1. Introduction
자율 주행에서 HD 맵의 중요성과 구축의 어려움(높은 주석 비용, 유지 보수)
-
기존 온라인 맵 학습 방식인 맵 요소 감지(기하학적 정보 중심)와 중심선 인식(위상학적 정보 중심)의 한계를 지적
-
두 방식 모두 도로 구조에 대한 완전한 정보를 제공하지 못하며, 이를 보완하기 위한 후처리 과정은 계산 비용을 증가시킴
차선 세그먼트라는 새로운 표현 방식을 제안하며, 이는 기하학적 경계, 의미론적 정보, 위상학적 연결성을 모두 통합 -> 차선 세그먼트 인식을 위한 종단 간 네트워크 LaneSegNet을 제안
LaneSegNet의 두 가지 핵심 수정 사항으로 1) 차선 어텐션 모듈(Lane Attention Module)과 2) 동일한 참조점 초기화 전략(Identical Initialization Strategy)을 소개
OpenLane-V2 데이터셋에서 LaneSegNet이 기존 방법론 대비 우수한 성능과 실시간 추론 속도를 달성함
2. Related Work
-
중심선 인식 (Centerline Perception) : STSU, Can et al.(2022), CenterLineDet, Tesla의 'language of lanes', TopoNet 등 기존 연구들을 소개하며, 이들이 차선 토폴로지 학습에 집중하지만 상세한 기하학적 정보가 부족함을 언급
-
맵 요소 감지 (Map Element Detection) : BEV(Bird's-Eye-View) 인식의 중요성을 강조하며, HDMapNet, VectorMapNet, MapTR, PivotNet, StreamMapNet 등 다양한 세그멘테이션 및 벡터화 기반 연구를 소개함 -> 이들은 픽셀 수준 정보나 포인트 시퀀스를 사용하지만, 복잡한 중첩 요소 간의 관계 모델링이나 방향성 정보 부족 문제를 언급
본 논문에서는 차선 세그먼트라는 통합된 표현을 통해 기존 작업들을 포괄하고, 기하학 및 의미론적 정보를 더 잘 활용할 수 있음을 강조
3. Methodology
3.1 TASK STATEMENT OF LANE SEGMENT PERCEPTION
차선 세그먼트의 정의 : 기하학적으로는 중심선과 좌/우 차선 경계의 벡터화된 선( 개의 점으로 구성) 또는 닫힌 다각형(주행 가능 영역)으로 표현
의미론적으로는 차선 세그먼트 분류(예: 차선, 보행자 횡단보도)와 좌/우 차선 경계의 선 유형(예: 보이지 않음, 실선, 점선)을 포함
토폴로지적으로는 차선 그래프 의 노드 역할을 하며, 각 노드는 차선 세그먼트이고 엣지는 연결성을 나타냄 -> 인접 행렬로 저장됨
3.2 Framework of LaneSegNet
전체적인 파이프라인은 인코더, 디코더, 예측기로 구성됨
3.2.1 LaneSeg Encoder
ResNet-50 백본과 BEVFormer의 PV-to-BEV 모듈을 사용하여 다중 뷰 이미지를 BEV 특징 맵으로 변환
3.2.2 LANESEG DECODER
Transformer 기반 디코더를 사용하며, 특히 차선 어텐션 모듈과 동일한 참조점 초기화 전략을 포함하여 장거리 정보 포착 및 로컬 세부 정보 추출 능력을 강화
-
Lane Attention : 기존 Deformable Attention의 한계를 지적하고, 'heads-to-regions' 메커니즘을 통해 각 헤드가 특정 로컬 영역에 집중하며 장거리 컨텍스트를 수집하는 방식을 제안
-
Identical Initialization of Reference Points : 첫 번째 레이어에서 모든 쿼리가 동일한 참조점을 사용하도록 하여, 복잡한 기하학적 구조로 인한 학습 방해를 줄이고 위치 사전 지식 학습을 안정화
3.2.3 LANESEG PREDICTOR
MLPs를 사용하여 차선 세그먼트 쿼리에서 최종 예측을 생성
중심선 회귀, 좌/우 차선 경계 오프셋 예측, 인스턴스 마스크 예측, 차선 유형 및 분류 예측, 위상학적 관계(인접 행렬) 예측을 수행
3.3 Training Loss
DETR 기반의 헝가리안 알고리즘을 사용한 최적 할당을 통해 손실을 계산함
기하학적 손실(벡터화된 기하학적 거리, 마스크 손실), 분류 손실(차선 유형, 클래스), 위상학적 손실로 구성됨
4. Experiments
4.1 Dataset and Metrics
-
Dataset : OpenLane-V2 데이터셋을 사용하며, 논문의 차선 세그먼트 형식으로 재주석화
-
Metrics : 맵 요소 감지, 중심선 인식, 차선 세그먼트 인식의 세 가지 작업으로 나누어 평가함, 차선 세그먼트 인식을 위한 새로운 지표(Dls, APls, APped, mAP, TOPlsls, AEtype, AEdist)를 정의
4.2 Main Results
-
Lane Segment Perception : Tab. 1에서 LaneSegNet이 mAP 32.6%로 기존 최고 성능을 크게 뛰어넘음
-
Map Element Detection : Tab. 2에서 LaneSegNet이 이 작업에 특화된 방법론보다도 우수한 성능을 보임
-
Centerline Perception : Tab. 3에서 LaneSegNet이 중심선 인식 및 위상학적 추론에서 뛰어난 성능을 보임
4.3 Ablation Study
-
Lane Segment Formulations : Tab. 4에서 차선 세그먼트라는 통합 표현이 단일 분기 또는 다중 분기 방식보다 성능과 효율성 면에서 우수함을 입증함
-
Lane Attention Module : Tab. 5, 6, Tab. 7, 8에서 Heads-to-regions 메커니즘과 동일한 초기화 전략이 성능 향상에 크게 기여함을 보여줌
5. Conclusion
-
차선 세그먼트 인식이라는 새로운 맵 학습 프레임워크와 이를 위한 LaneSegNet 네트워크를 제안
-
차선 어텐션 모듈과 동일한 참조점 초기화 전략이라는 두 가지 혁신적인 개선 사항을 소개
-
실험 결과로 제안된 디자인의 효과를 입증
-
Limitations and Future Work : 더 많은 백본 모델 적용, 다른 데이터셋(nuScenes, Waymo)으로의 확장, 다운스트림 작업에서의 활용 등을 미래 연구 방향으로 제시
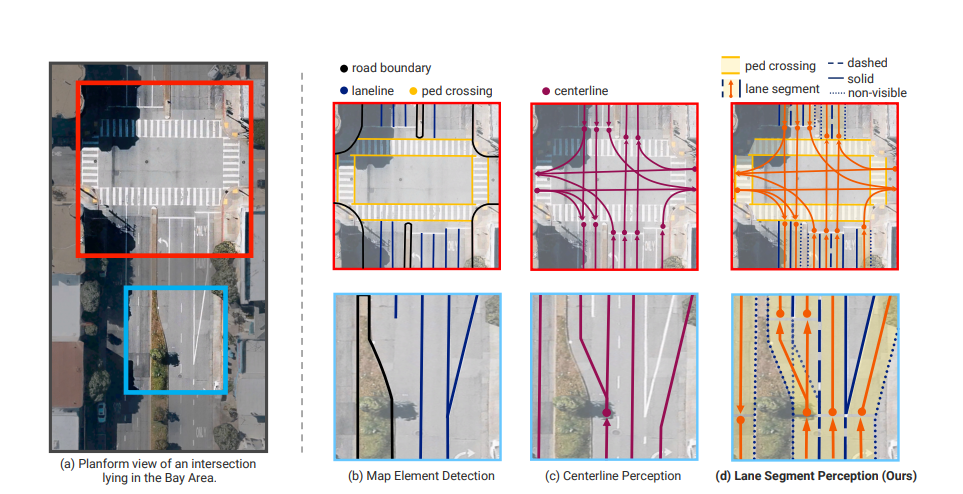
그림 1
온라인 매핑을 위한 세 가지 정식화(formulation)의 비교.
(a) 미국 캘리포니아주 베이 에어리어에 있는 교차로의 실제 장면.
(b) Map Element Detection. 이 방식은 차선선(lanelines), 횡단보도, 도로 경계를 검출할 수 있지만, 교차로나 차선이 분기/합류하는 상황에서 위상 관계(topology relationships) 를 충분히 나타내지 못한다.
(c) Centerline Perception. 이 방식은 차선의 위상 구조를 표현하지만, 이는 가상적인 표현이며 안전한 주행을 보장하는 데 필요한 중요한 물리적 기하 정보가 부족하다.
(d) Lane Segment Perception. 우리가 제안하는 이 정식화는 (b)의 기하학적 경계와 의미적 차선 유형(semantic lane types) 을 포착하는 동시에, (c)의 위상 그래프(topological graphs) 도 함께 담아낸다. 참고로, lane segment의 맥락에서는 횡단보도를 특별한 경우, 즉 가로 방향의 ‘차선’ 으로 간주한다.
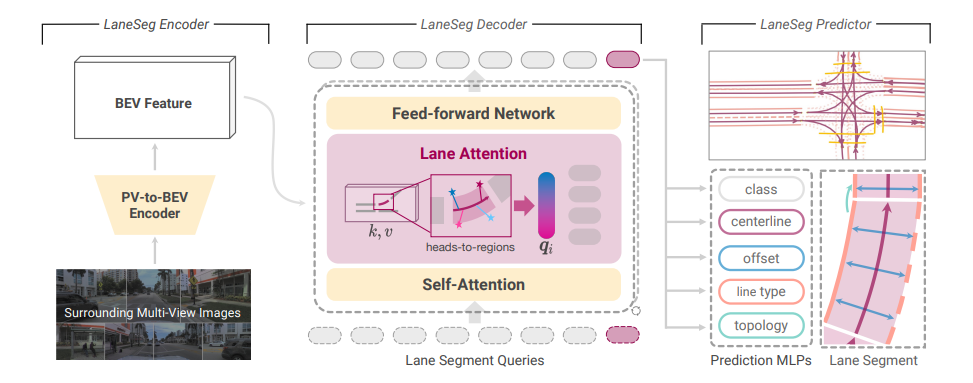
그림 2
LaneSegNet의 파이프라인.
LaneSegNet은 lane segment perception 작업을 위해 설계된 최초의 end-to-end 네트워크이다. 이 네트워크는 세 부분으로 구성된다. LaneSeg encoder 는 BEV(Bird’s-Eye View) 특징을 생성한다.
핵심인 LaneSeg decoder 는 우리가 제안한 lane attention module 을 사용하며, 이 모듈은 heads-to-regions 메커니즘과 reference point에 대한 identical initialization strategy 를 활용한다. LaneSeg predictor 는 서로 다른 MLP들에서 예측된 요소들을 조합하여 일련의 lane segment 를 형성하고, 이를 통해 도로 구조에 대한 완전한 설명을 생성한다.
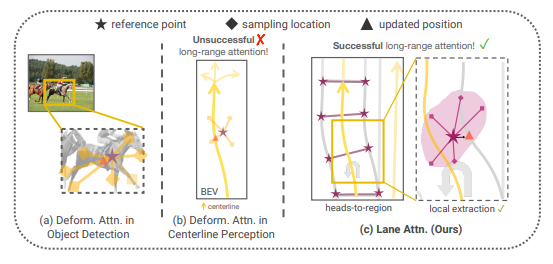
그림 3
Lane attention의 장점.
(a), (b) 기본적인 reference point를 사용하는 각 head는 객체의 형태와는 무관한 여러 방향에서 특징을 추출한다. 이것이 deformable attention이 선 형태(line-shape)의 객체에 대해 장거리 attention을 잘 수행하지 못하는 이유를 설명해준다.
(c) 반면, heads-to-regions 메커니즘의 도움을 통해 우리가 제안한 lane attention module 은 길게 뻗은 차선 형태를 따라 장거리 문맥 정보를 효과적으로 모을 수 있으며, 동시에 국소적인 세부 정보도 보존할 수 있다.
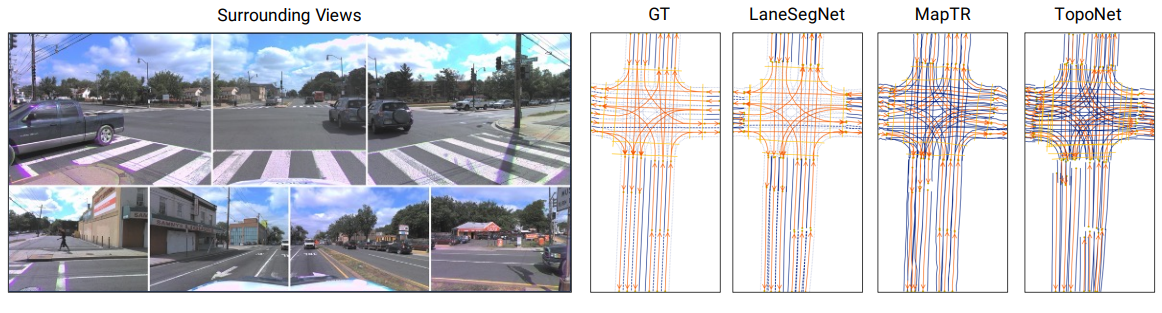
그림 4
정성적 결과.
LaneSegNet은 교차로의 위상 구조를 복원하고 보행자 횡단보도를 식별할 수 있다. 또한 다양한 종류의 차선선(laneline) 도 잘 분류한다. 하지만 카메라 시점의 한계 때문에, 교차로 양쪽에 있는 가로 방향 차선의 개수를 추정하는 데에는 오류가 발생한다.
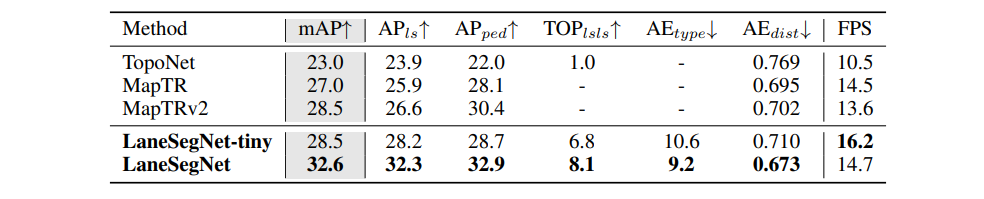
표 1
Lane segment perception.
LaneSegNet은 다른 접근법들보다 훨씬 큰 폭으로 더 뛰어난 성능을 보인다. 일관성을 유지하기 위해, 우리는 MapTR 계열에는 topology head를 추가하지 않았고, MapTR 계열이나 TopoNet에는 line type head도 추가하지 않았다. 이는 원래의 설계에 영향을 줄 수 있는 수정이 들어가는 것을 방지하기 위함이다.
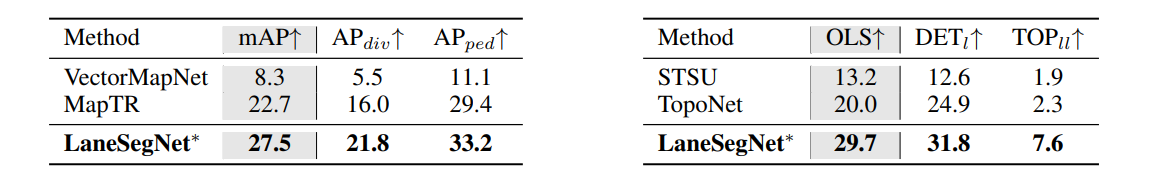
표 2, 3
< : Map element detection. LaneSegNet의 성능은 이 과업 자체를 위해 직접 학습된(native trained) 접근법들보다도 더 우수하다.
* : lane segment detection 모델의 예측 결과를 다시 형태 변환(reshaping)한 것을 의미한다.
: Centerline perception. LaneSegNet 은 centerline perception 과 topology reasoning 두 측면 모두에서 다른 방법들보다 더 뛰어난 성능을 보인다. OLS는 **과 을 바탕으로 계산된다.
* : lane segment 결과로부터 centerline을 추출한 것**을 의미한다.
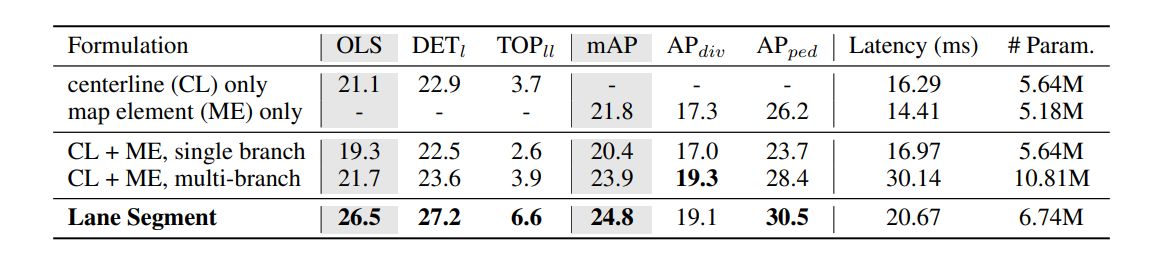
표 4
서로 다른 학습 정식화들 간의 비교.
“CL-only” (또는 “ME-only”)는 centerline perception 과업(또는 map element detection 과업)을 학습하기 위해 단일 브랜치를 사용하는 것을 의미한다.
“CL + ME”는 두 과업을 모두 수행하기 위한 멀티태스크 정식화를 뜻한다. 모든 모델은 3.2.2절에서 언급된 우리 고유의 설계는 적용하지 않은 동일한 아키텍처를 따른다.

표 5, 6
< : 서로 다른 cross-attention 설계들 간의 비교. “Deform. Attn.”은 deformable attention을 의미하고, “inst.”는 instance query를 사용하는 것을 뜻하며, “hie.”는 계층적 query 설계(hierarchical query design) 를 의미한다.
> : LaneSeg decoder의 설계들에 대한 ablation study로, 여기에는 heads-to-regions (heads2r.) 와 reference point의 identical initialization (ident. init.) 이 포함된다.
