OS
1.스레드
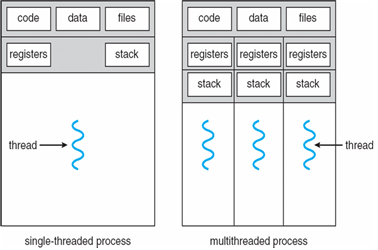
프로세스보다 더 작은 작업 단위(CPU에 할당 되는 단위). 프로세스 내 스레드가 작업 단위가 된다.스레드는 프로세스의 메모리 구조를 가진다. text, data영역, 열린 file이나 신호와 같은 운영체제 자원은 다른 스레드들과 공유를 하고 나머지 레지스터, 스택,
2.멀티 스레드 장점

각 장점이 뭔지 외우는것이 아니라 멀티 스레드를 사용했을때 어떤 이점을 얻을 수 있는 지, 어떤식으로 구현할 수 있는지를 생각해보자.예를 들어 단일 스레드 환경에서 요청을 하게 되면 해당 요청이 끝날때까지 나는 다른 요청을 할 수 없다.멀티 스레드 환경에서 요청을 하
3.병렬 프로그래밍시 생각할 점
프로그램을 분석하여 독립된 태스크로 나눌 수 있는 영역을 찾아야 한다. 각 태스크는 각자 다른 코어에서 병렬적으로 실행 가능하여야 한다.병렬로 실행될 수 있는 태스크를 찾아내는것도 중요하지만 찾아낸 태스크를 균등하게 분배하는것도 중요하다. 하나의 프로세서에 80%의 처
4.병렬 실행 유형
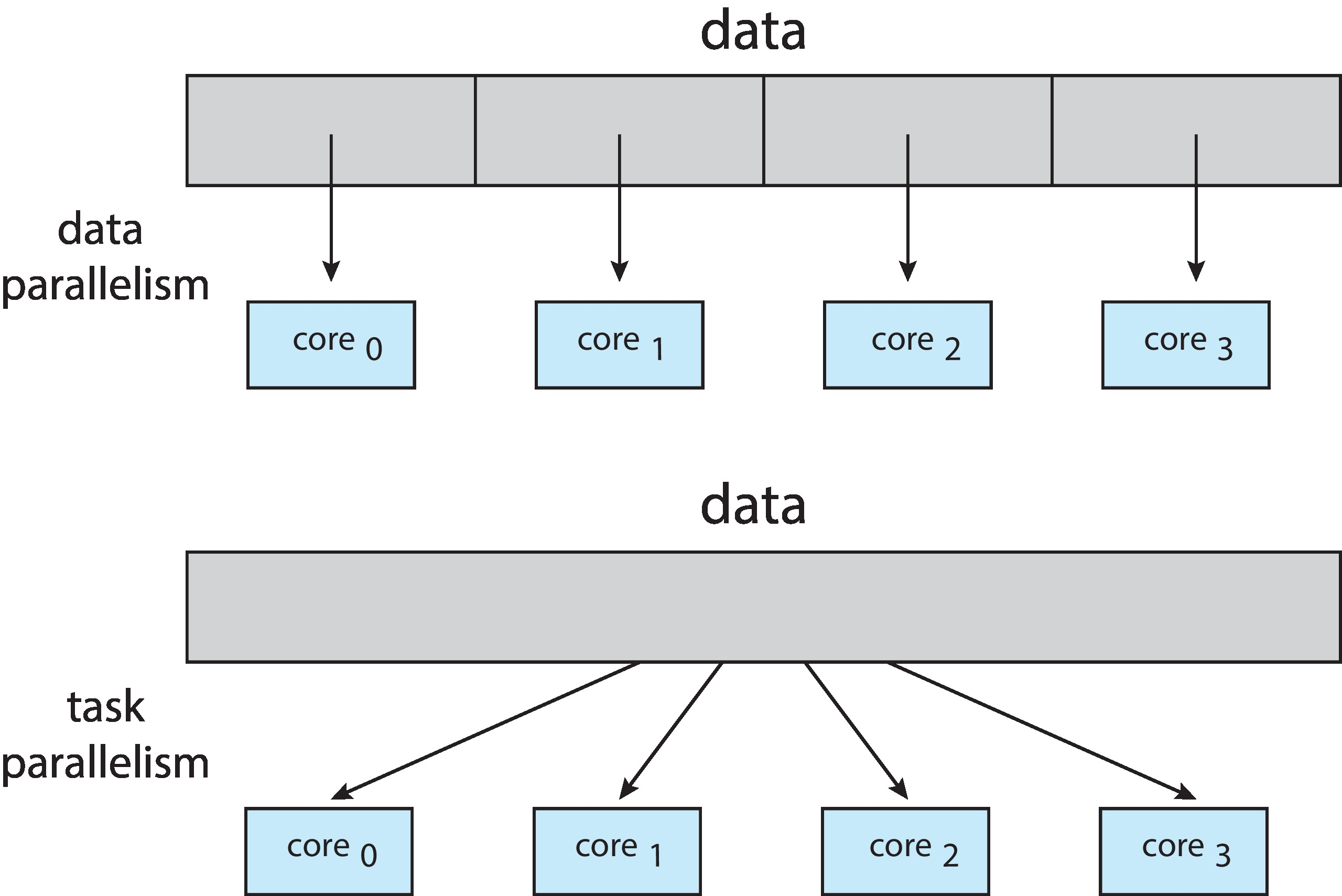
데이터를 부분화 하여 동일한 연산을 수행하는 스레드나 프로세스를 병렬적으로 실행하는 방법각 스레드나 프로세스가 서로 다른 연산을 수행하고 병렬적으로 실행하는 방법데이터는 같을 수도 다를 수도 있다. 예를 들어 하나의 데이터로 여러 통계 데이터를 출력하는 프로그램이라면
5.Multithreading Models (멀티 스레딩 모델)
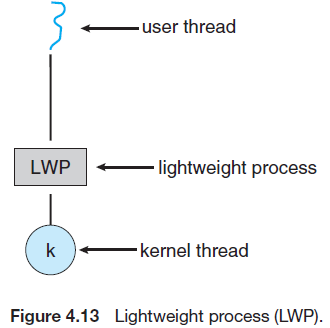
사용자 스레드 (User threads) 사용자 수준에서 사용하며 커널 위에서 동작하며 커널의 지원 없이 관리한다. 커널 스레드 (Kernel threads) 커널 영역에서 동작하며 운영체제에 의해 직접 지원되고 관리 된다. 사용자와 커널 스레드 멀티 스레딩 모델
6.Implicit Threading (암묵적 스레딩)
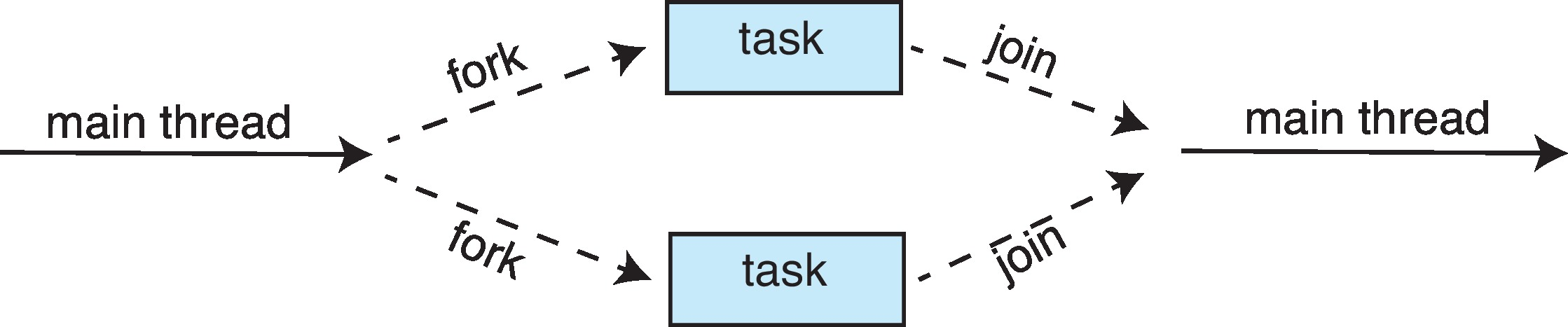
Implicit Threading은 스레딩의 생성과 관리 책임을 개발자가 하는것이 아닌 컴파일러와 런타임 라이브러리에게 넘겨주는것이다. 개발자는 병렬로 실행할 수 있는 작업만 식별하여 작업을 함수로 작성한다. 이후 런타임 라이브러리를 통해 가용한 스레드에 매핑된다.결국
7.Threading Issues (스레드와 관련된 문제)
다중 스레드 프로그램에서는 fork()와 exec()의 의미가 달라질 수 있다.fork 호출시 새로운 프로세스는 모든 스레드를 복제해야하는가? 아니면 한개의 스레드만 복제해야하는가? fork()는 이 두가지 복제방법을 모두 제공한다. exec() 시스템콜을 부르면 ex
8.프로세스 병렬 처리 시 동기화가 필요한 이유
프로세스를 병렬 처리시 스케쥴링을 통하여 프로세스의 일부분만 실행 된 후 다음 프로세스의 일부를 실행하게 된다는것을 알고있다. 여기서 문제점은 한 프로세스에서 자원에 대한 사용이 끝나지 않은 상태에서 스케쥴링이 이루어져고 다른 프로세스가 같은 자원을 사용하게 되면 우리
9.Critical Section 문제
임계영역이란 한 프로세스가 정해진 임계구역에서 수행하는 동안 다른 프로세스는 해당 임계구역이 진입할 수 없더록 만든 코드 영역이다. 임계 영역의 구조는 임계 영역에 진입 요청을하는 entry section(진입 영역)과 임계 영역을 나가는 exit section(퇴출
10.Critical Section의 해결방법 - Peterson 방법
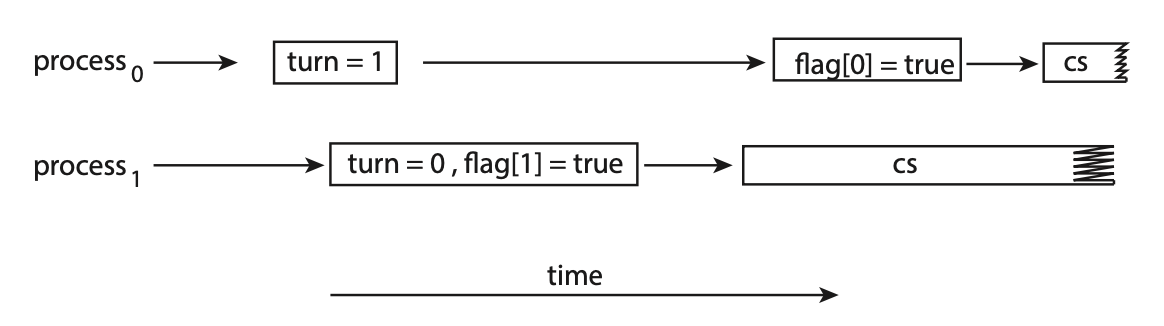
아래는 peterson 해결 방법에서 필요한 자료구조 이다.Pi와 Pj가 존재하며 j는 i를 제외한 프로세스를 뜻한다. 아래는 peterson 해결 방법의 Pi 프로세스 구조 이다.코드 한줄 한줄 정리 해보겠다.flag\[i] = true; 는 현재 내 프로세스가 임계
11.Critical section 문제를 해결하는 하드웨어 지원 (Hardware Support for Synchronization)
하드웨어 기반 해결책 소프트웨어 기반 해결책의 문제점 peterson 해결 방법과 같은 소프트웨어 기반 해결책은 최신 컴퓨터 아키텍처에서 명령어 순서 재정렬로 인한 문제가 발생할 수 있다. 그렇기 때문에 하드웨어는 특수한 명령어를 통해 해결책을 지원한다. Memory
12.Mutex Locks
critical section 문제를 하드웨어 기반으로 해결하기엔 복잡할 뿐만 아니라 응용 프로그래머는 사용할 수가 없다. 그렇기에 운영체제 설계자들은 임계 영역 문제를 해결하기 위한 상위 수준 소프트웨어 도구들을 개발하였고 그 중 하나가 mutex locks이다.간단
13.Semaphores 세마포어
이전 Mutex lock과 유사하게 동작하지만 더 강력한 기능을 제공한다.세마포어의 S는 정수 변수로서, 초기화를 제외하고는 wait()와 signal()인 두개의 원자적 연산으로만 접근한다.S의 정수 변수를 다루는 모든 작업은 인터럽트 되지 않고 원자적으로 실행 되어
14.Monitors (모니터)
세마포어나 뮤텍스를 사용하더라도 프로그래머의 실수로 인해 상호 배제가 지켜지지 않거나, 데드락이 발생할 수 있다.모니터는 추상화된 데이터 형이다(Abstract Data Type). 모니터는 내부에 사용할 변수와 함수를 선언하고 선언된 변수와 함수는 모니터 지역 내에서
15.Liveness
프로세스가 실행 되는 동안 Progress되는것을 보장하기 위해 시스템이 충족해야하는 속성이다. Progress가 지켜지지 않으면 Bounded waiting 또한 지켜 질수 없으므로 이러한 프로세스는 라이브니스 실패라고 한다.라이브니스 실패는 간단하게 무한루프를 통해
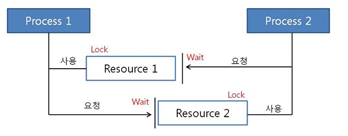
16.DeadLocks (교착 상태)
한 스레드가 자원을 요청했을때 그 자원이 이미 다른 스레드에서 점유 중이라면 요청 스레드는 대기상태에 들어간다. 이런식으로 모든 스레드가 대기상태에 들어가게 되어 어떠한 자원도 반납이나 점유가 이루어지지 못하는 상태를 데드락이라 한다.가장 중요한 핵심은 자원의 획득과
17.DeadLocks 특성
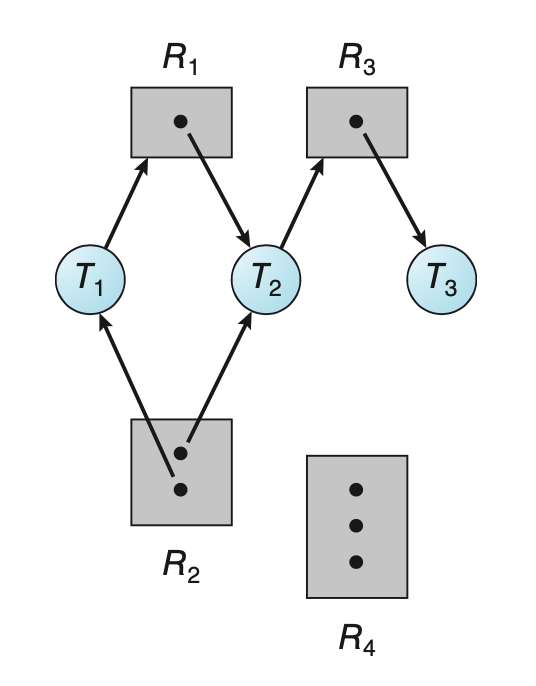
상호배제최소하나의 스레드만 자원에 접근할 수 있으며 해당 자원은 반납되기 전까지 누구도 접근할 수 없도록 한다.점유대기스레드는 자원을 점유한 채, 다른 스레드가 점유하고 있는 자원을 접근하기 위해선 반드시 대기하여야 한다.비선점자원들을 선점할 수 없다. 자원은 강제적으
18.DeadLocks 상태 처리 방법
데드락 상태 처리 방법 데드락 상태 처리 방법에는 3가지 방법이 있다. 문제를 무시하고, 교착 상태가 시스템에서 절대 발생하지 않는 척을 한다. 시스템이 결코 교착 상태가 되지 않도록 보장하기 위하여 교착 상태를 예방하거나 회피하는 프로토콜을 사용한다. 시스템이 교착
19. 교착 상태 예방
교착 상태가 발생하지 않도록 최소한 하나가 성립하지 않도록 보장한다. 이러한 기법을 예방이라고 한다.상호 배제를 하지 않음으로써 교착상태를 예방한다. 가장 좋은 예는 읽기-전용 파일이 공유 가능한 자원의 좋은 예이다. 여러 스레드가 읽기 전용의 파일을 열면, 그 파일에
20.교착 상태 회피
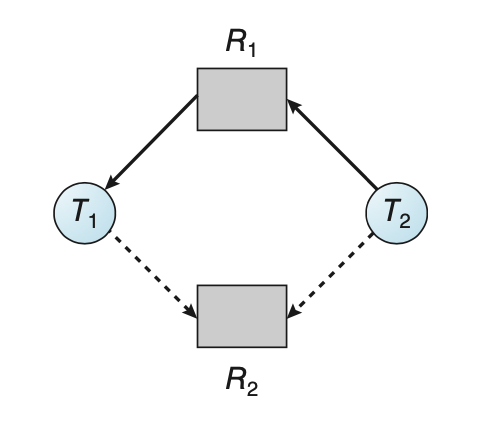
교착 상태 회피는 방법 중 하나는 자원이 어떻게 요청될지에 대한 정보를 제공하도록 요구하는 것이다.각 스레드의 요청과 방출에 대한 순서를 파악한다면 우리는 각 요청에 대해서 가능한 미래의 교착 상태를 피할 수 있다(스레드 대기를 통해). 이러한 동작을 위해 현재 가용자
21.교착 상태 탐지
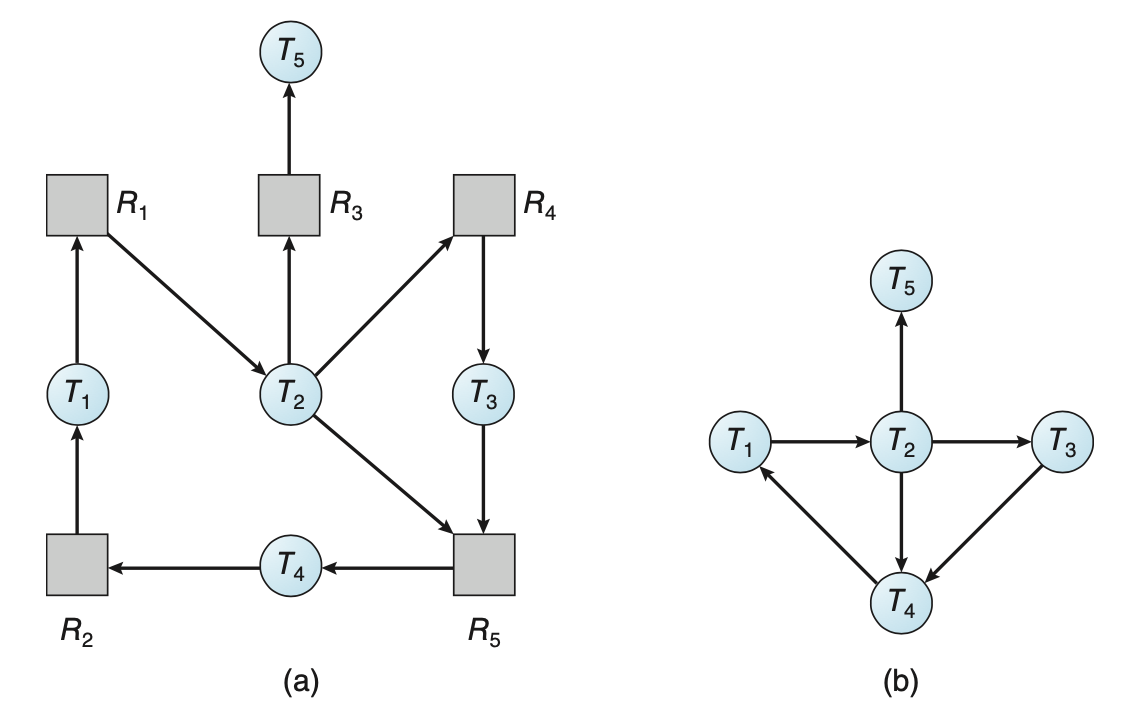
교착 상태 예방이나 회피 알고리즘을 사용하지 않는 시스템, 교착 상태가 발생할 수 있는 환경이라면 아래 두 알고리즘을 지원해야한다.교착 상태가 발생했는지 결정하기 위해 시스템의 상태를 검사하는 알고리즘.교착 상태로부터 회복하는 알고리즘.탐지와 회복 알고리즘 방법은 필요
22.교착 상태 회복
탐지 알고리즘으로 교착 상태를 확인한 후 처리에 대한 방법을 생각해야한다. 여러 방법 중 하나는 교착 상태 발생을 운영자에게 통지하여 운영자가 직접 처리하는 방법이고, 다른 방법은 시스템이 자동으로 회복하는 것이다. 교착 상태를 회복하는 방법은 순환 대기에 포함된 하나
23.메모리 계층 구조
폰 노이만 아키텍처 구조상 컴퓨터를 크게 나눠보면 CPU, 메인 메모리, IO장치들로 나누어진다. 이때 CPU는 CPU 내 레지스터에서 데이터를 가져올때 1틱 사이클이 발생한다. CPU 레지스터에 데이터가 없다면 데이터를 메인 메모리에서 가와야만 한다. 문제는 메인 메
24.하드웨어에서 메모리 관리
시스템이 올바르게 동작하기 위해서는 사용자 프로그램으로부터 운영체제 영역을 보호 해야한다. (운영체제도 현재 메모리에 상주해 있다는걸 잊지말자) 그리고 사용자 프로그램끼리도 메모리를 보호해야한다. 이러한 문제는 하드웨어가 해결해야 성능면에서 이점을 가질 수 있다. (소
25.프로그램의 주소 할당
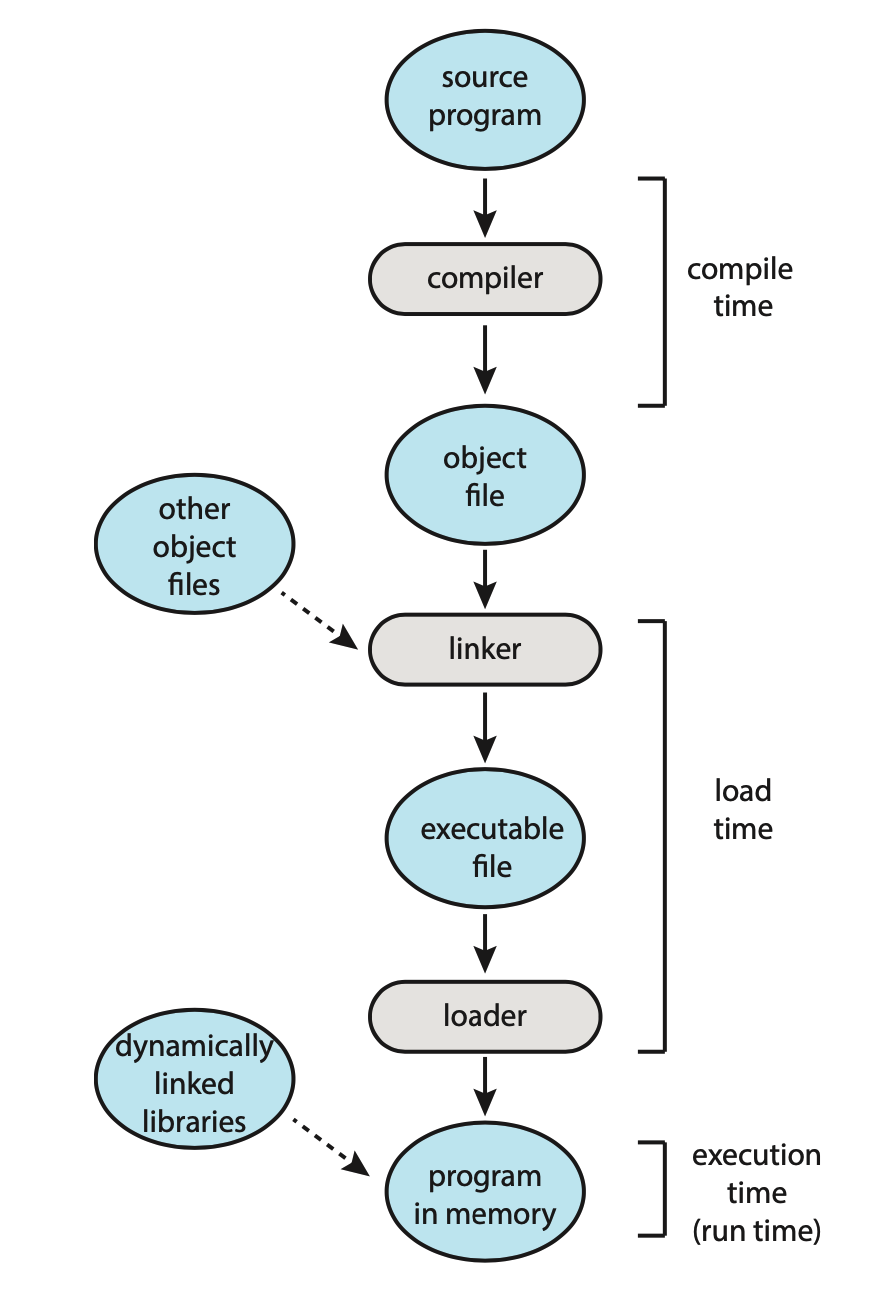
프로그램은 평상시 이진 실행 파일로 존재하다 메모리에 올라가는 순간 프로세스가 된다. 그러면 프로세스는 어떤 주소에 할당되며 프로그램 내 필요한 변수 주소를 어떻게 찾아야할까? 이러한 문제는 아래와 같이 해결할 수 있다.프로그램 내 count 변수가 있다고 하자.컴파일
26.논리, 물리 주소 공간
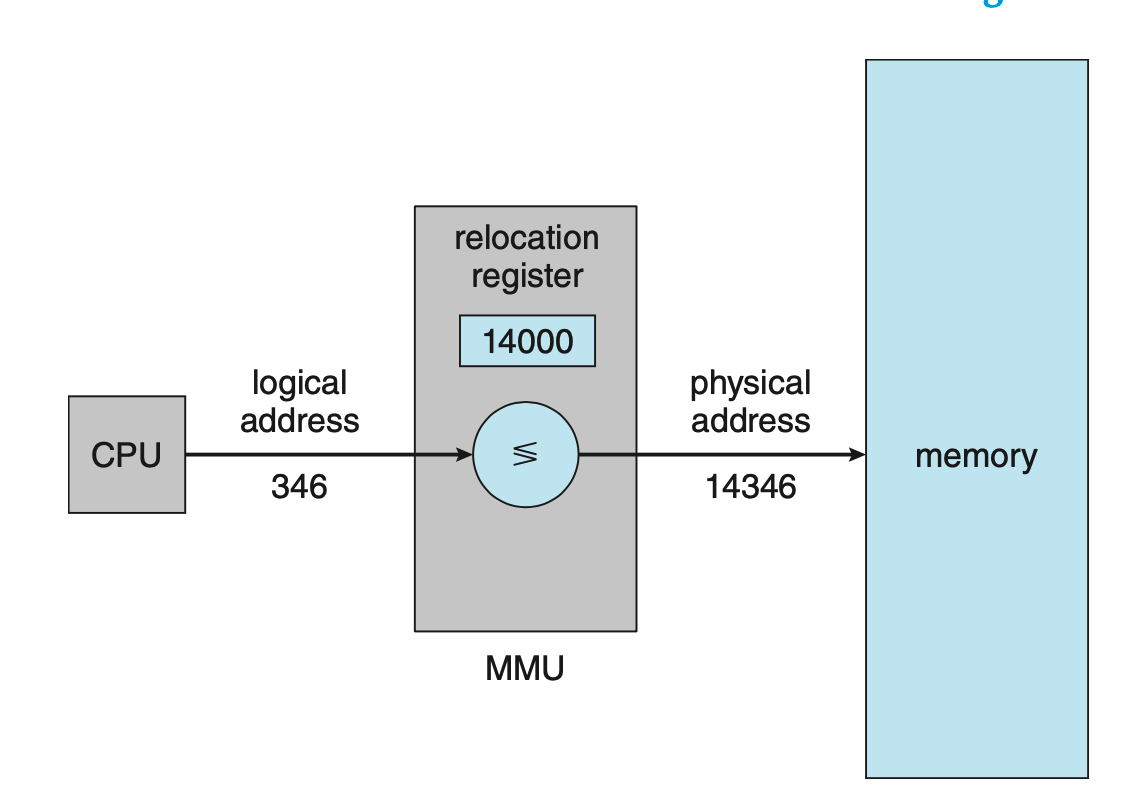
CPU가 생성하는 주소를 논리 주소라고 한다. 이렇게 생성된 논리 주소의 집합은 논리 주소 공간이라 한다.메모리가 취급하는 주소를 물리 주소라고 한다. 이러한 주소 집합을 물리 주소 공간이라 한다.컴파일 또는 적재 시에 주소를 바인딩하면 논리 주소와 물리 주소는 같게
27.동적 적재 (Dynamic Loading)
프로세스가 실행되기 위해선 프로세스가 전체 미리 메모리에 올라와야하며 이 크기는 메모리의 크기를 초과해서는 안된다. 이러한 문제를 해결하기 위해 동적 적재를 해야 한다.동적 적재란 각 루틴이 실제 호출 되기 전까지는 메모리에 올라오지 않고 재배치 가능한 상태로 디스크에
28.동적 연결 및 공유 라이브러리 (Dynamic Linking & Shared Libraries)
동적 연결 라이브러리 (DLL)은 사용자 프로그램이 실행될 때, 사용자 프로그램에 연결되는 시스템 라이브러리이다. 동적 연결 개념은 동적 적재와 유사하다. 동적 적재에서는 loading이 실행 시까지 미루어졌었지만 동적 연결은 linking이 실행 시기까지 미루어지는
29.연속 메모리 할당
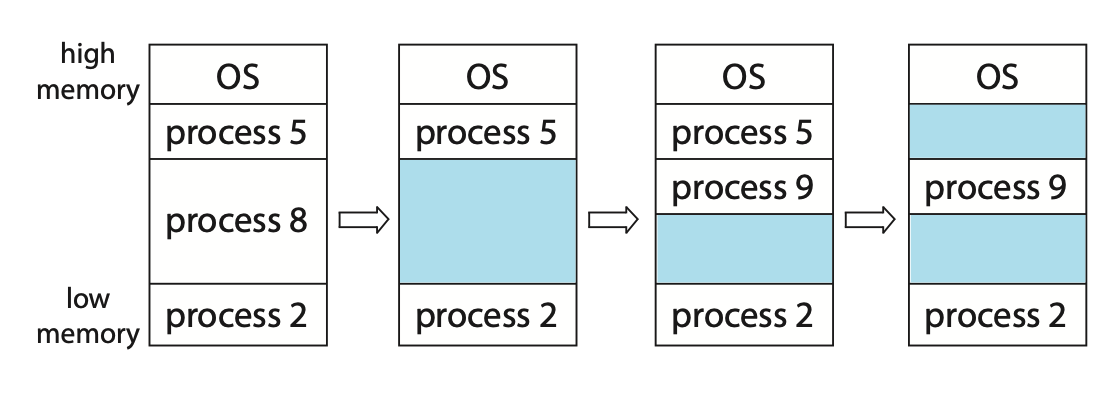
메인 메모리는 운영체제뿐만 아니라 사용자 프로세스도 수용해야 한다. 이때 우리는 여러 사용자 프로세스가 메모리에 상주하기를 원하며, 메모리에 적재되기를 기다리는 프로세스에게 사용 가능한 메모리를 할당하는 방법을 고려해야한다. 연속적 메모리 할당은 각 프로세스는 다음 프
30.페이징 Paging - 기본 방법
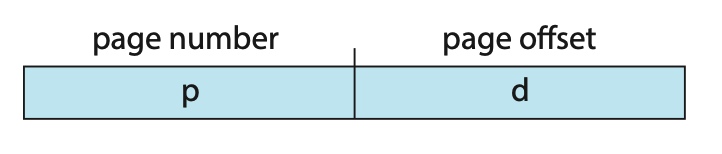
메모리를 비 연속적인 공간으로 나누어 프로세스가 요청한 크기의 공간이 있으면 할당하는 방식이다. 비 연속적인 공간이라는것은 프로세스가 메모리에 순차적으로 적재되지 않아도 된다는 말이다.물리 메모리는 프레임(fram)이라는 크기의 블록으로 나누어지며, 논리 메모리는 페이
31.페이징 Paging - 하드웨어 지원
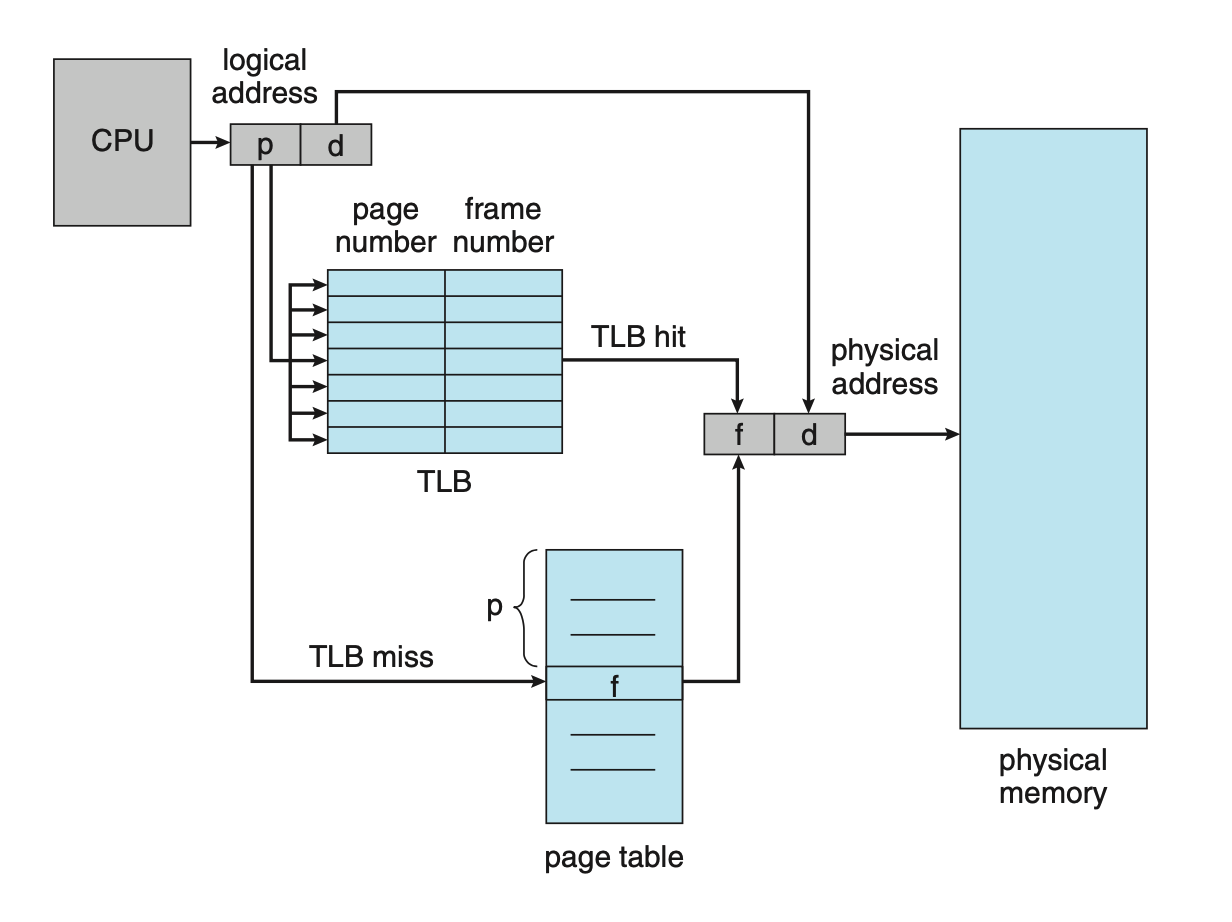
페이지 테이블은 프로세스별 자료구조이며 페이지 테이블에 대한 포인터는 각자의 PCB에 저장된다. CPU 스케쥴러가 실행할 프로세스를 선택하면 PCB에 저장된 레지스터값을 적재한 후 페이지 테이블에 값에 저장된 사용자 페이지 테이블로부터 적절한 하드웨어 페이지 테이블값을
32.페이징 Paging - 보호 (Protection)
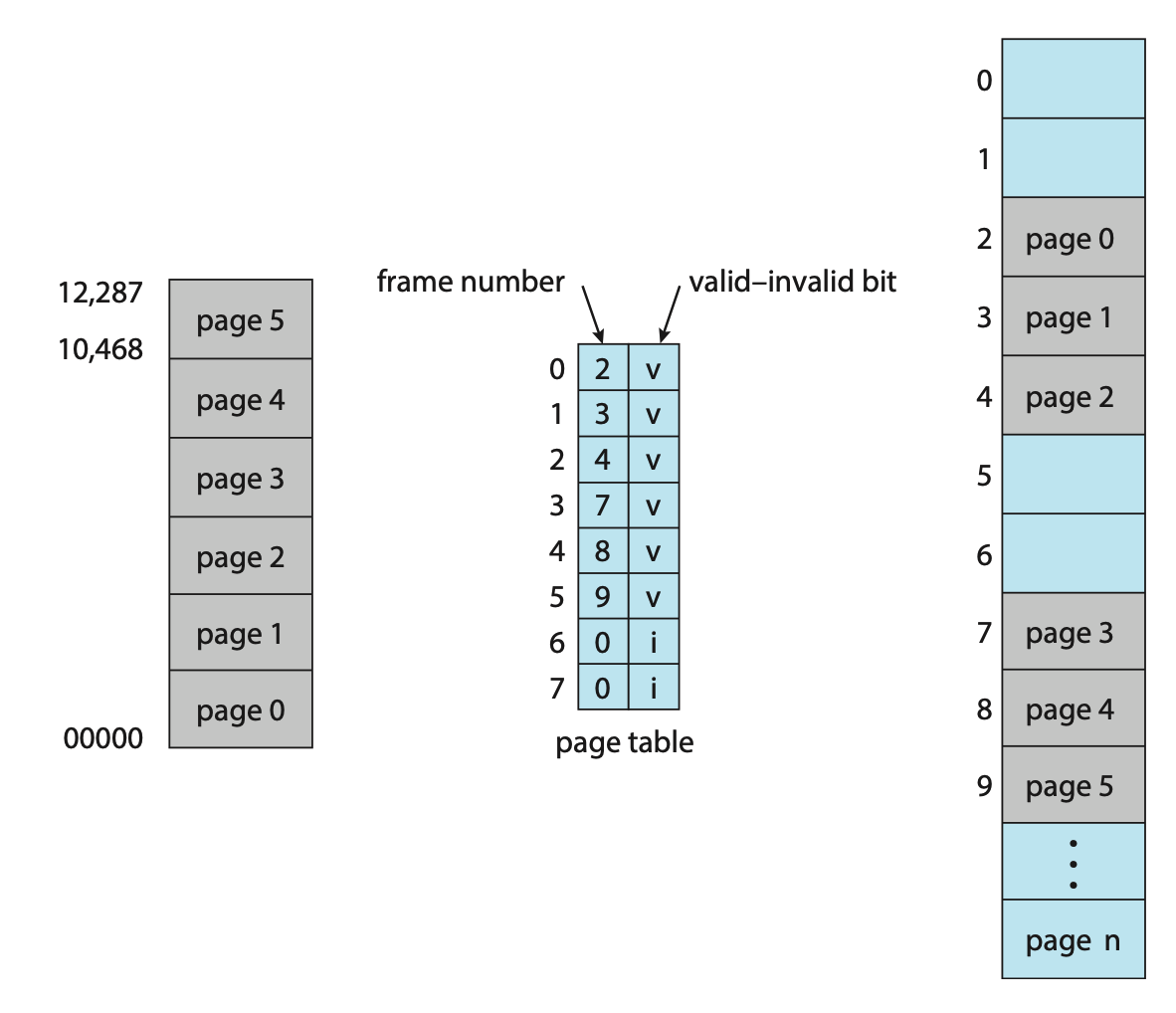
페이징 관경에서 메모리 보호는 각 페이지에 붙어있는 보호 비트에 의해 구현된다. 이 비트는 페이지 테이블 내에 존재한다.각 페이지는 읽기, 쓰기, 읽기 전용임을 각각 정의할 수 있다. 메모리에 대한 모든 접근은 페이지 테이블을 거치므로, 이때 주소 변환과 함께 이 페이
33.페이지 테이블의 구조 - 계층적 페이징
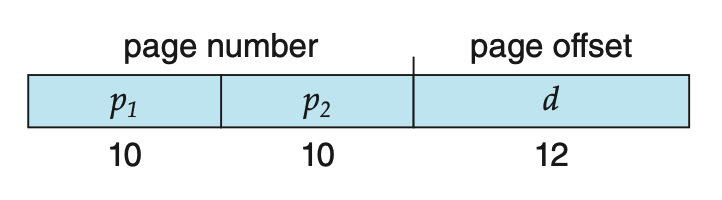
현대 컴퓨터는 매우 큰 주소 공간을 사용한다. (2^64와 같은) 이러한 환경에서는 페이지 테이블도 상당히 커지게 된다. 예를 들어 32Bit 논리 주소 공간을 가진 시스템에 페이지 크기가 4KB(2^12)라면 페이지 테이블은 2^20(2^32/2^12)개 이상의 항목
34.페이지 테이블의 구조 - 해시 페이지 테이블
이전에 설명한 방법들을 통해서 주소 공간이 매우 클 때는 일반적인 페이지 테이블은 문제가 발생함을 알 수 있었다.(페이지 테이블 크기가 너무 크다거나, 메모리 접근시 메인 메모리에 여러번 접근해야한다던가) 이 문제를 해결하기 위해 가상 주소를 해시로 사용하는 헤시 페이
35.페이지 테이블 구현
개념적인 페이지 테이블이 어떻게 동작할까 생각하며 구현하였습니다. 완벽히 개념과 일치하지는 않지만 어떤식으로 가상 주소가 물리주소로 맵핑 되는지에 대한 흐름을 이해 할 수 있을거라 생각합니다.(?)먼저 메인 메모리입니다. 간단하게 메모리 구조만 나타냈습니다. Byte