003_SQL 입문[MySQL]
복습
- 데이터베이스(DB) : 데이터 저장
- MYSQL(RDBMS) : 접근
# 데이터 베이스 확인 SHOW DATABASES; # 데이터 베이스 선택 USE database_name;-
TABLE 로 저장
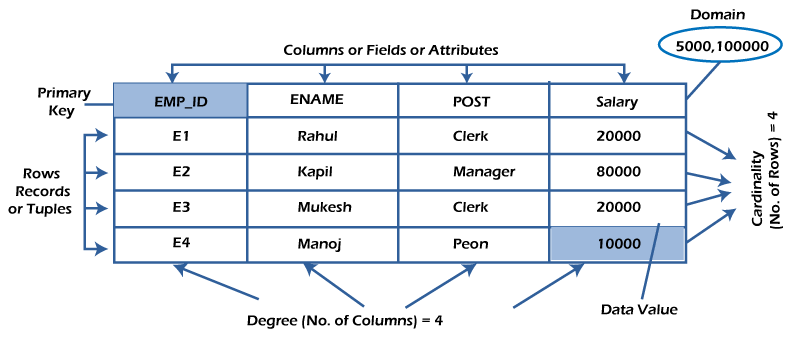
-
컬럼(Column)과 열(Row)이 존재
- PK(Primary Key) : 기본키 → Row를 구분할 수 있는 대표값
- FK(Foreign Key) : 외래키 ↔ 타 테이블과 관계를 맺음
-
SQL 명령어
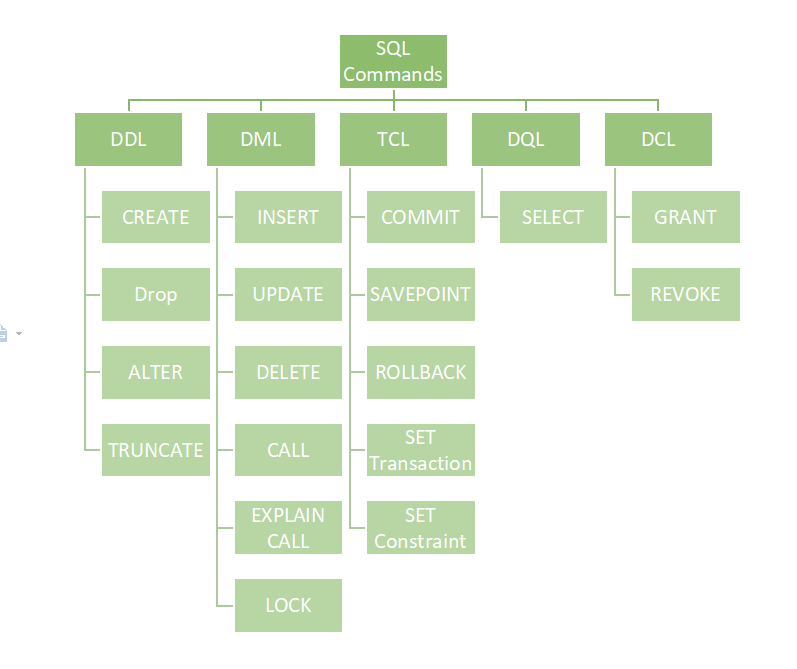
-
DML(Data Manipulation Language)
- Create
INSERT INTO table_name( columns_name1, ... ) VALUES ( value1, ... ); - Read
SELECT * # 피하자! FROM table_name1 t1 # WHERE 1=1 # AND t1.id = t2.id;- JOIN
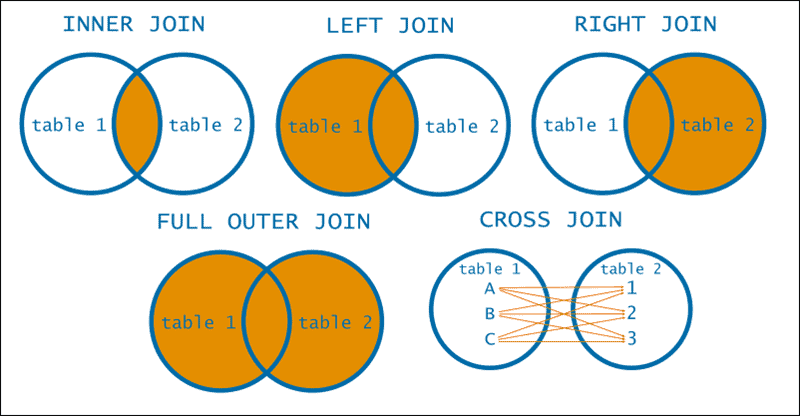
- INNER
SELECT * FROM table_name1 t1 INNER JOIN table_name2 t2 ON t1.id = t2.id; - OUTER
- FULL
- 짧은 코드가 존재하지 않음
- LEFT, RIGHT
SELECT * FROM table_name1 t1 LEFT OUTER JOIN table_name2 t2 ON t1.id = t2.id; LEFT OUTER JOIN table_name2 t3 ON t1.id = t3.id;
- FULL
- CROSS
SELECT * FROM table_name1 CROSS JOIN table_name2; # 또는 SELECT * FROM table_name1, table_name2;
- INNER
- JOIN
- Update
UPDATE table_name SET column_name1=value1, … WHERE 1=1; - Delete
DELETE FROM table_name WHERE 1=1;
- Create
-
TCL(Transaction Control Language)
- Start Transaction(트랜잭션 시작)
- Commit(트랜잭션 한번에 실행)
- Rollback(트랜잭션 취소)
-
DDL(Data Definition Language)
- Create
CREATE DATABASE db; CREATE TABLE table_name1( id BIGINT AUTO_INCREMENT PRIMARY KEY, # PRIMARY KEY = NOT NULL, UNIQUE, INDEX 생성 fk BIGINT, string VARCHAR(100), var DOUBLE, create_date DATETIME NOT NULL DEFAULT NOW(), # CURRENT_TIMESTAMP KEY fk (fk), CONSTRAINT table_name1_fk_1 FOREIGN KEY (fk) REFERENCES table_name2(id), # 또는 # FOREIGN KEY (fk) REFERENCES table_name2(id) ); CREATE INDEX index_name ON table_name1(create_date); CREATE VIEW view_name AS SELECT * FROM table_name1; - Alter
# 추가 ALTER TABLE table_name1 ADD COLUMN alter_add VARCHAR(20); # DEFAULT '0'; # 변경 ALTER TABLE table_name1 MODIFY COLUMN alter_add VARCHAR(20) DEFAULT '0'; # 삭제 ALTER TABLE table_name1 DROP COLUMN alter_add; - Drop
DROP TABLE IF EXISTS table_name1; DROP VIEW view_name;
- Create
-
- MYSQL(RDBMS) : 접근
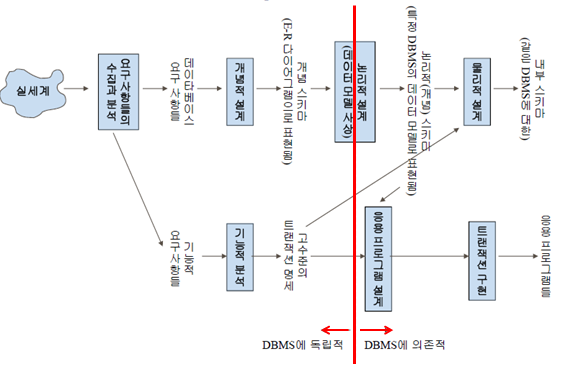
데이터 모델링
목적
- 데이터 품질 향상(ACID), 정확성, 속도
개요

| 업무 | 중요도 | 설명 |
|---|---|---|
| 요구사항 분석 | 20% | 업무 분석, 자료분석 |
| 설계 | 30% | 논리 및 물리 데이터 모델링 |
| 개발 | 10% | 언어, 툴 선택 → query 설계, CRUD 개발 |
| 테스트 | 40% | 에러 수정, 논리 수정, 요구에 맞추기 |
모델링이란?
- 요구사항 분석을 설계화 하는 것
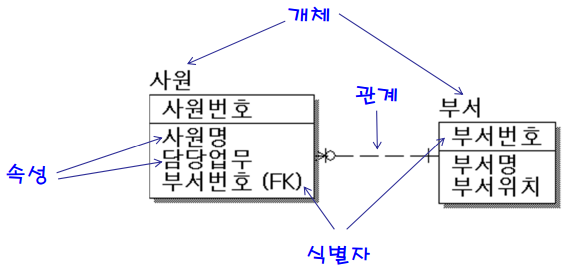
- 기업의 정보 구조 → 개체(TABLE-entity), 관계(FK), 속성(COLUMN), 식별자(PK) 부여
테이블 관계

| 방법 | 설명 |
|---|---|
| 1:1 | 잘 사용하지 않음(PK = PK) |
| 1:N | 대부분 사용(PK = FK) |
| N:M | 표현할 방법이 없음으로 1:N, 1:M 테이블 신설 = Mapping(한국에서 많이 사용) or Linking(공장, 외국) |
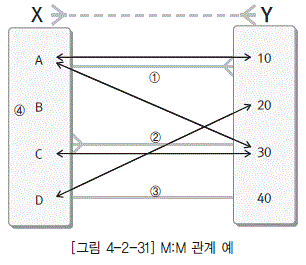
정규화 그림, 글, 4 ~ 5 정규화
| 정규화 | 뜻 | 설명 |
|---|---|---|
| 1 정규화 | 도메인 원자값 | 더 이상 나눌 수 없음(속성 안에 “,”로 나눠져 있음) |
| 2 정규화 | 부분적 함수 종속 제거 | A → BC ⇒ A → B, A → C |
| 3 정규화 | 이행적 함수 종속 제거 | A → B → C ⇒ A → B, B → C(복합키는 다 나눠가며 확인 필요) |
| BCNF 정규화 | 결정자이면서 후보키가 아닌 것 제거 | AB → C, C → B ⇒ A → C, C → B(잘못 설계하지 않으면 없음) |
| 4 정규화 | 다치 종속 제거 | AB → C ⇒ A → C, B → C |
| 5 정규화 | 조인 종속성 이용 | 더 이상 분해할 수 없어야 함 |
모델링 과정
| 명칭 | 설명 |
|---|---|
| 개체 파악 | 명사(회사, 구매, 회원) |
| 식별자 파악 | 보통 id로 통일(경우에 따라 복합 식별자 사용[두 회사 통합]) |
| 상세화 | 정규화 |
| 통합 | 논리 모델링 결합 및 뷰 설정 |
| 검증 | 오류 확인, 논리 확인, 요구 확인 |
| 물리모델링 | DB 선택, 자료형 선택, 기기 선택 |
| 구현 | 실행 |
용어 정리
개체
- Row를 구분할 수 있는 것
식별자 설정
- 선입견을 버림(저자는 3글자 → 미국은?, 공동저자는?)
명확한 의미
- 약어, 단어 통일
- datetime → dt, name → nm, quality, quantity → qty?
유형
| 종류 | 설명 |
|---|---|
| 기본개체 | 기본 정보를 포함한 개체(회사, 회원) |
| 개념개체 | 무형의 과정이나 개념(구매) |
| 교차개체 | N:M을 표현하기 위한 개체 |
주의점
- 단일 사례 분리
- 고립
- 동의어 중복 개체
관계
유형
| 이름 | 뜻 | 그림 |
|---|---|---|
| 종속관계 | 개체간 주종 관계 존재 |  |
| 중복관계 | 서로가 부모 관계(구독 = 누가, 누구를) | 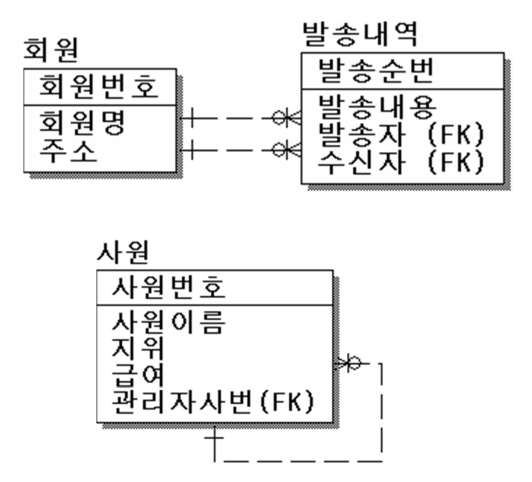 |
| 재귀관계 | 자기 자신을 참조 |  |
| 배타관계 | 한 곳에만 존재 | X |
주 식별자 규칙
- UNIQUE, NOT NULL, 짧고, 쉽게 == 채번규칙
속성
유형
| 이름 | 뜻 |
|---|---|
| 단순 | 기본 속성 |
| 결합 | 두 단순 속성 결합 |
| 추출 | 연산 처리 속성 |
| 설계 | 성능을 목적으로 생성 |
VIEW
왜 쓰는가?
- 자주 SELECT 되는 Query 문이 존재함
- 결과를 TABLE로 새로 만듬
- 값에 혼란이 올 수 있음
- 결과를 TABLE로 새로 만듬
- 보안
- 외부 통신용
- 외부에 데이터 공개
- TABLE 전체에 접근권한을 주게 되면, 개인 정보가 보호되지 않음
- 처음 User를 만든 것과 동일
- TABLE 전체에 접근권한을 주게 되면, 개인 정보가 보호되지 않음
- 편리함
가상의 테이블을 만들어서 쉽게 접근하자!
CREATE VIEW view_name AS
SELECT
*
FROM
table_name;특징
VIEW는 DELETE가 가능하지 않음- 가상의 테이블
- 데이터 변경 적용이 되는가?
- (INSERT, UPDATE) 가능
- 단, 제약 조건이 존재
- SubQuery, OUTER JOIN, UNION X
- 주의점
- 연관 테이블이 drop 되면 망가짐
PROCEDURE, TRIGGER
- DB에서 작업 == SQL programming
- PROCEDURE(프로시저)
- 함수 → 이름, 매개변수, CALL
- TRIGGER(트리거)
- 함수 → 이름, 매개변수, 이벤트
PROCEDURE
DELIMITER $$
CREATE PROCEDURE ADD(IN add_qty INT)
BEGIN
UPDATE product SET
qty = add_qty
END $$
DELIMITER;
CALL ADD(1);- 잘 사용하지 않음
- 생산성 하락
- 유지보수가 안됨
- 80, 90년대 많이 사용됨
- 사용하는 회사를 보기 힘듬(삼성, 한국수자원평가원)
TRIGGER
DELIMITER $$
CREATE TRIGGER triagger1
[BEFORE | AFTER] [INSERT | UPDATE | DELETE]
ON table_name
FOR EACH ROW
BEGIN
UPDATE product SET
qty = add_qty
END $$
DELIMITER;
- 프로시저 보다 더 사용됨
- INSERT, UPDATE, DELETE 가 발생했을 때, 따라서 발생함
- 언제 쓸까?
- 증감을 동시에 해결
- 생성시 같이 연결
유용한 SQL 함수(MySQL)
- 통계 쿼리
IF
- SELECT에 많이 사용됨
SELECT IF(조건, TRUE, FALSE) FROM table_name;
SELECT IF(price > 5000, '비쌈', '쌈') FROM product;- 조건에 NULL을 많이 확인함
IFNULL
SELECT IFNULL([컬럼 | 값], NULL일 때 대체) FROM table_name;
SELECT IFNULL(qty, 0) FROM product;NULLIF
SELECT NULLIF([컬럼 | 값], 컬럼) FROM table_name;
SELECT NULLIF(price, qty) FROM product;CASE
SELECT
CASE
컬럼
WHEN 조건 THEN 결과
...
ELSE 결과
END
FROM
product;
SELECT
CASE
price
WHEN 1000 THEN '천원'
WHEN 2000 THEN '이천원'
ELSE '모름'
END AS 'location'
FROM
product;- 약어를 전체 문장으로 펼쳐줌
CONCAT
CONCAT(문자1, 문자2)
SELECT * FROM table_name WHERE 컬럼 LIKE '%~%'; # <- 위 부분이 변수일 때!
SELECT * FROM table_name WHERE 컬럼 LIKE CONCAT('%', 변수, '%');GROUP_CONCAT
SELECT GROUP_CONCAT(컬럼) FROM table_name GROUP BY 컬럼;
SELECT GROUP_CONCAT(name) FROM product;DATE_FORMAT
SELECT DATE_FORMAT(컬럼, '변환식') FROM table_name;
SELECT date_format(create_date, '%Y') FROM product;RANK
# 순위에 번호를 매겨줌
SELECT RANK() OVER(ORDER BY 컬럼 ASC|DESC)
SELECT RANK() OVER(ORDER BY price) FROM product ;
# ROW_NUMBER 도 존재
SELECT ROW_NUMBER () OVER(ORDER BY price) FROM product ;UNION
SELECT name FROM product
UNION # 중복 X
# UNION ALL # 중복 O
SELECT name FROM `member`;유저 정보와 시간들
SELECT CURRENT_USER();
# 쿼리 시작
SELECT NOW();
# SELECT CURRENT_TIMESTAMP() ; # 동일함
# 쿼리 끝
SELECT SYSDATE();
SELECT NOW(), SYSDATE(), SLEEP(5), NOW(), SYSDATE()DBeaver
설정
사용법 - workbench
- table 생성
- column 생성
- row 생성
- view 생성
- trigger 생성
SQL 쓰는 법
- 의미 단위로 잘 끊고, 잘 띄어씀
실습
데이터 모델링(정규화)
- 완전히 동일한 column을 가진 table이 2개가 있다면?
- 새로운 종류 column을 추가함
- 종류 테이블을 제작해서 연결함
- 구매발주 업무
각 부서는 구매 의뢰 함
구매 의뢰에 따라 구매 발주가 이루어짐
한 구매 의뢰는 여러 번 발주 됨
자재는 자재 master에 의해서 관리
한 거래처에 대해서 한 건의 발주는 한건의 구매발주서가 발행
한 건의 구매발주에는 여러 품목이 포함
- 엔티티?
- 부서 - 구매 의뢰 -< 구매 발주, 자재, 거래처, 구매발주서, 품목
목표
| table 이름 | 영문 | 속성 이름 | 영문 | 데이터 타입 | DEFAULT | 추가 속성 |
|---|---|---|---|---|---|---|
| 학과정보 | dept | 학과명 | name | VARCHAR(100) | ||
| 학과장 | dean | VARCHAR(100) | NULL | fk | ||
| 식별자 | id | BIGINT | AUTO_INCREMENT | pk | ||
| 학생정보 | stdnt | 학번 | nbr | BIGINT | AUTO_INCREMENT | |
| 이름 | name | VARCHAR(100) | ||||
| 학과 | dept | DATETIME | fk | |||
| 입학년도 | adm_yr | DATETIME | NOW() | |||
| 학년 | grade | ENUM | 1-1,1-2,2-1,2-2,3-1,3-3,4-1,4-2 | |||
| 식별자 | id | BIGINT | AUTO_INCREMENT | pk | ||
| 과목정보 | subj | 과목명 | name | VARCHAR(100) | ||
| 개강년도 | str_cl_yr | DATETIME | NOW() | |||
| 학기 | semstr | ENUM | 1, semmer, 2, winter | |||
| 강의교수 | prof | BIGINT | fk | |||
| 개설학과 | dept_opnd | BIGINT | fk | |||
| 식별자 | id | BIGINT | AUTO_INCREMENT | pk | ||
| 교수정보 | prof | 교수번호 | nbr | BIGINT | AUTO_INCREMENT | |
| 교수명 | name | VARCHAR(100) | ||||
| 소속학과 | dept_affilation | BIGINT | fk | |||
| 식별자 | id | BIGINT | ||||
| 과목별 성적정보 | 과목 | subj | BIGINT | fk | ||
| 학생 | stdnt | BIGINT | fk | |||
| 성적 | score | DOUBLE | 0.0 | |||
| 식별자 | id | BIGINT | AUTO_INCREMENT | pk | ||
| 평점 | 전체 평점 | ovr_rtng | DOUBLE | 0.0 | ||
| 식별자 | id | BIGINT | AUTO_INCREMENT | pk |
VIEW
- 맴버 아이디와 이름, 구매 횟수를 나타내는 view를 생성
CREATE VIEW V_member_buy_count AS
SELECT
m.member_id ,
m.name ,
count(b.id) AS buy_count
FROM
`member` m
INNER JOIN buy b ON
b.member_id = m.id
GROUP BY
m.member_id ,
m.name ;회고
- 전체적인 복습을 통해 추가 자료를 찾아봄
- 이전에 배웠던 정규화에 대한 확실한 판단이 가능
- 개체와 관계에 대해 깊게 고민할 수 있는 시간이 됨
- VIEW에 UPDATE와 INSERT가 되는 것이 신기함
- SQL에 생각보다 다양한 함수가 존재함
- DBeaver를 통해 다른 유료툴을 사용하는 것보다 유용할 것 같음
- ERDcloud가 투박하지만, 전체적인 기능이 있고 무료인 것이 좋음
- 다양한 ERD 실습을 통해 상기 시킬 필요가 있음
Ref
- 🙈[DB이론] DB 설계 개요🐵 - bloh
- 모델링 개요 - blog
- 관계형 데이터베이스 설계 (관계 종류 1:1 / 1:M / N:M ) - 하나몬
- 관계(Relationship) 정의 - DATA ON-AIR
- [Database] 정규화(Normalization) 쉽게 이해하기 - blog
- 정규화 (제1 정규화 ~ 제3 정규화) - blog
- 데이터베이스 정규화 - BCNF - blog
- [복습]데이터베이스 정규화 -4 (4NF, 5NF) - blog
- 개체 도출 예 - blog
- RDB 관계, 관계 도출 예 - blog
- 자기참조관계, 순환관계 - blog
- Date and Time Functions - mysql docs
- DBeaver를 편리하게 사용할 수 있는 환경 설정. - blog
- MySQL 기본 사용법 - youtube
- 변수명 생성기
- [DB] 📈 데이터 모델링 개념 & ERD 다이어그램 그리기 💯 총정리 - blog

DA DE DS