Curriculum Temperature for Knowledge Distillation (2023)
기존 KD는 temperature τ 를 보통 고정 하이퍼파라미터로 두는데, 사실 이 값은 teacher–student 분포 차이의 난이도를 조절 → 그래서 학습 내내 같은 temperature를 쓰는 것은, 점점 성장하는 student 입장에서는 비효율적일 수 있음
이를 해결하기 위해 저자들은 동적으로 학습되는 temperature 와 easy-to-hard curriculum 을 결합한 CTKD 를 제안
[Adversarial Distillation]
temperature module 를 따로 두고 이 모듈이 distillation loss를 키우는 방향으로 움직이게 만듬
→ student와 temperature module 사이에 mini-max game 을 만듬
student 는 loss를 줄이려고 하고 temperature module 은 KD loss를 키우려고 함
student는 gradient descent, temperature module은 gradient ascent를 하는 구조
[Curriculum Temperature]
난이도를 점진적으로 올리는 curriculum 이 필요하다고 봄
temperature module 은 다음처럼 업데이트 됨
시간이 갈수록 를 키워서 temperature가 난이도를 더 적극적으로 올리게 만듬
원하는 Curriculum 조건은 두 가지임
1. distillation loss가 점진적으로 커질 것
2. curriculum scale λ 도 점진적으로 커질 것
이걸 만족시키기 위해서 여기서는 cosine schedule 을 씀
이 식은 초반엔 작은 λ 로 쉬운 distillation을 하고, 시간이 지나면서 λ 를 부드럽게 키워 harder distillation로 옮겨 가는 역할을 함
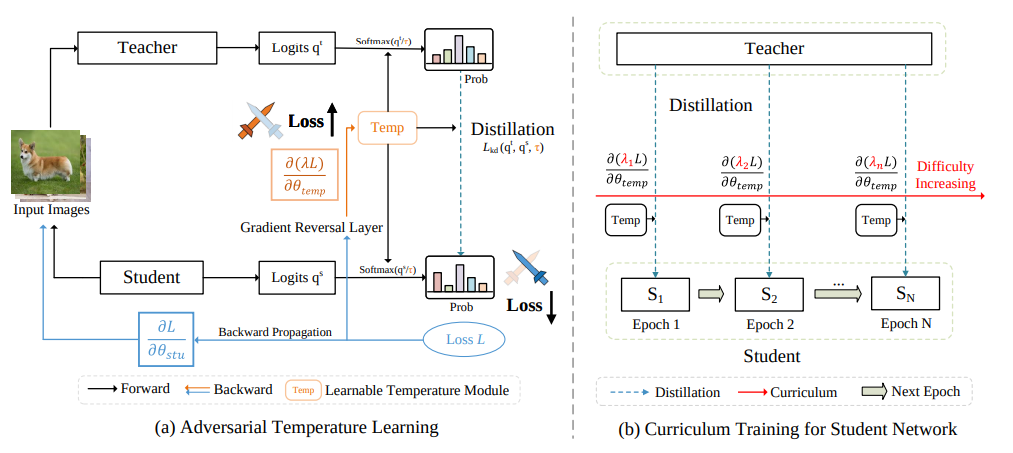
[Global-T & Instance-T]
temperature module은 두 가지 버전
- Global-T : 배치 전체에 대해 하나의 temperature만 예측
- Instance-T : 샘플마다 다른 temperature를 예측
Instance-T 는 표현력이 더 좋아서 성능이 조금 더 높지만 계산량도 약간 더 듬, 반면 Global-T 는 훨씬 가볍고 대부분 실험에서 기본 설정으로 쓰임
예측된 temperature는 다음 식으로 안정적으로 제한
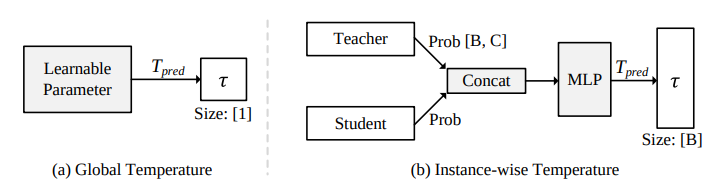
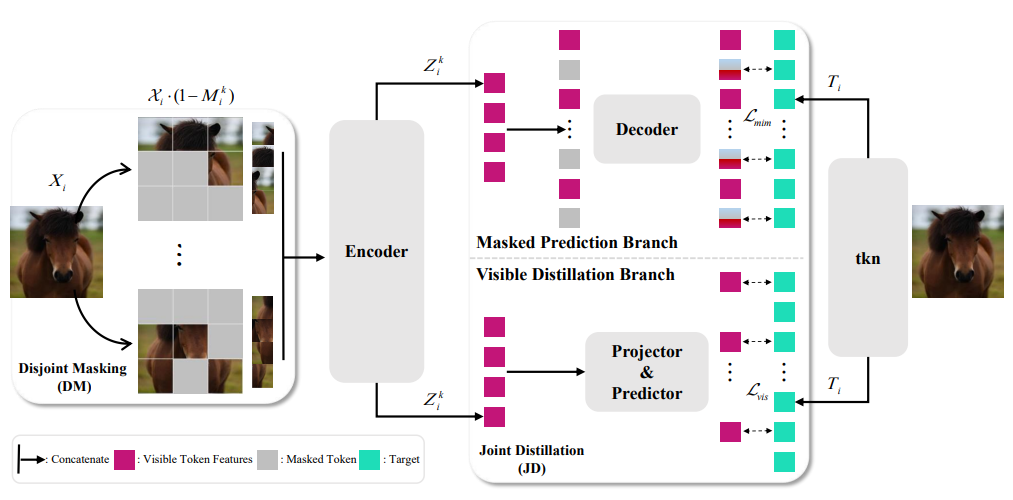
Disjoint Masking with Joint Distillation for Efficient Masked Image Modeling (2023)
이 논문은 MIM(Masked Image Modeling)의 비효율 원인을 한 이미지에서 학습 신호를 충분히 활용하지 못하는 점으로 보고, 이를 해결하기 위해 DMJD(Disjoint Masking with Joint Distillation) 를 제안함
-
DM : 한 이미지에서 여러 개의 서로 겹치지 않는 masked view를 만들어 전체 예측 비율을 높임
-
JD : masked token뿐 아니라 visible token도 distillation으로 학습하게 해서 학습 효율을 끌어올림
→ 기존 MIM은 masked token에서만 gradient가 흘러서, 한 이미지의 많은 정보가 학습에 직접 쓰이지 못한다는 것임, 그래서 multiple masked views + dual-branch distillation 구조를 만든다.
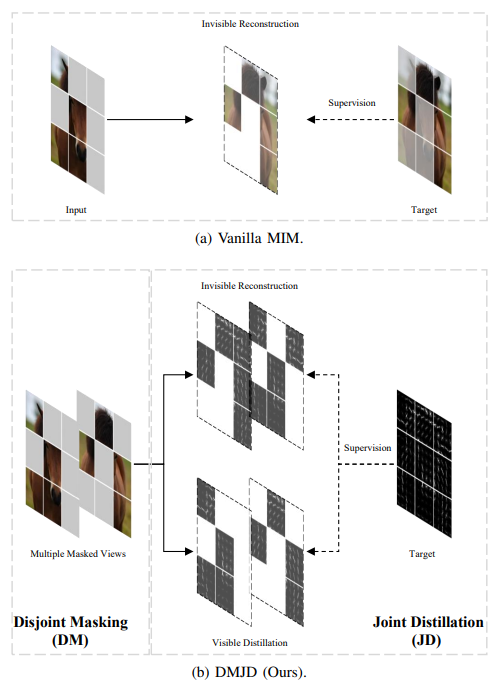
[DM (Disjoint Masking)]
여러 masked view를 만들되 서로 가능한 한 겹치지 않게(disjoint) 샘플링함
각 view에서는 여전히 적절한 corruption rate를 유지하면서도, 이미지 전체 기준으로는 더 많은 위치가 reconstruction supervision 을 받게 됨
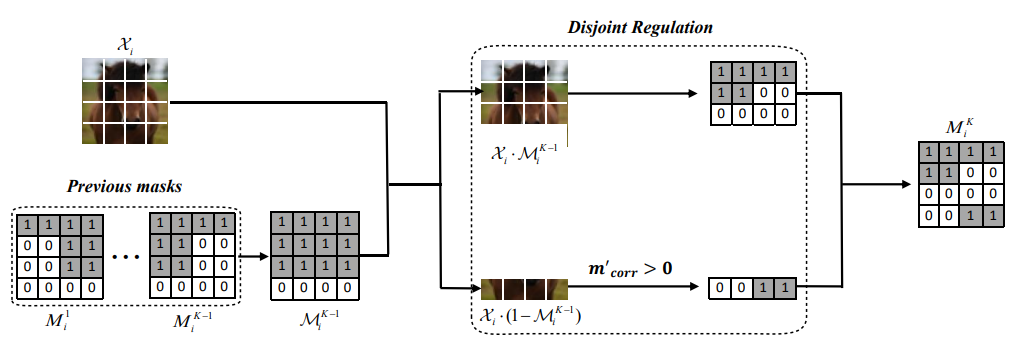
이전 view들에서 이미 mask된 영역과 아직 안 가려진 영역을 나누고, 다음 view는 아직 안 가려진 영역을 반드시 일부 포함하도록 규제함
추가로, 한 이미지를 여러 번 쓰면 batch size를 키운 것과 비슷하게 gradient variance가 줄어 generalization이 나빠질 수 있어서, prediction-rate 증가를 반영한 adaptive learning-rate scaling 도 함께 도입
[JD (Joint Distillation)]
원래의 masked prediction branch(MPB) 에 더해, visible distillation branch(VDB) 를 추가한 구조
visible token feature를 projector/predictor를 거쳐 타깃 tokenizer가 만든 표현과 맞추도록 학습시킴
visible part에도 semantic guidance를 주는 것이 학습 효율 향상에 중요하다고 봄
최종 loss는 visible distillation loss와 원래의 MIM reconstruction loss를 함께 쓰는 형태
[전체 Loss]
논문에서는 을 기본값으로 함,
visible distillation loss 와 masked reconstruction loss 를 더한 구조
- 가려진 토큰은 복원하도록 학습하고
- 보이는 토큰은 target feature에 맞추도록 distillation 하는
두 가지 목적을 동시에 최적화 (DMJD 핵심)
Revisiting Label Smoothing and Knowledge Distillation Compatibility What was Missing? (2022)
LS (Label Smoothing) 와 KD (Knowledge Distillation) 가 둘 다 soft target 을 씀
LS 는 hard label을 uniform distribution과 섞어서 target을 부드럽게 만들고, KD 는 teacher의 soft output을 student가 따라가게 만듬
핵심 기여
-
높은 에서 LS teacher를 쓰면 student 표현이 semantically similar class 쪽으로 체계적으로 이동하는 현상을 발견
-
이를 정량화하기 위해 diffusion index 를 제안
-
이 현상이 바로 기존 상반된 결과를 동시에 설명함
→ 낮은 에서는 LS의 이점이 살아 있고, 높은 에서는 systematic diffusion이 커져 LS의 이점이 사라진다는 해석이 가능
[Label Smoothing]
LS target은 정답 one-hot 와 uniform distribution을 섞은 형태
( 는 smoothing 정도, 는 클래스 수)
LS loss는 이 target과 예측 확률 사이의 cross-entropy
[Knowledge Distillation]
teacher와 student의 soft distribution을 temperature 로 부드럽게 만든 뒤 맞춤
LS와 KD의 관계 자체를 보기 위해 로 두고 soft-target distillation 효과를 중심으로 분석 (teacher soft target을 student가 얼마나 잘 따라가는지가 핵심)
[Systematic Diffusion in Student]
LS teacher로부터 높은 temperature 에서 KD를 하면, student의 penultimate representation이 무작위 방향으로 퍼지는 게 아니라 semantically similar class 방향으로 체계적으로 이동
어떤 정답 클래스 에 대해 teacher 출력 중 대부분의 오답 확률은 거의 0이지만, semantically similar class에 해당하는 몇몇 오답 확률 는 상대적으로 큼
temperature를 올리면 이런 의미 있는 오답 확률 은 정답 확률에 더 가까워지고, 아주 작은 잡음 수준의 오답 확률은 여전히 거의 영향이 없음
→ student는 모든 방향으로 퍼지는 게 아니라, 특정 유사 클래스 방향으로만 끌려감
