Abstract
기존 방법들이 과거 정보를 활용하더라도 motion planning에 충분히 반영하지 못하거나, 각 query가 하나의 trajectory 단위로 구성되어 있어 미래 여러 시점을 세밀하게 다뤄야 하는 planning 특성과 맞지 않음을 지적함.
이를 해결하기 위해 BridgeAD는 motion/planning query를 time step별 query 구조로 재설계하고, 현재 시점에 대응하는 과거 motion 정보는 perception 강화에, 미래 시점에 대응하는 과거 motion/planning 정보는 planning 강화에 활용함.
이를 통해 past와 future를 자연스럽게 연결하는 구조를 형성하며, nuScenes의 open-loop와 closed-loop 실험에서 우수한 성능을 달성함을 보임.
1. Introduction
전통적인 modular pipeline이 perception, prediction, planning을 분리하여 다루기 때문에 정보 전달이 단절되고 오차가 누적될 수 있음을 설명함.
반면 E2E 자율주행은 이를 하나의 통합된 framework 로 묶을 수 있으나, temporal information을 활용하는 방식은 여전히 detection 중심 설계의 한계를 벗어나지 못했다고 봄.
→ 즉, 과거 정보를 perception 보강에만 주로 활용하거나, planning 단계에서는 충분히 반영하지 못하는 문제가 존재함.
저자들은 특히 두 가지 한계를 지적함.
-
첫째, 과거 정보가 perception에만 사용될 경우 planning의 연속성 확보가 어려움.
-
둘째, 과거 motion/planning query를 trajectory 단위로만 다루면, 실제 planning에 필요한 미래 각 시점별 상태 변화를 세밀하게 반영하기 어려움.
따라서 BridgeAD는 미래를 하나의 trajectory 덩어리가 아니라 time step들의 연속 구조로 보고, 과거 prediction/planning 역시 이 step 구조에 맞추어 재사용하도록 설계함.
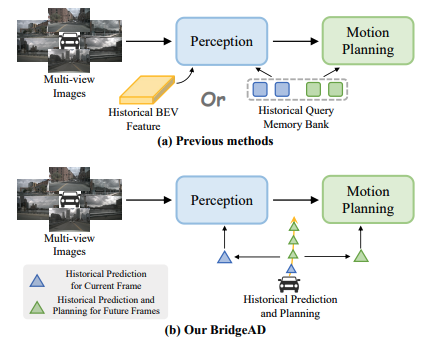
Figure 1
이전 방법들과 우리의 방법의 핵심적인 차이는 과거 정보를 어떻게 집계하느냐에 있다.
(a)에서 보이듯이, 기존 방법들은 과거 정보를 perception 모듈 내부에서 과거 BEV feature와 상호작용시키거나, 혹은 과거 query를 저장한 memory bank를 활용하는 방식을 사용한다.
반면 (b)에서 보이듯이, 우리가 제안한 BridgeAD는 현재 프레임에 대한 과거 prediction 정보를 perception 모듈에 반영하고, 미래 프레임들에 대해서는 과거 prediction 정보와 planning 정보를 motion planning 모듈에 반영함으로써 end-to-end 자율주행 성능을 향상시킨다.
2. Related work
관련 연구는 크게 Perception / Motion Prediction / Planning 세 영역으로 정리됨.
-
Perception 분야에서는 BEV 기반 3D detection, tracking, online mapping 계열을 다루고,
-
motion prediction 분야에서는 query 기반 trajectory forecasting 및 history-aware prediction 계열을 다룸.
-
Planning 분야에서는 ST-P3, UniAD, VAD, GenAD, SparseDrive 등의 E2E 자율주행 방법을 정리함.
저자들은 기존 방법들이 perception, prediction, planning을 통합하는 데는 성공했지만, historical information을 planning의 정확도와 연속성 향상에 충분히 활용하지 못했다는 점을 한계로 제시함.
BridgeAD의 차별점은 과거 정보를 perception 보강에 그치지 않고, prediction과 planning 전반에 걸쳐 일관되게 연결하는 데 있음.
3. Methodology
3.1 Overview
BridgeAD는 크게 image encoder, history-enhanced perception, history-enhanced motion planning 으로 구성됨.
먼저 multi-view 이미지로부터 feature를 추출하고, perception 단계에서는 detection/tracking/mapping을 수행하면서 과거 motion query를 활용함.
이후 motion prediction과 planning 단계에서는 과거 motion 및 planning query를 이용하여 미래 trajectory와 ego planning을 개선함.
또한 별도의 memory queue를 두어 past frame의 motion/planning query를 저장하고, 현재 프레임에서 필요한 시점의 history를 선택적으로 참조하도록 설계함.
이를 통해 과거 프레임의 정보가 단순히 누적되는 것이 아니라, 현재 perception과 미래 planning에 목적에 맞게 사용되도록 함.
3.2 Multi-step motion and planning query caching
이 논문의 핵심 설계 중 하나는 motion query와 planning query를 multi-step 구조로 재정의한 것임.
기존 방법은 보통 motion query를 trajectory 하나를 대표하는 query로 다루지만, BridgeAD는 이를 에이전트 × 모드 × 미래 time step × 채널 구조로 분해함.
Planning query 역시 planning mode × 미래 time step × 채널 구조로 표현함.
즉, 미래 trajectory 전체를 하나의 query로 다루는 것이 아니라, 미래 각 시점을 query 내부 차원으로 분리하여 명시적으로 표현하는 방식임.
이렇게 해야 과거 정보도 현재용 정보와 미래 각 step용 정보를 구분하여 정확히 결합할 수 있음.
과거 프레임에서 생성된 query들은 FIFO 방식의 memory queue에 저장되며, 새 프레임이 들어올 때 오래된 정보는 제거됨.
정리하면 다음과 같음.
-
motion query: [agent, mode, future step, channel]
-
planning query: [planning mode, future step, channel]
즉, 이 논문의 핵심은 trajectory 중심 표현을 time-step 중심 표현으로 바꾼 것에 있음.
3.3 History-enhanced perception
Perception은 sparse paradigm을 따르며, detection에서는 object query와 anchor box를 사용하고, tracking은 ID assignment를 통해 객체를 연결하며, mapping은 vectorized map query로 수행됨.
여기에 BridgeAD는 Historical Mot2Det Fusion 을 추가함.
구체적으로는 과거 프레임의 motion query 중에서 현재 프레임에 해당하는 step의 query를 선택하여 object query와 attention 방식으로 결합함.
이는 과거 prediction이 제공하는 현재 상태의 연속성을 활용하여, 현재 detection과 tracking의 안정성을 높이기 위한 목적임.
다시 말해 perception을 단순히 현재 이미지 기반 문제로 보지 않고, 과거의 motion prediction 정보를 함께 활용하여 현재 객체 상태를 더 정확히 파악하도록 한 것임.
3.4 History-enhanced motion planning
Motion prediction과 planning 단계에서는 perception에서 얻은 object/map query와 ego query를 바탕으로 미래 trajectory를 예측하고 ego planning을 수행함.
이때 BridgeAD는 과거 frame에서 저장된 motion query와 planning query를 불러와, 현재의 미래 step query와 대응시켜 결합함.
Motion prediction에서는 과거 motion query 중 미래 step들에 대응하는 부분을 선택하여 cross-attention을 수행하고, 이후 step-level self-attention과 mode-level self-attention을 적용함.
Planning 역시 유사한 구조를 가지며, 과거 planning query를 현재 planning query에 결합하여 미래 ego trajectory를 더 안정적으로 생성함.
핵심은 attention이 임의로 수행되는 것이 아니라, 동일하거나 대응되는 미래 step들끼리 정렬되어 상호작용한다는 점임.
예를 들어 과거 프레임이 예측한 “1초 후 상태” 정보는 현재 프레임의 “1초 후 planning/prediction”을 강화하는 데 사용됨.
→ 이처럼 step alignment를 기반으로 past와 future를 연결하는 것이 BridgeAD의 핵심 구조임.
Step-level Mot2Plan interaction
Prediction과 planning 사이의 일관성을 강화하기 위해, 논문은 motion query와 planning query를 step 단위로 직접 상호작용시키는 Mot2Plan 모듈도 제안함.
여기서는 주변 agent motion 중 확률이 높은 query를 선택한 뒤, planning horizon 내 각 future step에서 ego planning query와 대응시켜 interaction을 수행함.
즉, 주변 차량이 각 시점에 어떻게 움직일 것인지와 ego 차량이 그 시점에 어떻게 움직일 것인지를 동일한 시간축 위에서 함께 고려하도록 만든 구조임.
이를 통해 ego planning이 주변 객체의 미래 motion과 더 정합적으로 연결되도록 함.
3.5 End-to-end learning
학습은 detection, online mapping, motion prediction, planning의 네 가지 task loss 로 구성됨.
각 task는 regression과 classification loss로 구성되며, regression에는 L1 loss, classification에는 Focal loss를 사용함.
Multi-modal motion prediction과 planning에는 winner-takes-all 전략을 적용함.
전체 학습 objective는 이 네 task loss를 합한 end-to-end loss이며, perception, prediction, planning이 하나의 통합된 목적 아래 함께 최적화되도록 설계됨.
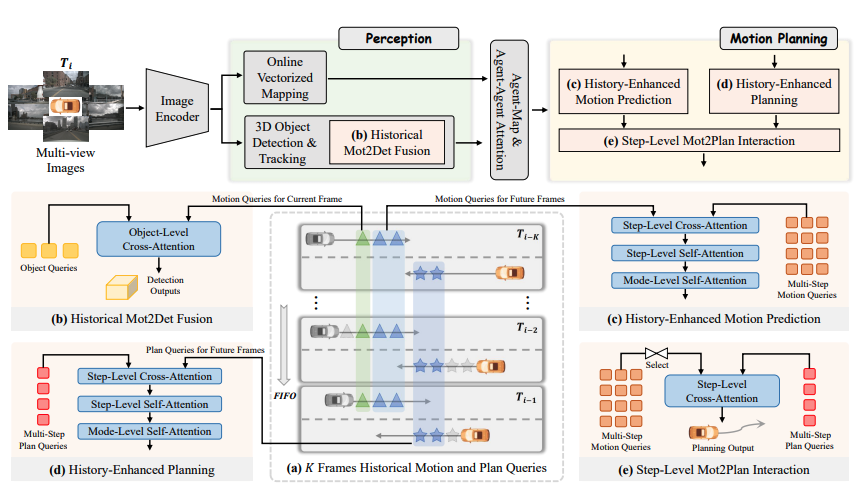
Figure 2
BridgeAD 프레임워크의 전체 개요는 다음과 같다. 먼저, 멀티뷰 이미지는 Image Encoder를 통해 처리되며, 그 이후 3D 객체와 벡터화된 맵(vectorized map) 이 인지된다.
(a) 메모리 큐(memory queue) 는 과거 K개 프레임의 motion query와 planning query를 저장한다.
(b) Historical Mot2Det Fusion Module은 현재 프레임의 탐지와 추적 성능을 향상시키기 위해, 과거의 motion query를 활용하도록 제안된 모듈이다.
모션 플래닝 구성 요소에서는,
(c) History-Enhanced Motion Prediction Module과
(d) History-Enhanced Planning Module이
여러 시간 단계에 걸친 과거의 motion query와 planning query를 모아, 미래 프레임을 위한 query로 통합한다.
마지막으로, (e) Step-Level Mot2Plan Interaction Module은 여러 미래 시점에 해당하는 motion query와 planning query 사이의 상호작용이 이루어지도록 한다.
4. Experiments
4.1 Experimental settings
실험은 nuScenes 데이터셋에서 수행됨.
Open-loop 평가는 nuScenes validation set 기준으로 진행하고, closed-loop 평가는 NeuroNCAP simulator 에서 수행함.
Ego vehicle은 3초 미래 trajectory를 planning하고, 주변 agent는 6초 미래 trajectory를 prediction함.
이에 따라 motion prediction time step은 12, planning time step은 6으로 설정되며, history aggregation에는 motion 6 step, planning 3 step을 사용함.
모델은 BridgeAD-S와 BridgeAD-B 두 가지 variant로 구성되며, 학습은 perception stage와 E2E stage로 나누어진 2-stage training 방식으로 수행됨.
4.2 Comparison with state of the art
Open-loop planning 성능에서 BridgeAD-B는 평균 L2 error 0.58, 평균 collision rate 0.08% 를 기록하여 비교 대상 중 가장 좋은 성능을 보임.
BridgeAD-S 역시 0.59 / 0.09%로 매우 우수한 성능을 보임.
이는 SparseDrive, VAD, UniAD 대비 개선된 결과이며, 저자들은 특히 ego status leakage 없이도 높은 planning 성능을 달성했다는 점을 강조함.
Closed-loop에서는 성능 차이가 더 크게 나타남. NeuroNCAP benchmark에서 post-processing 없이 BridgeAD-B는 score 1.60, collision rate 72.6%, BridgeAD-S는 1.52, 76.2% 를 기록함.
비교 모델인 SparseDrive, UniAD, VAD보다 더 높은 score와 더 낮은 collision rate를 보이며, 이는 BridgeAD가 연속 주행 상황에서 더 안정적이고 일관된 planning을 수행함을 의미함.
Perception과 motion prediction 결과도 우수함. Motion prediction에서는 ADE, FDE, EPA 지표 전반에서 좋은 성능을 보였고, Detection에서는 mAP와 NDS, Tracking에서는 AMOTA와 IDS 측면에서도 경쟁 방법보다 우수한 결과를 달성함. 즉, 이 모델은 planning뿐 아니라 perception-prediction-planning 전반의 성능 향상을 보여줌.
4.3 Ablation Study
Ablation study는 제안한 구성 요소들의 효과를 뚜렷하게 보여줌. Planning 쪽에서 History-Enhanced Planning 을 제거하면 평균 L2가 나빠지고 collision rate도 증가함. 또한 Mot2Plan interaction 을 제거해도 성능이 저하됨. 최종 모델이 가장 좋은 planning 성능과 가장 낮은 collision rate를 기록함.
Perception/prediction 쪽에서도 마찬가지로, HisMot 없이 prediction 성능이 저하되면 detection/tracking 성능도 함께 저하되고, Mot2Det 없이 perception 성능이 약화되면 전체 시스템 성능이 떨어짐.
또한 step-level self-attention 이나 mode-level self-attention 을 제거했을 때 planning 성능이 감소함. 이를 통해 저자들은 history aggregation, step-level interaction, self-attention 구조가 모두 유효함을 보임.
History 길이에 대한 실험에서는 motion 6 step, planning 3 step 구성이 가장 좋은 결과를 보였다고 보고함.
4.4 Efficiency analysis
효율성 측면에서 BridgeAD는 높은 성능 대비 비교적 합리적인 추론 속도를 보임. BridgeAD-S는 5.0 FPS, BridgeAD-B는 3.9 FPS, 추론 latency는 157.2 ms로 보고됨. 이는 VAD나 UniAD보다 빠른 수준이며, BridgeAD가 단순히 성능만 높은 무거운 모델이 아니라 어느 정도 실용성을 갖춘 구조임을 시사함.
4.5 Qualitative analysis
정성적 결과에서는 open-loop 환경에서 perception, prediction, planning 결과를 함께 시각화하고, closed-loop 환경에서는 반대 차선에서 잘못 진입하는 차량을 회피하는 안전-critical 시나리오를 제시함.
이 사례에서 BridgeAD는 적절한 steering을 통해 충돌을 피하지만, UniAD와 SparseDrive는 steering이 없거나 충분하지 않아 충돌하는 모습을 보임.
이를 통해 저자들은 history를 step-aligned하게 활용하면 주변 차량 motion에 대한 연속적인 이해가 가능해지고, 그 결과 ego vehicle이 보다 일관되고 안전한 driving action을 수행할 수 있다고 주장함.
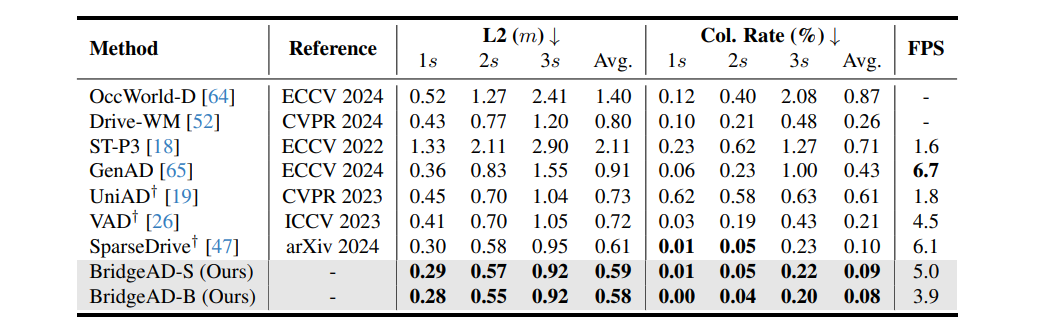
Table 1
nuScenes [2] 검증 데이터셋에서의 오픈루프 planning 성능 결과를 보여준다. †는 공식 체크포인트를 사용해 평가했음을 의미한다.
FPS는 배치 크기 1 기준으로 NVIDIA RTX 3090 GPU 1장에서 측정했으며, UniAD의 경우에는 NVIDIA Tesla A100 1장에서 측정했다.
또한 Li et al. [29]가 제안한 ego-status leakage 문제를 피하기 위해, 본 방법에서는 ego status를 입력으로 사용하지 않았다.
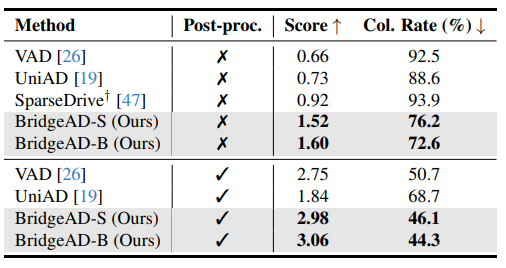
Table 2
nuScenes 데이터셋에서 NeuroNCAP [38] 벤치마크를 사용해 수행한 폐루프(closed-loop) 시뮬레이션 결과를 보여준다. †는 공식 체크포인트로 평가했음을 의미한다. 또한 “Post-proc.” 는 UniAD에서 제안한 trajectory 후처리 과정을 뜻한다.
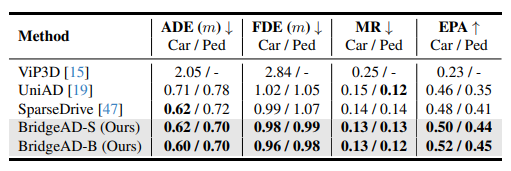
Table 3
최신(state-of-the-art) 방법들의 motion prediction 성능 결과를 비교한다.
평가는 자동차(cars) 와 보행자(pedestrians) 의 두 가지 주요 범주에 대해 수행한다.
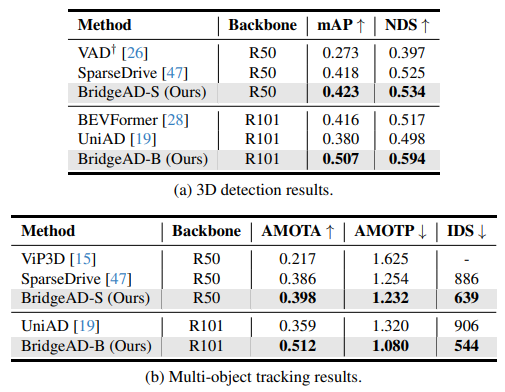
Table 4
최신(state-of-the-art) 인지(perception) 방법 또는 엔드투엔드(end-to-end) 방법들의 인지 성능 결과를 비교한 것이다.
†는 공식 체크포인트로 평가했음을 의미한다.

Table 5
History-Enhanced Planning 모듈과 Step-Level Mot2Plan Interaction 모듈에 대한 ablation study(구성요소 제거 실험) 결과이다.

Table 6
Historical Mot2Det Fusion 모듈과 History-Enhanced Motion Prediction 모듈에 대한 ablation study(구성요소 제거 실험) 결과이다.
평가는 자동차(cars) 와 보행자(pedestrians) 의 motion prediction 성능에 대해 수행한다.
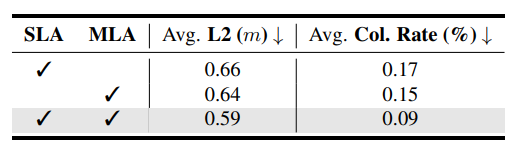
Table 7
step-level self-attention (SLA) 과 mode-level self-attention (MLA) 에 대한 ablation study(구성요소 제거 실험) 결과이다.
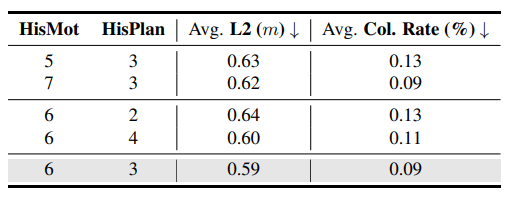
Table 8
과거 정보를 집계할 때 사용하는 time step 수에 대한 ablation study(구성요소 변화 실험) 결과이다.
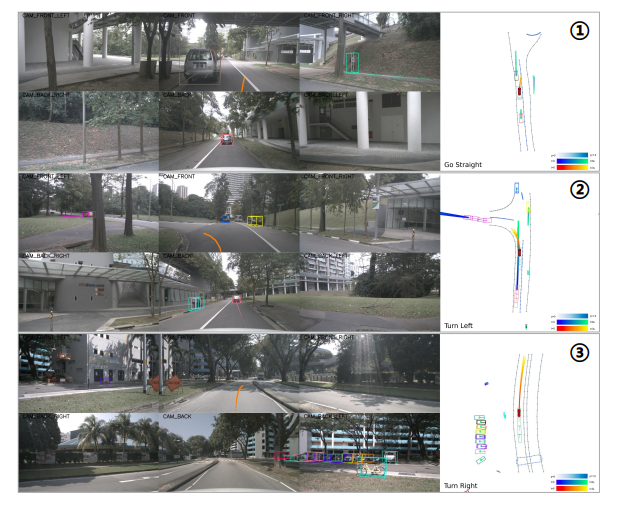
Figure 3
오픈루프 평가의 정성적 결과는, 우리 BridgeAD가 planning 출력 결과를 정확하게 생성함을 보여준다.

Figure 4
폐루프 평가의 정성적 결과는, 우리 BridgeAD가 안전이 중요한 시나리오에서 충돌을 효과적으로 회피함을 보여준다.
5. Conclusion
결론에서는 BridgeAD가 historical prediction과 planning 정보를 perception, prediction, planning 전반에 통합한 E2E 자율주행 프레임워크 임을 다시 강조함.
특히 motion/planning query를 multi-step query 구조로 표현함으로써, 과거 정보와 미래 step 간의 정렬된 interaction이 가능해졌음을 핵심 기여로 제시함.
결과적으로 BridgeAD는 future time steps 간 coherence를 높이고, nuScenes의 open-loop 및 closed-loop 평가 모두에서 우수한 성능을 달성함.
