1.Sequential 데이터란
데이터의 순서 정보가 중요한 데이터셋으로, 순서가 달라질 경우 의미가 바
뀌거나 손상되는 데이터를 말한다.
이렇게 보면 어려울 수 있는데,
예를 들면
자연어 텍스트 같은 것이다.
어순이 바뀌기나 하면 의미가 많이 퇴색되니 말이다.
한 마디로, 시간의 흐름이 중요한 데이터이다.
예:50년간 주식 가격의 변화/100년간 한국의 GDP 변화 등등...
2.RNN (Recurrent Neural Network) 구조
RNN은 Recurrent Layer을 사용하는 딥러닝 모델을 말한다.
또한, Feature 추출기로 Recurrent layer를 사용한다.
이 RNN은 Sequential 데이터 처리에 좋은 성능을 낸다.
3.메모리 시스템
Sequentail을 처리하는데 중요한 것은 기억이다.
단순히 순서대로만 처리하는게 중요한 것이 아니다. 이전 단계의 처리결과를
기억하고 그것을 현재 단계 처리에 사용한다.
Sequential 데이터 처리에서 순서대로 처리할 때 각각의 단계를 time
step 이라고 한다.
아래는 메모리 시스템에 관한 그림이다.
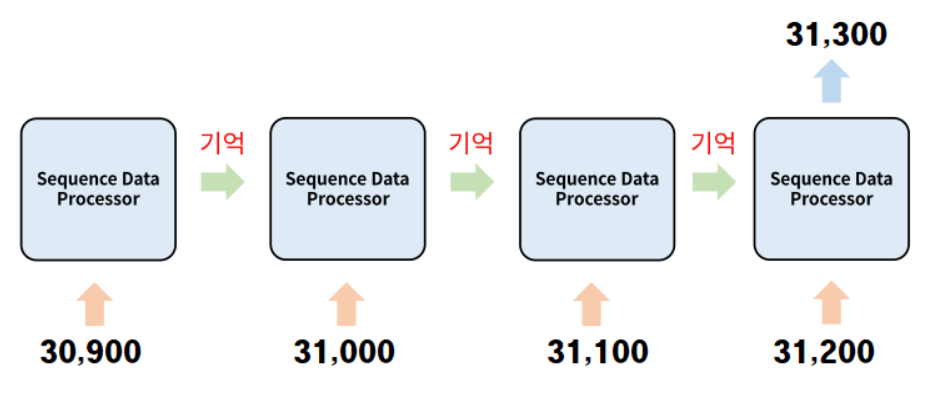
위 그림에서 가장 중요한 것은
두번째 processor가 전의 메모리가 30,900인 것을 기억하는 것이다.
3.1.예시
10일간의 주가 변화를 토대로 5일째 주가를 예측하기 위해서는 입력받은 4일간의 주가의 순서를 다 기억하고 있어야 한다.
4.Simple RNN 구조
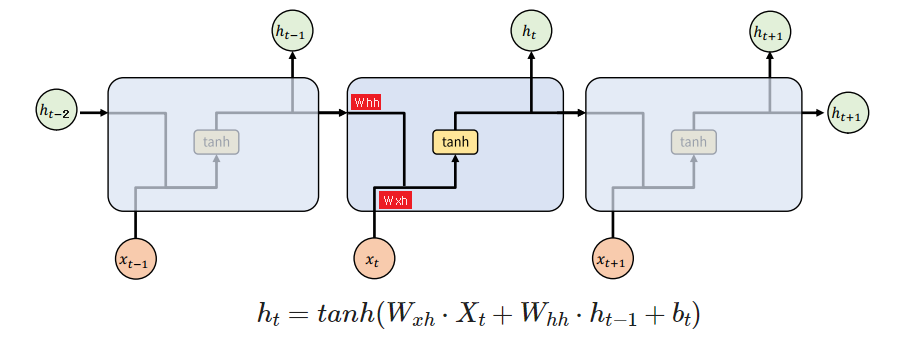
그림을 보면, rnn이기 때문에, 결과값인 h1을 받은 것을 볼 수 있다.
이 과정을 함수로 간단히 비유해보자.
wx:"x의 가중치", wh:"h의 가중치",b = w1,w2,w3
def RNN(X:"현재데이터",h:"이전처리"):
return tanh(X@wx+h@wh+b)
hidden = 0
for i in range(10):
#range가 제공하는 값이 현재순서의 값
hidden = RNN(i,hidden)
#이렇게 되면, hidden에 그 전에 처리한 값이 들어가게 된다.
이전 계산의 결과값을 받아서, 그 값이 다음 step에 input으로 들어간다.
4.1.hidden state
이전 step의 처리결과로 현재 step에 입력되는 값을 말한다.
메모리 시스템의 메모리에 해당한다.
'이전까지의 상태값'이라고 생각을 하면 된다.
숙지해야 할 점은
매 타임스텝별로 사용되는 가중치는 동일한 값이라는 것이다.
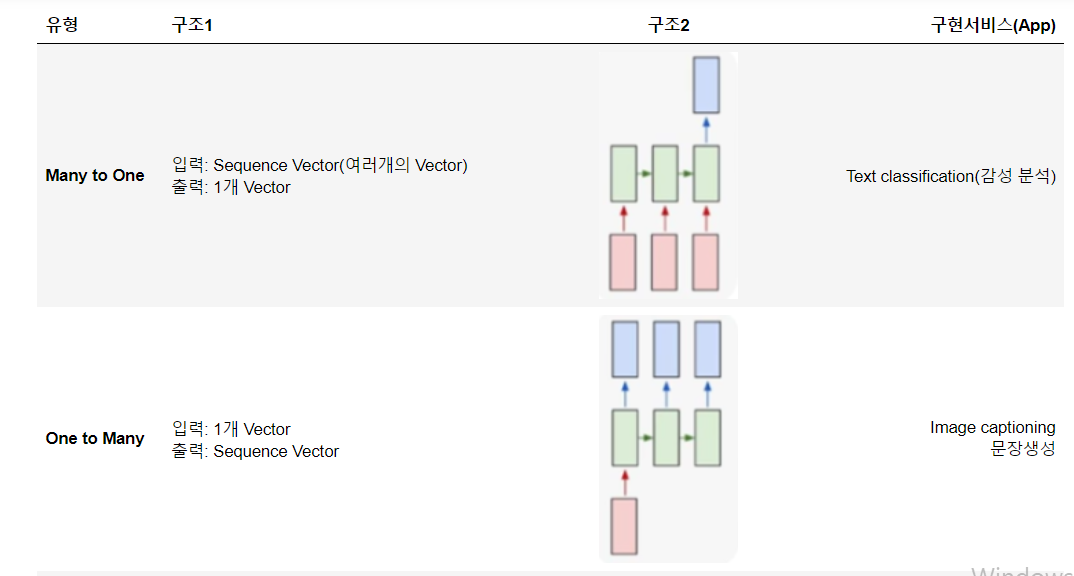
5.문제 유형별 RNN 구조
여러가지 유형이 있다. 밑의 캡쳐 이미지들을 잘 보도록 하자.
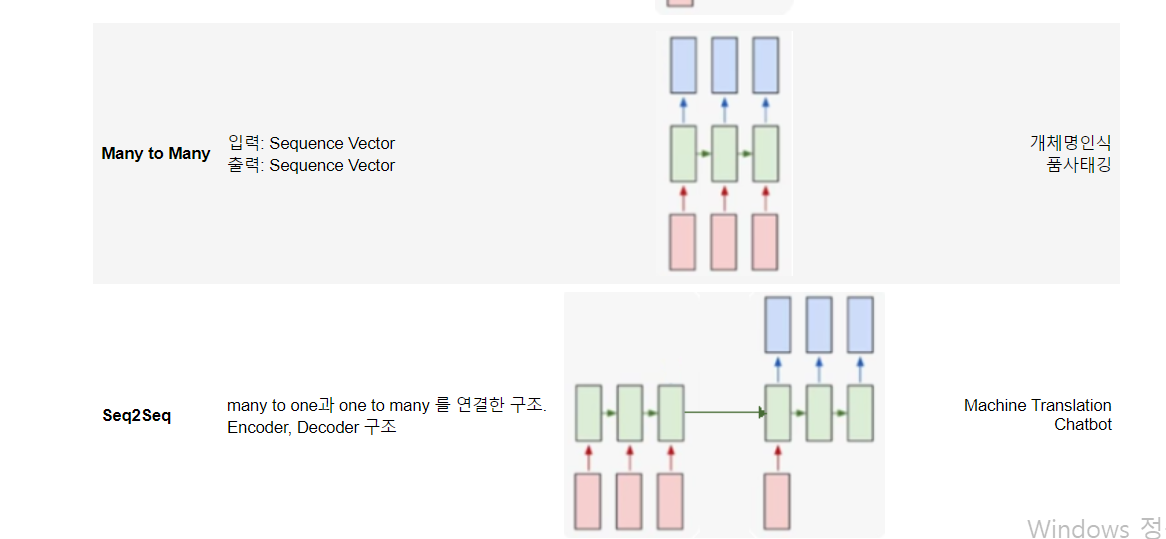
Many to Many에서 품사태깅은
'나' '밥' '먹었다' 등을 따로따로 나누는 것이다.
이렇게 나눠서, 대명사는 뭔지, 명사는 뭔지, 동사는 뭔지 따지는 것이다.
Seq2Seq는 many to one과 one to many를 연결한 구조이다.
이렇게 연결된 것이기 때문에 Seq to Seq이다.
질문에 대한 feature를 만들어 내는 부분이 encoder이고,
답변을 뽑아내는 부분이 decoder이다.
6.Bidirectional RNN
같은 정보를 정방향과 역방향 두 방향으로 주입해서 정확도를 높인다.
Non-Auto Regressive 모델의 경우 bidirectional RNN 사용이 권장이
된다.
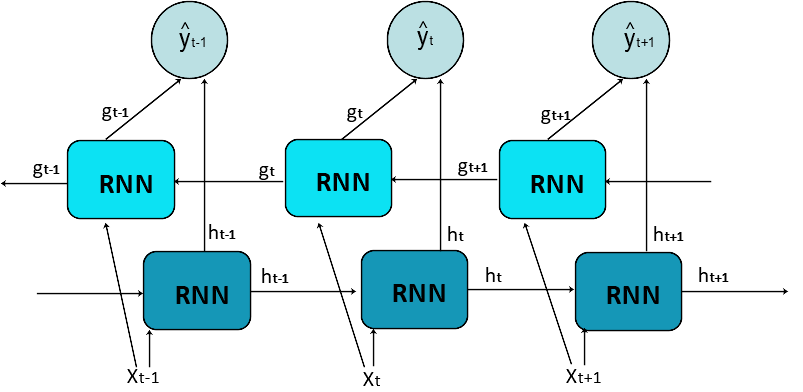
그림을 보면, 오른쪽으로 향하는 화살과
왼쪽으로 향햐는 화살
이렇게 2개가 있다.
Xt-1시점의 결과는 Yt-1가 되고, Xt 시점의 결과는 Yt가 되고 뭐 이런 식이다.
7.Stacking(Multi Layer) RNN
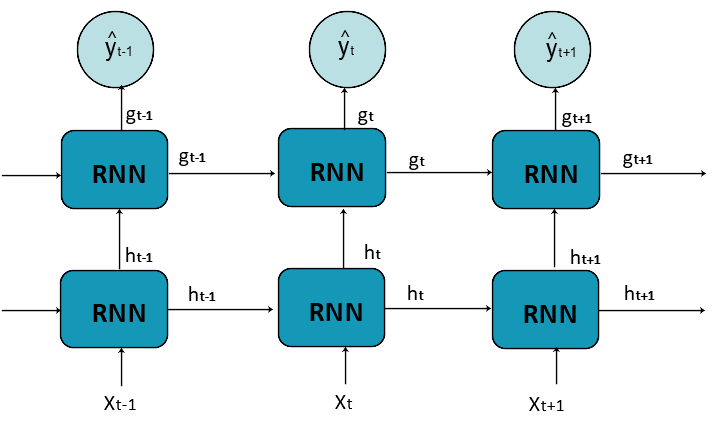
그림을 보면, X와 그 전의 h의 입력을 받아서, h 출력값이 나온다.
그 출력값이 다음 layer의 입력값이 되어서, g의 값에 영향을 주는 형식이다.
layer를 여러개 쌓았기 때문에 Stacking이라고 한다.
8.Pytorch RNN Layer
파라미터

파라미터들 자체는 어렵지 않다. 위의 사진의 설명을 잘 보면 된다.
8.1.RNN Layer의 input / output tensor 의 shape
추론시 input

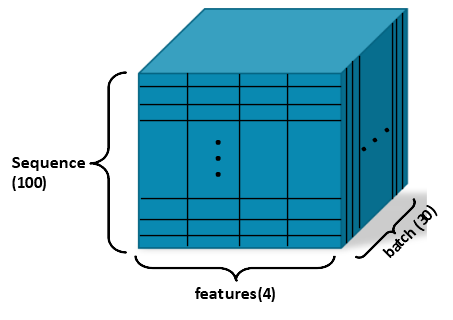
hidden_state의 shape
-시작 hidden state로 입력하지 않으면 0이 들어간다.
-shape은 아래의 hidden state 설명을 참조하자.
Output

Output shape

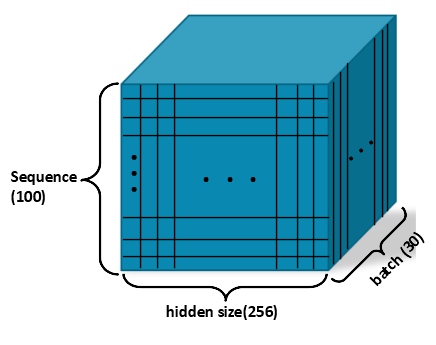
Hidden state

9.RNN의 Back Propagation
BPTT(Back Propagation Through Time) 이라고 한다.
RNN이 sequential하기 때문에 발생하는 hidden state를 따라 역행하면서 전파되는 gradient의 계산 방법이다.
9.1.RNN(Simple RNN)의 문제
Sequence가 길어지면 길어질수록 Gradient Vanishing으로 인해 초기
Sequence에 대한 학습이 안되는 문제가 RNN의 고질적인 문제이다.
아래는 그 이유이다.
RNN은 activation 함수로 tanh()을 사용한다. tanh()의 gradient는 0~1사이의 실수가 나온다. 그래서 sequence가 길어지면 초기 time step 값에 대한 weight가 업데이트 되지 않게 된다.
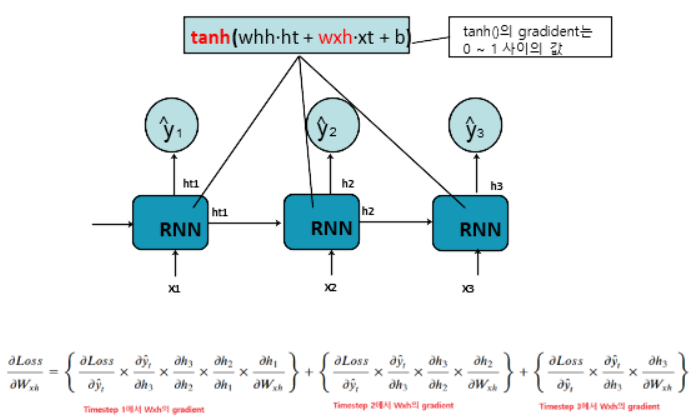
그림을 보면, y1에 관련된 미분값을 구하기 위해서는
y1에 대한 미분값,y2에 대한 미분값, y3에 대한 미분값
이렇게 3개를 다 적용해야 하기 때문에 더 복잡해진다.
간단히 이야기해서,
그 부분을 통과한 것은 다 계산의 범위에 포함해야 한다
라는 것이다.
그래서, 해결책이 있다.
이런 Simple RNN의 문제 모델 구조로 해결한 모델이 LSTM이나 GRU 모델이
다. Sequence 데이터 처리 모델로 이 둘을 주로 사용한다.
10.LSTM
(정리 시간에 따로 정리)
11.Pytorch LSTM layer
다음은 pytorch LSTM의 layer이다.

추론시 input

output

12.코드
import 부분
import torch
import torch.nn as nn
input_data = torch.randn(100,30,6) #[seql len, batch size, feature 수]
lstm 모델을 새롭게 정의한다.
#LSTM 모델을 새롭게 정의한다.
lstm1 = nn.LSTM(input_size=6, #feature수
hidden_size=200,num_layers=1)
print("===LSTM: hidden_size(unit수)=200, num_layers=1, bidirectional=False===")
output1, (hidden1,cell1) = lstm1(input_data)
type(output),type(hidden)
#output: 모든 타입 step 출력
#hidden: 바로 전 step 처리 결과(모든 과정을 다 거쳐서 나온 결과)
#cell_state: 이전 모든 step에 대한 처리 결과이다.(이전 step에서만 처리된 결과)
#결과들을 출력한다.
print(f"output: {output1.shape}, hidden: {hidden1.shape}, cell: {cell1.shape}")
#output: [100:seq개수, 30: batch, 200:hidden크기(유닛수)]
#hidden: [layer수 * 양방향여부, batch, hidden 개수]
#cell: [layer수 * 양방향여부, batch, hidden 개수]
출력값
===LSTM: hidden_size(unit수)=200, num_layers=1, bidirectional=False===
output: torch.Size([100, 30, 200]), hidden: torch.Size([1, 30, 200]), cell: torch.Size([1, 30, 200])그런 다음, bidircetion을 추가함에 따라 출력값이 어떻게 바뀌는지 파악
하자.
#bidircetion을 추가한다.
#bidircetion을 추가함에 따라 출력값이 어떻게 바뀌는지 파악하자.
lstm2 = nn.LSTM(input_size=6, #feature수
hidden_size=200,num_layers=1,bidirectional=True)
print("===LSTM: hidden_size(unit수)=200, num_layers=1, bidirectional=False===")
output2, (hidden2,cell2) = lstm2(input_data)
type(output),type(hidden)
#output: 모든 타입 step 출력
#hidden: 바로 전 step 처리 결과(모든 과정을 다 거쳐서 나온 결과)
#cell_state: 이전 모든 step에 대한 처리 결과이다.(이전 step에서만 처리된 결과)
#결과들을 출력한다.
print(f"output: {output2.shape}, hidden: {hidden2.shape}, cell: {cell2.shape}")
#output: [100:seq개수, 30: batch, 400:hidden크기(유닛수)]----양방향이기 때문에 400개이다.
#hidden: [layer수(1) * 양방향여부(2), batch, hidden 개수]
#cell: [layer수(1) * 양방향여부(2), batch, hidden 개수]출력값
===LSTM: hidden_size(unit수)=200, num_layers=1, bidirectional=False===
output: torch.Size([100, 30, 400]), hidden: torch.Size([2, 30, 200]), cell: torch.Size([2, 30, 200])