Numpy 추가 학습
연산자 & 형태 확인
import numpy as np
arr1 = np.array([1,2,3])
arr2 = np.array([4,5,6])
# 기본 연산은 요소간 계산
print(arr1 + arr2)
print(arr1 - arr2)
print(arr1 * arr2)
print(arr1 / arr2)
print(arr1 // arr2)
print(arr1 % arr2)
# 행렬곱은 dot으로 실행
print(arr1.dot(arr2))
# 배열처럼 계산하고 싶으면 배열로 변경 가능
print(arr1.tolist())
# 연산을 할 때, 형태가 같거나 브로드케스팅이 가능해야 함
# 형태 확인
print(arr1.shape)난수 생성 & 저장과 불러오기
# 난수 생성 가능
np.random.randint(1,7) # 주사위 1 ~ 6
# 난수들 생성 가능
np.random.randn(3, 3) # 0 ~ 1 사이 숫자를 (3,3) 크기로 생성
# 저장
# 바이너리 형식(파일 처리 쉬움)
np.save('./arr1.npy', arr1)
# 불러오기
new_arr = np.load('./arr1.npy')결측치
- NaN, None, nan, NAN, NA, N/A, NA! 엑셀 빈값, 엑셀의 !VALUE, 없음, 작성 안함
- 결측치는 해당 row를 지우는게 일반적
- columns 대다수가 결측치면 columns을 삭제
- 연산 하면, 대체로 결측치 반환
결측치 처리 함수
dropna
- NaN값을 가진 row 또는 col 삭제
# row 삭제
df.dropna()
# col 삭제
df.dropna(axis=1)fillna
- 빈값을 지정값으로 변경
df.fillna(0)결측치 라이브러리
import missingno as msno
msno.matrix(df)실습
다양한 공공데이터 사용
- 공공 데이터 포털 이용
- 분류, 평균, 비교, 연산
- 실질적인 의미 파악
- 결측치, 오기재 데이터 확인
국민연금공단_대량보유주식 보고내역
- 데이터 수(50개 이상), 다양한 컬럼)
df = pd.read_csv('국민연금공단_대량보유주식 보고내역_20221005.csv', encoding='cp949', index_col=0)
df_org = df.copy()
# 처음 렌덤 끝을 통해 데이터의 형태 파악하기
pd.concat([df.head(), df.sample(5), df.tail()])- 2022년 분기별 데이터로 분류
df['보고서 작성기준일'] = pd.to_datetime(df['보고서 작성기준일'])
df['quarter'] = df['보고서 작성기준일'].dt.quarter- df_3, df_6, df_9, df_12 변수에 저장
df_3 = df[df['quarter'] == 1]
df_6 = df[df['quarter'] == 2]
df_9 = df[df['quarter'] == 3]
df_12 = df[df['quarter'] == 4]- 분기별 지분율 평균을 비교
for df_temp in [df_3, df_6, df_9, df_12]:
print(df_temp['지분율(퍼센트)'].mean())
# 또는
df.groupby('quarter').mean()- 지분율이 가장 높은 기관이 있는 달과 가장 낮은 기관이 있는 달을 확인
[
df.loc[df['지분율(퍼센트)'] == df['지분율(퍼센트)'].max(), '보고서 작성기준일'].dt.month,
df.loc[df['지분율(퍼센트)'] == df['지분율(퍼센트)'].min(), '보고서 작성기준일'].dt.month,
]
# 또는
df.sort_values('지분율(퍼센트)').loc[::len(df) - 1, '보고서 작성기준일'].dt.month수출입무역통계
# excel에 맞게 데이터를 가져와야 함
df = pd.read_excel('FTA무역통계_20230109000037.xls')
# 정확하게 가져옴
df = pd.read_excel('FTA무역통계_20230109000037.xls', header = 4)- 무역수지 적자와 흑자로 나눠라
# 수치로 변경
df['무역수지'] = pd.to_numeric(df['무역수지'].str.replace(',', ''))
# 적자 흑자 나누기
df['손익'] = np.where(df['무역수지'] < 0, '-', '+')- 수출건수 상위 10% 그룹을 구하라
df['수출건수'] = pd.to_numeric(df['수출건수'].str.replace(',', ''))
df.sort_values('수출건수', ascending=False)[:int(len(df2) / 10) + 1]- 수입건수의 평균을 구하고 가까운 그룹을 구하라
df['수입건수'] = pd.to_numeric(df['수입건수'].str.replace(',', ''))
df['평균_수입건수'] = (df['수입건수'] - df['수입건수'].mean()).abs()도로교통공단사회교육교육실적정보
- 매우 큰 데이터 셋(604만 row)
- 결측치가 존재함
df = pd.read_csv('도로교통공단_사회교육_교육실적정보_20201231.csv', encoding='cp949', index_col=0)- 교육인원 별 3그룹으로 나눔
- 30명 이하, 500명 이하, 500명 초과
- 이후 그룹별 지역 분포 확인
df['교육인원분류'] = df.apply(lambda row:'30명 이하' if row['교육인원'] <= 30 else '500명 이하' if row['교육인원'] <= 500 else '500명 이상', axis = 1)
for i in df['교육인원분류'].unique():
print(i)
print(df[df['교육인원분류'] == i].value_counts('지부코드').index[0])
print(df[df['교육인원분류'] == i].value_counts('지부코드')[0])
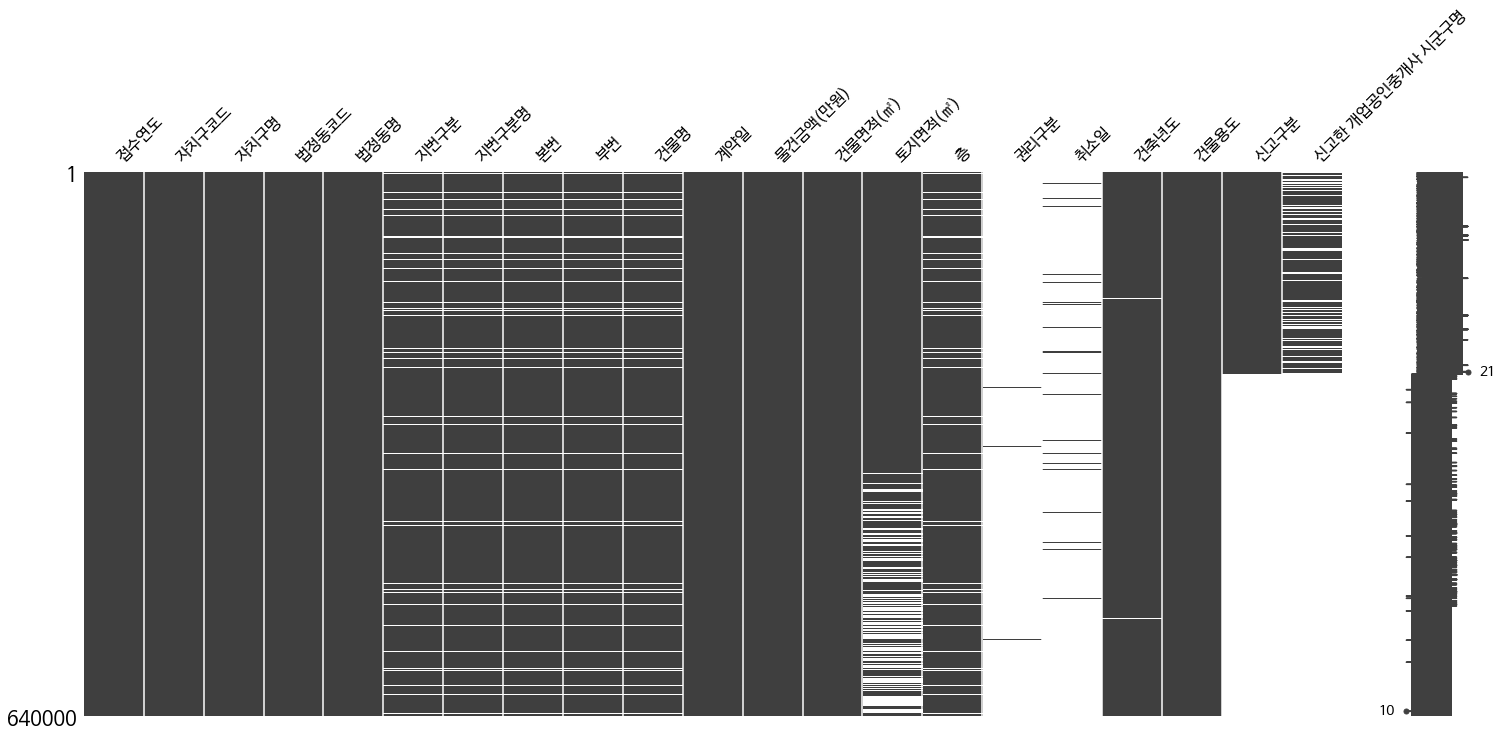
print('-' * 50)**서울시 부동산 실거래가 정보**
- 날짜 파싱 유효함
df = pd.read_csv('서울시 부동산 실거래가 정보.csv', encoding = 'cp949')- 자치구명별로 물건금액의 합계를 구한다 (단, 본번 정보가 있는 건물에 한함)
df[df.본번 != 'NaN'].pivot_table('물건금액(만원)', '자치구명', aggfunc = np.sum)- 신고한 개업공인중개사 시군구명 column에서 NaN값의 개수를 구한다
df['신고한 개업공인중개사 시군구명'].value_counts(dropna=False)[0]- 건물면적이 20평 이상인 건물에 대해서만 물건금액의 평균을 구한다
df[df['건물면적(㎡)'] / 3.3058 >= 20]['물건금액(만원)'].mean()- 5층 이하인 건물에 대해서만 자치구별로 빈도를 구한다
df[df['층'] <= 5].pivot_table('층', '자치구명', aggfunc = len)
# 또는
df[df['층'] <= 5].value_counts()pandas와 numpy
- 뒤에서 3번째 순서의 column을 df_to_arr 파일로 저장 (바이너리 파일로)
np.save('df_to_arr.npy', df.iloc[:, -3].to_numpy())- 임의의 범위를 슬라이싱한 뒤, 넘파이를 이용해 행렬곱 구하기
df.iloc[:, :2].to_numpy().T.dot(df.iloc[:, -10:-8].to_numpy())- 시간이 남는다면, 면적 대비 가격이 가장 비싼 건물을 알아보자
df['면적당가격'] = df['물건금액(만원)'] / df['건물면적(㎡)']
df.loc[df['면적당가격'].sort_values(ascending=False).index[0], '건물명']회고
- numpy에 다양한 사용법을 공부해야 할 것
- 결측치를 대체하게 된다면, 어떻게 대체할 것인지 고민해야 할 것
- 다양한 공공데이터가 존재하고, 생각보다 의미가 있는 정보가 많음을 인지함
- 자연어로 요구하는 문제를 코드로 어떻게 해결할지 고민해야 할
Ref
- [Python] 결측치 처리 및 시각화 - blog
- pandas.DataFrame.dropna - docs
- pandas.DataFrame.fillna - docs
- 공공데이터포털
- 국민연금공단_대량보유주식 보고내역 - 공공데이터포털
- FTA 무역통계 - 수출입무역통계
- 도로교통공단사회교육교육실적정보 - 공공데이터포털
- 서울시 부동산 실거래가 정보 - 서울특별시

DA DE DS