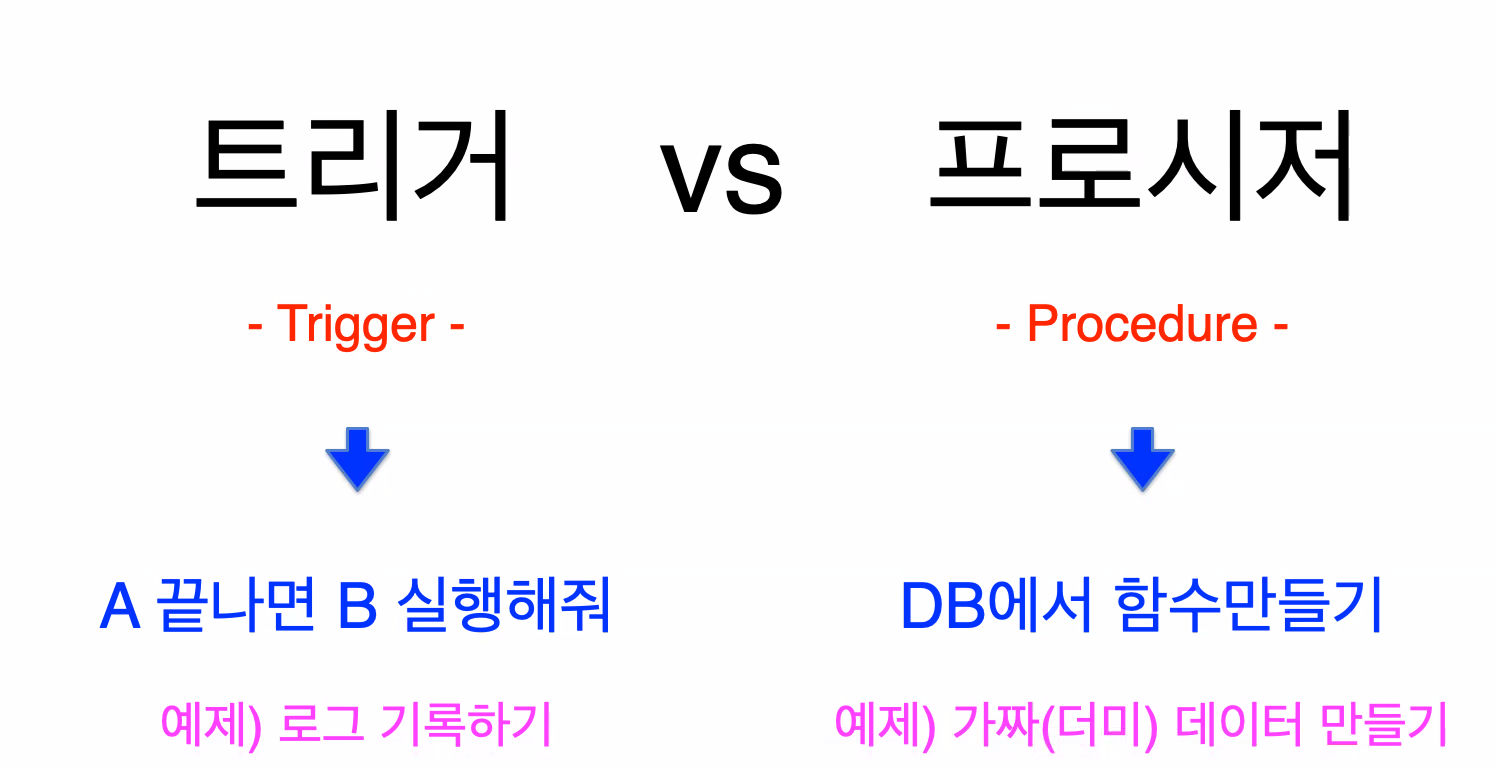
1. 트리거
2 .DB
-
옵티마이저: 검색을 효율적으로 해주는 DB내장기능
-
실행계획: 효율적인 검색 계획
-
Explain 명령어: 옵티마이저가 결정한 실행계획을 보여줘

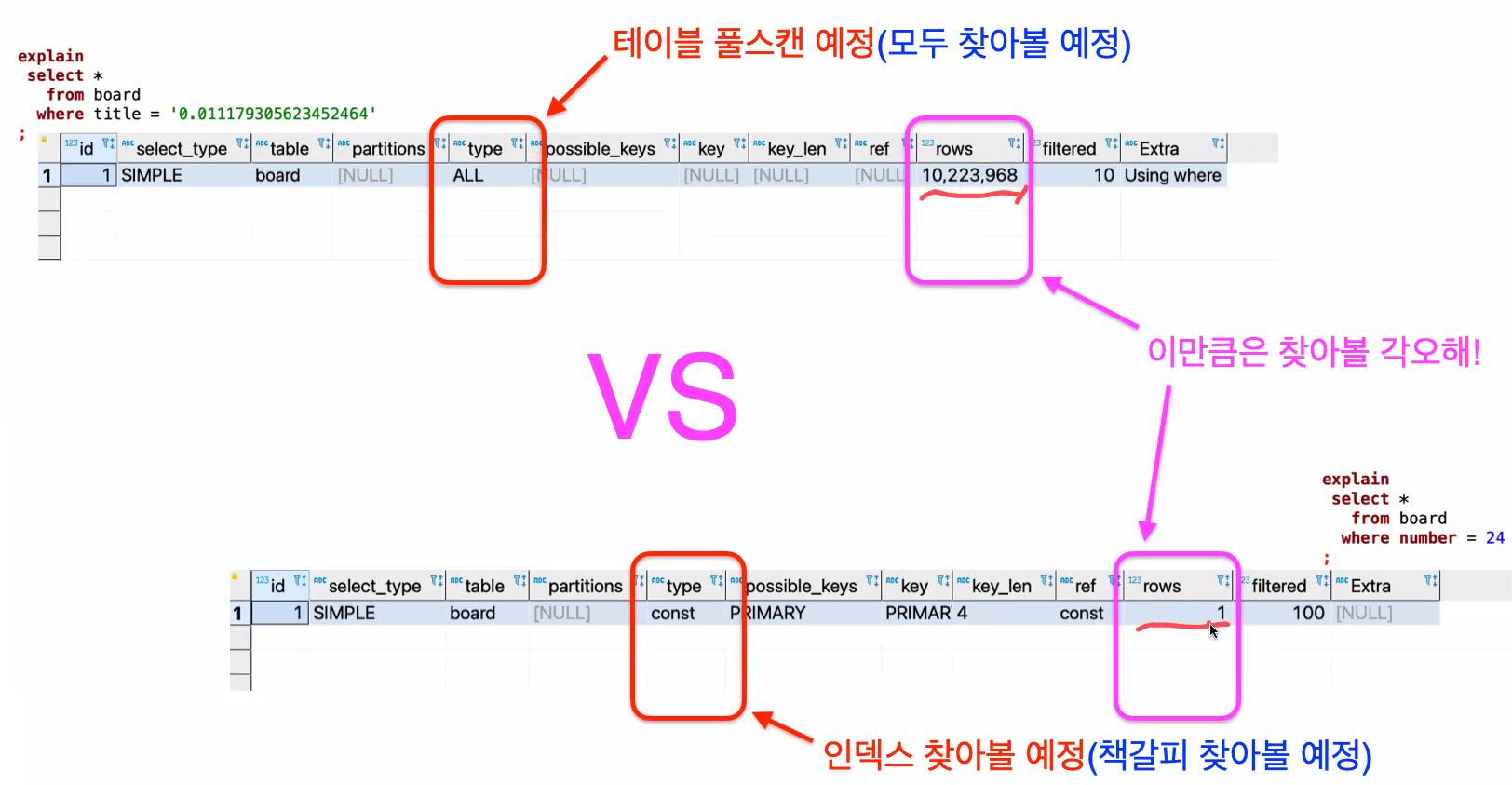
두 쿼리는 왜 다를까?
PK, FK, UNIQUE는 자동으로 인덱스(책갈피) 생성
=> 책갈피(인덱스)에서 뽑아오니까 더 빠른 것이다.
- 책갈피 보는 법
show index from board
PK, FK, UNIQUE 말고도 책갈피를 거는 법
create index idx_title on board(title) idx_title은 이름이라 아무거나 걸어도 됨

하지만 모든 컬럼에 인덱스를 걸면 안된다!!
인덱스(책갈피)를 건다는 뜻?
-
등록/수정시 책갈피에 맞게 데이터 정렬 필요
-
등록/수정의 속도를 포기하고 조회의 속도를 가져가는 것이다!!
3. redis
더 빠른 검색을 위해서 redis라는 곳에 저장을 한다.
-
redis는 메모리기반에 데이터베이스이다.
-
컴퓨터를 껐다켰을 때 데이터가 날아갈 수도 있다.
-
성능을 위해서 사용하는 것이기 때문에 보조용으로만 사용한다.
빠른검색용 vs 임시저장용
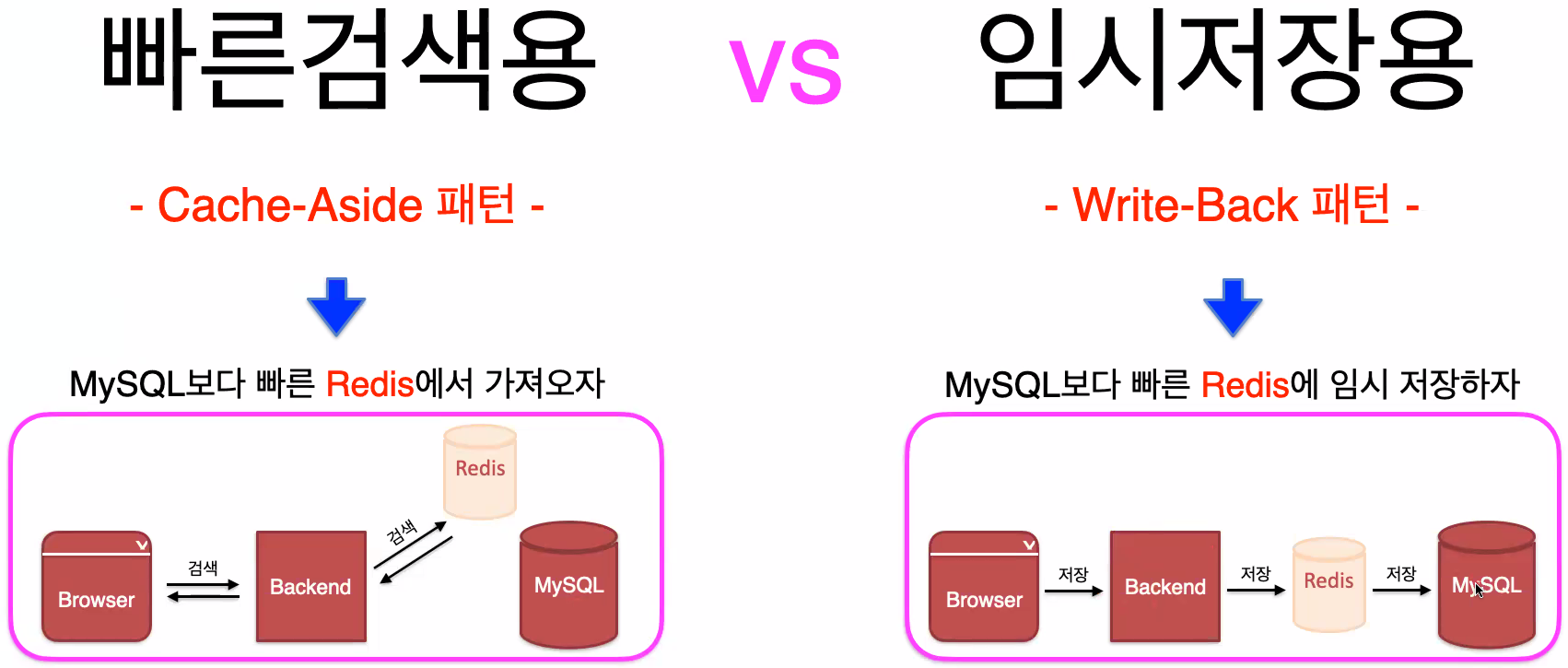
- Write-Back 패턴은 redis에 캐쉬만 저장한다음에 천천히 MYSQL에 저장함으로서
대량의 저장을 할 때 컴퓨터가 다운되는 것을 막아준다.
Cache-Aside 패턴
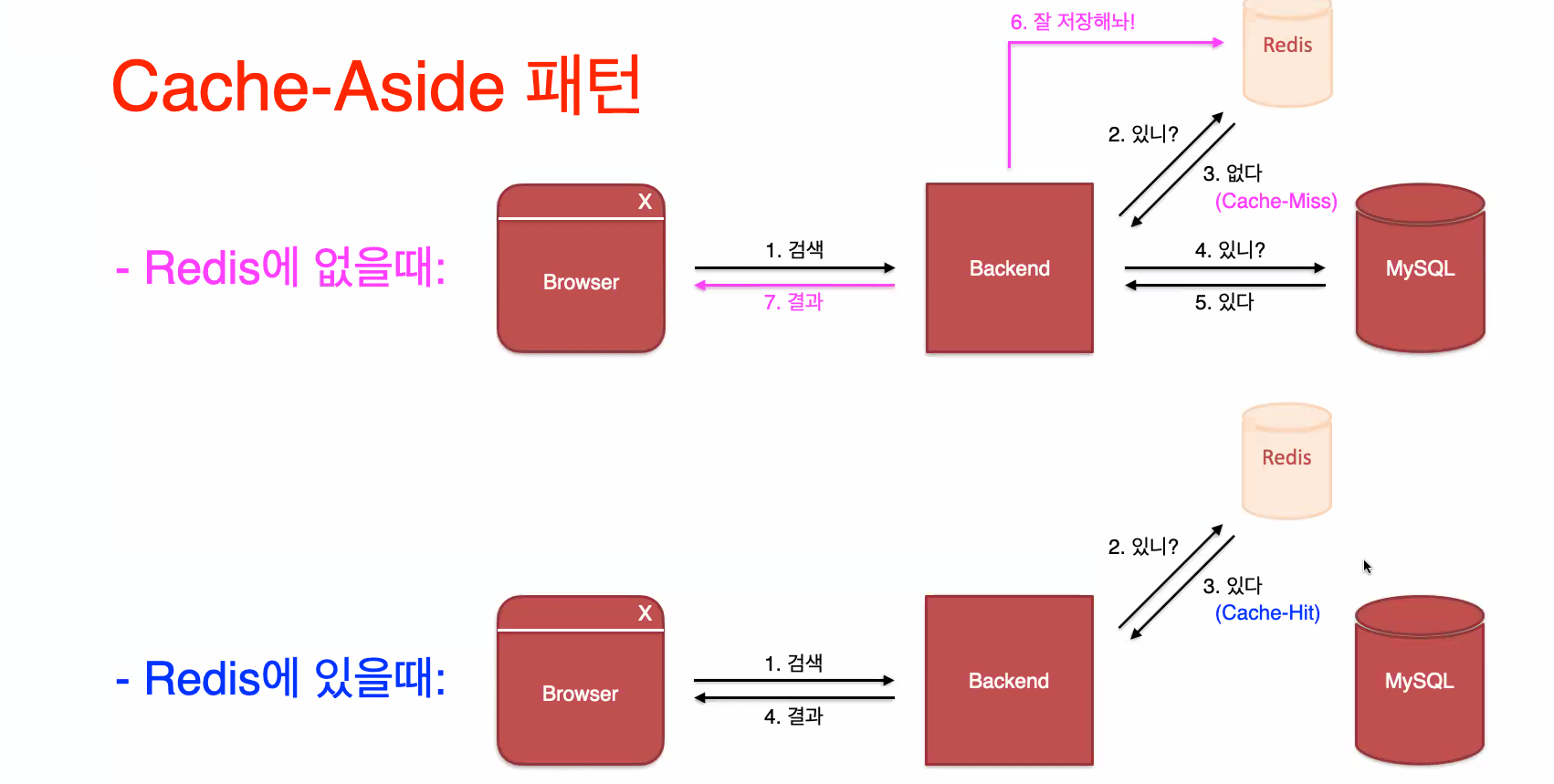
redis는 임시저장이라 ttl이라는 시간을 부여할 수 있다.
(integer) -1은 무제한이다
(integer) -2는 죽음을 의미한다.
yarn add cache-manager@4.1.0
yarn add cache-manager-redis-store@2.0.0
yarn add @nestjs/cache-manager
yarn add --dev @types/cache-manager-redis-store
maxmemory
보통 70% 정도를 쓰고 memory를 다 써도 maxmemory-policy에 따라 다르다.
-
noeviction
기존 데이터 삭제 안함. 메모리 한계에 도달하면 OOM 오류 반환하며 새 데이터가 저장되지 않는다.
더 이상 저장할 메모리가 없는데 기존 메모리도 제거 안하려니 프로그램이 종료된다. -
allkeys-lru
가장 권장하는 방식으로 모든 key들 중에 가장조금 최근에 사용된 것부터 지워버린다. -
volatile-lru
expire set을 가진 것 중 LRU로 삭제하여 공간확보 -
volatile-ttl
expire set을 가진 것 중 TTL이 짧은 것부터 삭제하여 공간확보
로그인 정보처럼 지우면 안되는 것이 있기에 그러면 여러대의 Redis를 연결해서 묶음으로 사용하여 이걸
Redis-Cluster라고 부른다.
