Abstract
저자들은 모듈형 자율주행이 perception-prediction-planning 사이에서 정보 손실과 error accumulation을 만든다고 보고, end-to-end 방식이 더 planning-oriented 하게 최적화될 수 있다고 봄.
하지만 기존 E2E 방법은 dense BEV feature 비용과 prediction/planning 설계의 단순성 때문에 특히 안전성 측면에서 한계가 있다고 지적함.
이를 해결하기 위해 SparseDrive 를 제안하며, 구성은 symmetric sparse perception 과 parallel motion planner, 그리고 collision-aware rescore 가 포함된 hierarchical planning selection 임.
1. Introduction
문제의식은 다음과 같음
-
첫째, motion prediction 과 planning 은 둘 다 미래 trajectory를 다루는 문제인데, 기존 방식은 둘을 순차적으로 처리해서 ego가 주변 agent에 주는 영향을 충분히 반영하지 못함.
-
둘째, prediction과 planning 모두 semantic 정보와 geometric 정보가 필요한데, 기존 방식은 주변 agent에는 이를 잘 쓰지만 ego vehicle 표현은 약하게 초기화하는 경우가 많음.
-
셋째, planning도 본질적으로 multi-modal 인데 기존 방법은 대개 deterministic trajectory 만 예측함. SparseDrive 는 이 세 문제를 겨냥해 sparse-centric 패러다임을 제안함.
2. Related Work
2.1 Multi-view 3D Detection
이 섹션은 LSS/BEV 계열처럼 dense BEV를 쓰는 흐름과, PETR·Sparse4D 처럼 sparse query/anchor 기반 표현으로 가는 흐름을 정리함.
SparseDrive는 후자 쪽 철학을 이어받아 dense BEV 의존도를 낮춘다는 위치를 가짐.
2.2 End-to-End Tracking
tracking-by-detection은 후처리에 크게 의존하므로 end-to-end 성이 약하다고 보고, query 기반 tracking이 더 적합하다고 설명함.
특히 Sparse4Dv3처럼 temporal propagation 자체가 identity consistency 를 어느 정도 보장한다는 점을 가져와, SparseDrive는 복잡한 tracking loss 없이도 tracking을 단순하게 설계함.
2.3 Online Mapping
online mapping은 HD map 비용 문제를 줄이기 위한 방향으로 소개됨.
HDMapNet, VectorMapNet, MapTR 등의 흐름을 정리하면서, SparseDrive는 map element도 object처럼 sparse instance 로 표현해 perception 안에 같이 넣음.
2.4 End-to-End Motion Prediction
기존 motion prediction 연구들은 tracking 정보나 vectorized map을 활용해 미래 trajectory를 예측해왔고, 이 논문은 그 연장선에서 motion prediction과 planning의 구조적 유사성을 더 강하게 밀어붙임.
2.5 End-to-End Planning
초기 end-to-end driving 은 perception/prediction intermediate task를 생략해 해석성과 최적화가 약했고, 이후 UniAD/VAD/GraphAD 등이 explicit scene learning을 강화했지만 여전히 prediction과 planning의 유사성을 충분히 설계에 반영하지 못함
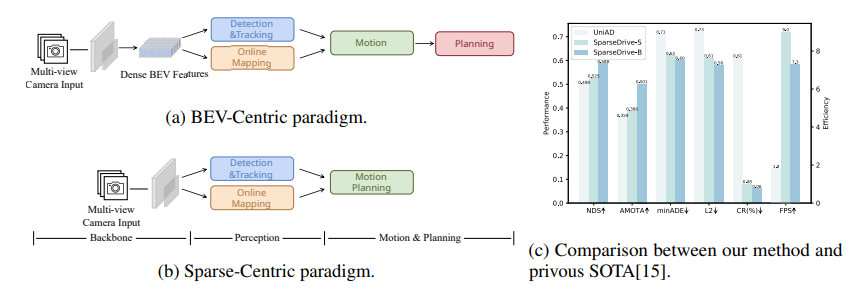
Figure 1
다양한 end-to-end 패러다임의 비교.
(a). BEV 중심 패러다임(BEV-Centric paradigm)
(b). 제안하는 Sparse 중심 패러다임(Sparse-Centric paradigm)
(c). (a)와 (b) 사이의 성능 및 효율성 비교
3. Method
3.1 Overview
전체 구조는 image encoder → symmetric sparse perception → parallel motion planner 순서임.
이미지 인코더가 multi-view, multi-scale feature map을 만들고, sparse perception이 여기서 agent instance 와 map instance 를 추출함.
그다음 planner가 ego instance와 이 sparse scene representation을 함께 사용해 motion prediction 과 planning 을 동시에 수행함.
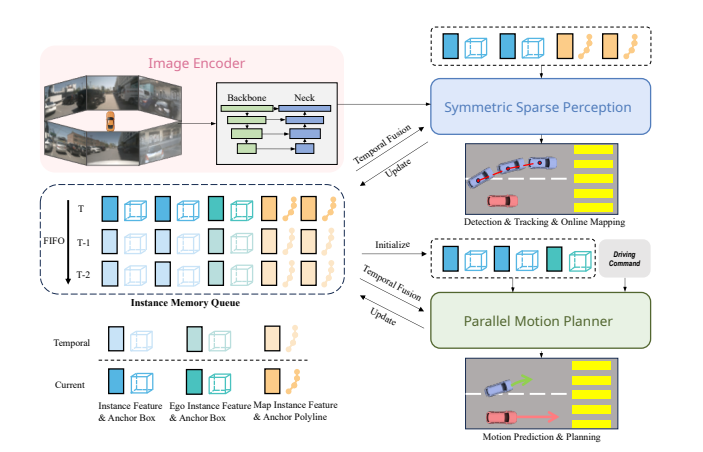
Figure 2
SparseDrive의 전체 구조 개요임.
SparseDrive는 먼저 다중 시점 이미지(multi-view images)를 feature map 으로 인코딩한 뒤, symmetric sparse perception 을 통해 sparse scene representation 을 학습함.
이후 motion prediction 과 planning 을 병렬 방식(parallel manner) 으로 수행함. 또한 시간적 정보를 반영하기 위해 instance memory queue 를 설계하여 사용함.
3.2 Symmetric Sparse Perception
이 파트의 핵심은 detection, tracking, online mapping을 거의 대칭적인 구조로 묶었다는 점임.
- Detection : 주변 agent를 instance feature와 3D anchor box로 표현함.
- Online Mapping : static map element를 instance feature와 polyline anchor로 표현함.
- Tracking : detection confidence가 threshold를 넘으면 ID를 부여하고 temporal propagation 동안 유지하는 단순한 방식임.
즉, scene을 dense BEV grid 대신 “instance feature + geometric anchor” 집합으로 표현하는 것이 핵심임.
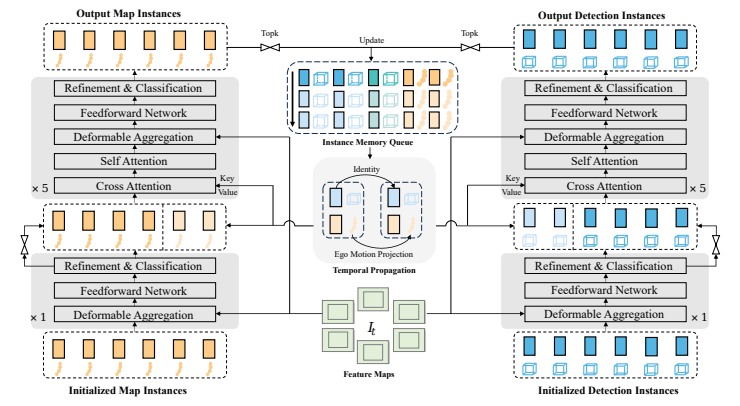
Figure 3
detection, tracking, online mapping을 대칭적인 구조 안에서 통합한 symmetric sparse perception의 모델 아키텍처
3.3 Parallel Motion Planner
planner 는 세 부분으로 나뉨.
(1) Ego instance initialization
저자들은 ego도 주변 agent처럼 semantic + geometric 정보를 가져야 한다고 보고, random init 대신 front camera의 가장 작은 feature map을 average pooling 해서 ego feature를 초기화함.
또 ego velocity는 GT를 바로 쓰면 leakage가 생길 수 있어서, 이전 프레임 예측 ego status 를 이용해 초기화함.
(2) Spatial-temporal interactions
ego와 주변 agent를 합쳐 agent-level instance 를 만들고, memory queue를 둔 뒤
- agent-temporal cross-attention
- agent-agent self-attention
- agent-map cross-attention
을 수행함.
즉, ego-others, agents among themselves, agents-map 상호작용을 모두 반영하려는 구조임. 또 motion prediction과 planning trajectory를 동시에 multi-modal로 예측함.
(3) Hierarchical Planning Selection
planning output은 바로 하나를 내는 게 아니라, 먼저 driving command 에 맞는 trajectory subset을 고르고, 그다음 collision-aware rescore 로 충돌 위험이 큰 planning mode의 점수를 낮춘 뒤 최종 trajectory를 선택함. 실질적으로는 “모드 생성 → command-conditioned filtering → 안전성 재채점 → 최종 선택” 구조임.
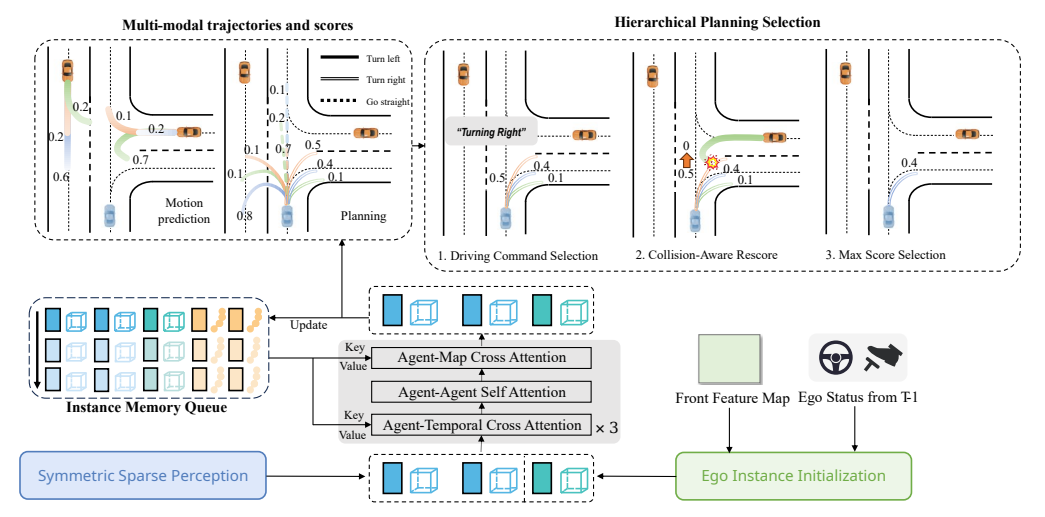
Figure 4
motion prediction과 planning을 동시에 수행하고, 안전한 planning trajectory를 출력하는 parallel motion planner의 모델 구조
3.4 End-to-End Learning
학습은 2단계임.
1단계에서는 symmetric sparse perception만 먼저 학습해 sparse representation을 안정화하고, 2단계에서는 perception과 planner를 함께 end-to-end로 학습함.
loss는 detection, mapping, motion, planning, depth auxiliary loss의 합으로 구성됨.
4. Experiments
4.1 Experiment Setting
실험은 nuScenes 에서 수행됨. 논문은 두 모델을 씀.
- SparseDrive-S : ResNet50, 256×704
- SparseDrive-B : ResNet101, 512×1408
평가는 perception, prediction, planning 전부 포함하며, planning에서는 L2 error와 collision rate를 사용함. 특히 collision metric은 기존 구현의 한계를 지적하며, ego heading 변화와 box overlap 를 고려해 다시 계산했다고 설명함.
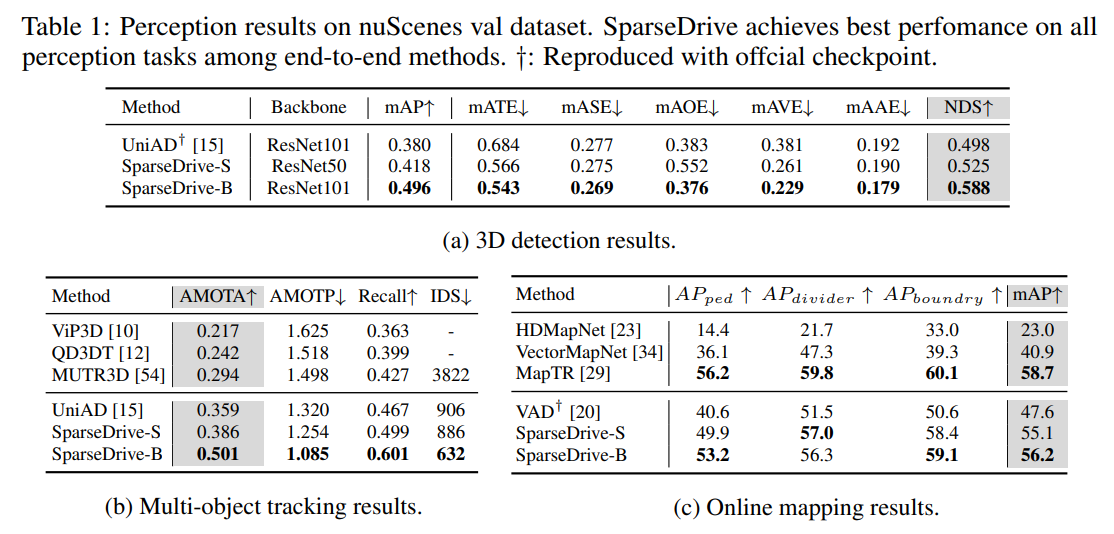
4.2 Main Results
논문 주장 기준으로 SparseDrive-B는
- detection: 49.6 mAP / 58.8 NDS
- tracking: 50.1 AMOTA, IDS 632
- online mapping: 56.2 mAP
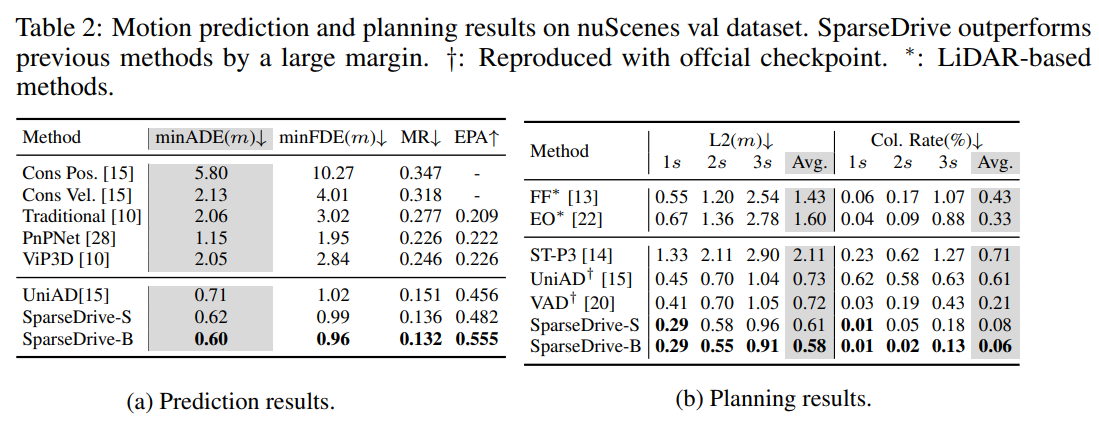
- prediction: 0.60 minADE / 0.96 minFDE / 13.2% MR / 0.555 EPA
- planning: 평균 L2 0.58m / collision rate 0.06%
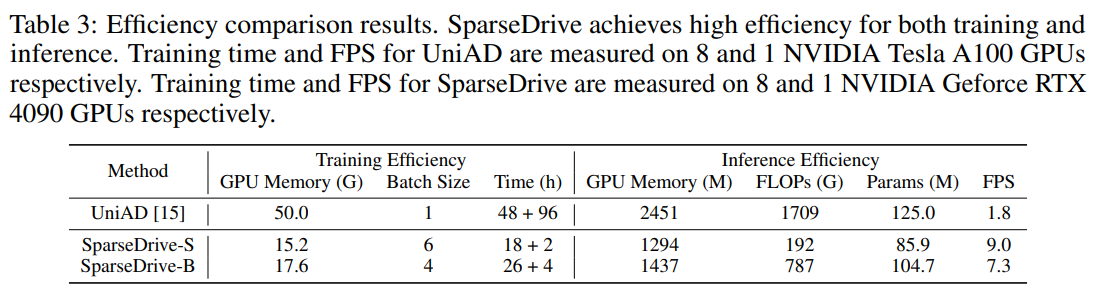
를 기록함. 또한 SparseDrive-S도 기존 E2E SOTA보다 대부분의 항목에서 우수했고, 속도도 크게 개선되었다고 보고함.
planning 쪽이 특히 강조되는데, 저자들은 VAD 대비 평균 L2를 0.72→0.58 로 낮추고, collision rate를 0.21%→0.06% 로 줄였다고 정리함. 효율 면에서도 SparseDrive-S는 training/inference가 각각 7.2배, 5.0배 빠르다고 주장함.
4.3 Ablation Study
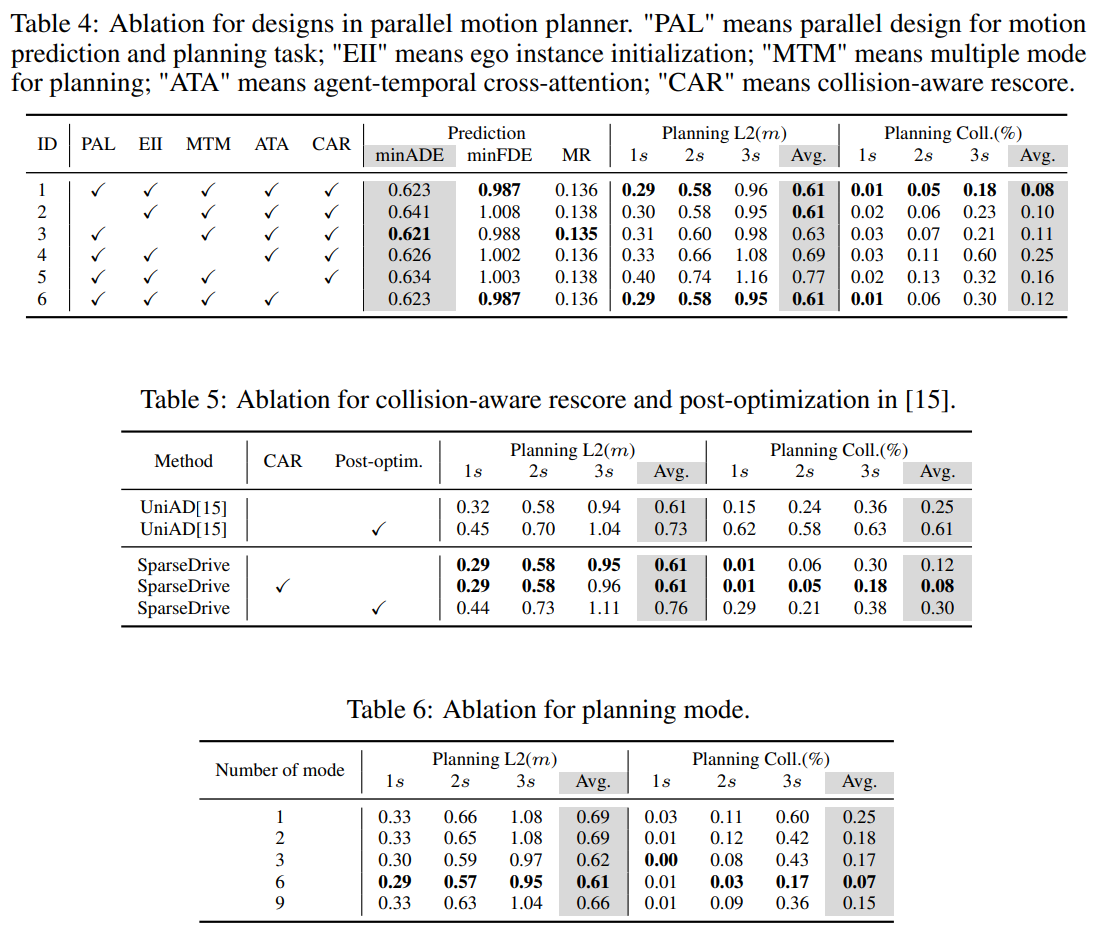
ablation은 논문의 설계 포인트를 꽤 명확히 보여줌.
- parallel design 제거: prediction/planning을 순차화하면 prediction과 collision rate가 악화됨.
- ego instance initialization 제거: semantic/geometric ego 표현을 약하게 만들면 planning이 나빠짐.
- multi-modal planning 제거: deterministic planning은 collision이 크게 증가함.
- agent-temporal cross-attention 제거: planning L2가 크게 악화됨.
- collision-aware rescore: post-optimization보다 planning 품질 저하가 적으면서 collision rate를 더 낮춤.
- planning mode 수 증가: 성능이 계속 좋아지다가 6 mode 근처에서 포화됨.
5. Conclusion
sparse scene representation 과 prediction-planning 병렬 설계를 통해 정확도와 효율을 동시에 끌어올렸다는 것임. 다만 저자들도 한계를 인정하는데,
1) online mapping 등에서는 여전히 single-task 방법보다 약한 부분이 있고,
2) dataset 규모가 충분하지 않으며,
3) open-loop 평가는 실제 성능을 완전히 대표하지 못한다고 말함.
