix
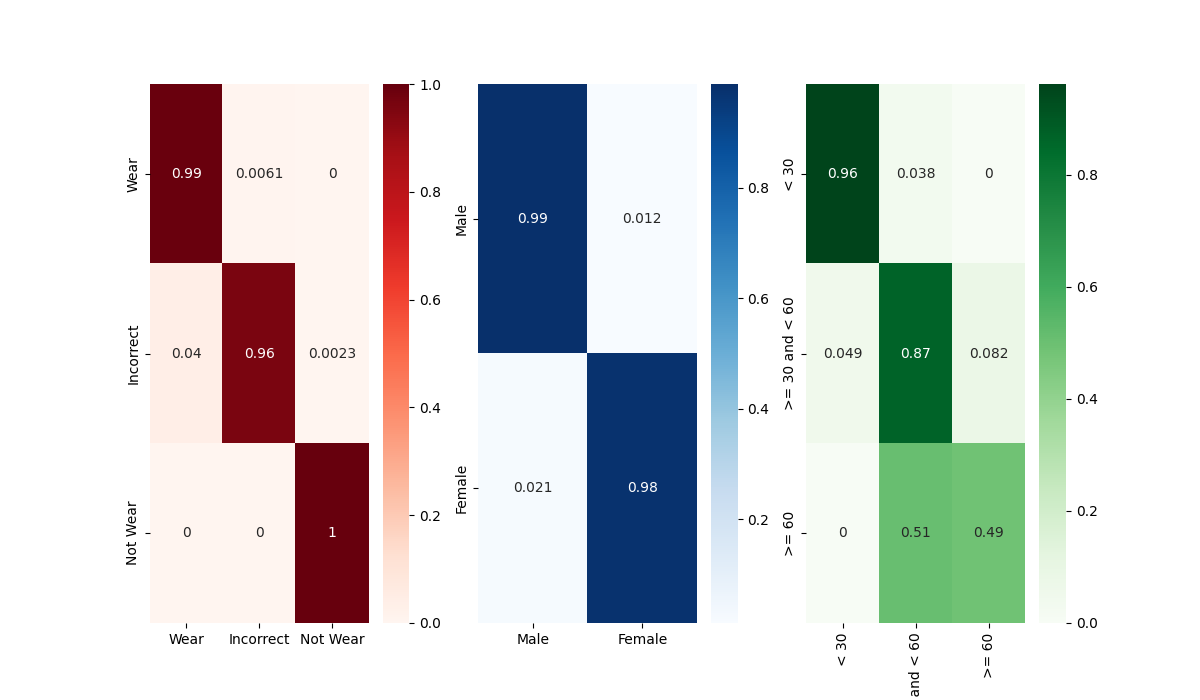 deit model의 Best model Confusion Matrix
deit model의 Best model Confusion Matrix
가독성이 별로 좋지않다 ㅠ
관건은 Age Classification에서의 30~60 / 60 대를 분류하는 문제인데,
굳이 따지자면 xcit나 pit model의 age confusion matrix가 비슷하게 나왔다.
다만 해당 부분이 어떤 값을 가져야 나이를 잘 분류하는 모델인지는 미지수다. 데이터 셋 이미지를 확인해 보았을 때, 육안으로 봤을 때도 60대인지, 50대인지 구분이 어려운 사람들이 많았고, 50대 임에도 불구하고 60대인 사람보다 더 액면가가 늙어 보이는 사람도 존재했기 때문이다.
사람이 찾지 못하는 feature를 찾아 학습하는 것이 AI model의 역할이지만, 생김새를 보고 Age를 예측한다는 것은 대부분의 feature가 개인 별로 차이가 심하다고 생각하기 때문에 다소 이해가 안가는 대회 내용이기도 하다.
만약 무조건 Age에 대한 상관 관계의 feature가 존재한다고 가정하더라도 그러한 feature를 학습하기에 너무 밸런스가 맞지 않는 데이터 셋이라고 생각한다.
evaluation 조건을 'f1'으로 변경했을 때도 같은 모델을 선택하므로 callback condition과는 관련이 없는듯 하다.
