2024-03-27
Nano Server
- Windows Server 2016에서 새로 소개된 Nano Server는 Windows 2008 Server의 Core Server보다 훨신 작은 용량으로 설치되므로 클라우드 환경에서 OS 재설치, 재시작, 이미지 복제 등을 빠르게 수행할 수 있게 한다. Windows Server 2016을 전체 GUI, Server Core, 혹은 Nano Server로 설치할 수 있다. 전체 GUI는 Server Core 위에서 작동되므로 서로 관련이 매우 깊은데 Linux의 CLI 런 레벨3에서 GUI 런 레벨5가 실행되는 것과 같다. 하지만 Nano Server는 독립적으로 작동되므로 전체 GUI와 무관하고 Windows Server 2016 위에서 작동되며 원격으로 접속해서 서버를 관리/운영하는 방식으로 사용된다. Server Core는 독립된 컴퓨터에 설치되고 운영되는 방식이지만 Nano Server는 사설 Cloud나 Data Center에 최적화된 운영체제이다.
=>Linux에서 주로 사용하는 Docker와 유사한 개념으로 보면 된다.
Nano Server 특징
∎ Hyper-V 가상 컴퓨터에서 컴퓨팅(계산)용으로 사용되거나,
∎ 파일 서버의 저장소나 저장소 관리로 사용되거나,
∎ DNS 서버나 IIS 웹 서버로 사용될 수도 있다.
∎ 그리고 가상 컴퓨터에 응용 프로그램을 실행할 때 주로 사용된다.
∎ 화면에 로그온이 없어서 원격 접속만 가능하고,
∎ 64비트 응용 프로그램이나 도구만 지원하고,
∎ Active Directory의 DC로 작동되지 못하고,
∎ GPO를 적용시킬 수도 없다.
∎ 또한 Proxy Server로도 사용할 수 없고,
∎ Power Shell을 사용하지 못한다. PowerShell은 이보다 용량이 조금 큰 Server Core에서 사용될 수 있다.
∎ 가벼운 용량의 서버는 Nano Server로 만들어서 클라우드에 올리면 좋다.
Power Shell 명령어로 설치


로그 파일과 vhd가 생성 된것을 볼 수 있었다.

vhd==1세대
vhdx==2세대
이후 Hyper-V에서 기존 하드 디스크 가져오기를 통해서 설치를 빠르게 진행하였다.
ID-PW 지정 후, Networking 설정으로 들어간다.
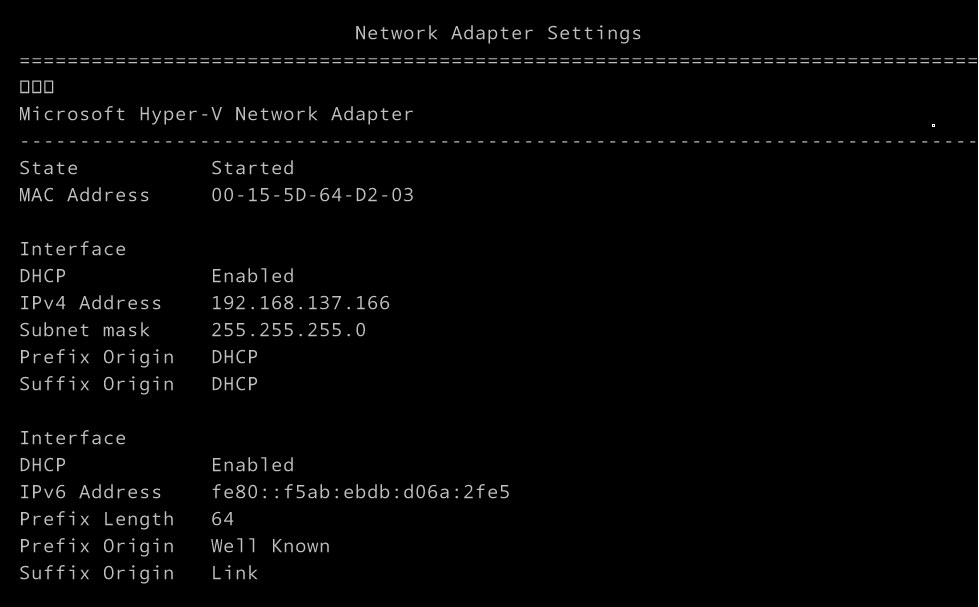
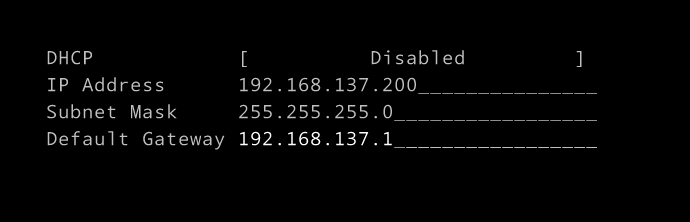
IPv4 설정을 바꿔본다.
Default Gateway는 Hyper-V(스위치)의 주소이다.

(NanoSer ID PW)
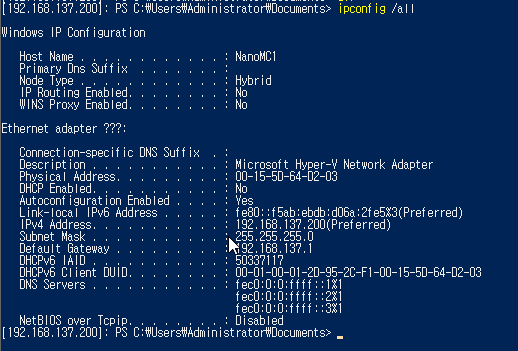
(Power-shell을 통해 NanoServer 접속)
==> NanoServer는 작은 용량으로 이루어진 OS이기 떄문에 작업 환경이 매우 제한적이다. 그렇기 떄문에 외부에서 Power-Shell 과 같은 워크스테이션을 통해서 작업한다.
Hyper-V는 스위치 역할을 한다.
Oracle
Oracle Database
데이터베이스를 사용하는 이유는 원시 데이터인 '자료(Raw Material)'와 그 외 컴퓨팅 및 비즈니스 인텔리전스 툴을 기반으로 수집한 '데이터 저장소(Data Warehouse)'를 충분히 활용해서 '가공 작업(Data Mining)' 통해서 비즈니스를 더 효율적으로 운영하고, 더 나은 의사결정을 내리며, 더 민첩하고 확장 가능한 기업으로의 발전을 도모하기 위해서이다.
데이터베이스란 일반적으로 컴퓨터 시스템에 디지털(전자) 방식으로 저장된 구조화된 정보 또는 데이터의 체계적인 집합(data_name, data_type, data_size, ...=>스키마(schema)로 부름)을 의미한다. 데이터베이스는 보통 데이터베이스 관리시스템(DBMS:DB Management System)이라는 소프트웨어에 의해 제어되는데 데이터와 DBMS는 연관된 어플리케이션들과 함께 '데이터베이스 시스템'으로 불리기도 하지만 짧게 '데이터베이스'라고 통칭한다.
유명한 DBMS로는 Oracle, MySQL/MariaDB, MS SQL, PostgreSQL, LiteSQL, DB2, Informix, Sybase, ..... 등이 있다.
=>스키마가 지정되지 않은 데이터베이스('NoShema(NoSQL)')로는 MongoDB, Cassandra, ... 등이 있다. 이들은 데이터를 <key:value> 형식(이름:데이터)으로 저장해서, <01:0001>, <03:1234>식이다. <= JSON format, Python에서는 Dictionary, xml, 최근 웹에서는 주로 사용되는 yaml 등이 이런 데이터 타입을 사용한다.
오늘날 운용되는 가장 공통적인 데이터베이스(database) 내의 데이터는 프로세싱과 데이터 쿼리 작업을 더 효율적으로 실행하기 위해서 일반적으로 일련의 테이블(table) 안에 행(row)과 열(column)로 모델링된다. 행과 열이 만나는 곳에 값(field)이 들어 있다. 하나의 행에 여러 열 값이 들어 있는 것을 레코드(record)라고 한다. 이런 구조로 원하는 데이터를 더 쉽게 액세스, 관리, 수정, 업데이트, 제어, 그리고 체계화할 수 있다.
=>대부분의 데이터베이스는 데이터 작성 및 쿼리 작업에 '구조화 질의 언어'(SQL:Structured Query Language)를 사용한다.
구조화 질의 언어(SQL)
SQL은 데이터를 쿼리(query), 조작(manipulate), 정의(define)하고 액세스 제어(access control)를 제공할 목적으로 거의 모든 관계형 데이터베이스(Relative DataBase)에서 사용되는 C, C++, Python, Java와 같은 프로그래밍 언어로써 SQL은 1970년대 IBM에서 가장 먼저 개발되었고, 나중에 데이터베이스계의 절대 강자 Oracle이 주요 기업으로서 참여했었다. 그 후 ANSI SQL 표준이 만들어 졌고 SQL은 IBM, Oracle, Microsoft 등의 기업들에 의해 더욱 확장되어 나아갔다. SQL이 여전히 광범위하게 사용되고 있긴 하지만 데이터 쿼리에 대한 새로운 기법과 프로그래밍 언어 등이 출현되고 있는 추세이다.
=>Scala, Spark(분산파일 시스템에서의 빅 데이터 쿼리), PySpark, ...그리고 AWS, Azure, GCP 등 상용 클라우드에서는 자체적으로 데이터베이스를 처리하는 프로그래밍 언어가 따로 있다.
SQL은 가장 진보된 인간의 언어와 유사한 프로그래밍 언어로써 프로그래밍에 특화된 SQL을 PL(Programming Language)/SQL이라고 한다.
데이터베이스의 진화
데이터베이스는 1960년대 초반 처음 도입된 이래로 계속해서 극적인 진화를 거듭해 왔다. 계층형 데이터베이스(트리 형태의 모델에 의존하며 일 대 다수의 관계만을 허용)와 네트워크 데이터베이스(다수의 관계를 허용하는 더 유연한 모델) 등의 탐색형 데이터베이스(Navigational Database)는 데이터 저장 및 조작을 위해 사용되던 최초의 시스템이었다. 이러한 초기 시스템의 경우 간편하기는 하지만 유연성이 부족해서 1980년대에는 관계형 데이터베이스가 주로 사용되었고, 1990년대 들어서는 객체 지향형 데이터베이스가 그 뒤를 이었다. 이후로는 인터넷의 성장과 함께 비정형 데이터에 대한 더 빠른 속도와 프로세싱을 요구하는 경향에 맞추어 NoSQL 데이터베이스가 주목받기 시작했다.
최근에는 데이터 수집, 저장, 관리, 활용 방식과 관련해서 가상화 클라우드를 이용하는 클라우드 데이터베이스와 AI와 M/L을 이용하는 자율구동 데이터베이스가 새로운 영역을 개척하고 있다.
데이터베이스와 엑셀/스프레드시트의 차이
데이터베이스와 전통적으로 예전부터 사용해오는 스프레드시트(예: Microsoft Excel)는 모두 정보를 편리하게 저장할 수 있는 방식이지만 주요 차이점은 데이터 저장 및 조작 방법, 그리고 데이터에 액세스할 수 있는 사용자, 데이터 저장 가능 용량 면에서 차이가 있다.
스프레드시트나 엑셀은 본래 단일 사용자를 위해 설계되었으며, 그 특성 또한 이러한 점을 반영하고 있어서 엄청나게 복잡한 데이터 조작을 다수 실행할 필요가 없는 단일 사용자 또는 적은 수의 사용자가 활용하기에 좋지만, 데이터베이스는 훨씬 더 많은 방대한 양의 조직화된 정보를 보관하도록 설계되었기 때문에 다수의 사용자가 매우 복잡한 로직과 프로그래밍적 기법 사용해서 동시에 신속하고 안전한 방식으로 데이터에 액세스해서 쿼리를 실행할 수 있다.
=>최근에는 엑셀 등에서 고급 함수를 사용해서 데이터를 처리하는 대신 Python 프로그래밍으로 더욱 세련되고 정밀하게 데이터를 처리할 수 있다.
데이터베이스의 종류
데이터베이스는 다양한 유형이 존재하는데 특정 조직에 가장 적합한 데이터베이스는 해당 조직이 데이터를 어떻게 활용할 것인지에 따라 다르다고 말할 수 있다.
▪ 관계형 데이터베이스
관계형 데이터베이스는 그 활용이 1980년대에 가장 지배적이었는데 관계형 데이터베이스 내 항목들은 행과 열을 가진 일련의 테이블로 체계화된다. 관계형 데이터베이스 기술은 구조화된 정보에 액세스할 수 있는 가장 효율적이고 유연한 방식을 제공한다. 최근의 데이터베이스는 거의 관계형 데이터베이스이다.
▪ 객체 지향형 데이터베이스
객체 지향형 데이터베이스 내 정보는 객체 형태로 표현되며 이를 객체 지향형 프로그래밍이라 부른다.
▪ 분산 데이터베이스 <- Hadoop
분산 데이터베이스는 서로 다른 곳에 존재하는 두 개 이상의 파일로 이루어져 있다. 동일한 물리적 장소에 분산되어 위치해 있거나 서로 다른 네트워크에 분산되어 있는 다수의 컴퓨터(노드)에 보관될 수 있다.
▪ 데이터 웨어하우스
데이터 중앙 보관소인 데이터 웨어하우스는 신속한 쿼리 및 분석을 위해 특별히 설계된 데이터베이스 유형 중 하나이다.
▪ NoSQL 데이터베이스
NoSQL 또는 비관계형 데이터베이스는 데이터베이스에 입력되는 모든 데이터의 구성방식을 정의해야 하는(스키마) 정형화 데이터인 관계형 데이터베이스와 다르게, 비정형 데이터와 반정형 데이터가 저장 및 조작될 수 있는 데이터베이스이다. NoSQL 데이터베이스는 웹 어플리케이션이 더 흔해지고 더 복잡해짐에 따라 활용도가 높아지기 시작했다.
▪ 그래프 데이터베이스
그래프 데이터베이스는 개체, 그리고 개체 간 관계 측면에서 데이터를 저장한다. 데이터 보관의 Node, 노드 간 관계와 방향성 표현의 Edge, 그리고 Key-Value의 Property로 구성되는데 SNS, NoSQL, 네트워크 관리 등에서 사용되며 Neo4j, Neptune 데이터베이스 등이 있다.
▪ OLTP(OnLine Transactional Processing)과 OLAP(OnLine Analytical Processing) 데이터베이스
OLTP 데이터베이스는 빠른 속도의 분석용 데이터베이스로서, 다수의 사용자에 의해 수행되는 다량의 트랜잭션을 위해서 설계되었다. 그리고 분석을 위주로 하는 OLAP도 있다.
=>이들은 오늘날 활용되는 수십 개의 데이터베이스 유형 중 일부에 불과하고, 이외에 덜 흔하게 사용되는 데이터베이스들은 특정 과학, 재무 또는 그 외 기능에 대해 특화되어 있다. 다양한 데이터베이스 유형에 더해서 클라우드나 자동화와 같은 기술 개발 접근방식의 변화 및 극적인 발전으로 인해서 데이터베이스는 전혀 새로운 방향으로 진화를 거듭하고 있다. 최근 등장한 데이터베이스로는
▪ 오픈 소스 데이터베이스
오픈 소스 데이터베이스 시스템은 소스 코드가 오픈 소스인 데이터베이스로 SQL 또는 NoSQL 데이터베이스가 포함될 수 있다.
▪ 클라우드 데이터베이스
클라우드 데이터베이스는 프라이빗, 퍼블릭 또는 하이브리드 클라우드 컴퓨팅 플랫폼에 존재하는 정형/비정형 데이터의 집합으로 클라우드 데이터베이스 모델 유형에는 전통 방식의 데이터베이스와 서비스형 데이터베이스(DBaaS:Database as a Service)가 있다. DBaaS의 경우, 서비스 제공업체가 관리 업무와 유지보수 서비스를 제공하는데 Amazon Web Services (simpleDB, DynamoDB), Enterprise DB(postgreSQL), Garantia Data(Redis, NoSQL), Google cloud SQL(Google), Azure DataSync(MS), MongoLab(MongnoDB), HANA(SAP), stormDB, Xeround, cloudDB for MySQL(MS SQL), SkySQL 등이 있다.
▪ 멀티모델 데이터베이스
멀티모델 데이터베이스는 서로 다른 유형의 데이터베이스 모델을 단일 통합 백엔드에 결합시킨 것으로 다양한 데이터 유형을 수용할 수 있다.
▪ 문서/JSON 데이터베이스
문서 기반 정보를 저장하고 검색하며 관리하기 위한 목적으로 설계된 문서 데이터베이스는 행과 열이 아닌 JSON 형식으로 데이터를 저장하는 최신 방식으로써 MongoDB가 대표적이다. JSON의 데이터를 <key:value> 포맷으로 저장한다. Python에서 Dictionary 표현과 같다.
▪ 자율구동 데이터베이스
가장 최근에 등장한 획기적인 데이터베이스 유형인 자율구동 데이터베이스('자율운영 데이터베이스'라고도 불림)는 클라우드 기반 데이터베이스로써 AI와 ML을 사용해서 데이터베이스의 튜닝, 보안, 백업, 업데이트 및 그 외 본래 데이터베이스 관리자가 수행하던 일상적인 관리 업무를 자동으로 처리하게 한 데이터베이스이다.
데이터베이스 관리 시스템(DBMS)
데이터베이스는 일반적으로 데이터베이스 관리시스템으로 알려진 포괄적인 데이터베이스 소프트웨어 프로그램 DBMS를 사용하는데 DBMS는 데이터베이스와 최종 사용자 또는 프로그램 사이의 인터페이스로써 사용자가 저장된 데이터 정보를 체계화, 최적화, 검색, 업데이트 및 관리를 적절히 수행하게 해준다. 또한 데이터베이스에 대한 관리 및 제어를 가능하게 해서 성능 모니터링, 튜닝, 백업, 복구 등과 같은 다양한 관리 작업도 지원한다.
1) MySQL(MariaDB), Oracle, 그리고 (MS) SQL 데이터베이스
▪ MySQL은 SQL 기반의 오픈 소스(무료) 관계형 데이터베이스 관리 시스템으로써 웹 어플리케이션에서 활용될 수 있도록 설계 및 최적화되었으며 어떤 플랫폼에서든 구동 가능하다. 인터넷 발전과 함께 서로 다른 새로운 요구 사항들이 등장하고 있는 오즘 오픈소스인 MySQL은 웹 개발자들과 웹 기반 어플리케이션에서의 활용을 위해서 촉망받는 플랫폼으로 자리 잡고 있다. 그뿐만 아니라 수백만 건의 쿼리와 수천만 건의 트랜잭션을 처리할 수 있도록 설계되어 있어서 다수의 송금 내역을 관리할 필요가 있는 이커머스 기업들이 가장 선호하는 플랫폼이기도 한데 온디맨드에서의 유연성은 MySQL이 제공하는 주요 기능이다.
MySQL은 Airbnb, Uber, LinkedIn, Facebook, Twitter, YouTube 등 전 세계 인기 웹 사이트 및 웹 기반 어플리케이션에서 활용하는 DBMS이다. 현재 MySQL도 Oracle이 소유하고 있기 때문에 오픈 소스를 지향하는 MySQL 기술자들이 새롭게 선보인 데이터베이스가 MariaDB이다.
▪ Oracle은 Oracle 사에서 만든 데이터베이스로써 가장 널리 사용되고 있다.
▪ MS SQL은 그냥 SQL로도 불리는데 마이크로소프트에서 만든 데이터베이스이다.
2) 데이터베이스 관련 도전 과제
오늘날 대형 엔터프라이즈 데이터베이스는 종종 매우 복잡한 쿼리를 지원하며 이러한 쿼리에 대해 거의 즉각적인 대응을 제공할 것으로 기대된다. 그 결과 데이터베이스 관리자들은 성능 개선을 도울 다양한 방법들을 마련하도록 계속해서 요구받고 있다.
최근의 데이터베이스 관리자들이 직면한 공통적인 도전 과제를 일부 정리하면 다음과 같다.
a) 상당 수준으로 증가한 데이터 양 처리
센서나 커넥티드 장치 및 그 외 다수의 데이터 소스로부터 나오는 데이터가 폭발적 수준에 이르기 때문에 데이터베이스 관리자들은 자사 데이터를 효율적으로 관리 및 체계화하기 위해서 사투를 벌이고 있다.
b) 데이터 보안의 보장
최근 데이터 침해 사건이 세계 도처에서 일어나고 있으며, 해커들은 점점 더 독창적인 방식을 구사하고 있다. 따라서 데이터 보안을 유지하는 동시에 사용자들이 간편하게 액세스할 수 있도록 하는 일은 그 어느 때보다 중요해지고 있다.
c) 데이터에 대한 시대의 요구에 부응
빠르게 변화하는 오늘날의 비즈니스 환경에서 기업들은 시의적절한 의사결정을 내리고 새로운 기회를 적극 활용할 수 있도록 데이터에 대한 실시간 액세스를 필요로 하고 있기 때문에 신속하고 편리한 접근성이 필요하다.
d) 데이터베이스와 인프라 관리 및 유지
데이터베이스 관리자들은 데이터베이스에 문제가 발생하지 않는지 계속해서 지켜보고 예방 목적의 유지관리를 수행하는 동시에 소프트 업그레이드와 패치를 적용해 주어야만 한다. 데이터베이스는 점점 더 복잡해지고 데이터의 양이 점점 더 증가함에 따라, 기업들은 데이터베이스 모니터링 및 튜닝을 위해서 추가로 인력을 고용해야 하는 상황에 직면해 있다.
e) 확장성과 관련된 한계 제거
기업들은 생존을 위해 성장을 거듭해야 하며, 데이터 관리 역시 발전을 거듭해 나가야 하지만 데이터베이스 관리자들의 경우, 특히 온-프레미스(On-Premise) 데이터베이스와 관련해서는 기업이 얼마나 많은 역량을 요구할지 예측하기가 매우 어려운 실정이다.
=>이 모든 도전과제를 해결하는 일은 시간 소모적이 될 수 있으며, 데이터베이스 관리자들이 더 전략적인 기능을 수행하는 것을 방해할 수 있다.
데이터베이스 일반
여기서 데이터베이스 일반적 특성을 살펴본다.
1) 테이블의 구조
테이블 구조를 알기 위해서는 Schema를 알아야 하는데 스키마는 논리적인 데이터 구조나 스키마 객체의 모음이다. 스키마는 데이터베이스 사용자가 지정하면 해당 사용자와 같은 이름으로 저장된다. 각 사용자는 하나의 스키마를 가지고 있고, 스키마 객체는 SQL로 생성되고 조작된다.
테이블은 데이터베이스에 저장되는데 이 공간을 Tablespace로 부른다. 각 디스크에 데이터베이스가 저장되고, 데이터베이스 안에 각각의 스키마로 지정된 테이블들이 저장되게 되는데 하나의 테이블이 한 곳에 저장되는 것이 아니라 여러 곳에 분산되어 저장된다!! 이는 문제가 있을 때 오류를 복구하기 위해서 이다.
=>필드, 열, 컬럼, 레코드 로 구성된다.
2) SQL 명령어의 종류
다음처럼 SQL을 기능적인 면에서 분류하기도 한다.
a. DDL(Data Definition Language : 데이터 정의어)
데이터베이스 관리자나 응용 프로그래머가 데이터베이스의 논리적 구조를 정의하기 위한 언어로서 이런 정보는 데이터 사전(Data Dictionary)에 저장 된다.
=>create : 테이블 생성, alter : 테이블 구조 변경, drop : 데이터베이스나 테이블 삭제, rename : 테이블 이름 변경, truncate : 테이블의 모든 내용 제거(테이블은 남김)가 있다.
b. DML(Data Manipulation Language : 데이터 조작어)
데이터베이스에 저장된 데이터를 조작하기 위해 사용하는 언어로서 데이터 검색, 추가, 삭제, 갱신 작업을 수행한다.
=>insert : 데이터 삽입, delete : 데이터 삭제, update : 데이터 수정, select : 테이블에 저장 된 데이터 조회, 대부분 SQL 문에는 이 select가 들어 있어야 한다.
c. DCL(Data Control Language : 데이터 제어어)
데이터에 대한 접근 권한 부여 등의 데이터베이스 시스템의 트랜잭션(TCL)을 관리하기 위한 목적으로 사용된다.
=>grant : 사용자에게 특정 권한 부여(~ to), revoke : 사용자로부터 특정 권한 제거(~ from)
d. TCL(Transaction Control Language : 트랜젝션 제어어)
DML에 의해 변경 된 내용을 완성 및 저장이나 취소한다.
=>commit(OR /) : 변경 된 내용을 영구적 저장, rollback : 변경되기 전 상태로 돌림, savepoint : 특정 위치까지 영구 저장 혹은 이전 상태로 돌릴 수 있도록 트랜잭션 중에 복원을 위해서 임시 저장 지점을 만듦(redo, undo).
=>SQL 쿼리를 실행하면 결과가 임시로 메모리 상에 저장되기 때문에 일단의 작업 완료나 취소가 가능하다.
∎ Oracle 10g, 11g(grid), 12c, 19c, 21c, 23c(cloud) 종류
10g : 그리드 컴퓨팅, 분산된 컴퓨팅 자원을 초고속 네트워크로 모아 아주 큰 서버같이 보이도록 하여 성능을 일정 수준 이상으로 극대화 하는 개념, 기업 내의 중소 형 서버를 연결시켜 유휴 자원을 활용, 하나의 커다란 서버로 활용할 수 있기 때문에 무리하게 서버를 구입할 필요가 없어짐, Provisioning(프로비저닝), Load Balancing(부하관리), Automation(자동화) 지원
11g : 10g와 마찬가지로 그리드 컴퓨팅 기반, DB관리자의 편의 기능이 이전 버전보다 훨씬 더 많이 지원, 많은 기능 보강, 설치 관련 기능, 저장 영역 기능, 대용 량 데이터 처리기능, 자동 SQL튜닝 기능 등 기존 버전보다 향상됨.
12c : 이전 버전과의 가장 큰 차이점은 클라우드 지원, 12c부터 오라클은 하나의 플랫폼을 여러 사용자가 사용하는 오라클 멀티테넌트(Oracle Multitenant) 아 키텍처를 추가함, 클라우드 컴퓨팅을 통해 아키텍처 컨테이너 DB라는 가상의 DB가 존재하고, 그 안에서 많은 DB를 관리하게 됨. In-Database MapReduce(인-데이터베이스 맵리듀스)기능을 강화, 빅데이터에 대한 효과적인 분석 가능해짐.
19c : 자동 인덱싱, 활성 데이터가드 DML 리디렉션, 하이브리드 파티션 테이블, JSON 지원 강화, 쿼리 격리를 통한 데이터 일관성 유지와 성능 개선
21c : 블록체인 지원으로 오라클 암호 보안 데이터 관리를 각 행을 암호화해서 연결시킴으로 불변성 유지, 데이터 변조 방지, JSON 포맷 저장, JavaScript 실행 지원, Auto ML으로 머신러닝 기법 도입
=>데이터베이스는 사용자에게 Performance(성능), Stability(안정성), Availability(가용성)을 지원함
