파일 시스템은 컴퓨터에서 파일이나 자료를 쉽게 발견할 수 있도록, 유지 및 관리하는 방법이다.
저장매체에는 수많은 파일이 있기 때문에, 이런 파일들을 관리하는 방법을 말한다.
특징
- 커널 영역에서 동작
- 파일 CRUD 기능을 원활히 수행하기 위한 목적
- 계층적 디렉터리 구조를 가짐
- 디스크 파티션 별로 하나씩 둘 수 있음
역할
- 파일 관리 : 파일 저장, 참조, 공유
- 보조 저장소 관리 : 저장 공간 할당
- 파일 무결성 메커니즘 : 파일이 의도한 정보만 포함하고 있음을 의미
- 접근 방법 제공 : 저장된 데이터에 접근할 수 있는 방법 제공
개발 목적
- 하드디스크와 메인 메모리 속도차를 줄이기 위함
- 파일 관리
- 하드디스크 용량 효율적 이용
구조
- 메타 영역 : 데이터 영역에 기록된 파일의 이름, 위치, 크기, 시간정보, 삭제유무 등의 파일 정보
- 데이터 영역 : 파일의 데이터
접근 방법
- 순차 접근(Sequentail Access)
가장 간단한 접근 방법으로, 대부분 연산은 read와 write
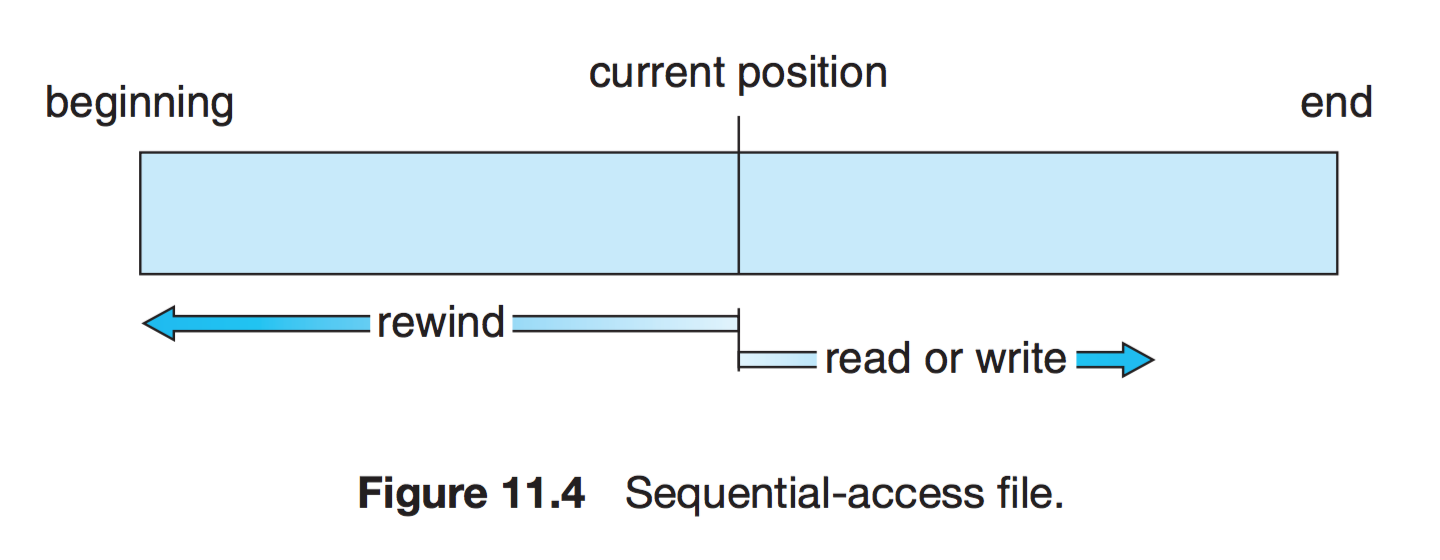
현재 위치를 가리키는 포인터에서 시스템 콜이 발생할 경우 포인터를 앞으로 보내면서 read와 write를 진행한다. 뒤로 돌아갈 땐 지정한 offset만큼 되감기를 해야 한다. (테이프 모델 기반)
- 직접 접근(Direct Access)
특별한 순서없이, 빠르게 레코드를 read, write 기능
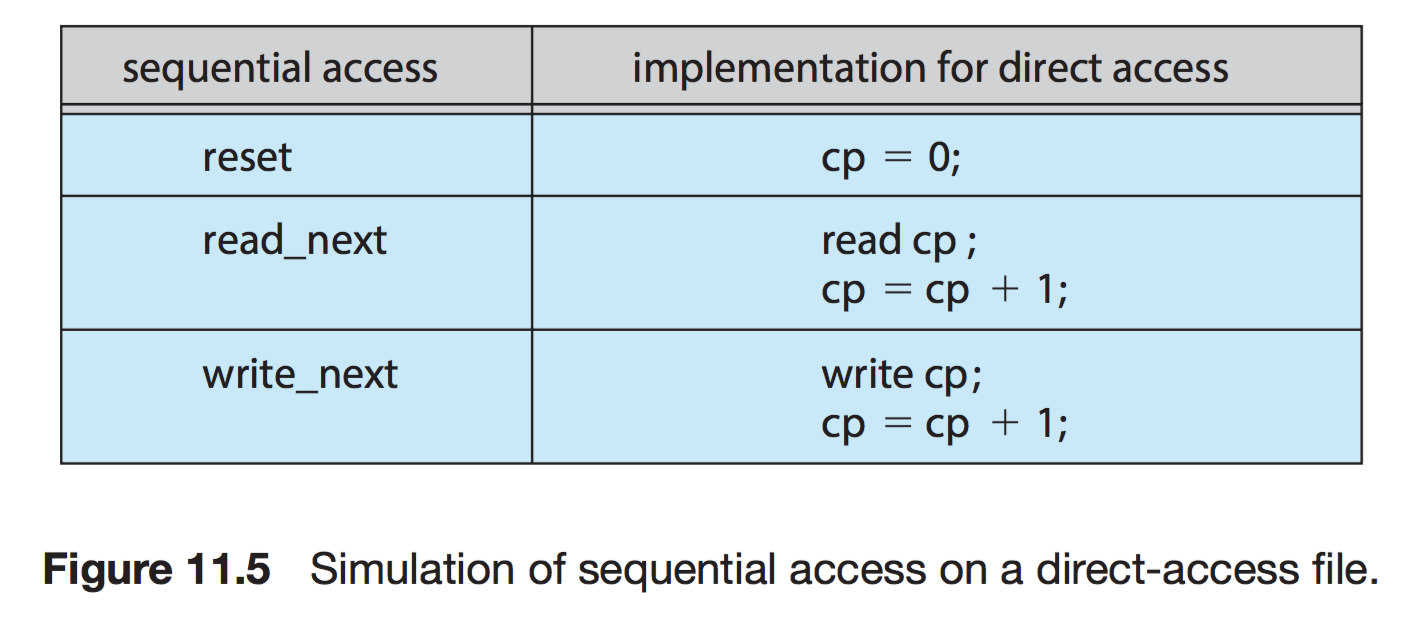
현재 위치를 가리키는 cp 변수만 유지하면 직접 접근 파일을 가지고 순차 파일 기능을 쉽게 구현이 가능하다.
무작위 파일 블록에 대한 임의 접근을 허용한다. 따라서 순서의 제약이 없다.
대규모 정보를 접근할 때 유용하기 때문에 '데이터베이스'에 활용된다.
- 기타 접근
직접 접근 파일에 기반하여 색인 구축
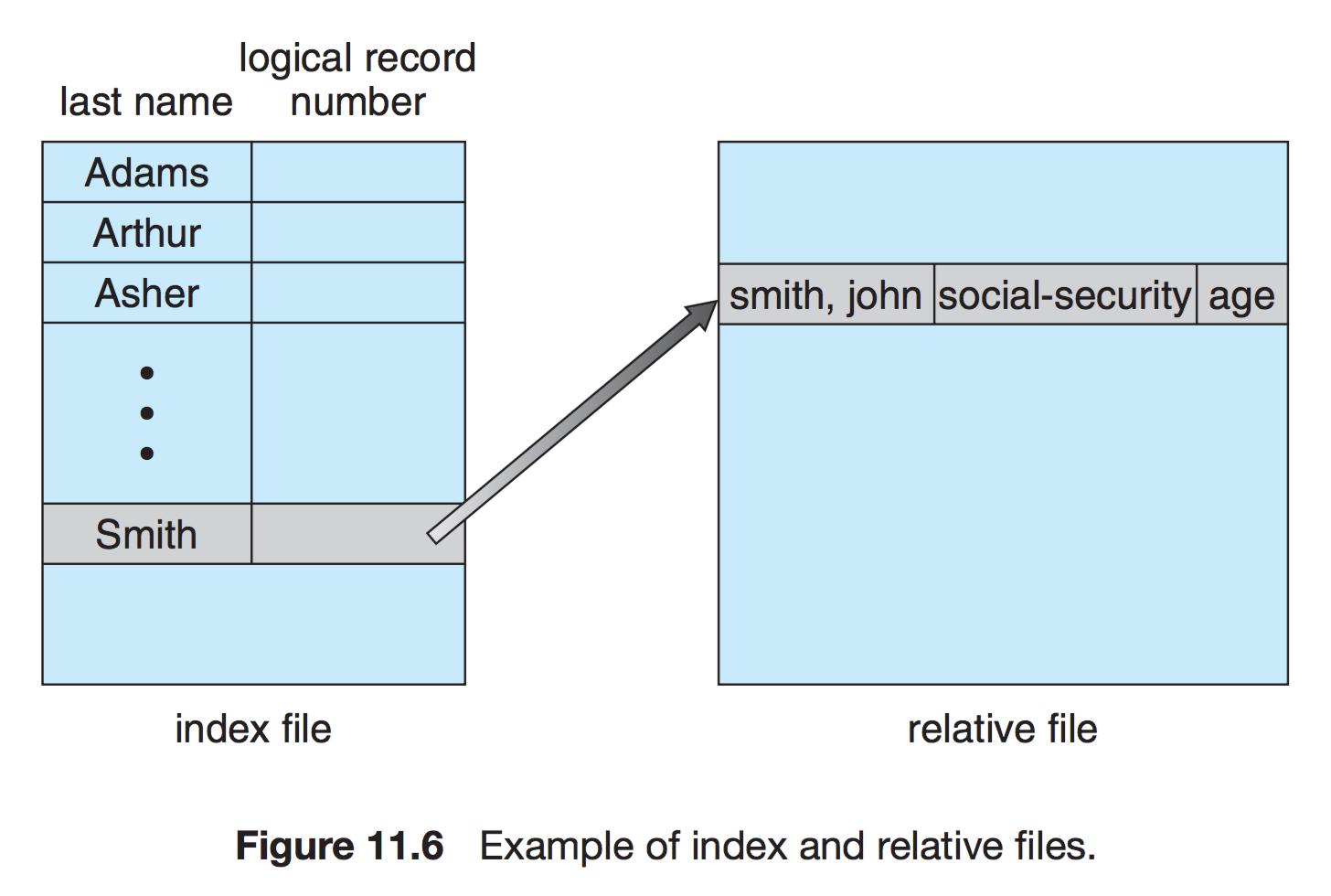
크기가 큰 파일을 입출력 탐색할 수 있게 도와주는 방법이다.
직접 접근 파일이 있으면 그것을 기반으로 여러 가지 다른 파일 접근 방법을 제공할 수 있다. 그런데 이들은 대부분 파일에 대한 색인(index)을 사용한다. 찾으려고 하는 레코드가 있으면 먼저 이 색인부터 찾아 그에 대응하는 포인터를 얻는다. 그런 다음 그 포인터를 사용하여 파일을 직접 접근하고 원하는 레코드를 찾는다.
파일이 아주 크면 색인 자체도 매우 커서 메모리에 다 들어가지 못할 수가 있으므로 그것 자체를 파일로 만들어 주어야 한다. 색인 파일이 너무 커지면 그것에 대해서도 또 색인을 만들 수 있다. 일차 색인 파일(primary index file)은 이차 색인 파일의 포인터를 가지고 이는 다시 실제 자료 항목을 가리킨다.
IBM의 ISAM(index sequential access method)은 크기가 작은 마스터 색인을 메모리에 유지하고 그것이 이차 색인 디스크 블록을 가리키도록 한다. 이차 색인이 실제 파일 블록을 가리킨다. 파일은 키 값에 따라 순서대로 유지한다. 어떤 특정 항목을 찾기 위해서는 먼저 마스터 색인에서 이진 탐색을 하여 이차 색인 블록 번호를 알아 낸다. 이 블록을 읽은 후 다시 이진 탐색을 하여 원하는 레코드를 찾아내고 마지막으로 이 블록을 순차적으로 탐색 한다.
이러한 방법은 어떠한 레코드도 최대 두 번의 직접 접근 읽기로 그 위치를 알 수 있다.
디렉터리와 디스크 구조
- 1단계 디렉터리
가장 간단한 구조
파일들은 서로 유일한 이름을 가짐. 서로 다른 사용자라도 같은 이름 사용 불가하다.
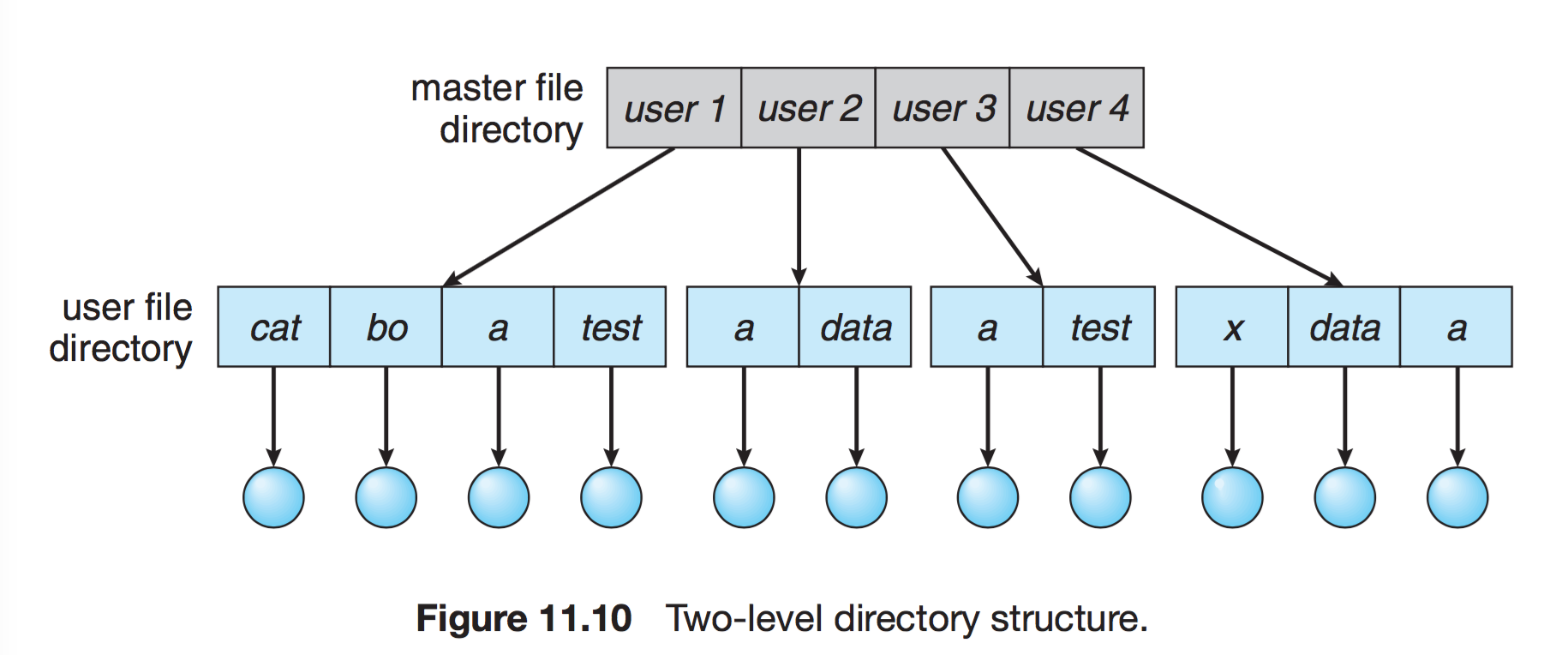
- 2단계 디렉터리
사용자에게 개별적인 디렉터리 만들어줌
UFD : 자신만의 사용자 파일 디렉터리
MFD : 사용자의 이름과 계정번호로 색인되어 있는 디렉터리
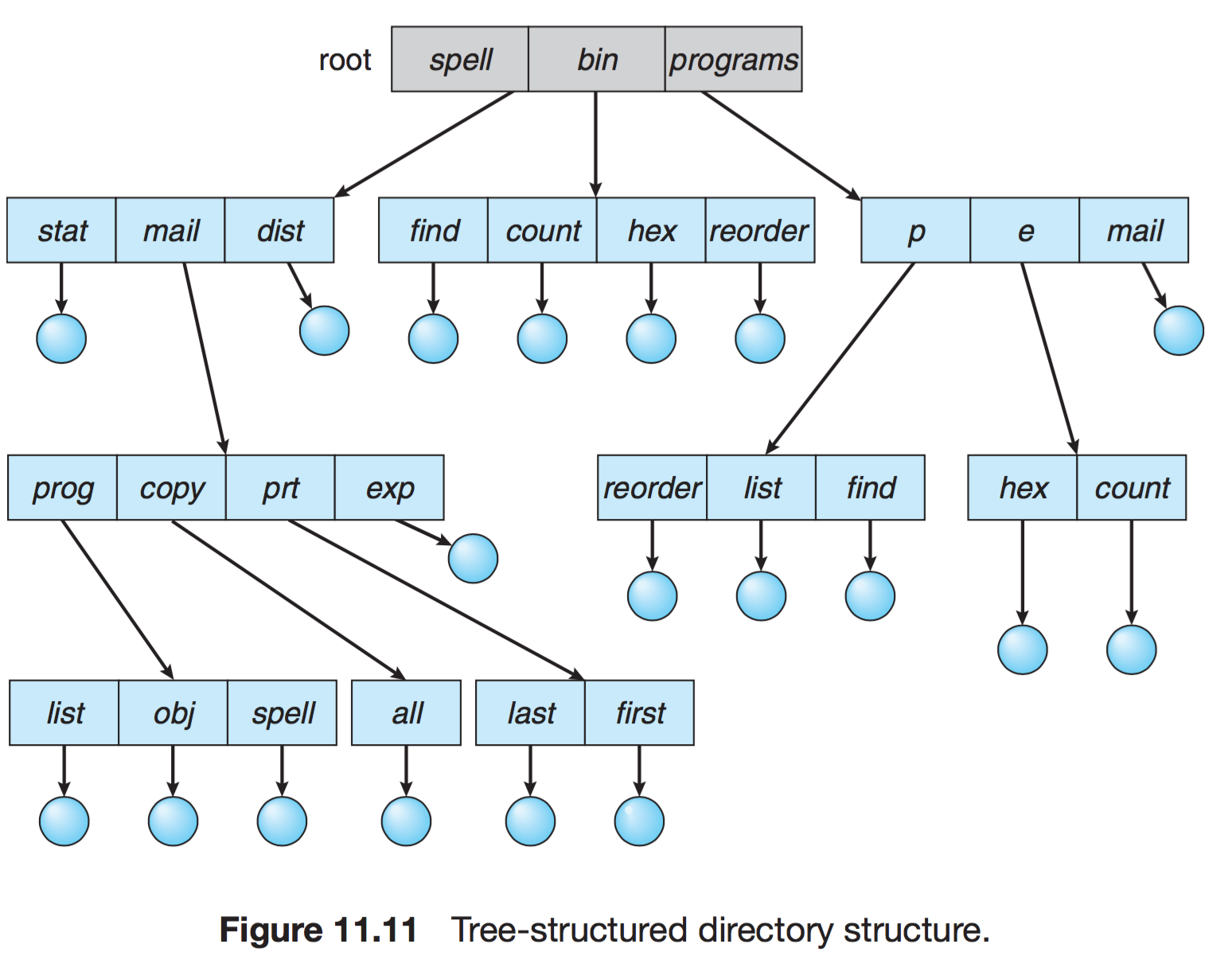
- 트리 구조 디렉터리
2단계 구조 확장된 다단계 트리 구조
한 비트를 활용하여, 일반 파일(0)인지 디렉터리 파일(1) 구분한다.
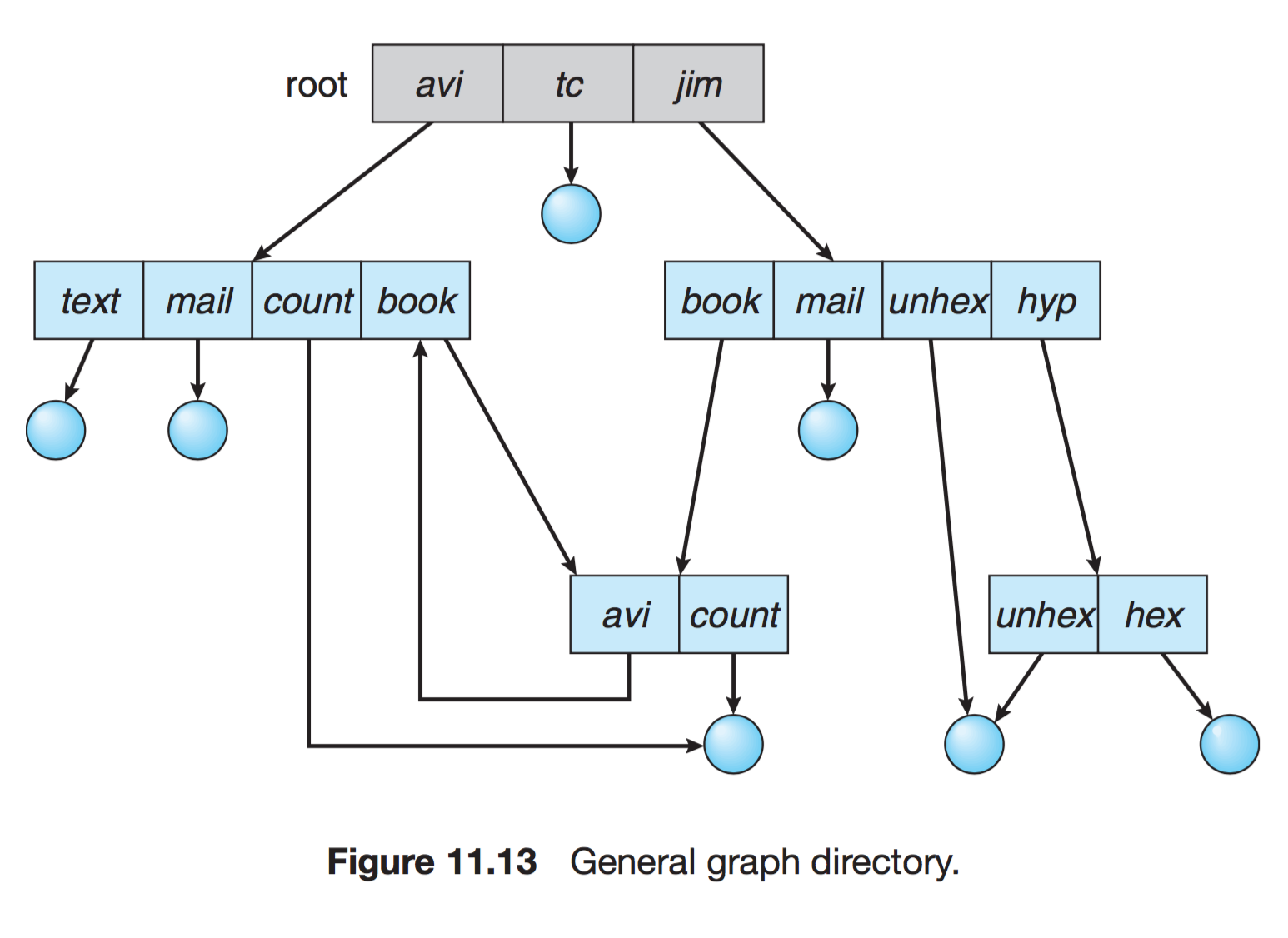
- 그래프 구조 디렉터리
순환이 발생하지 않도록 하위 디렉터리가 아닌 파일에 대한 링크만 허용하거나, 가비지 컬렉션을 이용해 전체 파일 시스템을 순회하고 접근 가능한 모든것을 표시
링크가 있으면 우회하여 순환을 피할 수 있다.
Source
- https://gyoogle.dev/blog/computer-science/operating-system/File%20System.html
- https://security-nanglam.tistory.com/228
- https://sungwookkang.com/199#:~:text=%5B%EC%88%9C%EC%B0%A8%20%EC%A0%91%EA%B7%BC%20(Sequential%20Access)%5D&text=%EB%94%94%EC%8A%A4%ED%81%AC%EC%97%90%20%EC%9E%88%EB%8A%94%20%ED%8C%8C%EC%9D%BC%EC%9D%84,%EC%9C%BC%EB%A1%9C%20%ED%8C%8C%EC%9D%BC%EC%9D%84%20%EC%A0%91%EA%B7%BC%20%ED%95%9C%EB%8B%A4
- https://blackjellybear.tistory.com/56
