
앞서 배웠던 Uipath Activity들을 Python으로 바꿔서 배워보자!
python에서 Excel를 다루기 전에, Excel 기능을 지원해주는 라이브러리 설치가 필요하다.
- openpyxl
- xls, xlsx, xlsm 파일을 처리하는데 필요한 라이브러리이다
- pandas
- pandas는 파이썬 언어로 작성된 데이터를 분석 및 조작하기 위한 소프트웨어 라이브러리이다.
따라서 Excel을 다루기 전에 해당 라이브러리를 모두 설치하자.
Pip install openpyxl
Pip install pandas설치가 완료 되었으면 이제 python으로 Excel을 다루어 볼 수 있다.
Uipath에서 Excel값을 읽을 때, 사용되는 Read Range Activity를 python 코드로 구현보기 앞서 간단하게 pandas로 Excel 데이터를 읽는 법에 대해 설명하였다.
데이터를 읽고자 할 Excel 파일과 시트명을 지정해주고
# 파일명 지정
file_name = '파일이름.xlsx' # 반드시 확장자 붙여주기
# 시트명 지정
file_name = '시트이름'해당 값을 데이터프레임 형식으로 읽어온다.
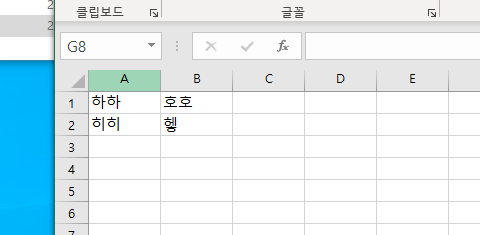
df = pd.read_excel(file_name, sheet_name)예시용으로 다음과 같은 '연습'이라는 엑셀 파일을 만들고 해당 코드를 실행 시켜보자.
import pandas as pd
# 파일명
file_name = '연습.xlsx'
# 시트명
sheet_name='Sheet1'
# Daraframe형식으로 엑셀 파일 읽기
df = pd.read_excel(file_name, sheet_name)
# 데이터 프레임 출력
print(df)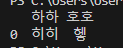
df 결과값으로 위와 같은 결과가 나온다. 자동적으로 읽고자 하는 데이터의 첫번째 행을 컬럼명으로 인식하여 표현한다. 또한 옆에 해당 행의 위치를 표시하는 값으로 숫자가 표시된다.(해당 사진에서는 [히히, 헿]의 행 위치를 0이라는(왼쪽) 숫자로 표현한다.)
만약 첫번째 행을 컬럼명으로 표시하지 않고 싶다면
import pandas as pd
# 파일명
file_name = '연습.xlsx'
# 시트명
sheet_name='Sheet1'
# Daraframe형식으로 엑셀 파일 읽기
df = pd.read_excel(file_name, sheet_name, header=None)
# 데이터 프레임 출력
print(df)으로 지정하면 된다.
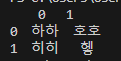
- header 인자의 경우 int형을 넣어서 컬럼명의 위치를 정할 수 있다.
- 만약, 두번째 행을 컬럼명으로 지정하고 싶으면 header=2를 넣으면 된다.
기초적으로 다루는 법에 대해서 배웠으니 이제 Uipath에서 사용되는 Read Range처럼 응용해서 사용해보자
uipath에 read range 처럼 activity형식으로 쓰기 위해서
def read_range(file_name: str, sheet_name: str | int, range: str = None)라는 함수를 선언하였다.
- file_name 인수는 사용하고자 할 엑셀 파일명
- sheet_name 인수는 사용하고자 할 시트명
- range 인수는 읽고자 하는 범위
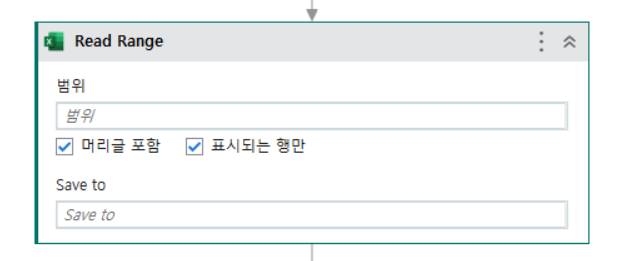
해당 부분에서 '범위'의 경우 Uipath의 Read Range Activity의 '범위'랑 똑같은 기능을 지원하게 최대한 구상해 보았다.
def read_range(file_name: str, sheet_name: str | int, range: str = None, header_y_n: int | None = 0):
if range == None:
df = pd.read_excel(file_name, sheet_name, header = header_y_n)
return df
else:
pattern = r'[a-z A-Z]+'
result = re.findall(pattern, range)
alphabet = result
alphabet_count = len(alphabet)
pattern = r'\d+'
result = re.findall(pattern, range)
numbers = result
numbers_count = len(numbers)
wb = load_workbook(file_name)
ws = wb[sheet_name]
data = []
if alphabet_count == 1 and numbers_count == 1:
# A1
start_column = alphabet[0]
start_column = int(ord(start_column)) - 64
start_row = int(numbers[0])
for row in ws.iter_rows(min_row=start_row, min_col=start_column):
row_data = [cell.value for cell in row]
data.append(row_data)
df = pd.DataFrame(data)
return df
elif alphabet_count == 2 and numbers_count == 2:
# A1:B2
start_column = alphabet[0]
start_column = int(ord(start_column)) - 64
start_row = int(numbers[0])
end_column = alphabet[1]
end_column = int(ord(end_column)) - 64
end_row = int(numbers[1])
for row in ws.iter_rows(min_row=start_row, max_row=end_row, min_col=start_column, max_col=end_column):
row_data = [cell.value for cell in row]
data.append(row_data)
df = pd.DataFrame(data)
return df
else:
print('오류')Range 인수안에 읽고자 할 특정 Excel 범위를 기입해주면
pattern = r'[a-z A-Z]+'
result = re.findall(pattern, range)
alphabet = result
alphabet_count = len(alphabet)
pattern = r'\d+'
result = re.findall(pattern, range)
numbers = result
numbers_count = len(numbers)를 통해 'Colume+Row' 인지 'Colume+Row:Colume+Row'인지 파악한다.
(전자의 경우 A7 후자의 경우 A3:B7이라고 생각하면 된다.)
- Colume+Row의 형식인 경우
if alphabet_count == 1 and numbers_count == 1:
# A1
start_column = alphabet[0]
start_column = int(ord(start_column)) - 64
start_row = int(numbers[0])
for row in ws.iter_rows(min_row=start_row, min_col=start_column):
row_data = [cell.value for cell in row]
data.append(row_data)
df = pd.DataFrame(data)
return df해당 cell부터 전체 범위를 읽는다.
(ex. A1:D20이라는 엑셀 데이터가 있을 때, B7이라고 기입하면 B7:D20을 df를 뱉어준다.)
- Colume+Row:Colume+Row의 형식인 경우
elif alphabet_count == 2 and numbers_count == 2:
# A1:B2
start_column = alphabet[0]
start_column = int(ord(start_column)) - 64
start_row = int(numbers[0])
end_column = alphabet[1]
end_column = int(ord(end_column)) - 64
end_row = int(numbers[1])
for row in ws.iter_rows(min_row=start_row, max_row=end_row, min_col=start_column, max_col=end_column):
row_data = [cell.value for cell in row]
data.append(row_data)
df = pd.DataFrame(data)
return df지정해준 범위를 df로 반환한다.
(ex. A3:B7이라고 기입하면 해당 범위를 df로 뱉어준다.)
만약, 전체시트를 읽고 싶다고 한다면 range를 None값으로 지정하면 전체 범위를 df로 뱉어준다.
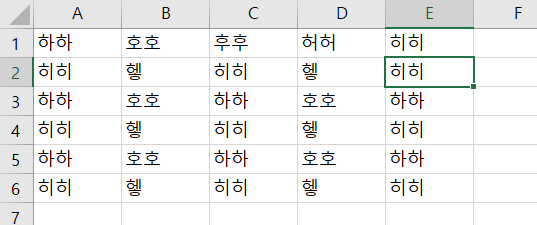
다음과 같은 Excel 파일이 있다고 가정하자. 해당 파일을 방금 설명하였던 코드를 활용하여 제어해보자.
먼저 해당 전체값을 읽는다고 하면,
read_range('연습.xlsx', 'Sheet1', None, 0)또는
read_range('연습.xlsx', 'Sheet1')로 하면 된다.
그 결과로는

Sheet1의 전체 데이터를 보여준다.
여기서 헤더값을 제외하고 읽고 싶다고 한다면
read_range('연습.xlsx', 'Sheet1', None, None)으로 바꿔 준다면,
로 보여준다.
(해당 기능은 전체 시트를 읽을 때만 지원 가능하다.)

특정 Cell부터 범위를 읽고 싶다고 한다면
read_range('연습.xlsx', 'Sheet1', 'B3')로 하면 된다.
그 결과로는,
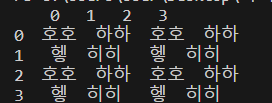
로 보여준다.
특정 범위로 읽고 싶다고 한다면
read_range('연습.xlsx', 'Sheet1', 'B3:C5')로 하면 된다.
그 결과로는,
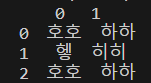
로 보여준다.
여담으로 python에서 Excel 기능을 지원하는 라이브러리는 두가지 종류가 있다.
1. win32
- Win32com은 Microsoft에서 제공하는 윈도우 프로그램을 파이썬이라는 언어를 매개체로 제어할 수 있도록 만든 API다. Win32com을 사용하면 Microsoft Excel, Power point, Word, Outlook 등 프로그램을 제어할 수 있다.
- win32는 이름 그대로 윈도우에서 지원하기 때문에 맥 이용자들은 사용하기 힘들 수 있다. 필자 또한, win32보다는 다음에 소개할 라이브러리를 선호한다.
2. openpyxl
- OpenPyXL은 Excel 파일을 읽고 쓰기를 Python으로 할 수 있는 일종의 모듈이다.
- win32와 같은 기능을 지원하지만 해당 라이브러리는 excel만 지원한다.
- 해당 모듈은 OS에 구애받지 않고 excel사용이 가능하다. 다만, 확장자가 반드시 xls, xlsx, xlsm 만 제어 가능하다는 단점이 있다.
