3D Gaussian Splatting(3DGS)의 모바일 실시간 배포가 어려운 이유(정렬 기반 alpha blending의 비용, 큰 저장 요구량)를 제기하고, 이를 해결하기 위한 Mobile-GS를 제안
핵심 기여는 (1) 정렬을 제거하는 depth-aware order-independent rendering, (2) order-independent 렌더링에서 발생하는 투명도 아티팩트 완화를 위한 neural view-dependent enhancement, (3) 1차 spherical harmonics distillation, (4) neural vector quantization, (5) contribution-based pruning
이러한 구성으로 모바일에서 실시간(예: Snapdragon 8 Gen 3에서 116 FPS) 및 저용량(수 MB 수준) 배포가 가능함을 주장함
1. Introduction
NeRF 계열과 3DGS의 장점(고품질, differentiable 표현)을 요약하고, 모바일에서의 병목(특히 깊이 정렬과 alpha blending)을 식별
모바일 실시간을 위해 필요한 요소로서 (1) order-free rendering, (2) quantization, (3) Gaussian 수 감소를 제시
본문에서 제안하는 Mobile-GS의 전체 구성 요소와 목표 : 고품질 유지, 실시간 성능, 초저용량
2. Related Work
3DGS와 그 변형들(Scaffold-GS, Mini-Splatting 등), order-independent transparency(OIT) 관련 기존 기법들(depth peeling, k-buffer, stochastic transparency 등), 정렬-없는 Gaussian 렌더링 연구들을 정리
Gaussian 압축/양자화/프루닝 관련 최근 작업들을 개괄하고, 기존 방법들이 정렬을 유지하거나 모바일 제약에서 한계가 있음을 지적
3. Methodology
Mobile-GS의 핵심 구성 요소들을 자세히 설명 : depth-aware order-independent rendering, neural view-dependent enhancement, first-order SH distillation, neural vector quantization, contribution-based pruning.
각 구성 요소가 문제를 어떻게 해결하는지 (정렬 제거→병렬화, 신경망으로 뷰 의존성 보정, SH 축소로 저장 절감 등)를 논의
3.1 Depth-aware Order-independent Rendering
전통적 alpha blending은 깊이 정렬을 필요로 하며, 이 정렬이 모바일에서 큰 병목이라고 지적함
Mobile-GS에서는 정렬 없이 모든 관련 Gaussian 기여를 가중합하는 방식으로 픽셀 색을 계산
- 주요 렌더링 식은 다음과 같음
여기서 는 전역 투과도, 는 i번째 Gaussian의 색, 는 opacity 이며, 는 깊이, 스케일 기반의 가중치
- 가중치 설계는 다음과 같음
여기서 는 카메라 기준 깊이, 는 Gaussian의 최대 스케일, 는 view-dependent 파라미터
이렇게 하면 정렬 비용을 제거하여 병렬 누적이 가능해지고, 깊이에 따른 기여 감쇠와 스케일 강조로 원치 않는 먼 오브젝트 기여를 줄임
단점으로 겹침 영역에서의 투명도 애칭(artifacts)이 생길 수 있음을 인정함
Neural View-dependent Enhancement
order-independent 렌더링에서 발생하는 투명도 문제를 완화하기 위해, 각 Gaussian별로 뷰 의존적 opacity와 가중치 보정값을 MLP로 예측
입력으로는 카메라 -> Gaussian 벡터 , 스케일 , 회전 , SH 계수 등을 사용함
- 예측 구조는 다음과 같음
여기서 는 시점-의존 opacity, 는 sigmoid
이 보정은 order-free 방식에서 발생하는 시각적 흐림과 반투명 문제를 줄여 고품질을 유지하도록 함
3.2 Distillation and Quantization
First-order Spherical Harmonics Distillation
원래 3DGS가 3차 SH (3×16)를 쓰는 반면, teacher 모델을 통해 1차 SH (3×4)로 지식을 증류하여 저장량과 계산을 줄임, 증류 손실은 픽 단위 색 차이를 최소화하는 형태로 정의됨
깊이 증류는 scale-invariant 형태의 로그-차이 손실을 사용
- 예시는 다음과 같음
여기서
-
Neural Vector Quantization (NVQ) : Gaussian 속성 벡터를 개의 서브벡터로 분할하고 각 서브공간마다 코드북을 학습해 양자화, 마지막으로 허프만 코딩으로 엔트로피 압축을 적용함
-
SH 계수를 diffuse 와 view-dependent 로 분해하고, 경량 MLP 로 재구성함
이러면 모든 Gaussian에 고차원 SH를 저장할 필요 없이 코드 및 작은 MLP만 저장하여 용량을 줄임
3.3 Contribution-based Pruning
Gaussian의 기여도를 opacity와 최대 스케일 통계 기반으로 판단하여 pruning 후보를 선정
- 매 반복 에서 opacity 와 의 -quantile을 이용해 후보 집합을 구하고, 누적 투표 방식으로 안정적으로 반복적으로 낮은 기여의 Gaussian을 제거 (식으로 요약됨)
이 접근은 초기 학습 중 불필요한 Gaussian을 점진적으로 제거해 모델 크기와 계산량을 줄임
3.4 Implementation
전체 손실은 색상 손실(혼합 L1 + DSSIM)과 증류/깊이 손실을 합친 형태
CUDA 커널과 Vulkan(모바일) 구현을 통해 모바일 배포를 고려한 최적화를 수행함
학습 파이프라인(초기화, quantization 시점, pruning 스케줄 등)도 상세히 기술되어 있음
4. Experiments
4.1 Quantitative and Qualitive Results
-
Mip-NeRF360, Tanks&Temples, Deep Blending 등에서 SOTA 방법들과 비교해 Mobile-GS가 PSNR/SSIM/LPIPS, FPS, 저장공간 면에서 균형 잡힌 우수성을 보인다고 보고
-
테이블에서 Mobile-GS는 매우 작은 저장공간(수 MB)과 높은 FPS(데스크탑/모바일 모두)로 좋은 품질을 유지함을 보임
-
모바일(예: Snapdragon 8 Gen 3) 배포 결과도 제시되어 Cold-start와 Steady-state FPS, 전력 소모 측정 등 실사용 지표를 제공함
4.2 Ablation Study
-
핵심 구성요소(정렬 제거, view-dependent 보정, NVQ, SH distillation 등)를 하나씩 제거한 결과를 제시하여 각 요소의 기여를 정량화
-
예: order-independent 렌더링을 제거하면 PSNR이 약간 증가하지만(FP S 감소), view-dependent 보정을 제거하면 PSNR이 크게 떨어짐 등을 보고
-
pruning threshold, 코드북 크기 등 하이퍼파라미터 민감도도 분석
5. Conclusion
-
Mobile-GS가 모바일에서 실시간 Gaussian Splatting을 가능하게 하는 통합적 해법임을 정리
-
정렬 없는 렌더링, 신경 보정, SH 증류, NVQ, pruning의 결합으로 고품질-저용량-고속의 트레이드오프를 달성했다고 결론지음
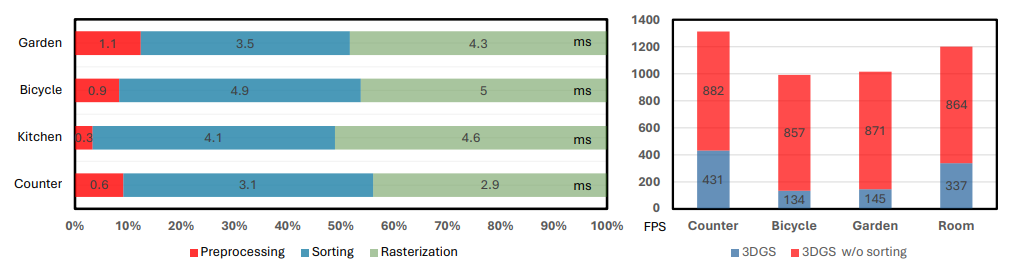
그림 1
Mobile-GS는 실시간 Gaussian Splatting 방법 중 최초로, Snapdragon 8 Gen 3 GPU가 탑재된 모바일 기기에서 Bicycle 장면을 1600 × 1063 해상도로 116 FPS의 속도로 렌더링할 수 있는 방법이다. 이는 (a)에서 확인할 수 있다.
또한 우리는 (b)와 (c)에서 RTX 3090 Ti GPU를 사용하여 렌더링 품질, 저장 비용, 추론 속도를 평가하였다. Mobile-GS는 깊이 인지 순서 독립 렌더링(depth-aware order-independent rendering), 압축(compression), 그리고 증류(distillation) 기법을 통합함으로써, 원래의 3DGS와 비교해도 비슷한 수준의 렌더링 품질을 유지한다.
동시에, 저장 용량은 4.8MB까지 크게 줄였고, unbounded scene에서는 1098 FPS를 달성하여, 모바일 기기에서 효율적으로 배포될 수 있음을 보여준다.
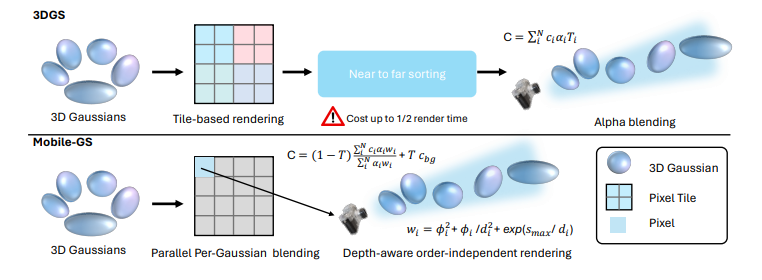
그림 2
정렬(sorting)은 주요 성능 병목이다.
왼쪽 : 원래의 3DGS에 대한 실행 시간 분석 결과, 정렬 연산이 추론 과정에서 상당한 계산 오버헤드를 유발한다는 점을 보여준다.
오른쪽 : 정렬 단계를 제거하면 3DGS의 속도가 크게 향상되며, 원래 구현과 비교했을 때 몇 배 수준의 속도 향상을 달성할 수 있다.
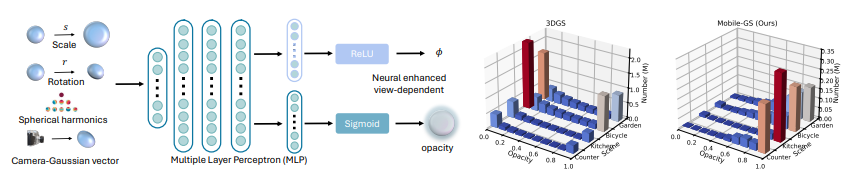
그림 3
제안하는 Mobile-GS의 렌더링 파이프라인을 기존 3DGS와 비교한 내용이다. 추론 단계(inference stage) 에서, 제안한 방법은 기존 3DGS와 달리 정확한 알파 블렌딩(alpha blending) 을 위해 일반적으로 필요했던 타일 기반 렌더링과 3D 가우시안 정렬 과정을 제거한다.
대신, 먼저 각 3D 가우시안이 관련된 픽셀들에 대해 자신의 색을 병렬로 계산하고, 각 픽셀에 대한 색 값을 누적한다. 그런 다음. 전경(foreground) 과 배경(background) 색을 한 번의 패스(single pass) 로 합성한다.
또한 성능을 더 높이면서도 시각적 품질을 유지하기 위해, 기존의 정렬 의존적인 알파 블렌딩을 대체하는 깊이 인식(order-independent) 렌더링 전략을 제안한다.

그림 4
시점 의존 불투명도 모델링의 전체 구조와 시각화를 보여준다.
왼쪽 : 저자들은 3D 가우시안의 스케일(scale), 회전(rotation), 구면조화함수(spherical harmonics), 그리고 카메라에서 3D 가우시안을 향하는 벡터를 입력으로 받는 MLP를 사용하여, 시점 의존적인 불투명도(view-dependent opacity) 를 예측한다.
오른쪽 : Mobile-GS가 불필요한 opacity는 제거하고, 높은 opacity를 갖는 중요한 가우시안은 유지 하는 모습을 보여준다. (Opacity : 불투명도)

그림 5
기존 방법들과 우리가 제안한 Mobile-GS의 정성적 비교. 우리는 우리 방법의 성능을 더 잘 보여주기 위해 장면별 저장 비용과 FPS를 제시한다. 우리는 차이점을 강조하기 위해 확대된 부분들을 추출한다.
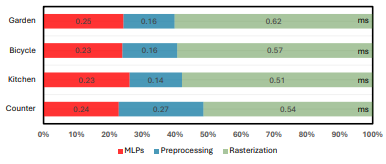
그림 6
Mobile-GS 런타임 분석

그림 7
제안한 신경망 기반 시점 의존 향상 전략에 대한 평가.
“w/o” 는 해당 전략을 제거한 경우(without) 를 의미하고, “w/” 는 해당 전략을 포함한 경우(with) 를 의미한다.
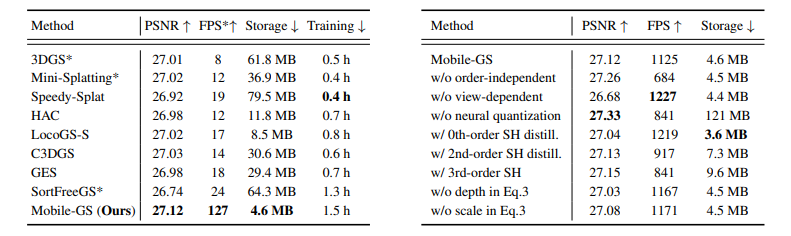
표 1
실제 세계 데이터셋에서의 최신 3D 재구성 방법들에 대한 정량적 비교. 우리는 Mip-NeRF 360 (Barron et al., 2022), Tank&Temples (Knapitsch et al., 2017), 그리고 Deep Blending (Hedman et al., 2018)과 같은 세 가지 널리 사용되는 데이터셋에서 성능을 평가하고 보고한다. 우리는 경량(lightweight) 3DGS 방법들 중 가장 좋은 결과를 강조한다.

< 표 2 : Snapdragon 8 Gen 3 GPU가 탑재된 모바일 기기에서의 평가.
3DGS*, Mini-Splatting*, 그리고 SortFreeGS* 는 허프만 인코딩(Huffman encoding) 을 통한 양자화 버전을 의미한다.
> 표 3 : 제안한 구성 요소들에 대한 ablation study. 우리는 Mip-NeRF 360 데이터셋에서의 결과를 보고한다. 추론 속도 FPS 는 Desktop RTX 3090 GPU 에서 평가된다.

< 표 4 : 프루닝 전략에 대한 ablation study. 우리는 프루닝이 없는 우리의 Mobile-GS를 baseline으로 사용하고, 불투명도만, 스케일만, 그리고 두 속성 모두에 대해서 프루닝을 적용한다.
> 표 5 : 프루닝 임계값에 대한 하이퍼파라미터 분석. 우리는 우리의 기여도 기반 프루닝이 없는 Mobile-GS를 baseline으로 사용하고, 적절한 trade-off를 찾기 위해 프루닝 임계값을 조정한다.

< 표 6 : 제안한 기여도 기반 프루닝의 적응성. 우리가 제안한 기여도 기반 프루닝은 추가적인 가우시안 프루닝을 위해 MaksGaussian (Liu et al., 2025)과 Mini-Splatting에 적용될 수 있다.
> 표 7 : 코드북 크기에 대한 분석. 우리는 더 균형 잡힌 trade-off를 찾기 위해 Mip-NeRF 360 데이터셋에서 서로 다른 코드북 크기를 분석한다. 더 작은 코드북 크기는 더 적은 저장 비용을 의미한다.
