2024-03-28
Oracle 10g 설치
Oracle은 Oracle 사에서 만든 RDBMS 소프트웨어인데 현재 오픈소스인 MySQL도 소유하고 있다. 관계형 데이터베이스(RDBMS)라 하는 것은 하나의 많은 요소들이 들어 있는 원본 테이블을 목적에 맞게 여러 개의 테이블로 분할해서 각각의 테이블로 만들어 두고 이들 테이블의 한 컬럼명을 원본 테이블의 한 컬럼명과 관계(Relation)를 만들어서(PK, FK, ...) 두 테이블이 서로 연결되게 한 기법이다. 테이블간에 관계가 있어서 관계형 데이터베이스라고 부른다. 이런 관계가 있어서 나중에 JOIN이 가능한 것이다.
MySQL의 중요한 기술지원은 유료이다. 이에 따라서 Open Source를 주장하던 MySQL 엔지니어가 새롭게 만든 RDBMS가 MariaDB이다. 그러므로 MariaDB는 오픈소스이고 무료이다.
먼저 Oracle 사이트에 들어가서 회원가입한 뒤 http://www.oracle.com/technology/soft ware/index.html에서 좌측의 POPULATE DOWNLOADS에서 Oracle Database 10g를 선택하고 Windows 10g(10.2.0.10)을 선택해서 다운받는다. 설치 머신의 사양이 정해져 있지만 대부분 현재의 머신에서는 문제없이 잘 설치된다.
그리고 시작>설정>제어판>시스템>고급 탭>우측하단의 설정>하단의 가상 메모리를 현재 사용하는 RAM의 2배로 해준다.
Oracle에서의 관리자 계정에는
▪ SYS : 데이터베이스 관리 작업을 수행하는 일반적인 관리자. Windows의 Administrator나 Linux의 root 권한과 유사
▪ SYSDBA : 데이터베이스의 구조, 설계 등을 관리하는 관리자
▪ SYSTEM : 데이터베이스를 위한 순수 데이터베이스 관리자로써 Oracle에서는 SYSTEM 계정으로 작업하는 것보다 개별 데이터베이스 관리자 계정을 생성해서 백업, 복원 등 데이터베이스 작업을 수행하는 것을 권장한다.
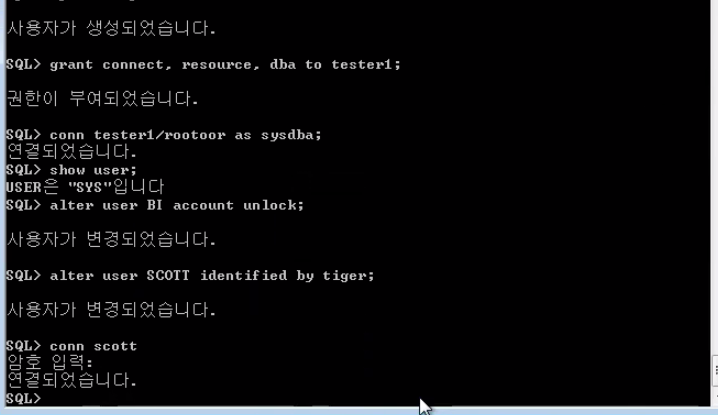
Oracle에서의 일반 사용자로는 BI(Business Intelligence), HR(Human Resources), OE(Order Entry), PM(Product Media), IX(Information Exchange), SH(Sales), 그리고 Scott 사용자들이 기본적으로 자신의 테이블들을 가지고 있다.
그리고 데이터베이스 아래에는 여러 테이블들이 저장되어 있는데 이 공간을 테이블스페이스라고 부른다. 중요한 것은 하나의 테이블이 하나의 파일로 저장되는 것이 아니라 하나의 테이블에 있는 정보가 테이블스페이스의 각 공간에 적절히 Oracle이 알아서 저장해두고 Data Dictionary에 그런 정보를 가지고 있어서 사용자는 알 수 없다(이런 것을 Transparent 하다고 한다).
삭제 시, Oracle Universal Installer에서 제품 설치 해제를 해주면 된다.


관리자 작업
SQL 규칙을 간단히 알아보면
∎ SQL 명령어는 대소문자를 구분하지 않지만 입력된 데이터에서는 대소문자를 엄격히 구별한다. ex) SELECT 나 select 모두 가능
∎ 예약어(SELECT, FROM, WHERE, ....)와 Data Dictionary(Oracle이 알아서 하는 객체 관리 데이터 저장 방식)에 저장된 항목이나 데이터이름 등은 주로 대문자로 쓴다.
∎ 문장의 끝에는 ; 을 찍는다(C로 생성한 모든 프로그램은 거의 그렇다).
∎ 정규표현식에서 *는 any의 의미이고, ?는 한 문자를 의미하지만 Oracle에서는 any 대신 %를 사용하고 ? 대신 를 사용한다.
∎ / ~ / 사이가 여러 줄 주석(Remark) 처리이다.
// 는 한 줄 주석처리인데 잘 먹히지 않아서 / ~ /로 처리하는 것이 좋다.
∎ 년도와 문자는 ' '로 묶고, 문자열은 “ ”로 묶는다.
∎ SELECT col1, col2, .. FROM tablename ; 은 SQL 쿼리문에서 거의 필수적으로 들어 있어야 한다.
SELECT 뒤에 쿼리하고자 하는 열명을 ,로 나열해주고
FROM ~ 뒤에 테이블_명이 나온다. 여기에 추가해서
WHERE ~ 뒤에 조건을 넣는다.
=>보통 SELECT ~ FROM ~ WHERE ~ ;식으로 해주는데 이 구문이 SQL의 기본 문형이다.
A 사용자로 데이터베이스에 연결한 뒤 기본적인 4가지 작업을 해주는데
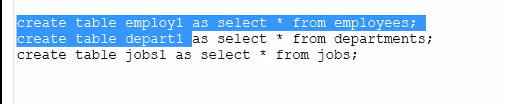
1) select from tabs; 해서 현재 A 사용자 소유의 테이블들을 보고
2) desc employees; 식으로 A 사용자 소유의 employees; 라는 테이블의 속성(열_명)을 보고
3) select from employees
where rownum <= 10; 식으로 해서 10개의 레코드만 먼저 살펴보고,
4) select * from ALL_CONSTRAINTS
where table_name='EMPLOYEES'; 식으로 해서 이 employees 테이블이 가지고 있는 제약조건을 본다.
=>원본 테이블을 복사한 뒤 작업하는 것도 좋은 습관이다.
hr 사용자가 소유한 employees 테이블의 제약조건을 보면 3개가 보이는데
EMP_MANAGER_FK ->EMP_EMP_ID_PK,
EMP_JOB_FK ->JOB_ID_PK, 그리고
EMP_DEPT_FK ->DEPT_ID_PK와 관계가 있는 것을 볼 수 있다.
하나의 테이블에는 대부분 하나(나 하나 이상)의 PK(unique과 not null 두 가지 조건이 있어야 함)가 존재하지만 하나의 테이블은 또 여러 테이블들과 관계(Relation)를 맺고 있기 때문에 여러 FK가 존재할 수 있다. 이 FK는 연관된 다른 테이블의 PK이어서 서로 관계를 맺고 있기 때문에 어느 한 테이블에서 함부로 해당 열을 삭제하거나 변경할 수 없는 제약(constraints)이 있다. 그래서 테이블 간에 항목(열)별로 관계가 있을 수 있어서 관계형 데이터베이스로 부른다.
=>제약조건에는 U(Unique), C(Check), R(Reference:Foreign key), P(Primary key)가 있어서 이들 항목의 데이터를 입력하거나 삭제하는 등의 작업을 함부로 수행할 수 없다.
->employees 테이블의 컬럼들
EMPLOYEEID, FIRST_NAME, LAST_NAME, EMAIL, PHONE_NUMBER, HIRE_DATE, JOB_ID, SALARY, COMMISSION_PCT, MANAGER_ID, DEPARTMENT_ID
->departments 테이블의 컬럼들
DEPARTMENT_ID, DEPARTMENT_NAME, MANAGER_ID, LOCATION_ID
->jobs 테이블의 컬럼들
JOB_ID, JOB_TITLE, MIN_SALARY, MAX_SALARY
=>emp_details_view 뷰 테이블의 컬럼들
EMPLOYEE_ID, JOB_ID, MANAGER_ID, DEPARTMENT_ID, LOCATION_ID, COUNTRY ID, FIRST_NAME, LAST_NAME, SALARY, COMMISSION_PCT, DEPARTMENT_NAME, JOB_TITLE, CITY, STATE_PROVINCE, COUNTRY_NAME, REGION_NAME이다.
몇 가지
1) SQL 쿼리문 실행 후에
commit; 하면 변경 내용이 영구 저장되는 것으로 Transaction 되었다고 말하고
/ 하면 메모리에 저장된 내용이 다시 불러와서 실행된다.
2) || 연산자는 문자를 이어준다. <= concat() 함수와 유사
select lastname || ' ' || first_name AS FULL_NAME(OR "FULL_NAME") from employees where rownum <= 10;
3) 항목명 뒤에 as 별칭(OR "별칭") 해서 열명을 임시로 보이게 할 수 있다.
4) SQL> 프로프트의 모양을 변경할 수도 있다. 시간이 표시되게 할 수도 있다.
set sqlprompt "USER>"; <=SQL을 나갔다가 다시 들어오면 없어진다.
set time on; <=set time off;
5) 전체 쿼리 시간을 보일 수도 있다. <=Dababase Tuning 시 요긴하게 참조된다.
set timing on; <=set timing off;
6) 열명의 길이 조절, 실행창의 크기 조절, 컬럼제목 미표시, 긴 출력 끊어서 표시, 출력결과 화면 미표시, 컬럼과 데이터가 *식으로 구분되게 표시,
컬럼 두 줄로 표시, 숫자에서 세자리마다 , 표시, 입력 내용 파일로 동시 저장시키기, ...
column city format A10; 식으로 하는데 A는 한 글자이다.
set linesize 150; <=default 80 가로창 크기 변경
set pagesize 50; <=default 14 50자리마다 컬럼 제목 표시됨
set pages 14; 페이지 크기 변경
set feedback 10; <=default 6 10자리마다 '~개의 행이 선택되었다'로 보임
set heading off; <=set heading on; 컬럼명 미표시
set pause on; 긴 출력을 페이지별로 끊어서 보임, 엔터하면 다음 줄로 넘어감
set underline '*'; 컬럼_명 아래에 ** 표시가 붙음
column last_name heading 'last|name'; 하고
select employee_id, last_name from employ1; 하면 된다.
column salary format 00,000; 하고
select last_name, salary from employ1; 하면 월급이 14000에서 14,000식으로 보인다.
7) 외부에서 *.sql 파일 불러들여서 사용하기
SQL>에서 '@ 파일저장_위치.sql' 하면 된다.
데이터베이스 가동은
conn sysdba as sysdba 해주고 rootoor 패스워드를 줘서 로그온하고
startup; 해서 가동시키고
shutdown immediate; 해서 중지시킬 수 있다.
결과를 order by salary 오름차순(ASC: default)/내림차순(DESC)를 써주면 정렬할 수 있다.
쿼리해서 salary가 동일한 결과가 보일 때 last_name으로 별로 정렬할 수도 있다.
이럴 때에는 order by salary DESC, last_name ASC식으로 구별하면 된다.
범위는 salary >= 10000 and salary <= 20000식일 때
=>salary between 10000 and 20000식으로 처리할 수 있다.
선책은 OR를 사용하는데
job_id가 FI_MGR이거나 FI_ACCOUNT인 직원을 보인다면
select last_name, salary, job_id from employees
where job_id = 'FI_MGR' or job_id = 'FI_ACCOUNT';식으로 하거나
~
~
where job_id IN('FI_MGR', 'FI_ACCOUNT');식으로 해주면 된다.
중복되는 내용을 빼고 쿼리할 때에는 distinct를 넣어서
select distinct job_id from employ1;식으로 하면 job_id 항목이 하나씩만 보이게 된다.
is null, is not null
null은 값이 지정되지 않았다는 의미로 0이 아니다.
like, not like
like는 전치사로써 '~와 같은 의미'이다. 여기서 정규표현식 %(*), _(?)를 사용하면 다양한 쿼리를 쉽게 할 수 있다.
*** 모든 프로그래밍 언어 중에서 SQL 프로그래밍 언어가 가장 사람이 쓰는 언어와 유사하다!!!
Escape 문자 \
%는 특수기호인데 데이터 내에 있는 특수기호 %를 쿼리하거나 퍼센트 %를 표시한다면 \ 뒤에 %기호를 쓰면 된다. 이런 \를 Escape 문자라고 해서 ESCAPE '\'를 써서 밝혀주면 된다. 홍길동은 '홍동'식으로 데이터가 있을 때 '홍*동'식으로 쿼리할 때 사용된다. 93.2%는 ‘93.2\%’ 해야 표시된다. ‘93.2%’ 하면 Wildcard가 되어 93.2....가 될 것이다.
일반적으로 정규표현식(Regular Expression)에서 는 모든(any), ?는 하나(one)의 의미인데, SQL 쿼리 구문에서는 %(any), _(one)의 의미가 된다.
*** 데이터가 어떠한 형태로 입력되어 있어도 원하는 형태로 변경해서 표시할 수 있다.
20000 =>$20,000
99/12/20 =>1999-12-20, 1999-Dec/20, ....
group by
GROUP BY는 쿼리할 대상을 그룹으로 묶을 때 사용된다. 그룹화 할 대상을 GROUP BY 절에 명시해서 그룹화한 뒤, 그 그룹에 SQL 집합함수를 사용해서 다양한 결과를 얻을 수 있다. GROUP BY는 보통 집합함수 AVG(), SUM(), MIN(), MAX() 등과 함께 사용된다. 일단 그룹화 한 경우에는 그룹행 함수와 group by에 지정된 컬럼만 사용가능하다.
쿼리에서
▪ '홍길동' 사원의 월급만 구한다면,
=>한 사원의 월급을 대상으로 작업하므로 단일 쿼리 salary를 사용하지만
▪ '전체사원'의 월급의 합/평균을 구한다면,
=>여러 명의 월급을 대상으로 작업하므로 그룹 쿼리로 sum(salary)과 같은 그룹행 함수를 사용해야 한다.
그룹으로 묶을 때에는 group by ~를 사용한다.
부서별로 평균급여를 구해서 내림차순으로 보인다면
select distinct department_id, trunc(avg(salary),0) "SAL_BY_DEPT" from employ1
group by department_id
order by SAL_BY_DEPT DESC; 하면 된다.
=>group by ~ 에 조건을 건다면 having ~으로 해주면 된다. where ~를 쓰지 않고, 반드시 group by ~ 다음에 having ~이 와야 한다.
부서별로 평균급여가 10000불 이상인 부서의 평균급여를 내림차순으로 보인다면
select distinct department_id, trunc(avg(salary),0) "SAL_BY_DEPT" from employ1
group by department_id
having trunc(avg(salary), 0) >= 10000
order by SAL_BY_DEPT DESC; 하면 된다.
인원을 구할 때에는 count() 함수를 사용한다. () 속에는 employee_id나 *를 쓰면 된다.
부서별로 평균급여를 구해서 내림차순으로 보인다면
select distinct department_id, trunc(avg(salary),0) "SAL_BY_DEPT" from employ1
group by department_id
order by SAL_BY_DEPT DESC; 하면 된다.
