코드스테이츠 AI 부트캠프 04기 Section2
1.AI 부트캠프 26일차

선형회귀모델지도학습(Supervised Learning)회귀모델에 기준모델을 설정Scikit-learn을 이용해 선형 회귀 모델을 만들어 사용하고 해석
2021년 6월 8일
2.AI 부트캠프 27일차
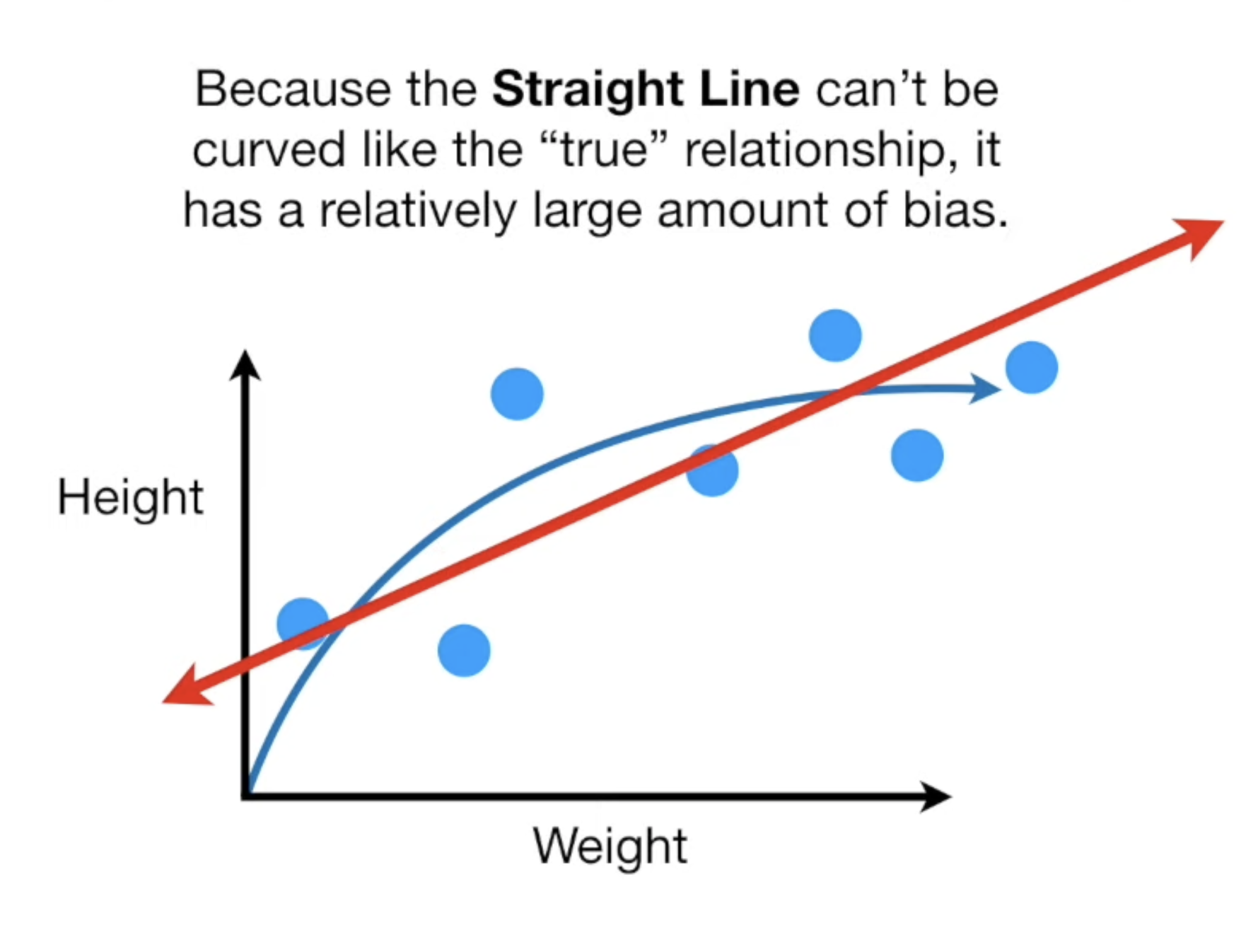
머신러닝모델을 만들 때 학습과 테스트 데이터를 분리 해야 하는 이유다중선형회귀과적합/과소적합을 일반화 관점에서 설명편향/분산의 트레이트오프 개념을 이해하고 일반화 관점에서 설명예측 모델을 만들기 전에 간단하게 최소한의 성능을 나타내는 기준이 되는 모델관찰된 연속형 변수
2021년 6월 9일
3.AI 부트캠프 28일차
릿지 회귀 모델 "수식"L2 Norm선형회귀모델의 식과 릿지 회귀 모델의 식이 무엇이 다른가
2021년 6월 10일
4.AI 부트캠프 31일차

S2-WEEK2트리 모델트리 모델을 기반으로 한 최신 앙상블 모델까지 다룸category_encodersgraphviznumpypandasscikit-learn데이터가 가진 특성값 기준으로 샘플들을 분류해가는 모델앙상블 모델의 기초가 되는 모델장점다른 모델보다 성능이
2021년 6월 14일
5.AI 부트캠프 33일차

좋지 않음ex) 100개의 sample : 99개가 yes, 1개가 no모두 yes로 예측하는 모델의 정확도 : 99%이지만 실제로 좋은 모델이라고 할 수 없다\-> Precision, Recall F-beta score 사용Precisionrelevant = posi
2021년 6월 22일