Abstract
저자들은 멀티태스크 학습이 단일 태스크 각각 따로 학습하는 것보다 오히려 어려운 이유를 분석하고, 그 원인 중 하나로 task 간 해로운 gradient interference를 지목함
이를 막기 위해, 다른 task gradient와 충돌하는 경우 그 충돌 성분을 제거하는 gradient surgery 를 제안함
이 방법은 모델 비의존적이며, 여러 supervised / RL 문제에서 데이터 효율과 최종 성능을 개선했다고 주장함
1. Introduction
멀티태스크 학습의 이상적인 목표는 shared structure를 활용해 더 적은 데이터로 더 많은 능력을 학습하는 것
하지만 실제로는 joint training이 optimization을 어렵게 만들어, 독립 학습보다도 성능이 떨어지는 경우가 많음
여기서, 이 논문은 이 문제를 단순히 architecture 문제로만 보지 않고, task별 gradient가 서로 반대 방향을 가리키는 conflict 가 큰 원인이라고 가정
특히 이 conflict가 큰 curvature와 gradient magnitude 차이와 함께 나타날 때 optimization이 심하게 꼬인다고 봄
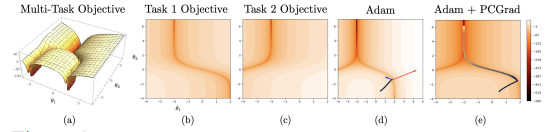
그림 1
2차원 멀티태스크 최적화 문제에서 PCGrad를 시각화한 그림.
(a) 멀티태스크 목적 함수의 지형(objective landscape). (b)와 (c)는 (a)를 구성하는 개별 작업 목적 함수들의 등고선도(contour plot)이다. (d)는 Adam 옵티마이저를 사용했을 때, 멀티태스크 목적 함수 위에서의 그래디언트 업데이트 경로(trajectory)를 나타낸다.
경로의 끝 지점에서 두 작업의 그래디언트 벡터는 각각 파란색 화살표와 빨간색 화살표로 표시되어 있으며, 이들의 상대적인 길이는 로그 스케일로 표현되었다.
(e)는 PCGrad를 적용한 Adam을 사용했을 때, 멀티태스크 목적 함수 위에서의 그래디언트 업데이트 경로를 나타낸다. (d)와 (e)에서 최적화 경로는 검은색에서 노란색 방향으로 진행된다.
2. Multi-Trask Learning with PCGrad
2.1 Preliminaries : Problem and Notation
멀티태스크 목표는 여러 task의 평균 loss를 최소화함.
논문은 이를 다음처럼 두고 있음
유한한 task 집합에서는 전체 loss를 로 두고, 각 task gradient 를 로 정의함
즉, 기본 출발점은 “각 task loss의 gradient를 어떻게 함께 사용할 것인가” 임
2.2 The Tragic Triad: Conflicting Gradients, Dominating Gradients, High Curvature
저자들은 멀티태스크 최적화가 어려워지는 상황을 tragic triad 라고 부름
첫째는 conflicting gradients 이며, 두 task gradient 사이 각도를 라 할 때, 이면 두 gradient 가 충돌한다고 정의함
즉, 한 task를 줄이는 방향이 다른 task를 악화시키는 방향과 겹친다는 뜻임
둘째는 gradient magnitude imbalance 이며, 두 gradient의 크기 유사도를 다음처럼 정의함
이 값이 1이면 두 gradient 크기가 비슷하고, 0에 가까우면 한쪽이 다른 쪽을 지배함
즉, average gradient를 쓰면 큰 gradient를 가진 task가 update를 사실상 주도하게 됨
셋째는 high curvature 이며, 논문은 multi-task curvature를 다음처럼 정의함
이는 현재 update 방향을 따라 봤을 때 loss landscape가 얼마나 휘어 있는지를 나타냄
curvature가 크면, 어떤 task에서 얻는 이득은 과대평가되고 다른 task에서 입는 손해는 과소평가될 수 있음, 그래서 단순 평균 gradient가 특히 위험해짐
즉, gradient가 서로 충돌하고, 그중 하나가 훨씬 크고, landscape까지 많이 휘어 있으면, joint training이 비효율적이거나 멈출 수 있음
2.3 PCGrad: Project Conflicting Gradients
두 task gradient , 가 충돌하면, 에서 방향으로의 음의 충돌 성분만 제거함
즉, 의 normal plane 위로 를 투영함
반대로 충돌하지 않으면 gradient를 건드리지 않음, 그래서 positive transfer는 유지하고, destructive interference만 줄이려는 방식임
알고리즘 흐름은 다음과 같음
각 task gradient를 구한 뒤, 각 task 에 대해 다른 task들을 랜덤 순서로 보면서, 충돌하는 경우에만 projection을 적용함
마지막에는 수정된 gradient들을 합쳐서 update에 사용함
이 과정은 모델 구조를 바꾸지 않으므로, SGD/Adam 같은 기존 optimizer와 바로 결합할 수 있음
2.4 Theoretical Analysis of PCGrad
먼저 convex 두-task setting에서, 적절한 step size 아래 PCGrad update는 최적값 또는 두 gradient가 정확히 반대 방향인 특수점으로 수렴한다고 보임
즉, 적어도 이상한 방향으로 발산하는 규칙은 아니라는 점을 보임
그다음 더 중요한 결과는 Theorem 2 임.
Theorem 2
손실함수 𝐿 이 미분 가능하고, 그 gradient가 Lipschitz 연속이며 상수 𝐿 > 0 를 가진다고 가정함.
현재 파라미터 𝜃 에서, gradient 𝑔 를 사용해 한 번 업데이트한 뒤의 파라미터를 , PCGrad로 수정된 gradient 를 사용해 한 번 업데이트한 뒤의 파라미터를 라고 하자. 이때 step size는 t>0 임.
또한 어떤 상수 ℓ≤L 에 대해 를 만족한다고 가정하자. 즉, multi-task curvature가 아래에서 bounded 되어 있다고 하자.
그러면 다음 조건들이 성립할 때 가 성립함. 즉, PCGrad로 업데이트한 결과의 loss가 일반 multi-task gradient로 업데이트한 경우보다 크지 않음.
저자들은 다음과 같은 조건에서 PCGrad가 vanilla multi-task gradient descent보다 한 번의 update 후 loss를 더 낮출 수 있는 충분조건을 제시함
그리고 curvature 관련 하한 조건, 그리고 step size가 충분히 큰 조건이 함께 필요함
또한 보조량으로
을 정의함
직관적으로는 gradient conflict가 충분히 크고, 크기 불균형이 있으며, curvature가 높을 때 PCGrad의 이득이 커진다는 의미임
즉, 이론 분석도 결국 tragic triad 가설을 뒷받침하는 방향
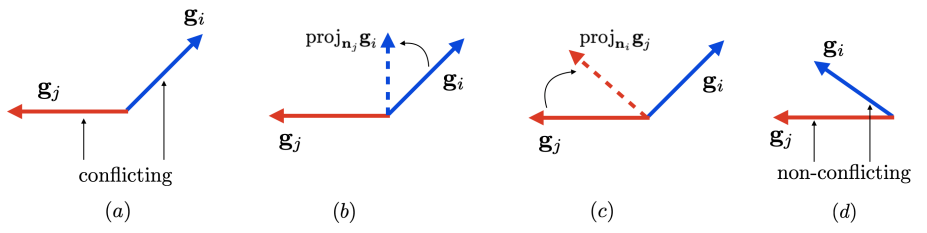
그림 2
충돌하는 그래디언트와 PCGrad.
(a)에서 작업 와 는 서로 충돌하는 그래디언트 방향을 가지며, 이는 파괴적인 간섭(destructive interference)을 초래할 수 있다. (b)와 (c)에서는 그래디언트가 서로 충돌하는 경우의 PCGrad 알고리즘을 보여준다. PCGrad는 작업 의 그래디언트를 작업 의 그래디언트의 법선 벡터(normal vector) 방향으로 투영하고, 반대로 작업 의 그래디언트도 작업 의 그래디언트의 법선 벡터 방향으로 투영한다. 충돌하지 않는 작업 그래디언트들(d)은 PCGrad에서 변경되지 않으며, 이를 통해 건설적인 상호작용(constructive interaction)이 가능해진다.
3. PCGrad in Practice
supervised learning에서는 minibatch 안에 들어온 task별로 gradient를 따로 계산한 뒤, task gradient들 사이 cosine similarity를 미리 구하고, Algorithm 1에 따라 projection을 적용함
중요한 점은 gradient를 다시 역전파할 필요 없이 이미 계산한 task gradient들만 가지고 수정할 수 있음
RL에서는 policy gradient나 actor-critic에도 그대로 적용할 수 있음, actor와 critic 각각의 task gradient를 PCGrad로 바꿔 넣으면 됨
즉, 이 방법은 특정 네트워크 구조보다 gradient를 쓰는 방식 자체를 수정하는 기법

4. Related Work
첫째, architecture-based multi-task learning 임.
Cross-Stitch, routing, attention-based sharing처럼 구조를 바꿔 task sharing을 조절하는 방법들,
PCGrad는 이런 방법과 경쟁하기보다 보완적으로 같이 붙일 수 있다고 말하고 있음
둘째, divide-and-conquer / distillation 임
task별로 따로 학습한 뒤 distill해서 하나로 합치는 방식인데, 이런 방법은 최종 멀티태스크 모델은 얻지만 학습 효율 이점이 줄어든다고 봄
PCGrad는 처음부터 joint training을 잘 되게 만드는 접근
셋째, gradient rescaling / orthogonal gradient / continual learning projection 임
저자들은 기존 방법들이 gradient 크기만 조절하거나, sequential setting용 projection이라는 점에서 다르다고 정리함
PCGrad는 simultaneous multi-task learning에서 충돌하는 task gradient 쌍마다 반복적으로 projection한다는 점이 차별점
5. Experiments
PCGrad가 실제로 optimization을 쉽게 만드는가, 다른 multi-task 방법과 결합 가능한가, 그리고 tragic triad가 실제 문제에서도 중요한가임.
저자들은 supervised learning, multi-task RL, goal-conditioned RL에 대해 평가했다고 밝힘
5.1 Multi-Trask Supervised Learning
여기서는 MultiMNIST, CityScapes, CelebA, multi-task CIFAR-100, NYUv2를 사용
CIFAR-100에서는 20개 coarse class를 20개 task로 보고 평가했는데, PCGrad 단독 single network가 71% accuracy를 얻어 independent training 67.7%, cross-stitch 53% 등을 넘겼고, routing network와 결합하면 77.5%까지 올라감
→ 즉, representation sharing도 살리고 gradient conflict도 줄이면 더 좋아짐
CelebA 40-attribute multi-label classification에서는 평균 classification error가 8.69로, 비교 대상인 Sener and Koltun의 8.95보다 낮습니다. task 수가 많아도 gradient surgery가 유효하다는 예시로 사용됨
NYUv2에서는 MTAN과 결합했을 때 성능이 더 올라감
본문 Table 1 기준으로 MTAN + PCGrad 는 segmentation mIoU 20.17, pixel accuracy 56.65, depth abs error 0.5904, rel error 0.2467, surface normal mean 30.01 등으로 강한 결과를 보이며, 저자들은 9개 평가 항목 중 8개에서 최고 점수를 기록했다고 함
→ 즉, PCGrad는 architecture-based SOTA와도 잘 결합됨
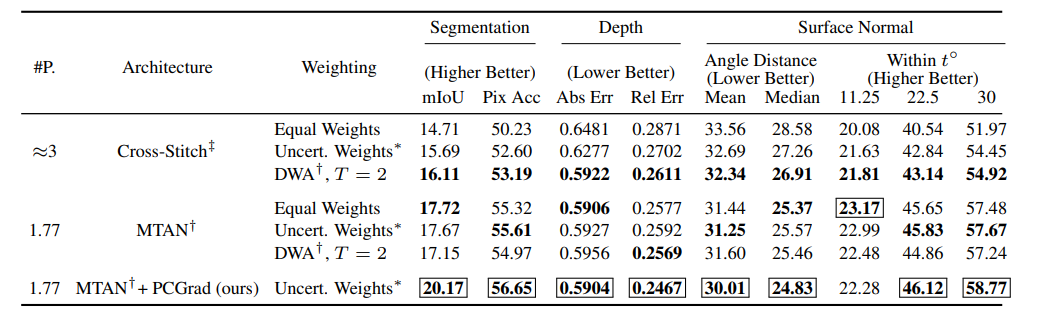
표 1
YUv2 데이터셋에서의 3개 작업 학습 결과: 13개 클래스 의미론적 분할(semantic segmentation), 깊이 추정(depth estimation), 그리고 표면 법선(surface normal) 예측 결과를 나타낸다.
#P 는 전체 네트워크 파라미터 수를 의미한다. 우리는 멀티태스크 아키텍처와 가중치 부여 방식의 조합 중 가장 좋은 성능을 낸 경우를 굵게 표시하였다. 또한 각 작업별로 가장 높은 검증 성능(validation score)은 박스로 표시하였다. 기호들은 기존 방법들을 나타낸다: ∗ : [28], † : [33], ‡ : [40]
다른 방법들의 성능은 Liu 등 [33]에서 보고된 값을 사용하였다.
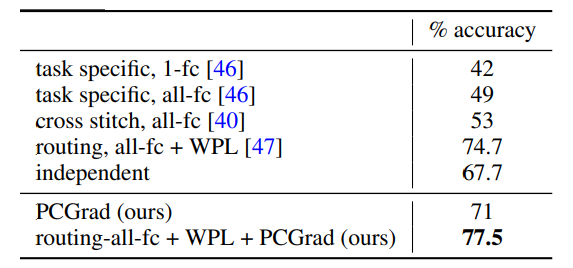
표 2
CIFAR-100 멀티태스크 결과. PCGrad를 routing network와 결합했을 때, 성능이 크게 향상된다.

표 3
CelebA 결과. CelebA의 전체 40개 작업에 대한 평균 분류 오류(classification error)를 제시한다. 이 데이터셋에서 PCGrad는 기존 방법인 Sener와 Koltun [53]보다 더 우수한 성능을 보인다.
5.2 Multi-Task Reinforcement Learning
RL에서는 Meta-World의 MT10과 MT50 을 사용하고, SAC와 결합한 PCGrad를 평가함, 결과적으로 PCGrad + SAC 는 MT10의 10개 task를 모두 해결하고, MT50에서는 약 70%의 task를 해결하면서 가장 좋은 데이터 효율을 보임, 반면 single SAC policy나 multi-head policy는 절반 수준의 skill도 제대로 못 익힘
또한 독립적으로 SAC를 task별로 학습하면 최종적으로 비슷한 수준까지 갈 수는 있지만, MT10에서 약 2 million, MT50에서 약 15 million samples를 더 사용해야 함
→ 즉, PCGrad가 단순히 최종 성능만이 아니라 shared structure를 활용한 sample efficiency 도 개선한다는 주장임
여기서 중요한 ablation도 있음. 저자들은
1) 방향만 바꾸고 크기는 유지하는 버전,
2) 크기만 바꾸고 방향은 유지하는 버전,
3) GradNorm
과 비교했는데, 전부 full PCGrad보다 못했음, 특히 방향 수정이 중요하다는 점을 강조함
→ 즉, 이 논문은 “gradient magnitude balancing만으로는 부족하고, 방향 conflict 자체를 다뤄야 한다”고 함
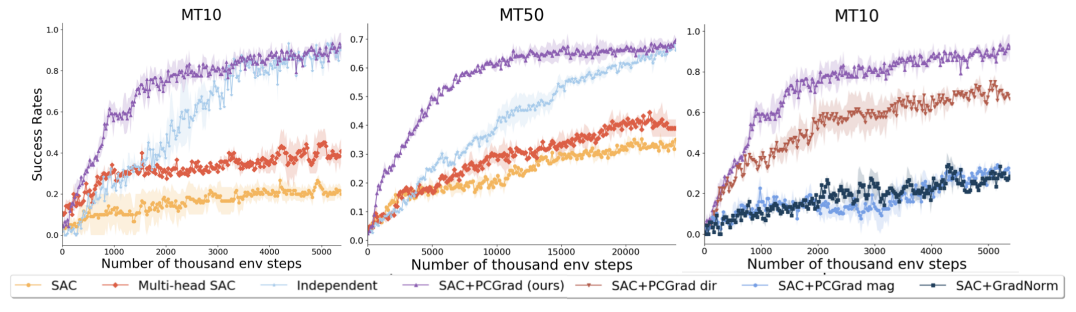
그림 3
왼쪽의 두 그래프는 각각 MT10과 MT50에서의 학습 곡선(learning curves)을 보여준다.
PCGrad는 성공률(success rate) 과 데이터 효율성(data efficiency) 측면 모두에서 다른 방법들보다 훨씬 뛰어난 성능을 보인다. 가장 오른쪽 그래프에서는, PCGrad로 수정된 그래디언트의 크기(magnitude)만 사용할 때와 방향(direction)만 사용할 때에 대한 ablation study 결과, 그리고 GradNorm [8] 과의 비교를 제시한다.
PCGrad는 이 두 ablation 버전과 GradNorm보다 모두 더 좋은 성능을 보이는데, 이는 멀티태스크 학습에서 그래디언트의 방향과 크기를 모두 수정하는 것이 중요하다는 점을 보여준다.
5.3 Empirical Analysis of the Tragic Triad
Meta-World의 두 task를 골라, 학습 초반 100 iteration 동안 tragic triad 관련 조건들이 실제로 관측되는지 확인함
저자들은 학습 중 multi-task curvature를 Taylor 전개를 이용해 추정함
그리고 이 값이 학습 동안 양수이면서 증가하는 경향을 보여, high curvature 조건이 실제로 흔하다고 주장함. 또한 gradient conflict 조건과 이론에서 나온 조건들의 성립 비율이, 아직 학습 신호를 못 얻는 구간에서 높다가 PCGrad가 task를 풀기 시작하면 줄어드는 패턴을 보였다고 설명함.
요지는 tragic triad가 실제 neural network 멀티태스크 학습에서도 중요한 현상처럼 보인다는 것임

그림 4
정리 2에서 논의한 이론적 조건들에 대한 실험적 분석으로, 두 개의 강화학습 작업인 reach 와 press button top 에 대해 학습 초기 100 iteration을 보여준다.
왼쪽: 멀티태스크 곡률(multi-task curvature)의 추정값이다. 학습 전반에 걸쳐 높은 멀티태스크 곡률이 존재함을 관찰할 수 있으며, 이는 정리 2의 조건 (b)를 뒷받침하는 증거를 제공한다.
가운데: 실선은 두 작업 그래디언트 사이의 cosine similarity가 양수인 그래디언트의 비율을 나타낸다. 점선과 파선은 각각 cosine similarity가 음수인 iteration들 중에서, 정리 2의 조건 (a)와 조건 (b)의 함의인 이 성립하는 iteration의 비율을 보여준다.
오른쪽: SAC와 SAC+PCGrad가 각 작업에서 달성한 평균 return을 나타낸다.
가운데와 오른쪽 그래프를 통해, Adam 과 Adam+PCGrad 모두 Task 2를 아직 해결하지 못한 동안에는 조건 (a)가 대부분의 시간 동안 성립한다는 것을 알 수 있다. 그리고 Adam+PCGrad가 Task 2를 학습하기 시작하자마자, 조건 (a)가 성립하는 비율은 감소하기 시작한다. 이 관찰은 조건 (a)가 PCGrad가 멀티태스크 학습에서 뛰어난 성능을 내는 핵심 요인임을 시사한다.
6. Conclusion
멀티태스크 최적화의 주요 어려움은 conflicting gradients, high positive curvature, large gradient differences에서 오며, PCGrad 는 이를 줄이는 간단한 방법
supervised learning과 RL에서 개선을 보였고, 저자들은 이 아이디어가 meta-learning, continual learning, multi-goal imitation learning, NLP 등 다른 setting에도 확장될 수 있다고 함
