DB Index
- 목적 : RDBMS에서 검색 속도를 높이기 위한 기술이고,
table의 Column을 색인화한다. (따로 파일로 저장)
-> 해당 Table의 Record를 Full scan 하지 않는다.
-> 색인화 된 (B+ Tree 구조로) Index 파일 검색으로 검색 속도 향상
- 과정 : Table을 생성하면, MYD, MYI, FRM 3개의 파일이 생성된다.
- FRM : 테이블 구조가 저장되어 있는 파일
- MYD : 실제 데이터가 있는 파일
- MYI : Index 정보가 들어가 있는 파일
Index를 사용하지 않는 경우, MYI 파일은 비어져 있다. 그러나 인덱싱하는 경우 MYI 파일이 생성된다.
이후에 사용자가 Select 쿼리로 Index를 사용하는 Column을 탐색 시, MYI 파일의 내용을 검색한다.
- 단점
- Index 생성 시, .mdb 파일 크기 증가
- 한 페이지를 동시에 수정할 수 있는 병행성이 줄어듦.
- 인덱스된 Field에서 Data를 업데이트하거나, Record를 추가 또는 삭제 시 성능이 떨어짐.
- 데이터 변경 작업이 자주 일어나는 경우, Index를 재작성해야 하므로, 성능에 영향을 미침.
- 상황 분석
- 사용하면 좋은 경우
(1) Where 절에서 자주 사용되는 Column
(2) 외래키가 사용되는 Column
(3) Join에 자주 사용되는 Column - Index 사용을 피해야 하는 경우
(1) Data 중복도가 높은 Column
(2) DML이 자주 일어나는 Column
- DML이 일어났을 때의 상황
- INSERT : 새로운 데이터에 대한 인덱스를 추가한다.
- DELETE : 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업을 진행한다.
- UPDATE : 기존의 인덱스를 사용하지 않음 처리하고, 갱신된 데이터에 대해 인덱스를 추가한다.
- Index 구조
인덱스에는 여러가지 유형이 있지만 그중에서도 가장 많이 사용하는 인덱스의 구조는 밸러스드 트리 인덱스 구조이다. 그리고 B Tree 인덱스 중에서도 가장 많이 사용하는 것은 B Tree와 B + Tree 구조가 가장 많이 사용되는 인덱스의 구조다.
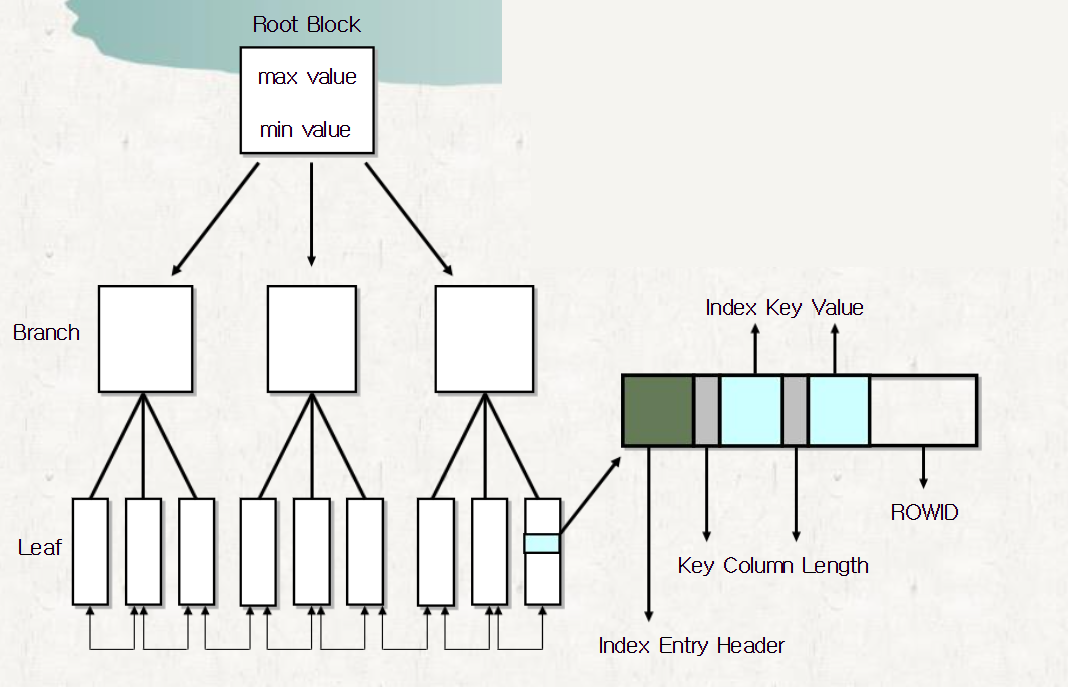
B Tree 인덱스는 대부분의 DBMS 그리고 오라클에서 특히 중점적으로 사용하고 있는 가장 보편적인 인덱스이다. 구조는 위와 같이 Root(기준) / Branch(중간) / Leaf(말단) Node로 구성되며 계층적 구조를 갖고 있다. 특정 컬럼에 인덱스를 생성하는 순간 컬럼의 값들을 정렬하는데, 오라클 서버에서 풀 스캔보다 인덱스 스캔이 유리하다고 판단되었을 때 생성된 인덱스의 정렬한 순서가 중간쯤 되는 데이터를 뿌리에 해당하는 ROOT 블록으로 지정하고 ROOT 블록을 기준으로 가지가 되는 BRANCH블록을 정의하며 마지막으로 잎에 해당하는 LEAF 블록에 인덱스의 키가 되는 데이터와 데이터의 물리적 주소 정보인 ROWID를 저장한다.
- 참고) ROOT에는 BRANCH 블럭의 시작점에 대한 정보를 갖고 있어 찾고자 하는 데이터의 위치가 어느 BRANCH에 위치하는지 알 수 있다. BRANCH 블럭에서도 마찬가지로 LEAF 블럭에 대한 시작점 정보를 갖고 있어 어느 LEAF에 포함되어 있는지 알 수 있다.
Source

Nuxt, Nest 개발자