Abstract
저자들은 기존 end-to-end autonomous driving(E2E-AD)이 open-loop에서는 좋아 보여도, 실제 주행 시뮬레이션에 가까운 closed-loop 평가 성능은 아직 부족하다고 본다. 이를 해결하기 위해 두 가지를 제안한다.
첫째, multi-granularity planning query representation 이다. waypoint를 단순히 하나의 trajectory로 예측하지 않고,
- temporal waypoint
- spatial waypoint
- driving-style waypoint
로 나눈 뒤, 각 waypoint를 또 여러 sampling 방식으로 구성한다. 이렇게 하면 trajectory supervision이 더 풍부해지고 ego vehicle 제어가 더 정교해진다.
둘째, planning deformable attention 이다. planning trajectory의 기하 정보를 이용해, 미래 경로 주변에 해당하는 이미지 feature를 직접 가져오게 만든다. 이 둘을 합쳐서 perception, prediction, planning을 하나의 decoder 안에서 함께 수행하는 HiP-AD를 제안한다. Bench2Drive와 nuScenes 실험에서 좋은 성능을 보였다고 한다.
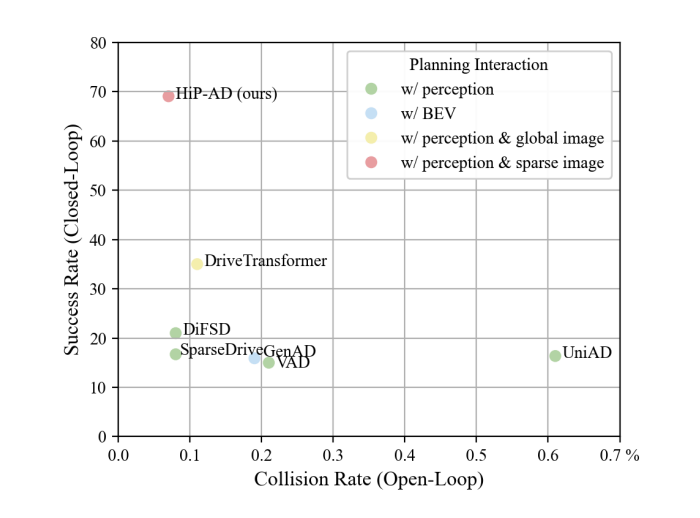
그림 1
기존 최신(state-of-the-art) 방법들을, nuScenes 데이터셋의 open-loop 지표인 Collision Rate와 Bench2Drive 데이터셋의 closed-loop 지표인 Success Rate를 기준으로 비교한 것이다. 이때 왼쪽 위에 위치할수록 더 좋은 성능을 의미한다. 범례(legend)는 서로 다른 planning interaction 방법들을 나타낸다.
1. Introduction
[문제의식]
기존 E2E-AD는 raw sensor에서 바로 planning trajectory를 예측하지만, open-loop와 closed-loop 사이 성능 차이가 크다.
- open-loop : GT trajectory와 얼마나 비슷한가
- closed-loop : 실제로 안전하고 성공적으로 주행하는가
즉, trajectory fitting이 잘 된다고 해서 실제 driving behavior가 좋은 것은 아니라는 게 핵심 문제다. 논문은 특히 기존 방법들이 open-loop collision rate는 낮아도 Bench2Drive success rate가 낮다고 지적한다.
[기존 방법의 한계]
저자들은 planning이 충분히 활용되지 못한 이유를 크게 두 가지로 본다.
1) waypoint 설계가 너무 단순함
많은 방법은 ego trajectory를 그냥 하나의 regression target처럼 다루거나, temporal/spatial 정도만 나눈다. 하지만 실제 closed-loop 주행에서는
- 거시적인 경로 판단
- 미세한 steering/braking 제어
- overtaking, traffic sign 대응 같은 행동 스타일
이 모두 중요하다. 그래서 저자들은 waypoint를 더 풍부하게 설계해야 한다고 본다.
2) planning query와 scene interaction이 불충분함
기존 방법은 planning query가 perception output이나 BEV feature와만 제한적으로 상호작용하는 경우가 많다. 특히 multi-view image와 interaction할 때 global attention만 쓰면, 실제 주행 trajectory와 관련 있는 위치의 feature를 잘 못 가져올 수 있다. 그래서 trajectory의 물리적 위치를 이용해 planning trajectory 주변 feature를 sparse하게 샘플링하는 방식이 필요하다고 주장한다.
[이 논문의 핵심 기여]
-
multi-granularity planning query representation
-
planning deformable attention
-
perception과 planning이 함께 상호작용하는 unified decoder
즉, 이 논문은 “planning을 더 잘하기 위한 representation + interaction 방식” 을 강화한 논문이라고 보면 된다.
2. Related Work
[2.1 Dynamic and Static Perception]
이 부분은 perception 관련 배경 설명이다.
-
dynamic object detection 은 BEV 기반과 sparse query 기반으로 나뉜다.
-
static map detection 은 rasterized 방식과 vectorized 방식으로 나뉜다.
저자들은 최근 흐름이 sparse query나 vectorized representation 쪽으로 가고 있다고 정리한다. 이는 뒤에서 HiP-AD가 query 기반 unified decoder를 쓰는 배경이 된다.
[2.2 Motion Prediction and Planning]
여기서는 trajectory prediction과 planning 관련 기존 연구를 정리한다.
-
전통적 planning은 perception/prediction 이후의 별도 모듈이었음
-
최근엔 learning-based planning, 직접 control/trajectory를 예측하는 방법, reinforcement learning 기반 방법도 등장함
즉, planning이 단순 후처리 모듈이 아니라 학습 가능한 핵심 task가 되었다는 흐름을 설명한다.
[2.3 End-to-end Autonomous Driving]
여기서는 UniAD, VAD, SparseDrive, Para-Drive, DriveTransformer 같은 대표 E2E-AD를 비교한다.
핵심은 기존 방법들도 perception/prediction/planning을 통합하려 했지만,
-
planning query design이 단순하거나
-
planning interaction이 충분히 정교하지 않거나
-
closed-loop 성능이 아직 부족하다는 것
이다. HiP-AD는 이 부분을 개선하는 방향으로 제안되었다.
3. Method
[3.1 Overview]
전체 구조는 Backbone + FPN + Unified Decoder + Task Heads 로 구성된다.
입력은 multi-view image이고, decoder 안에는 세 종류의 query가 들어간다.
-
agent query : object detection / motion prediction 담당
-
map query : online mapping 담당
-
planning query : ego trajectory planning 담당
이 planning query가 이 논문의 핵심인데, 단일 query가 아니라 multi-granularity waypoint representation으로 구성된다. 그리고 decoder를 거치며 각 task query가 업데이트되고, 마지막에 detection/map/planning head가 각 결과를 예측한다. 그림 3이 전체 파이프라인을 보여준다.
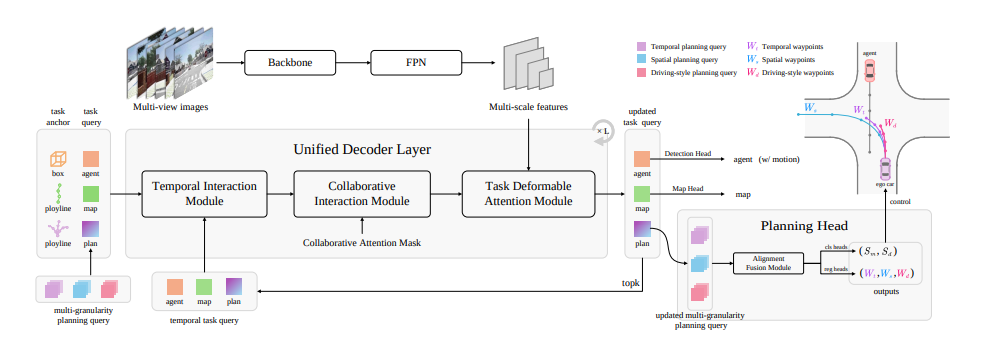
그림 3
HiP-AD의 전체 프레임워크이다.
이 프레임워크는 이미지 특징을 추출하기 위한 Backbone과 FPN, 쿼리를 반복적으로 업데이트하는 통합 디코더(unified decoder), 그리고 다중 작업 예측(multi-task prediction) 을 위한 여러 헤드(heads) 로 구성된다.
통합 디코더의 입력은 task anchor 와 여러 종류의 query(agent, map, planning)이며, 이때 planning query 는 다중 granularity waypoint 표현으로 이루어진다.
각 통합 디코더 레이어에서는
먼저 task query들이 각각 temporal query 와 따로 상호작용하고,
그다음 서로 협력적으로 상호작용한 뒤,
마지막으로 이미지 특징과도 반복적인 방식으로 상호작용한다.
최종적으로 업데이트된 task query들은 각각 대응되는 head로 전달되어
인식(perception), 맵 예측, 계획(planning) 등의 작업을 수행한다.
[3.2 Unified Decoder]
Unified decoder는 3개 모듈로 구성된다.
(1) Temporal Interaction Module
현재 프레임의 task query가 이전 프레임에서 저장해둔 top-k query들과 상호작용한다.
즉, temporal memory를 이용해 과거 정보를 현재 판단에 반영한다. 특히 planning query가 과거 perception query와도 상호작용해 주변 객체의 과거 맥락을 참고할 수 있게 한다.
(2) Collaborative Interaction Module
이 모듈은 task 간 상호작용을 담당한다.
agent, map, plan query가 각자 self-attention 도 하고, unified self-attention 으로 서로 정보도 교환한다.
여기서 중요한 점은 그냥 global attention을 쓰는 게 아니라, 기하학적 관계 기반 attention mask를 사용한다는 것이다. 예를 들어 perception query끼리는 BEV 상 거리 정보가 attention weight에 반영된다. 즉, 가까운 객체끼리 더 강하게 상호작용하게 만든다. 반면 planning query는 전체 task 정보에 접근할 수 있게 둔다.
Collaborative Intercation 에서는 global attention 대신 거리 기반 geometric attention map 을 넣음
여기서 는 object 간 거리, 는 query로부터 학습되는 계수임.
즉, 가까운 객체들에 더 집중하도록 BEV receptive field를 조절하는 구조임. planning query는 거리 제한 없이 모든 task 정보에 접근할 수 있게 둠.
(3) Task Deformable Attention Module
이 부분이 HiP-AD의 큰 차별점이다.
기존에는 planning query가 이미지 feature 전체와 global attention을 하는 경우가 많았는데, 논문은 그것보다 trajectory 주변의 관련 이미지 feature만 sparse하게 샘플링하는 게 더 낫다고 본다.
그래서 planning anchor(미래 waypoint)를 camera로 image plane에 projection하고, 그 reference point 주변에서 deformable attention으로 feature를 뽑는다.
Task deformable attention에서는 planning query의 future waypoint를 여러 높이값에 배치한 뒤 카메라로 투영해서, trajectory 주변 image feature를 sparse하게 sampling함.
즉 planning anchor 를 projection 함수 로 이미지에 보내고, 각 view의 feature 에서 trajectory 주변을 긁어와 collision을 피하는 데 필요한 sparse scene representation을 학습함.
수식으로는 위와 같이 planning deformable attention(PDA)을 정의하고, planning trajectory 주변의 scene representation을 학습하도록 한다. 쉽게 말하면:
“ego가 앞으로 갈 경로 근처에 뭐가 있는지 직접 보게 하자”
라는 아이디어다. 이는 특히 collision avoidance나 closed-loop behavior 개선과 연결된다. 그림 4가 이 구조를 잘 보여준다.
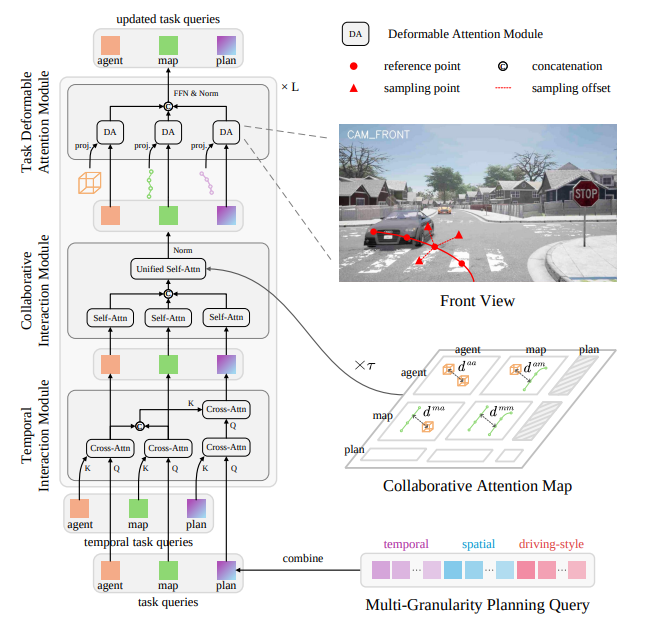
그림 4
포괄적인 상호작용(comprehensive interaction)을 위해, unified decoder layer 안에 포함된 세 가지 서브모듈의 상세 아키텍처를 보여주는 그림이다.
[3.3 Hierarchical and Multi-granularity Planning]
Hierarchical Waypoints
기존 방법은 temporal 또는 spatial waypoint 정도만 쓰는 경우가 많았는데, 이 논문은 waypoint를 3종류로 나눈다.
1. Temporal waypoints
- 일정 시간 간격으로 future position 예측
- 주로 시간 축 기준 trajectory supervision
2. Spatial waypoints
- 일정 거리 간격으로 경로를 표현
- lateral control에 유리
3. Driving-style waypoints
- temporal waypoint와 비슷하지만 속도 정보를 더 반영
- overtaking, emergency brake 같은 행동 스타일 학습에 유리
즉, 단순히 “어디로 갈까”만이 아니라, “어떤 속도/행동 스타일로 갈까”까지 예측하게 만든다.
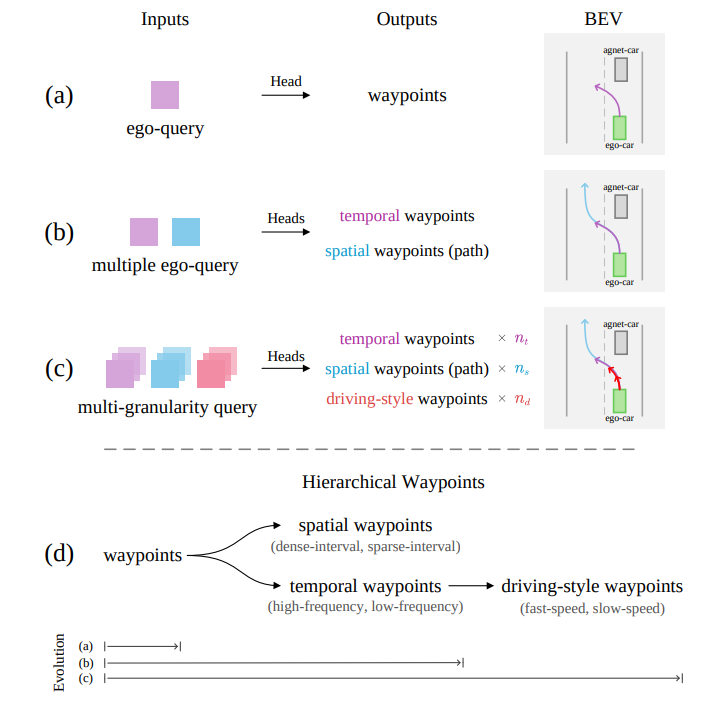
그림 2
이 도식은 웨이포인트를 예측하기 위한 기존 방법들(a-b)과, 우리가 제안하는 다중 granularity planning 설계(c)를 비교한다. 여기서 , , 는 각각 웨이포인트 유형별 granularity 의 개수를 의미하며, 이는 주파수(frequency), 간격(interval), 속도(speed) 측면에서 정의된다. 또한 (d)는 서로 다른 샘플링 전략에 따라, 구체적인 granularity가 적용된 계층적 웨이포인트가 어떻게 변화하는지를 보여준다.
Multi-sampling / Multi-granularity
각 waypoint 종류를 또 여러 granularity로 나눈다.
-
spatial : dense interval / sparse interval
-
temporal : high frequency / low frequency
-
driving-style : 다양한 speed range + frequency
이렇게 하는 이유는 역할 분담 때문이다.
-
sparse한 waypoint : 더 긴 horizon의 global context 제공
-
dense한 waypoint : 미세한 control에 유리
-
driving-style waypoint : 속도/행동 전략 학습
즉, coarse한 정보와 fine한 정보를 동시에 쓰겠다는 발상이다. 저자들은 이것이 ego hesitation, 즉 차가 애매한 상황에서 계속 머뭇거리다가 timeout 되는 문제를 줄여준다고 설명한다.
Multi-granularity Planning Query
planning query는 modality와 granularity를 함께 가진다.
예를 들어 left / straight / right 같은 modality별로 여러 granularity의 query를 둔다. decoder를 거친 뒤에는 같은 modality 안의 서로 다른 granularity query를 합쳐서 fused query를 만든다. 그 fused query로 각 granularity별 waypoint를 예측한다.
multi-granularity planning query는 개의 query group과 개의 modality를 갖고, 각 modality 안에서 granularity별 query를 합쳐 fused query를 만듦.
핵심 식은 다음처럼 정리할 수 있음.
그리고 fused query로 각 granularity의 waypoint와 modality score를 예측함.
여기에 driving-style 분류 점수도 별도로 둠.
즉 한 modality 안에서 여러 granularity가 서로 보완되도록 만들고, 그 fused representation으로 전체 trajectory를 더 잘 예측하게 하는 구조임.
핵심은, 여러 granularity가 따로 노는 게 아니라 같은 modality 안에서 alignment/fusion되어 서로 보완되게 만든다는 점이다. 그림 5가 이를 설명한다.
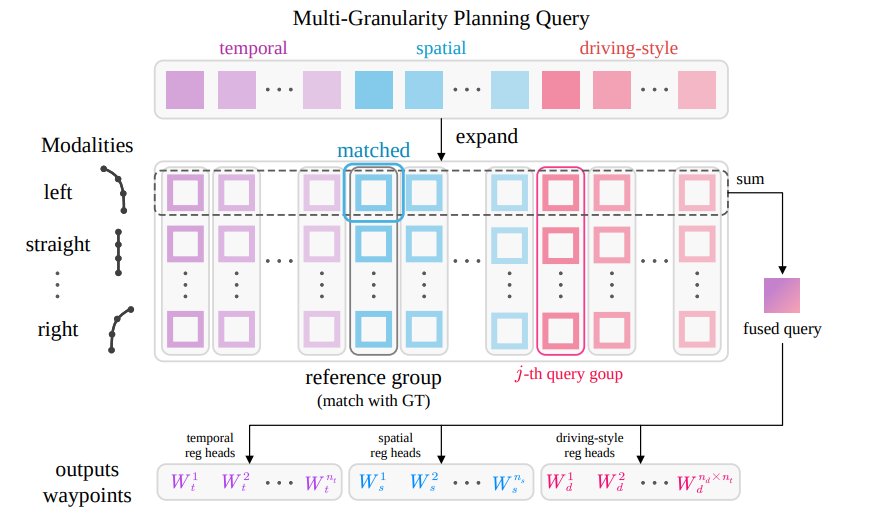
그림 5
웨이포인트 예측을 위해 정렬 기반 융합(alignment fusion)을 포함한 다중 granularity query 아키텍처를 나타낸 그림이다. 이해를 돕기 위해 classification head는 생략하였다.
Align Matching
학습 시 각 query group마다 따로 modality matching을 하면 granularity별 supervision이 어긋날 수 있다. 그래서 이 논문은 reference group 하나를 기준으로 modality matching을 정하고, 나머지 granularity들도 그 결과를 공유하게 한다.
즉,
-
한 granularity에서 “이 modality가 GT랑 가장 가깝다”를 찾고
-
다른 granularity도 같은 modality를 따라가게 만든다.
이렇게 해서 여러 granularity가 같은 planning intention을 배우도록 정렬한다.
[3.4 Waypoints Selection and Action Control]
Selection
추론 시 최종 waypoint를 고르는 과정은 2단계다.
-
modality score로 left / straight / right 중 최적 modality 선택
-
waypoint 종류별로 사용할 granularity 선택
- spatial : dense interval 선택
- temporal : high-frequency 선택
- driving-style : style classification score 기반 선택
즉, 모든 예측을 다 쓰는 게 아니라, control에 더 적합한 대표 waypoint를 고른다.
Control
- lateral control : spatial waypoint 사용
- longitudinal control : driving-style waypoint를 우선 사용
단, driving-style waypoint의 속도가 선택된 style의 범위와 맞지 않으면 fallback으로 temporal waypoint를 사용한다.
즉, stering은 spatial, 속도 조절은 driving-style 중심으로 제어한다는 점이 특징이다.
[3.5 Loss Functions]
전체 loss는 detection, motion, map, planning loss의 합이다.
그중 planning loss는
- multi-granularity waypoint regression loss
- modality classification loss
- driving-style classification loss
로 구성된다. 논문은 VAD 계열에서 쓰이던 추가적인 constraint loss나 denoising trick 없이도 좋은 성능을 얻었다고 강조한다. 즉, 핵심 성능 향상은 복잡한 trick보다 planning representation과 interaction 설계에서 온다는 주장이다.
4. Experiments
[4.1 Dataset and Metrics]
Dataset
주요 실험은 Bench2Drive 에서 한다.
이 데이터셋은 CARLA 기반의 closed-loop benchmark 로, 다양한 interactive scenario에서 실제 주행 능력을 평가하기 좋다. 추가로 nuScenes 에서도 open-loop/perception 성능을 평가한다.
Metrics
- closed-loop : Driving Score, Success Rate, Efficiency, Comfortness
- open-loop : L2 displacement error, Collision Rate
- nuScenes에서는 detection/map/tracking/motion prediction metric도 함께 본다.
[4.2 Implementation Details]
기본 backbone은 ResNet50, decoder layer는 6개다. Planning query는 총 480개, modality는 48개, granularity는 10개로 구성한다.
Granularity 예시는 다음과 같다.
- spatial: 2m / 5m interval
- temporal: 2Hz / 5Hz
- driving-style: 3개 speed range × 2개 frequency
학습은 2단계로 진행되며, 처음에는 driving-style head를 끄고 학습한 뒤, 이후 fine-tuning에서 활성화한다. Bench2Drive에서는 8개의 RTX 4090으로 학습했다고 적혀 있다.
[4.3 Main Results]
Bench2Drive 결과
이 논문의 가장 중요한 성과다.
HiP-AD는 Bench2Drive에서 기존 SOTA보다 큰 폭으로 성능이 오른다.
- Driving Score : 86.77
- Success Rate : 69.09%
비교 대상으로 제시된 DriveTransformer-Large는
- Driving Score : 63.46
- Success Rate : 35.01%
즉, closed-loop 성능에서 큰 차이를 보인다. 논문은 이것을 multi-granularity planning과 PDA 덕분이라고 해석한다. 특히 overtaking, emergency brake, traffic sign 대응 등 multi-ability 성능도 크게 향상되었다.
nuScenes 결과
nuScenes에서는 open-loop planning과 perception 성능을 평가한다. HiP-AD는 planning에서 낮은 collision rate를 유지하면서, detection / map / tracking / motion 예측도 강한 성능을 보인다.
즉, “closed-loop만 잘하고 perception은 약한 모델”이 아니라, 전반적인 멀티태스크 성능도 괜찮다는 걸 보여주려는 section이다.
[4.4 Ablation Study]
(1) Architecture와 module 효과
Table 5를 보면,
- unified decoder
- planning deformable attention(PDA)
- multi-granularity(MG)
를 하나씩 넣어볼 때 성능이 올라간다. 특히 PDA + MG를 둘 다 넣었을 때 closed-loop 성능이 가장 좋다. 또한 sequential 구조보다 unified 구조가 더 좋았다. 즉, perception과 planning을 따로 하는 것보다 같은 decoder에서 반복적으로 상호작용시키는 방식이 더 효과적이었다는 뜻이다.
(2) Multi-granularity planning 효과
Table 6은 매우 중요하다.
기본 temporal-only waypoint에서 시작해 spatial waypoint, fusion, align-matching, dense sampling, driving-style을 차례대로 넣으면 성능이 계속 올라간다.
특히 마지막 setting에서
- Driving Score 88.3
- Success Rate 72.7%
를 얻는다.
또한 timeout 비율이 크게 줄어드는데, 이는 multi-granularity planning이 ego hesitation을 줄여준다는 저자 주장과 맞는다. 즉, 차가 애매한 상황에서 너무 오래 서 있지 않고 더 적극적으로 행동을 학습했다는 의미다.
[4.5 Qualitative Results]
그림 6 및 supplementary figure들에서 시각화 결과를 보여준다.
예를 들어,
- 비보호 좌회전에서 자전거를 피하며 회전하는 장면
- roadside hazard를 보고 감속하는 장면
등이 제시된다. spatial waypoint는 경로 제어, driving-style waypoint는 속도/행동 제어에 기여하는 식으로 해석된다. 즉, 제안한 waypoint 분해가 실제 장면에서도 의미 있게 작동한다고 보여주려는 부분이다.

그림 6
폐루프(closed-loop) 경로에서의 HiP-AD 정성적 결과를 보여준다. 여기에는 인지(perception), 움직임(motion), 그리고 계획 경로(planning trajectories)가 포함된다. 공간적 웨이포인트(spatial waypoints)는 하늘색으로 표시되고, 주행 스타일 웨이포인트(driving-style waypoints)는 빨간색으로 표시된다. 중요한 객체들은 노란색 원으로 강조된다.
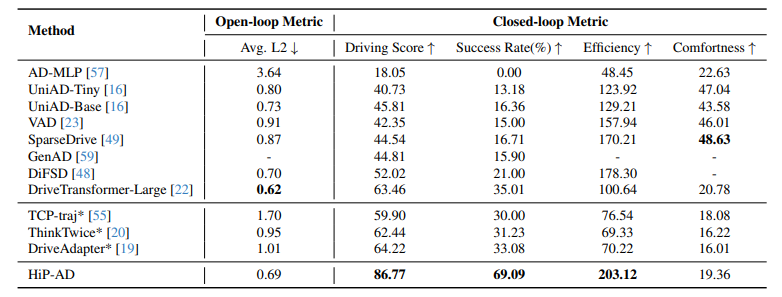
표 1
Bench2Drive에서의 planning에 대한 open-loop 및 closed-loop 결과. Avg. L2는 2Hz 기준으로 2초 동안의 예측값들에 대해 평균낸 값이다. * 표시는 expert feature distillation을 사용했음을 의미한다.
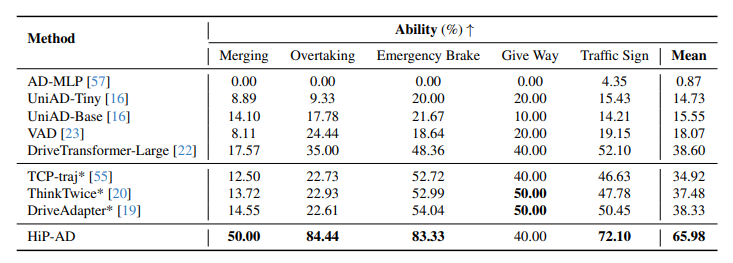
표 2
Bench2Drive에서의 E2E-AD 방법들의 다중 능력(Multi-Ability) 결과. * 표시는 expert feature distillation이 사용되었음을 의미한다.
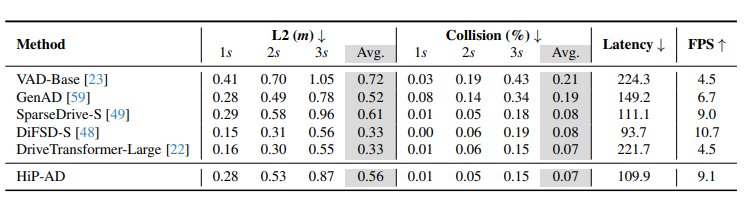
표 3
[28]의 평가 프로토콜을 사용한 nuScenes 검증 데이터셋에서의 open-loop planning 평가 결과. DriveTransformer [22]의 지연 시간(latency)과 FPS는 NVIDIA H800 GPU에서 측정되었고, 나머지 방법들은 NVIDIA 3090 GPU에서 측정되었다.
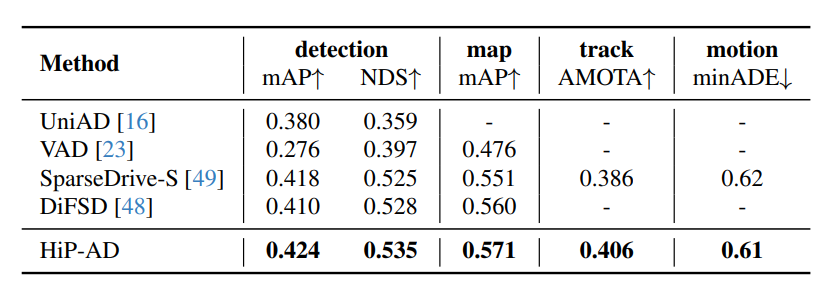
표 4
nuScenes 검증 데이터셋에서의 인식(perception), 매핑(mapping), 추적(tracking), 그리고 움직임 예측(motion prediction) 성능 비교
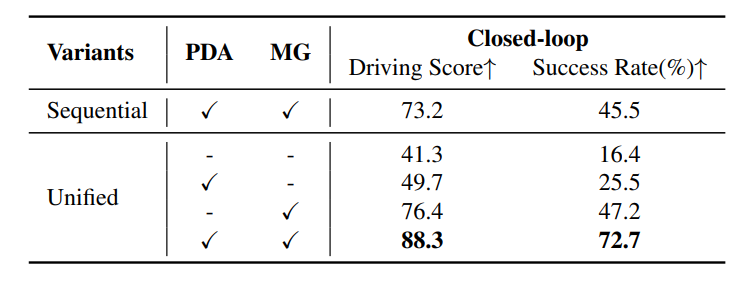
표 5
아키텍처와 제안된 모듈들에 대한 ablation study. PDA는 Planning Deformable Attention, MG는 Multi-Granularity를 의미한다.
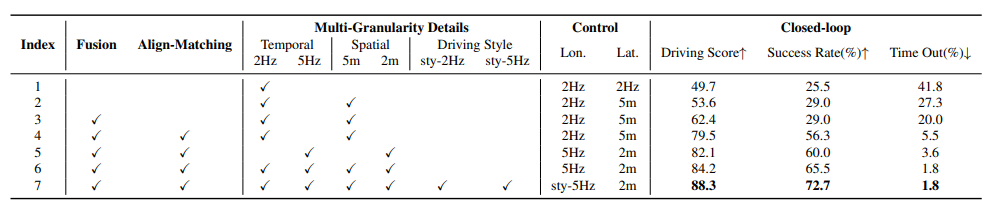
표 6
multi-granularity planning에 대한 ablation study. Lon.과 Lat.은 각각 longitudinal control(종방향 제어)과 lateral control(횡방향 제어)을 의미한다.
5. Conclusion and Limitation
결론
HiP-AD는
- unified decoder
- planning deformable attention
- hierarchical + multi-granularity planning
을 결합한 E2E-AD 프레임워크다. 저자들은 이것이 perception, prediction, planning을 함께 수행하면서도 planning 품질을 크게 높여 closed-loop driving 성능을 크게 향상시켰다고 결론 내린다.
한계
논문이 직접 언급한 limitation도 있다.
- 아직 실제 도로(real-world) 검증이 더 필요함
- 뒤에서 빠르게 접근하는 차량을 회피하는 문제는 여전히 어려움
즉, 시뮬레이터와 benchmark에서는 강하지만, real-world robustness는 앞으로 더 검증해야 한다는 의미다.
