0.들어가기 전에
이미지를 다운 받는 사이트
이곳에서, downloads로 가서 zip을 다운받으면 된다.
1.DCGan
Convolutional Layer 를 이용한 GAN 이미지 생성 모델이다.
논문의 링크이다.
파이토치의 토튜리얼은 아래에 있다.
https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html
2.import
관련 내용을 import 한다.
import os
import random
import time
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torchvision import datasets, transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt3.Random Seed 설정
파이토치는 Random Seed를 이미 설정을 해 두고 코드를 짠다.
코드에서 사용하는 랜덤값을 생성하는 모든 lib에 설정한다는 점을 숙지하자.
# Random Seed 설정--->코드에서 사용하는 랜덤값을 생성하는 모든 lib에 설정하다.
seed_value = 0
random.seed(seed_value)
torch.manual_seed(seed_value)
np.random.seed(seed_value)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(device)4.하이퍼파라미터 변수 정의

아래는 구체적인 코드이다. 코드에서, 각 파라미터를 설명하는 코드를 잘 보도록 하자.
# 하이퍼파라미터 변수 설정
dataroot = r"datasets" #train dataset을 저장할 디렉토리
os.makedirs(dataroot,exist_ok=True)
#cpu_count() : cpu로 할 수 있는 병렬처리의 최대 개수이다.
workers = os.cpu_count() #dataloader 사용. data load시 사용할 thread의 개수이다.
batch_size = 128
image_size = 64 # 학습 이미지의 h,w 크기. (64*64를 학습시킨다.)
nc = 3 #입력 이미지의 channel 수이다.
nz = 100 # Latent vector의 크기. ->Generator의 입력 데이터.(표준분포를 따르는 random 값들로 구성한다.)
ngf = 64 # G(enerative) 출력 F(eature map) 개수에 사용할 값.
ndf = 64 # D(iscriminator-판별자) 출력 F(eature map) 개수에 사용할 값.
num_epochs = 10
lr = 0.0002
beta1 = 0.5 #Adam 옵티마이저의 하이퍼파라미터값.
ngpu = 1 if device == 'cuda' else 05.Dataset, DataLoader 생성
이미지를 다운 받은 것을 압축을 푼다.
참고로, 이미지의 개수가 많기 때문에 압축을 푸는데 시간이 많이 걸린다.
(이미지가 22만개로 굉장히 많다.)
from zipfile import ZipFile
with ZipFile(os.path.join(dataroot, "img_align_celeba.zip")) as zfile:
zfile.extractall(os.path.join(dataroot))그런 다음, Dataset, DataLoader을 생성한다.
그 전에, 파일을 카피하거나 옮기는 shutil 라이브러리를 통해 폴더를 바꾸자.
import shutil ##파일/디렉토리 카피, 복사 옮기기, 이동 함수 제공.
os.makedirs('datasets/celeba/',exist_ok = True)
shutil.move("datasets/img_align_celeba/","datasets/celeba")
# Dataset, DataLoader 생성
transform = transforms.Compose([
transforms.Resize(image_size), #Resize((h,w)), Resize(정수):h/w 중 짧은 쪽의 크기를 지정. 긴쪽은 원본 이미지 종횡비에 맞춰 resize한다.
transforms.CenterCrop(image_size), #CenterCrop(정수) #정수 x 정수
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) # -1.0에서 1.0 사이로 픽셀 값이 만들어진다.
dataset = datasets.ImageFolder(root="datasets/celeba", transform=transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=workers)자, 그러면 확인을 해보자.
real_batch = next(iter(dataloader))
plt.figure(figsize=(10, 10))
plt.axis("off")
plt.title("Training Images")
plt.imshow(vutils.make_grid(real_batch[0][:64] #0:X , [:64] 128장 중 앞 64장
, padding=2
, normalize=True).permute(1, 2, 0))
plt.show()아래는 사진들이다.

6.모델을 구성하는 Layer의 파라미터 초기화
DCGAN 논문에서 저자에서 모든 모델 가중치를 평균=0, 표준편차=0.02의 정규 분포에서
무작위로 초기화 하도록 한다.
weights_init() 함수는 Random값으로 초기화된 모델을 입력으로 받아 위 기준을 충족하도록 모든
convolution, convolution-transpose 및 Batch Normalization 레이어의 파라미터들을 다시 초기화
한다.
이 함수는 조금 어렵다. 복습 시간에 잘 보도록 하자.
## 논문에 따라 레이어의 파라미터들을 초기화하는 함수.
# nn.init.normal_(텐서, 평균, 표준편차): 텐서를 평균, 표준편차를 따르는 정규분포의 난수들로 채운다.
# nn.init.constant_(텐서, value): 텐서를 value:float 으로 채운다.
def weights_init(m:"Layer"):
classname = m.__class__.__name__ #레이어객체의 클래스이름
if classname.find('Conv') != -1: #Convolution Layer의 경우
nn.init.normal_(m.weight.data, 0.0, 0.02) # weight을 평균 0, 표준편차 0.02를 따르는 random값으로 변경한다.
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
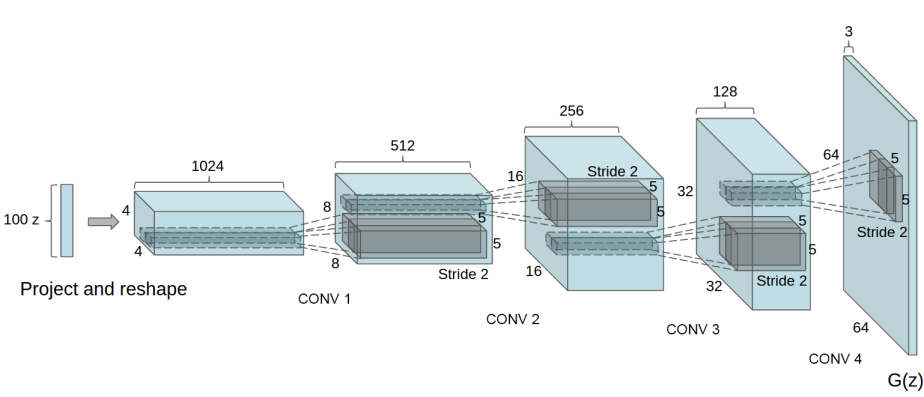
nn.init.constant_(m.bias.data, 0)7.Generator
Generator는 Latent space Vector(잠재공간벡터) 를 입력 받아 training image와 동일한 형태(분포)의 이미지를 생성 한다.
한마디로 진짜같은 가짜를 생성한다는 것이다.
이미지를 통해 이해하면 좋다.
8.Transpose Convolution Layer 출력 size 공식
아래의 약자와 식을 잘 보자.
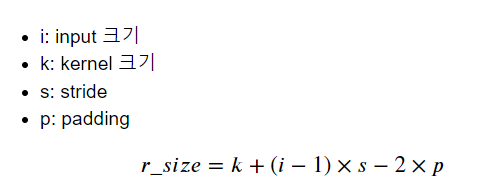
활용 예시이다.
잘 보면, 원본 데이터의 사이즈와 변경 후 사이즈가 다른 것을 잘 보도록 하자.
i_data = torch.ones((1,1,64,64)) #견본 데이터를 정의한다.layer = nn.ConvTranspose2d(in_channels=1,out_channels=3,kernel_size=4,stride=2,padding=1)
i_data = torch.ones((1,1,64,64)) #견본 데이터를 정의한다.
result = layer(i_data)
print(result.shape) #사이즈가 변경이 되는 것을 볼 수 있다.
#사이즈의 변경은 layer의 변수들을 변경하는 것이다.
#특히, stride나 padding의 값에 따라 result의 shape이 바뀌는 것을 주목하자.
출력 결과
torch.Size([1, 3, 128, 128])
9.generator 생성
nn.Sequential을 생성했고, 그 다음에 여러 겹으로 쌓아 놨다고 볼 수 있다.
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
#input: (100,1,1)->(64*8*8)
nn.ConvTranspose2d(in_channels=nz,
out_channels=ngf * 8,
kernel_size=4,
stride=1,
padding=0,
bias=False),
nn.BatchNorm2d(ngf * 8), #앞의 out_channel이 input으로!
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False), #점점 출력 channel 수를 좁혀나간다.
nn.Tanh()
)
def forward(self, input):
return self.main(input)그런 다음, Generator를 생성하고 weights_init 함수를 적용한다.
# Generator 생성
netG = Generator(ngpu).to(device)
netG.apply(weights_init)
print(netG)이렇게 생성을 하면, 다음과 같이 세부 내용이 나온다.
Generator(
(main): Sequential(
(0): ConvTranspose2d(100, 512, kernel_size=(4, 4), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(13): Tanh()
)
)10.Discriminator
일반적은 layer인데, '진짜인지 가짜인지' 같은 이진 분류를 처리해주는 놈이다.

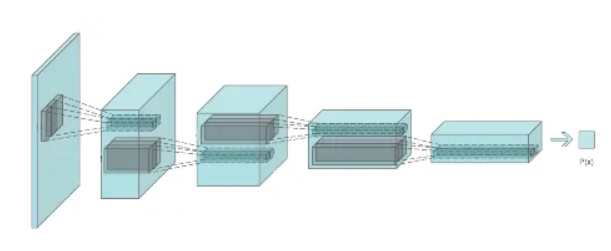
솔직히, 전체적인 코드는 generator와 상관이 없다.
그러나, 마지막에 Sigmoid 함수가 들어갔다는 점만이 다르다.
이는 Discriminator가 이진분류 문제를 해결하는 것이기 때문이다.
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
#이런 과정들을 거쳐서 결국에는 출력값을 1개로 만든다.
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)위의 과정을 마쳤다면, 본격적으로 Discriminator을 생성하자.
# Discriminator 생성
netD = Discriminator(ngpu).to(device)
#모델.apply(함수) => 함수에 모델의 레이어들을 전달. =>레이어 파라미터 값을 함수를 이용해 초기화할 때 사용한다.
netD.apply(weights_init)
print(netD)아래는 netD에 대한 결과를 출력한 것이다.
Discriminator(
(main): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): LeakyReLU(negative_slope=0.2, inplace=True)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)
(12): Sigmoid()
)
)12.학습
우선 loss 함수와 Optimizers를 보도록 하자.
GAN 모델의 최종 출력은 Real image인지 여부이므로 이진분류 문제이다.
Loss 함수는 Binary Cross Entropy loss (BCELoss) 함수를 사용한다.
optimizer를 생성할 코드이다.
criterion = nn.BCELoss()
#generator/판별자 모두 판별자의 오차를 바탕으로 업데이트를 한다. 그래서 BCELoss를 쓴다.
#학습하는 도중 중간중간 생성자가 생성한 이미지를 지정한다. 그때 사용할 입력 데이터(latent vector)
#표준정규분포를 따르는 난수로 구성. shape: (개수,100(nz),1,1)
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
real_label = 1. #진짜 이미지(train data)의 label
fake_label = 0. #가짜 이미지(생성자가 만든 데이터)의 label
#판별자를 최적화할 옵티마이저.
optimizerD = torch.optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
###생성자(generator)를 최적화할 옵티마이저.
optimizerG = torch.optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))자, 여기서 중요한 것은,
가짜인 것은 가짜라고 잘 이야기를 하고, 진짜인 것은 진짜라고 이야기를 하는 것이다.
그래야 판별자든 생성자든 더 성능이 좋아질 것이다.
결국, 정확도가 높아져야, 속이는 입장인 생성자도 '진짜같은 가짜'를 더 머리를 굴려서 잘 만드려고 하기 때문이다.
13.training
자, 지금부터는 데이터를 본격적으로 확인하는 과정이다.
코드가 길다. 과정들을 잘 살피자.
#생성자 만든 가짜 이미지를 저장할 리스트(확인용)
img_list = []
#Generator, Discriminator의 loss들을 저장할 리스트이다.
G_losses = []
D_losses = []
iters = 0 #몇번째 step인지를 저장할 변수
print("Starting Training Loop...")
s_all = time.time() ##전체 학습 시간을 계산한다.
for epoch in range(num_epochs):
s = time.time() ##에폭별 학습 시간을 계산한다.
for i, data in enumerate(dataloader, 0):
#한 step
####################################################################################
# (1) Update Discriminator(판별자) network Traing
###################################################################################
netD.zero_grad() #gradient 초기화
#X(진짜 이미지)
real_cpu = data[0].to(device) #data:(X,y)로 이뤄져있는 튜플. data[0]: 이미지
b_size = real_cpu.size(0) #(batch,c,h,w) ->데이터수
#y(정답) - 1
label = torch.full((b_size,), real_label, dtype=torch.float, device=device)
### 모델 추정 ===>진짜인지의 여부를 출력한다.
output = netD(real_cpu).view(-1)
#flatten을 통해 다차원으로 이뤄져 있는 배열을 1차원르로 바꾼다.
errD_real = criterion(output, label)
###판별자가 진짜 이미지를 추론한 결과의 오차를 구한다.
errD_real.backward()
#연산을 다 한 다음, gradient를 계산한다.
#판별자가 real image에 대해 맞춘 비율(정확도)
D_x = output.mean().item()
#가짜 이미지를 생성한다. - 가짜 이미지에 대한 input data를 생성한다.
# Generator의 입력 vector를 생성한다. (100,1,1)
noise = torch.randn(b_size, nz, 1, 1, device=device)
#이미지 생성(X)
fake = netG(noise)
## 정답(y) - 0.0
label.fill_(fake_label) #Tensor객체.fill_(값) 텐서의 값을 "값"으로 다 변경.
#### 가짜 이미지를 판별자를 통해 판별한다.
output = netD(fake.detach()).view(-1) #Tensor객체.detach() : 계산그래프에서 뺀다.
# Tensor객체. detach(): 계산그래프에서 뺀다. Tensor 객체의 값만 복사한 tensor를 반환한다.
errD_fake = criterion(output, label) #판별자가 가짜 이미지에 대한 추정결과의 오차를 계산한다.
#gradient 계산
errD_fake.backward()
### 판별자 파라미터들의 gradient는 가짜 + 진짜에 대한 gradient 합이다.
D_G_z1 = output.mean().item() # 가짜 이미지에 대해서 틀린 것의 비율을 구한다.
#현재 step에서 판별자의 loss -> 진짜이미지에 대한 loss + 가짜 이미지에 대한 loss
errD = errD_real + errD_fake
#판별자의 파라미터 업데이트
optimizerD.step()
#######################################################
# (2) Update Generator(생성자) network Traning
#######################################################
netG.zero_grad()
label.fill_(real_label)
output = netD(fake).view(-1)
errG = criterion(output, label)
errG.backward()
D_G_z2 = output.mean().item()
optimizerG.step()
if i % 50 == 0:
print('[%02d/%d][%04d:/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'.format(epoch+1,
num_epochs,
i,
len(dataloader),
errD.item(),
errG.item(),
D_x,
D_G_z1,
D_G_z2
))
G_losses.append(errG.item())
D_losses.append(errD.item())
#500 step에 한번씩, 마지막 에폭의 마지막 step일 경우
#generator가 생성한 가짜 이미지를 저장한다. - fixed_noise를 입력으로 사용한다.
if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1
e = time.time() #시간을 잰다.
print(f"{epoch+1} epoch 걸린시간: {e-s}초")
e_all = time.time()
print(f"총 걸린 시간: {e_all - s_all}초")그런데...... 시간이 굉장히 많이 걸린다는 단점이 있다.
그래서 colab에서 코드를 실행할 것이다.
다음은 코랩에서 실행 한 뒤, 파일의 일부를 가져 온 것이다.
Starting Training Loop...
[01/10][0000:/1583] Loss_D: 0.3648 Loss_G: 2.3453 D(x): 0.7993 D(G(z)): 0.1089 / 0.1206
[01/10][0050:/1583] Loss_D: 0.4648 Loss_G: 2.3824 D(x): 0.8162 D(G(z)): 0.1964 / 0.1163
[01/10][0100:/1583] Loss_D: 0.6551 Loss_G: 1.2915 D(x): 0.6736 D(G(z)): 0.1600 / 0.3375
[01/10][0150:/1583] Loss_D: 0.4212 Loss_G: 2.7231 D(x): 0.8351 D(G(z)): 0.1827 / 0.0866
[01/10][0200:/1583] Loss_D: 1.5777 Loss_G: 0.7706 D(x): 0.2744 D(G(z)): 0.0315 / 0.5191
[01/10][0250:/1583] Loss_D: 0.5331 Loss_G: 3.3886 D(x): 0.7150 D(G(z)): 0.1312 / 0.0539
[01/10][0300:/1583] Loss_D: 0.5195 Loss_G: 3.6319 D(x): 0.8770 D(G(z)): 0.2761 / 0.0375
[01/10][0350:/1583] Loss_D: 0.6521 Loss_G: 1.1155 D(x): 0.6341 D(G(z)): 0.1075 / 0.3925
[01/10][0400:/1583] Loss_D: 0.4299 Loss_G: 2.1815 D(x): 0.7854 D(G(z)): 0.1374 / 0.1416
[01/10][0450:/1583] Loss_D: 0.6203 Loss_G: 2.2737 D(x): 0.7017 D(G(z)): 0.1800 / 0.1349
[01/10][0500:/1583] Loss_D: 2.0625 Loss_G: 7.0306 D(x): 0.9787 D(G(z)): 0.8164 / 0.0020
[01/10][0550:/1583] Loss_D: 0.4117 Loss_G: 2.4965 D(x): 0.7873 D(G(z)): 0.1330 / 0.1065
[01/10][0600:/1583] Loss_D: 0.7915 Loss_G: 1.2773 D(x): 0.5333 D(G(z)): 0.0627 / 0.3406
[01/10][0650:/1583] Loss_D: 0.4899 Loss_G: 1.9141 D(x): 0.7026 D(G(z)): 0.0918 / 0.1782
[01/10][0700:/1583] Loss_D: 0.4754 Loss_G: 2.8153 D(x): 0.8910 D(G(z)): 0.2760 / 0.0747
[01/10][0750:/1583] Loss_D: 0.5148 Loss_G: 2.0415 D(x): 0.7001 D(G(z)): 0.1147 / 0.1691
[01/10][0800:/1583] Loss_D: 0.5776 Loss_G: 1.9174 D(x): 0.6243 D(G(z)): 0.0369 / 0.1932
[01/10][0850:/1583] Loss_D: 0.3079 Loss_G: 3.0601 D(x): 0.8495 D(G(z)): 0.1163 / 0.0605
[01/10][0900:/1583] Loss_D: 0.8212 Loss_G: 1.6980 D(x): 0.5479 D(G(z)): 0.0837 / 0.2315
[01/10][0950:/1583] Loss_D: 0.8422 Loss_G: 4.0060 D(x): 0.9404 D(G(z)): 0.4883 / 0.0265
[01/10][1000:/1583] Loss_D: 1.7864 Loss_G: 5.3595 D(x): 0.9685 D(G(z)): 0.7726 / 0.0081
[01/10][1050:/1583] Loss_D: 0.3616 Loss_G: 2.9288 D(x): 0.8409 D(G(z)): 0.1490 / 0.0731
[01/10][1100:/1583] Loss_D: 0.5798 Loss_G: 3.6933 D(x): 0.8986 D(G(z)): 0.3365 / 0.0356
[01/10][1150:/1583] Loss_D: 0.7947 Loss_G: 1.0852 D(x): 0.5281 D(G(z)): 0.0425 / 0.4060
[01/10][1200:/1583] Loss_D: 0.6481 Loss_G: 3.7363 D(x): 0.9372 D(G(z)): 0.4039 / 0.0325
[01/10][1250:/1583] Loss_D: 0.6301 Loss_G: 1.7577 D(x): 0.6199 D(G(z)): 0.0826 / 0.2069
[01/10][1300:/1583] Loss_D: 1.1787 Loss_G: 3.1940 D(x): 0.8826 D(G(z)): 0.5691 / 0.0637
[01/10][1350:/1583] Loss_D: 0.5815 Loss_G: 1.7891 D(x): 0.7154 D(G(z)): 0.1667 / 0.2007
[01/10][1400:/1583] Loss_D: 0.6557 Loss_G: 1.4648 D(x): 0.5972 D(G(z)): 0.0681 / 0.2770
[01/10][1450:/1583] Loss_D: 0.8633 Loss_G: 4.7089 D(x): 0.9150 D(G(z)): 0.4842 / 0.0146
[01/10][1500:/1583] Loss_D: 1.1851 Loss_G: 1.3888 D(x): 0.3882 D(G(z)): 0.0534 / 0.3199
[01/10][1550:/1583] Loss_D: 0.3729 Loss_G: 3.2242 D(x): 0.9116 D(G(z)): 0.2221 / 0.0545
1 epoch 걸린시간: 304.21628975868225초
[02/10][0000:/1583] Loss_D: 0.7503 Loss_G: 1.2695 D(x): 0.5871 D(G(z)): 0.1030 / 0.3298
[02/10][0050:/1583] Loss_D: 0.5040 Loss_G: 3.2199 D(x): 0.9109 D(G(z)): 0.2919 / 0.0530
[02/10][0100:/1583] Loss_D: 0.4720 Loss_G: 1.9830 D(x): 0.7445 D(G(z)): 0.1210 / 0.1786
[02/10][0150:/1583] Loss_D: 0.4589 Loss_G: 2.2812 D(x): 0.7861 D(G(z)): 0.1691 / 0.131414.학습 결과 시각화
훈련을 다 마친 다음의 인물 사진을 보면,
이상하긴 하지만 어쨋든 사람의 형태를 한 그림들이 출력이 된다.
잡음이 들어가서 이렇게 된 것이다.
(강사님의 코드 보고 내용 마무리 짓기.)
