1.컴퓨터 비전(Computer Vision)
인간의 시각과 관련된 부분을 컴퓨터 알고리즘을 이용해 구현하는 방법을 연구하는 분야로 최근에는 딥러닝 알고리즘을 이용한 방식이 주류를 이루고 있다.
2.주요 컴퓨터 비전 분야
- Image Classification (이미지 분류)
- Image Segmentation
- Object Detection (물체검출)
근데 위의 설명만 보면 뭐가 뭔지 잘 모르겠지?
그럼, 그림을 보자.(라임 좋다)
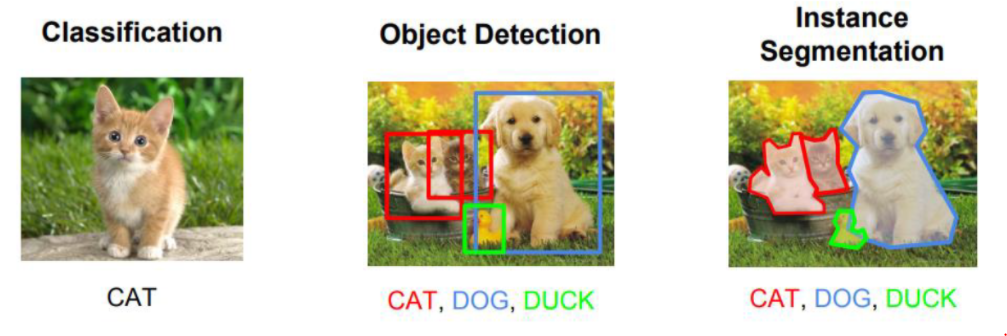
3.Object Detection 개요
자, object Detection을 한다고 한다면,
이미지는 x이다.
그렇다면 y는 뭘까? y는 'label class'이다.
이는 어떤 동물인지 구분하는 것이다.
또한, 고양이가 어디에 있는지, 개가 어디에 있는지 나타낸다.
한마디로, (class,좌표) 같은 식으로 나타낸다는 것이다.
4.예시
(0,20,10,30,60) 이런 식으로 나타낸다.
첫번째는 class이고, 나머지는 좌표를 나타낸다.
보통 Image Segmentation와 Object Detection이 이런 방법을 쓰며,
Image Classification은 다른 방법을 쓴다.
5.결론
x와 y를 문제푸는 영역에 맞춘 다음, y에 맞춰서 학습을 시킨다.
그렇게 된다면, 어느 정도 성능이 나온다.
6.Object Detection 개요
한줄요약: Object Detection = Localization + Classification
Object Detection은 우선 영상에 존재하는 물체들을 Bounding Box을
통해 위치를 찾아내고, class를 분류하는 작업이다.
7.Object Detection 방식
One stage detector: localization과 classification을 하나의 네트워크에서 처리
Two stage detector: localization과 classification을 나눠서 순차적으로 실행 처리
이렇게 2가지 방법이 있다.
One stage detector은 한방에 찾을 수 있어서 속도가 빠르다.
Two stage detector는, '어? 일단 모델이 있네요'라고 한 다음,
그 이미지를 자른 다음에 classification을 한다.
이렇기 때문에 정확도는 높지만, 속도는 느리다.
8.근데 이 분야는 속도가 더 중요하기 때문에,
One stage detector가 더 중요해졌다.
그래서
One stage detector를 쓰면서 어떻게 정확도를 높일까??
라는 연구가 활발하게 이뤄지고 있다.
9.Bounding Box(BBox)의 Location(위치)
Bounding Box의 위치값은 4개로 구성되어 있는데 각 값이 가리키는 것은 모델마다 다르다. 대부분 아래 3가지 경우중 하나이다.
9.1.x좌표, y좌표, width, hight 로 구성
-x좌표, y좌표
Bounding Box 중심점의 좌표
Bounding Box 좌상단 좌표
-width, height: Bounding Box 의 너비(widgh)와 높이(heigh)
9.2.x_min, y_min, x_max, y_max를 이용
x_min, y_min: 좌상단(Left-Top)의 x, y 좌표
x_max, y_max: 우하단(right-bottom)의 x, y 좌표
자, 여기서 중요한 것은,
알고리즘에 따라 좌표와 크기를 실제값 또는 이미지의 width, height 대비 비율로 지정한다는 것이다.
이렇게 하는 이유는,
비율로 했을 때 장점은 원본 이미지의 크기가 resize되어도 영향을 받지 않기 때문이다.
ex) (X좌표/이미지 width, Y좌표/이미지 height, bbox width/이미지 width, bbox height/이미지 height)
9.3.Object class 관련 출력값
직접 사진을 보는 것이 좋다.

순서대로
좌표,class,확률
이다. 위의 그림을 보면,
첫번째 박스 안에 사람 object가 있을 확률이 0.92이고,
두번째 박스 안에 고양이 object가 있을 확률이 0.93이다.
9.4.
Object Dection 은 하나의 이미지안에서 N개의 Object를 검출해 내야 한
다. 그런데 몇개를 찾을지는 입력 이미지마다 다르다. 그래서 한 이미지에
찾으려는 Object가 있을 최대의 개수를 정하고 모델은 무조건 그 개수만큼
bounding box(위치+분류)를 추론(출력)하도록 한다. 추론한 결과에서 후
처리를 통해 최종 추론결과를 낸다.
위와 같은 이유로 bounding box마다 box안에 물체가 있을 확률
(confidence score)을 모델이 찾도록 하여 낮은 확률의 box는 후처리에
서 제거한다.(확률이 낮은 것들은 제거!)
이런 과정이 꽤나 힘이 드는 모양이다.
9.5.문제와 해결책
자, 다른 문제도 있다.
고양이를 찾고자하는데 어떤 이미지(예:군대 사진)에는 고양이가 0마리일수도 있고,
고양이 가게 사진에서는 고양이가 20마리일 수도 있다.
즉, 내가 찾으려는 사물이 이미지 안에 몇개인지 고정이 되지 않기 때문에,
데이터를 처리하기가 힘들어지는 측면이 있다.
그래서, 이런 문제를 해결하는 것이 중요하다.
train 이미지가 100개라고 하면, output은 100개가 필요할 것이다.
이를 더 극단적으로 이야기하면,
에이, 설마, 한 사진에 고양이가 1만개 이상이 있겠어? 찾을 수 있는 고양이의 최대 개수를 1만개로 정하자!
이런 식이다.
즉, 최대로 찾을 수 있는 object의 수를 정해 두는 것이다.
(bounding box의 개수를 1만개를 상한으로 정하는 것이다.)
뭐.... 이 '상한'은 몇개로 설정을 하든 상관없다. '유도리' 있게 하는게
좋을듯.
10.ObjectDection 성능 평가
IoU (Intersection Over Union, Jaccard overlap)
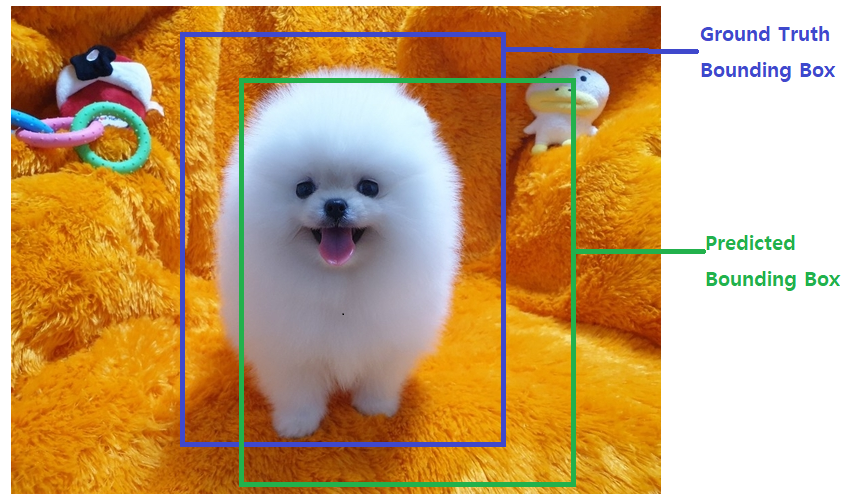
bounding box를 평가하는 것이다. 보통 후처리를 하는 과정에서 쓰인다.
보통은 두 개의 bounding box가 얼마나 겹치는지를 나타내는 평가지표이다.
보통, IoU값 0.5를 기준으로 그 이상이면 많이 겹치는 것으로 적게 겹치는 것으로 본다. 이 기준이 되는 값을 IoU Threshold(임계값) 라고 한다.
(근데 왜 0.5라는 비교적 낮아 보이는 수치를 기준으로 삼는가?---회귀 문제이기 때문이다.)
회귀에 관해서는 이 블로그의 설명글을 참고하자.
https://velog.io/@ym980118/%EB%94%A5%EB%9F%AC%EB%8B%9D-%ED%9A%8C%EA%B7%80-Regression
Train(학습) 시 모델이 예측한 bounding box와 ground truth(정답)
bounding box가 얼마나 겹치는지 확인하는 지표로 사용.
모델이 추론한 결과에서 하나의 object에 대해 여러개 bounding box가 나
오면 그중 하나만 선택할 때 사용.(NMS)
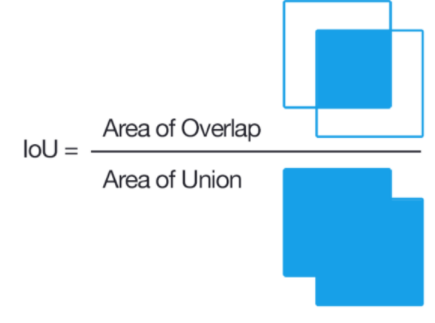
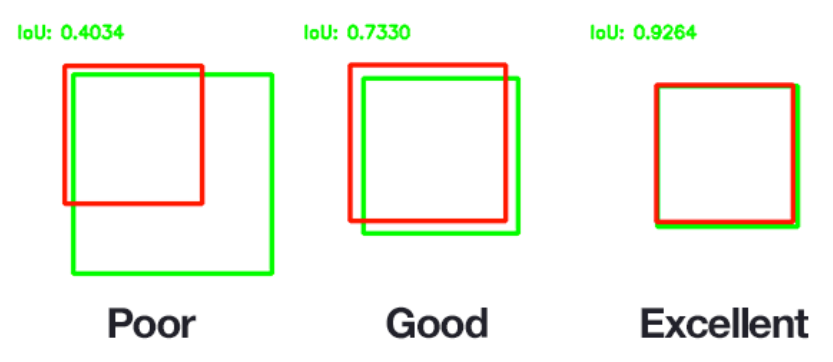
그림은 참고용!
11.mAP (mean Average Precision)
근데..... 이를 들어가기 위해서는 정밀도와 재현율에 대해 잘 알아야 한다.
정밀도는 positive로 예측한 것 중 실제 positive인 것의 비율이다.
재현율은 실제 positive인 것 중 positive로 예측한 것의 비율이다.
이 둘은 비슷한 듯 보이지만, 실제로는 상당히 다르다.
예시를 보자.

1개를 예측해서 1개 맞았으므로 Precision(정밀도)은 100%(1.0)가 된다.
새는 두 마리인데 하나만 Detect(검출) 했으므로 Recall(재현율)은 50%(0.5)가 된다.
12.Confusion Matrix와 Object Detection
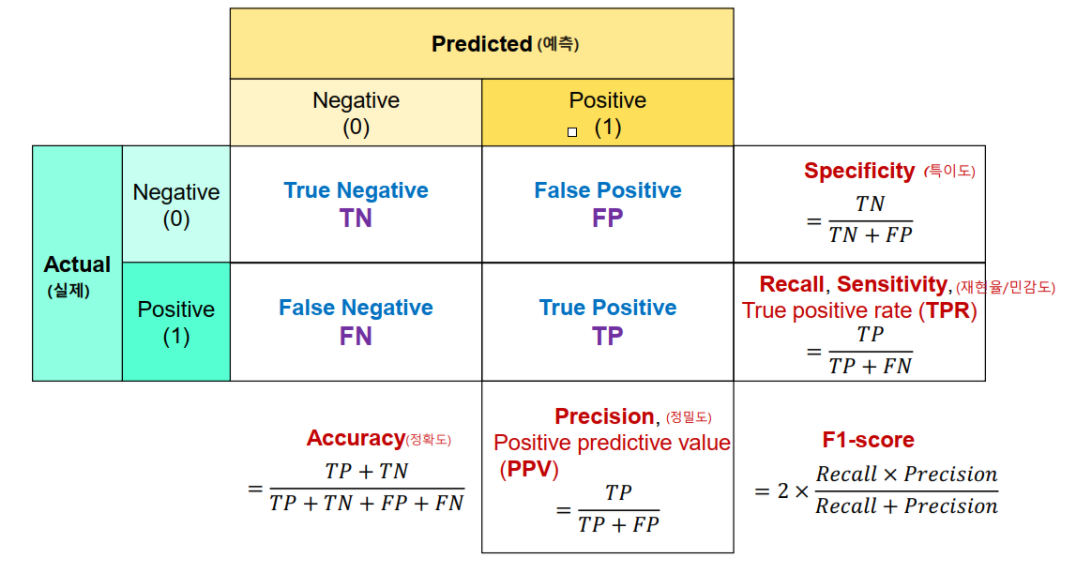
위 그림을 보면, 정밀도나 재현율에 대한 인사이트를 얻을 수 있을 것이다.
아, 참! 위 그래프를 보기 위해 용어들을 정리했다.
T:맞은 것, F:틀린 것
N: Negative로 모델이 예측을 한 것, P:Positive로 모델이 예측한 것
EX: TN: N으로 예측해서 맞은 것의 개수
13.간단한 예시
### confusion matrix 계산 -> scikit-learn 이용
import numpy as np
from sklearn.metrics import confusion_matrix
##class: 0,1 (이진분류)
y=np.array([0,1,1,1,0])
pred = np.array([0,0,1,1,1]) #정답과 조작을 정의한다. 5개 중에 3개가 정답이다.
cm = confusion_matrix(y,pred) #평가지표 함수(정답, 모델 예측값)
print(cm)
# 대각선이 맞춘 거다.
# 대각선이 아닌 것들은 예측과 실제 값이 다른 경우들이다.출력 코드는 다음과 같다.
[[1 1]
[1 2]]이를 더 세련되게 표현하면 다음과 같다.
from sklearn.metrics import accuracy_score, recall_score, precision_score
#accuracy 계산
print(f"정확도:{accuracy_score(y,pred)}",(3/5))
print(f"재현율:{recall_score(y,pred)}",(2/3))
print(f"정밀도(precision): {precision_score(y,pred)}",(2/3))출력 코드는 다음과 같다.
#출력 코드
정확도:0.6 0.6
재현율:0.6666666666666666 0.6666666666666666
정밀도(precision): 0.6666666666666666 0.6666666666666666자, 이제는 class가 여러개인 경우를 한번 보자.
#class가 여러개인 경우
y = np.array([0,0,1,2,2,3,4,4,2,3])
pred = np.array([0,0,1,2,2,3,4,4,2,3])
confusion_matrix(y,pred)출력값은 다음과 같다. 이 중, 대각선이 정답니다.
array([[2, 0, 0, 0, 0],
[0, 1, 0, 0, 0],
[0, 0, 3, 0, 0],
[0, 0, 0, 2, 0],
[0, 0, 0, 0, 2]], dtype=int64)14.Object Detection에서 TP, FP, FN

그림에서도 알 수 있듯, TN은 보지 않는다.
이유는 Negative라고 예측(찾는 대상이 아니라고 예측-즉, 배경)해서
True인 것은 '아니라고 예측을 해서(배경이라고 예측해서) 그것이 맞은 것'이다.
근데, 우리는 배경을 찾을 필요는 없다. 그래서 TN은 목적이 아니다.
또 하나 잘 봐야 할 것은,
FP 부분에서 IOU <0.5라고 입력이 되어 있는 것이다.
0.5가 넘느냐 마느냐에 따라 참과 거짓을 구분할 수 있다.
추가적인 설명은 캡쳐 사진을 잘 보도록 하자.

15.precision과 recall의 trade off(반비례관계)
여러가지 중요한 사실이 있다. 잘 파악하도록 하자.
Confidence Score: 박스 안에 내가 찾는 사물이 있는지에 대한 점수.
실제로 사물이 있는지 없는지는 상관이 없다. '박스 안에'만 있어야 한다.
이 score는 1차적인 거름망 역활을 한다.
Confidence threshold: 지정된 값 이상의 confidence를 가진 결과만 예측결과로 사용하고 그 이하인 것들은 무시한다.
예:이 값을 0.5로 설정하면 confidence score가 0.5 미만인 결과(0.1,0.2,0.3등)는 무시한다.이 값은 하이퍼파라미터이다.
그런데, 이 값은 높게 측정하지는 않는다. 기준을 높게 잡으면, 정작 정확도가 많이 떨어지기 때문이다.
하지만, 그렇다고 기준값을 극단적으로 낮게 잡지도 않는다.
Confidence threshold를 높게 잡으면 recall은 낮아지지만, 정확도는 높아진다. 반면, Confidence threshold를 낮게 잡으면 recall은 높아지지만 정확도는 낮아진다.
그렇기 때문에, Confidence threshold를 0.5보다 높게 잡느냐 낮게 잡느냐가 중요해진다.
아래의 그림들을 보면서, 관련 개념을 보도록 하자.
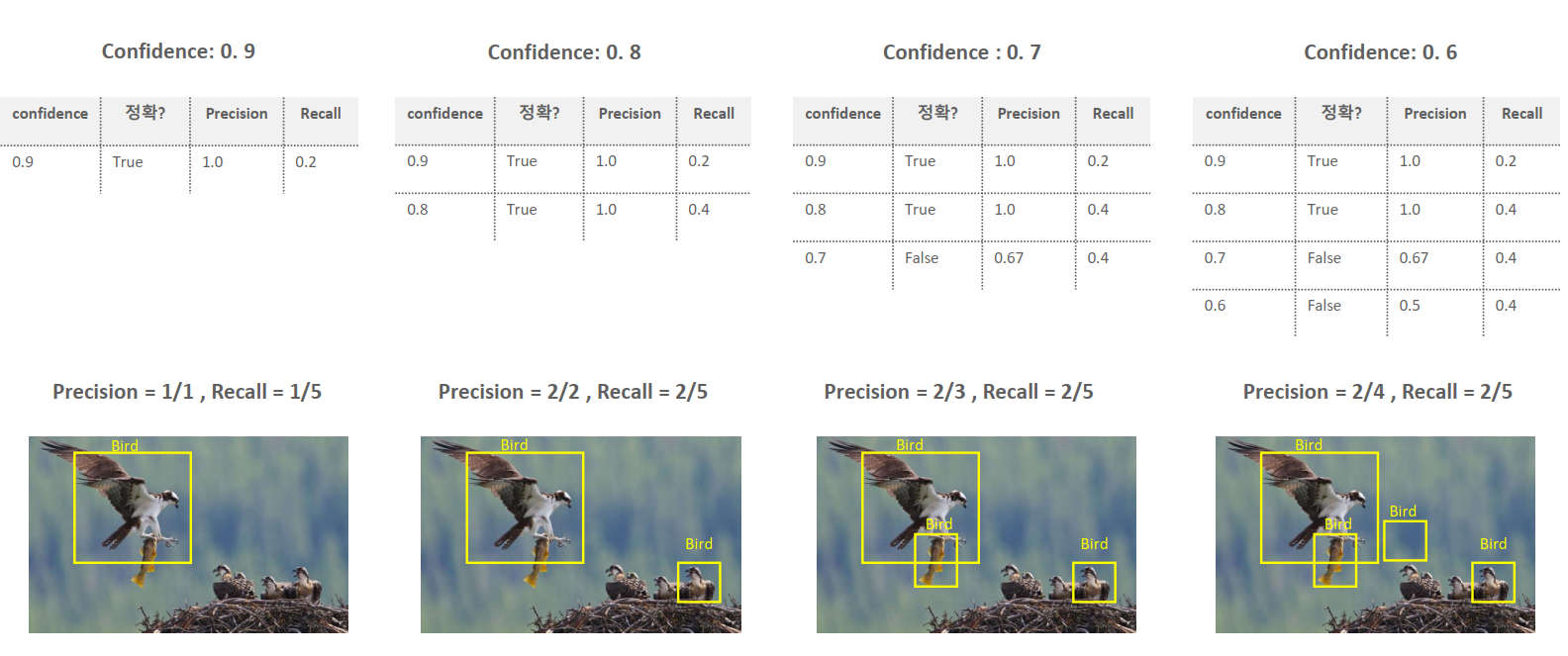

잘 보면, precision과 recall은 서로 정비례하지 않는다는 것을 볼 수 있다.
16.precision과 recall의 trade off(반비례관계)에 대한 인사이트
confidence에 따라서 precision과 recall의 관계가 엄청나게 차이가 난다.
또한, confidence를 마냥 늘린다고, 혹은 마냥 줄인다고 precision과
recall의 '수치'가 마냥 좋아지거나 나빠지지 않는다.(물론 confidence를
줄일수록 precision이 떨어지므로 bad한 것이라고는 할 수 있다.)
또한, 위의 그림에서 recall이나 precision에 대한 그래프를 보았을 때,
confidence score와 precision의 상관관계에 대한 인사이트도 있다.
이는 다음과 같다.
confidence score를 낮춤에 따라 precision도 낮아진다. 그러나 최대한 버티다가 떨어지는 경우도 있고, 훅하고 가버리는 경우도 있다.
당연히, 최대한 버티다가 떨어지는 모델이 성능이 좋은 모델이다.
위와 같은 것을 그래프로 그린 것을 Precision-Recall curve라고 한다.
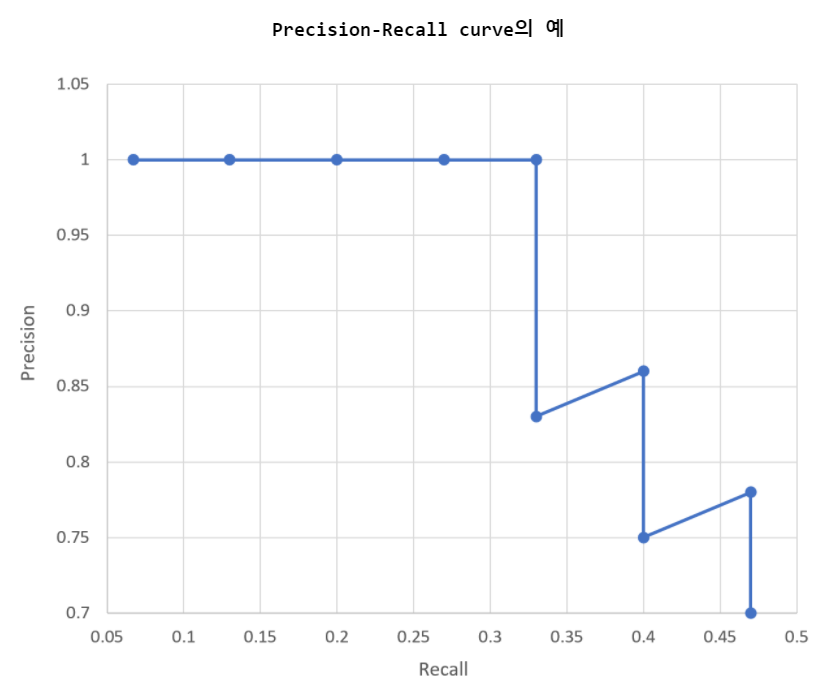
17.Average Precision (AP)
다음과 같은 그래프를 보자.
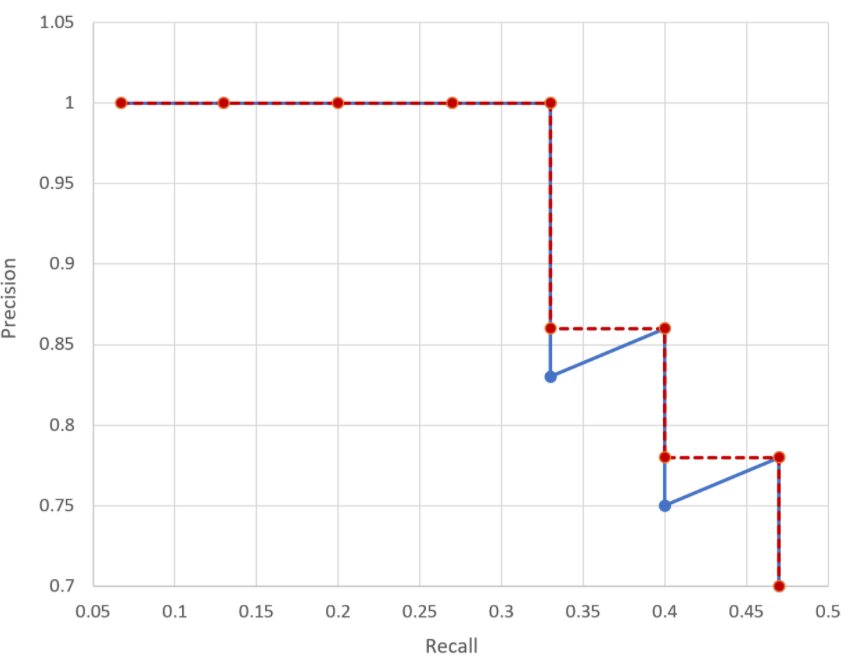
그래프만 봐서는 뭐가 뭔지 알 수 없다. 그러니, 설명을 보자.
한마디로, 꺾인 부분이 있는 그래프를 계단형으로 바꾼 다음 그것의 면적을 구한다. 이 값은 0에서 1사이의 값을 가지며 1에 가까울수록 좋은 성능을 낸다.
Precision-Recall curve를 점수화시킨 것이 AP라고 할 수 있다.
18.mAP (mean Average Precision)
검출해야하는 Object가 여러개인 경우 각 클래스별 AP를 평균값을 mAP라고 한다.
19.논문의 평가지표 예시

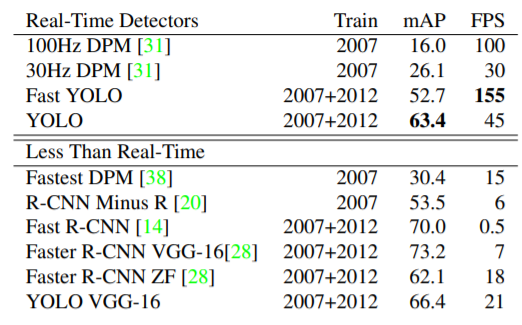
FPS: Frame Per Second 로 초당 몇 Frame씩 처리했는지를 나타낸다. 클수록 1초에 처리하는 Frame양이 많다는 것으로 처리속도가 빠르다는 것을 의미한다.
아래 그림은 각 모델별로 초당 몇 Frame씩 처리했는지를 나타낸다.
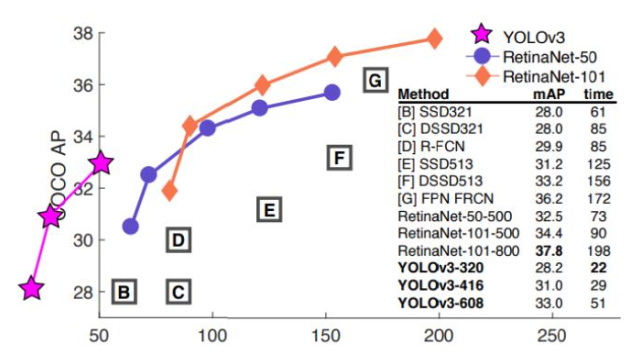
말 그대로 성능을 나타내주는 것이다.
이 때, 쓰이는 수치가 time과 앞서 이야기한 mAP이다.
20.Model 추론 결과 후처리 (Post Processing)
모델이 추론한 Bounding Box 예측 결과를 후처리를 통해 정제한다.
20.1.NMS(Non Max Suppression)
Object Dection 알고리즘은 Object가 있을 것이라 예측하는 위치에 여러
개의 bounding Box들을 예측한다.
NMS는 Detect(검출)된 Bounding Box들 중에서 비슷한 위치에 있는 겹치
는bbox들을 제거하고 가장 적합한 bbox를 선택하는 방법이다.
위의 것을 간단히 이해하려면, 아래 그림을 보도록 하자.
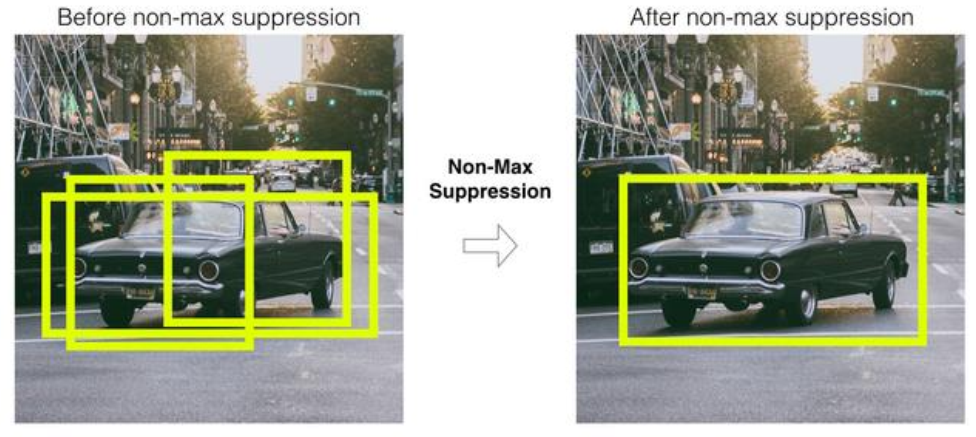
21.NMS 실행 로직
만약 박스가 1000개가 나온다고 하면,
각 박스는 confidence score가 나오고, 각자 좌표도 존재할 것이다.
많은 박스들 중, onfidence score가 Confidence threshold (신뢰 임계
값) 이하의 박스들을 제거한다. (confidence threshold는 하이퍼파라미
터)
그런 다음, 가장 높은 confidence score를 가진 bounding box 순서대로
내림차순 정렬을 한 뒤 높은 confidence score를 가진 bounding box와 겹
치는 다른 bounding box를 모두 조사하여 IoU가 특정 threshold(임계값)
이상인 bounding box들을 모두 제거한다. (ex: IoU threshold > 0.5)
한마디로 많이 겹치는 것들은 제거를 한다는 것이다.
그렇게 제거를 하고, 가장 수치가 정확한 것들 위주로 남긴다.
22.단점
근데.... 이 box가 겹치는 경우보다, 물체 그 자체가 겹치는 경우에는 어찌할겨?

이 그림을 보면 위에서 말한 것이 뭔지 알 수 있다.
그래서, 이를 해결하는 방법이 바로 Soft NMS이다.
23.Soft NMS
Soft NMS는 겹치는 bbox의 경우 confidence score가 낮은 것을 제거하지
않고 confidence score를 줄여서 남긴다.
그래서, 아까 보았던 그림을 다시 보자면, 좌우 사이드에 있는 말의
confidence를 0.4로 줄인다.
(참고 사이트:https://towardsdatascience.com/non-maximum-suppression-nms-93ce178e177c)
