교착 상태 탐지
교착 상태 예방이나 회피 알고리즘을 사용하지 않는 시스템, 교착 상태가 발생할 수 있는 환경이라면 아래 두 알고리즘을 지원해야한다.
- 교착 상태가 발생했는지 결정하기 위해 시스템의 상태를 검사하는 알고리즘.
- 교착 상태로부터 회복하는 알고리즘.
탐지와 회복 알고리즘 방법은 필요한 정보를 유지하고 탐지 알고리즘을 실행시키기 위한 실행 시간, 비용, 교착 상태로 부터 회복할 때 내재하는 가능한 손실을 포함하는 오버헤드가 필요하다.
각 자원 유형이 한 개씩 있는 경우
대기 그래프
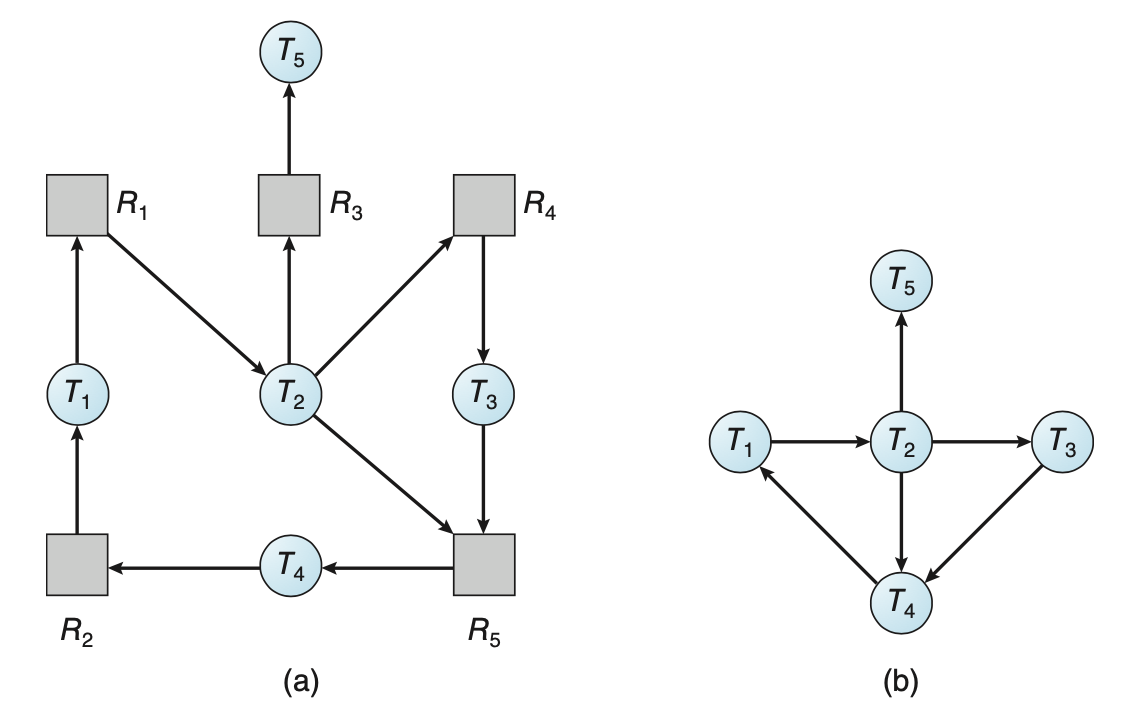
자원 할당 그래프를 변형 하여 교착 상태 탐지 알고리즘을 정의할 수 있다. 자원 할당 그래프로부터 자원 노드를 제거하고 적절하게 간선을 결합한 그래프이다.
Ti -> Tj의 의미는 Ti는 Tj가 가지고 있는 자원들 중 Ti가 필요한 자원이 반납 되기까지 대기중이라는 의미이다. Ti -> Tj는 Ti->R와 R->Tj를 포함하는 경우만 대기 그래프가 존재한다.
대기 그래프에서 사이클이 포함되는 경우만 교착 상태가 존재한다. 교착 상태 탐지를 위해 시스템은 대기 그래프를 유지하여야 하며, 주기적으로 사이클을 탐지하는 알고리즘을 호출한다.
아래의 (a)는 자원할당 그래프이며 (b)는 (a)를 대기 그래프로 만든것이다.
각 유형의 자원을 여러 개 가진 경우
이 경우 대기 그래프는 사용할 수 없으며 은행원 알고리즘처럼 상태 정보를 가지는 자료 구조를 사용해야한다.
자료구조
-
Available : 종류별로 가용한 자원의 개수를 나타내는 벡터, 크기는 m.
Available[j] = k라면 현재 Rj를 k개 사용할 수 있다는 뜻. -
Allocation : 각 스레드에 현재 할당된 자원의 개수. 크기는 n*m.
Allocation[i][j]=k라면 스레드 Ti가 Rj를 현재 k개 사용중이다는 뜻. -
Request : 각 스레드가 현재 요청 중인 자원의 개수. 크기는 n*m.
Reqeust[i][j]==k라면 현재 Ti가 Rj를 k개 요청 중이라는 뜻.
<= 연산은 해당 원소가 모두 작거나 같고, 두 집합이 같지 않아야 한다. (원소가 같은 것이 아닌 요청하는 두 집합이 같지 않아야함)
알고리즘
가능한 모든 할당 순서를 조사해보는 방식.
-
Work와 Finish는 크기가 m과 n인 벡터.
Work = Available로 초기화, i = 0,1,...,n-1에 대해서 Allocation != 0이면 Finish[i] = false, 아니면 finish[i] = true 초기화. -
아래 두 조건을 만족시키는 i값을 찾는다.
a. Finish[i] == false
b. Request[i] <= Work
c. 두 조건을 만족하는 i값을 찾지 못하면 4번으로 이동 -
Work = Work + Allocation[i]
Finish[i] = true
2번으로 간다. -
어떠한 i 값에 대해 (0<=i<n) Finish[i] == false이면 이 시스템은 교착 상태에 빠져 있으며 Ti가 교착상태에 빠져있다.
3번 과정에서 스레드 Ti의 자원을 회수하는 이유는 이 프로세스가 작업을 마치기 까지 더 이상 추가적인 자원을 필요하지 않다고 생각할 수 있다. 그러면 Ti는 현재까지 사용한 자원을 반환하며 시스템을 떠난다고 가정한다. 만약 이 가정이 틀리게 되면 다음 탐지 알고리즘이 동작할때 교착상태가 탐지될 것이다.
예시
아래와 같은 상태가 있다고 가정하자.
| Allocation | Request | Available | |
|---|---|---|---|
| A B C | A B C | A B C | |
| T0 | 0 1 0 | 0 0 0 | 0 0 0 |
| T1 | 2 0 0 | 2 0 2 | |
| T2 | 3 0 3 | 0 0 0 | |
| T3 | 2 1 1 | 1 0 0 | |
| T4 | 0 0 2 | 0 0 2 |
이 시스템은 위 상태에서 교착 상태가 발생되지 않는다. 알고리즘을 돌려보면 <T0,T2,T3,T1,T4> 순서와 같이 작업을 다 끝낼 수 있다. 이때 모든 finish[i]는 true가 된다.
| Request | |
|---|---|
| A B C | |
| T2 | 0 0 1 |
만약 T2가 C를 하나더 요청하도록 변경한다면 이제 시스템은 교착 상태에 빠지게 된다. T0의 자원을 회수한다고 하더라고 다른 프로세스들이 요구하는 자원을 충족시켜줄 수 없다. T1,T2,T3,T4가 교착 상태에 빠지게 된다.
코드
public class DeadLocksDetectionAlgorithm {
public int numOfThreads = 5;
public int numOfResources = 3;
public int[] Available = {0, 0, 0};
public int[][] Allocation = {{0, 1, 0}, {2, 0, 0}, {3, 0, 3}, {2, 1, 1}, {0, 0, 2}};
public int[][] Request = {{0, 0, 0}, {2, 0, 2}, {0, 0, 0}, {1, 0, 0}, {0, 0, 2}};
public boolean lessThan(int[] lhs, int[] rhs) {
for (int i = 0; i < lhs.length; ++i) {
if (lhs[i] > rhs[i])
return false;
}
return true;
}
public void sum(int[] lhs, int[] rhs) {
for (int i = 0; i < lhs.length; ++i) {
lhs[i] += rhs[i];
}
}
public List<Integer> detect() {
// 현재 가용한 자원의 개수로 초기화
int[] work = new int[numOfResources];
System.arraycopy(Available, 0, work, 0, work.length);
boolean[] finish = new boolean[numOfThreads];
for (int i = 0; i < finish.length; i++) {
boolean isZero = true;
for (int j = 0; j < Allocation[i].length; ++j) {
if (Allocation[i][j] != 0) {
finish[i] = false;
isZero = false;
break;
}
}
if (isZero) {
finish[i] = true;
}
}
for (int i = 0; i < numOfThreads; ++i) {
for (int j = 0; j < numOfThreads; ++j) {
if (!finish[j] && lessThan(Request[j], work)) {
sum(work, Allocation[j]);
finish[j] = true;
}
}
}
List<Integer> ret = new ArrayList<>();
for (int i = 0; i < finish.length; i++) {
boolean b = finish[i];
if (!b) ret.add(i);
}
return ret;
}
}
class DeadLocksDetectionAlgorithmTest {
@Test
@DisplayName("교착 상태가 아닌 상태 테스트")
public void test() {
DeadLocksDetectionAlgorithm deadLocksDetectionAlgorithm = new DeadLocksDetectionAlgorithm();
run(deadLocksDetectionAlgorithm);
}
@Test
@DisplayName("교착 상태가 발생하는 상태 테스트")
public void test2() {
DeadLocksDetectionAlgorithm deadLocksDetectionAlgorithm = new DeadLocksDetectionAlgorithm();
deadLocksDetectionAlgorithm.Request[2][2] += 1;
run(deadLocksDetectionAlgorithm);
}
private void run(DeadLocksDetectionAlgorithm deadLocksDetectionAlgorithm) {
List<Integer> threadIdsOfDetectedDeadLocks = deadLocksDetectionAlgorithm.detect();
if (threadIdsOfDetectedDeadLocks.isEmpty()) {
System.out.println("데드락 없어~");
} else {
for (int threadId : threadIdsOfDetectedDeadLocks) {
System.out.print(threadId + "번 ");
}
System.out.println("스레드가 데드락 상태야~");
}
}
}
탐지 알고리즘 사용
- 교착 상태가 얼마나 자주 일어나는가?
- 교착 상태가 일어나면 대략 몇개의 스레드가 포함되는가?
위 두가지 관점을 통해 우리는 탐지 알고리즘을 언제 돌리지 정해야한다. 간단하게 교착 상태가 자주 발생하면 자주 탐지하여야한다. 교착 상태 동안은 자원이 묶이며 시간이 지날수록 교착 상태에 포함되는 스레드가 많아지기 때문이다.
교착 상태가 일어나는 시점은 스레드가 자원을 요청하고 점유를 하지 못할 때이다. 그렇기에 자원 요청에 대해 대기를 해야할때 탐지 알고리즘을 돌리는 방법도 있다. 매 요청마다 탐지 알고리즘을 실행하는 경우에서, 교착 상태가 발생되면 현재 요청한 스레드가 교착 상태를 야기했다는것을 알 수 있다.
자원을 요청할 때 마다 탐지 알고리즘을 호출하면 많은 오버헤드가 발생하게 된다. 이 문제를 해결하는 방법은 지정된 시간 간격으로 돌리거나 CPU 이용률을 기준으로 돌리는 것이다. 일정 시간 및 규칙에 따라 탐지 알고리즘을 호출하면 교착 상태를 야기한 스레드는 알 수 없다.