S1-WEEK3 Note 03 : Dimension Reduction
학습목표
- Vector transformation
- eigenvector / eigenvalue
- 고차원의 문제 (The Curse of Dimensionality)
- PCA (Principal Component Analysis)
Vector transformation
-
선형변환
임의의 두 벡터 덧셈 or 스칼라 곱 -
matrix를 곱하는 것을 통해, 벡터(데이터)를 다른 위치로 옮긴다
Linear projection도 일종의 vector transformation
Eigenvector / Eigenvalue
-
Eigenvector (고유벡터)
주어진 transformation에 대해서 크기만 변하고 방향은 변화 하지 않는 벡터 -
Eigenvalue (고유값)
변화하는 크기 = 스칼라 = 고유값
고차원의 문제 (The Curse of Dimensionality)
피쳐의 수가 많은 (100 혹은 1000개 이상의) 데이터셋을 모델링하거나 분석할때에 생기는 여러 문제점들
- 데이터의 시각화나 탐색이 어려워짐
- 모델링에서의 overfitting 이슈
제한적인 해결책 : pairplot
변수들의 가능한 조합에 대해서 scatter plot
동일한 변수 조합에 대해서는 histogram
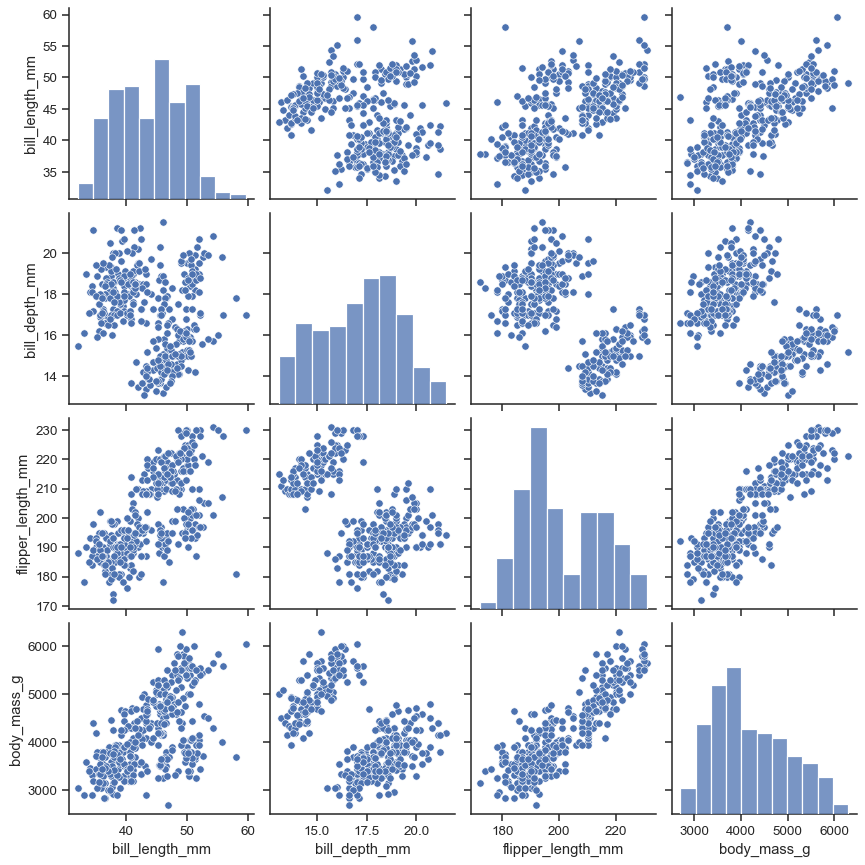 대각선을 기준으로 그래프가 대칭 -> 상당히 많은 양의 불필요한 scatterplot
대각선을 기준으로 그래프가 대칭 -> 상당히 많은 양의 불필요한 scatterplot
유의미한 Feature을 선별할 필요성 -> Dimension Reduction
높은 feature의 다른 문제점 : overfitting
 feature의 수가 sample 수보다 같거나 많을 때, overfitting 문제 발생
feature의 수가 sample 수보다 같거나 많을 때, overfitting 문제 발생
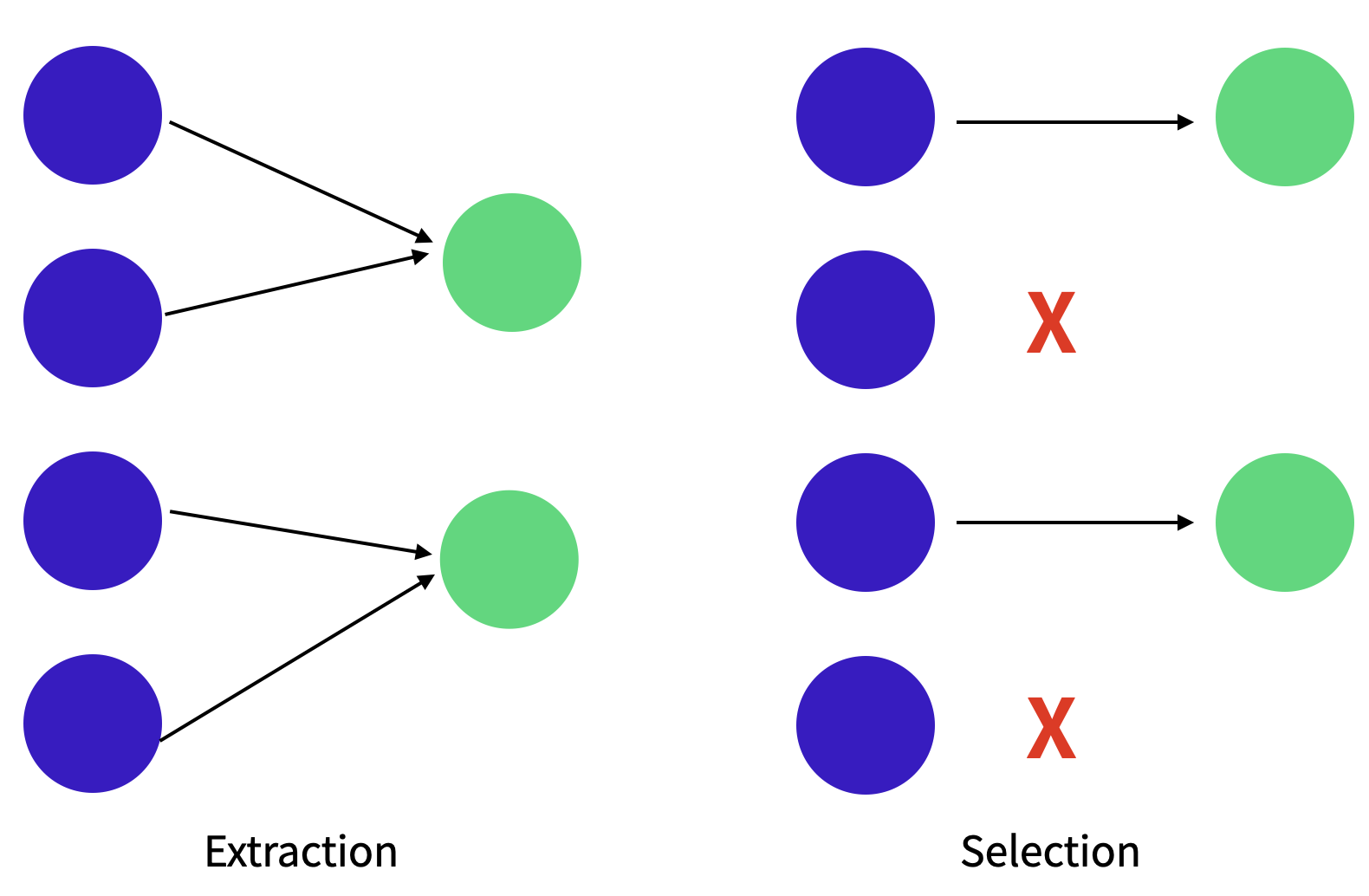
Dimension Reduction
-
Feacture Selection
데이터셋에서 덜 중요한 feature를 제거 -
Feature Extraction (Feature engineering과 유사)
기존에 있는 Feature 혹은 그들을 바탕으로 조합된 Feature를 사용
PCA도 Feature Extraction의 한 종류
Feacture Selection
장점 : 선택된 feature 해석이 쉽다.
단점 : feature들간의 연관성을 고려해야함.
예시 : LASSO, Genetic algorithm 등
Feature Extraction
장점 : feature 들간의 연관성 고려됨. feature수 많이 줄일 수 있음
단점 : feature 해석이 어려움.
예시 : PCA, Auto-encoder 등
Principal Component Analysis (PCA)
고차원 데이터를 효과적으로 시각화 + clustering
원래 고차원 데이터의 정보(분산)를 최대한 유지하는 벡터를 찾고
해당 벡터에 대해 데이터를 (Linear) Projection
데이터의 흩어진 정도를 가장 크게 하는 벡터 축(분산이 가장 큰 축)에
데이터를 (Linear) Projection
PCA Process
다차원 데이터를 2차원으로 축소
제일 정보 손실이 적은 2차원 고르기
- 각 열에 대해서 평균을 빼고, 표준편차로 나누어서 Normalize
- 분산-공분산 매트릭스를 계산
- 분산-공분산 매트릭스의 고유벡터와 고유값을 계산
- 데이터를 고유 벡터에 projection
PCA는 고차원의 데이터를 분산을 유지하는 축 (PC)을 기반으로 데이터를 변환
-> PC 들중 일부를 사용하는 것으로 차원 축소 가능
실제로는 sklearn 라이브러리 사용
from sklearn.preprocessing import StandardScaler, Normalizer
from sklearn.decomposition import PCA
# Normalize
scaler = StandardScaler()
# Standardized Data
Z = scaler.fit_transform(X)
# 차원결정 (2차원)
pca = PCA(2)
pca.fit(X)
# Projected Data
B = pca.transform(X)PCA 특징
- 데이터에 대해 독립적인 축을 찾는데 사용 할 수 있음.
- 데이터의 분포가 정규성을 띄지 않는 경우 적용이 어렵
이 경우는 커널 PCA 를 사용 가능 - 분류/예측 문제에 대해서 데이터의 라벨을 고려하지 않기 때문에 효과적 분리가 어려움
이 경우는 PLS 사용 가능
