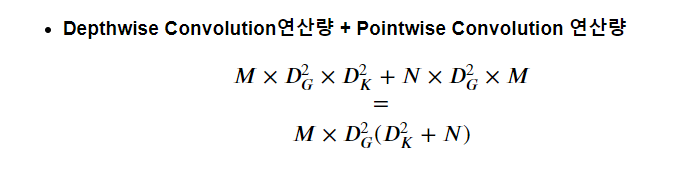1.ImageNet Dataset
페이페리 리 교수가 이끄는 Stanford Vision Lab에서
웹상에서 수집한 약 1500만장의 라벨링된 고해상도 이미지로 약 22,000개
카테고리로 구성된 대규모 이미지 데이터셋이다.
사이트 링크이다.
2.이런 이미지셋과 연관해서 경진대회가 열린다.
바로 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)
대회이다.
mageNet의 이미지중 1000개 카테고리 약 120만장의 학습용이미지, 5만장
의 검증 이미지, 15만장의 테스트 이미지를 이용해 대회를 진행한다.
ILSVRC에서 우승하거나 좋은 성적을 올린 모델들이 컴퓨터 비전분야 발전에
큰 역할을 해왔으며 이후 다양한 Computer Vision 분야의 네트워크 모델
의 백본(backbone)으로 사용되고 있다.
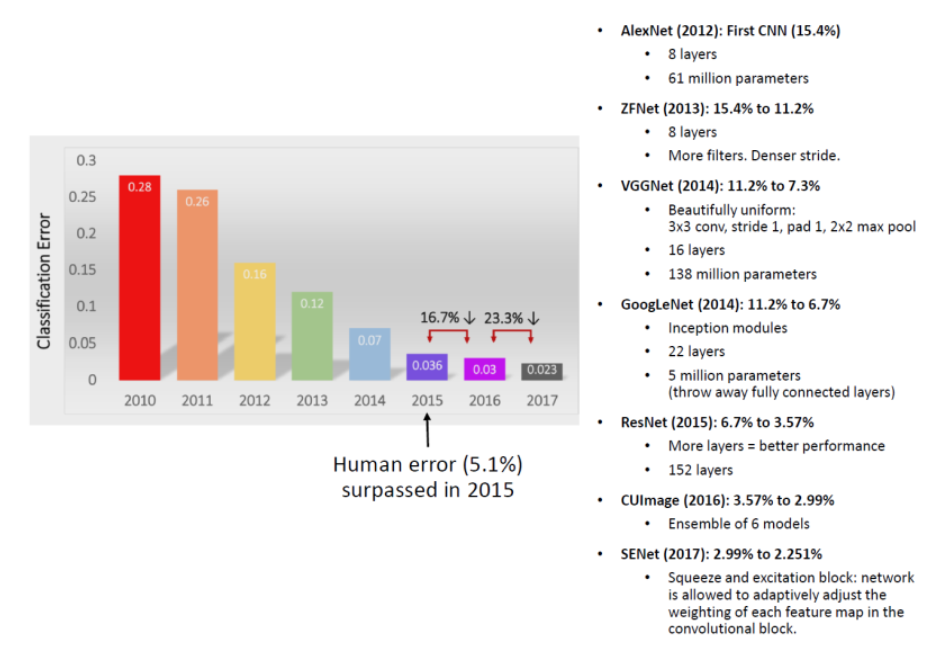
그림을 보면, 시간이 갈 수록 에러율이 떨어지고 있다.
2010년만 보더라도 오류율이 28프로정도였는데,
2017년도를 보면 오류율이 2.3프로 정도로 획기적으로 떨어졌다.
(물론 2017년도 이후로 획기적으로 더 떨어진 경우가 없긴 하다.)
3.VGGNet(VGG16)

캡쳐 사진 중에서 중요한 것은,
'5x5' 하나를 사용하는 것 보다 '3x3' 2개를 사용하는 것이 더 좋다
라는 것이다.
자세한 구조이다.
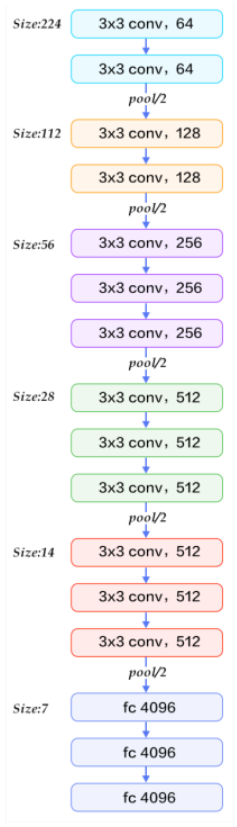
그런데, 구조를 잘 보면, 파라미터 수가 너무 많아졌다는 문제가 있다.
약 1억4천만 개의 parameter(가중치)중 1억 2천만개 정도가 Fully
Connected Layer의 파라미터 이다.
이런 것들이 성능 개선에 문제가 된다.
4.ResNet (Residual Networks)
우리말로 하면 '나머지 네트워크'이다.
2015년 마이크로소프트 리서치 팀에서 제안한 신경망구조로 잔차모듈
(Residual module) 과 skip connection 이라는 구조가 사용되었다.
Skip connection(Shortcut connection)기법을 이용해 Layer수를 획기
적으로 늘린 CNN 모델로 ILSVRC 2015년 대회에서 우승을 차지했다.
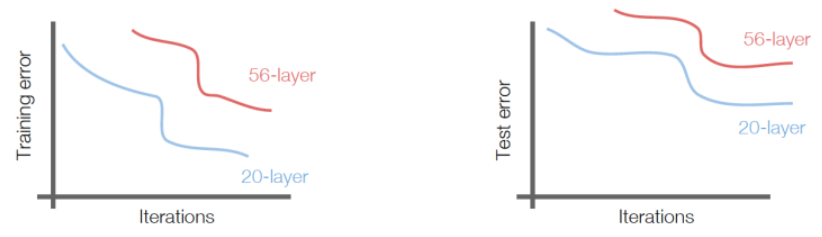
아래 그림을 보면, 레이어의 수가 획기적으로 늘어난 것을 알 수 있다.
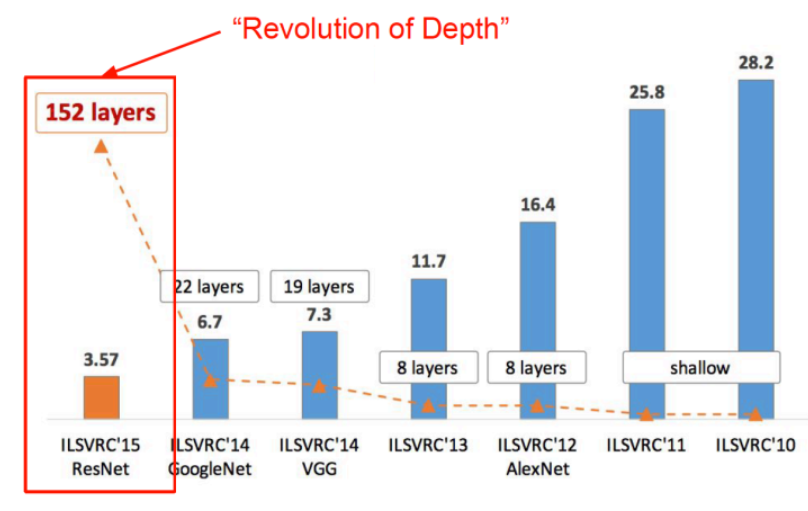
레이어 수가 이렇게 늘어난 것을 보면, 이 생각밖에 안든다.

세상에..... 갑자기 22개에서 152개가 되다니...
자, 다 이유가 있다.
그 이유를 살펴보자.
레이어를 단순히 깊게만 쌓으면, testset, trainset 모두에서 성능이 나
쁘게 나온다. 레이어를 너무 깊게 쌓았더니 최적화
문제가 생긴 것이다.
솔직히 trainset에서도 성능이 좋지 않은 것은 문제가 심했다.
overfitting도 아니고 underfitting이다.
즉, 과적합도 아니고, 그냥
'최적화가 안되었다'
이다.
(이상과현실은다르다.jpg)
그래서, 새로운 아이디어를 냈다.
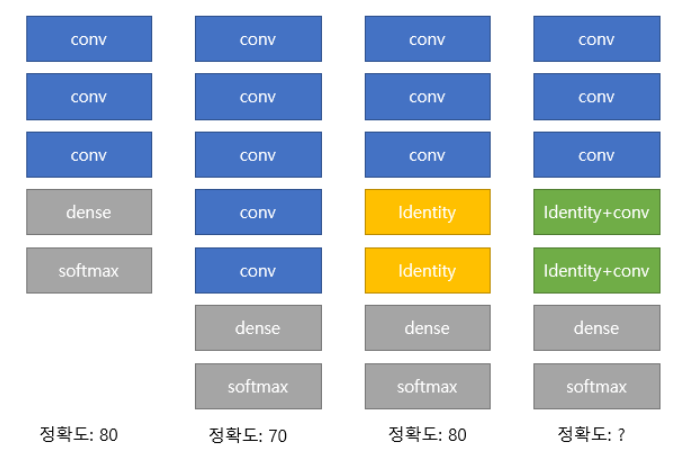
여기서 보면, 입력값을 그대로 출력하는 identity block를 사용하면
성능이 떨어지지 않는다.
그럼 convloution block을 identity block으로 만들면 최소한 성능은
떨어지지 않고 깊은 layer를 쌓을 수 있지 않을까?
4.1.해결책-Residual block
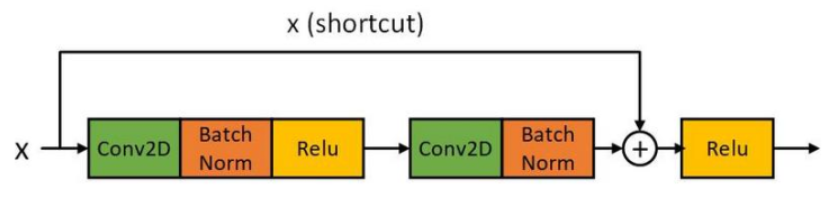
위의 그림처럼, 여러 과정을 거친 값과 원본 x값을 더해서,
그 값을 relu에 더한다.
이런 식으로 최적화를 했더니 최적화가 잘 되었다.
아래 그림에서 왼쪽과 오른쪽을 잘 비교하면 이해가 잘 될 것이다.
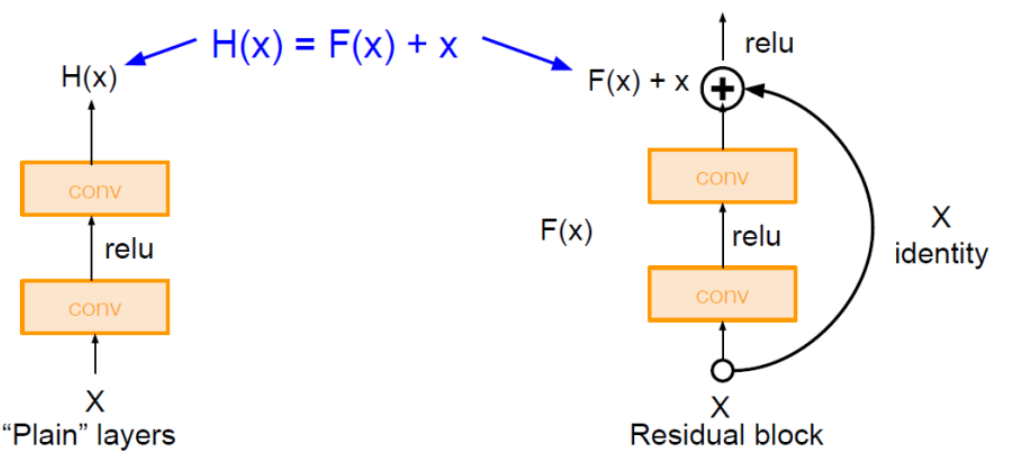
근데, 이렇게 하면 어떤 장점이 있길래 그럴까?
4.2.장점
1.위의 과정을 식으로 표현하면 '𝐻(𝑥)=𝐹(𝑥)+𝑥'이다.
2.이렇게 되면 X가 얼마나 변하면 Y가 되는 지를 푸는 함수로 바뀌게 된다. 전체 모델로 보면 처음 입력 값 X를 최종 출력값 Y가 될 때까지 조금씩 조금씩 변경해 나가는 것이 되어 Layer가 깊더라도 안정적인 학습이 된다.
4.3.성능향상
𝐻(𝑥)=𝐹(𝑥)+𝑥을 𝑥에 대해 미분하면
최소한 1이므로 Gradient Vanishing 문제를 해결한다.
4.4.결과
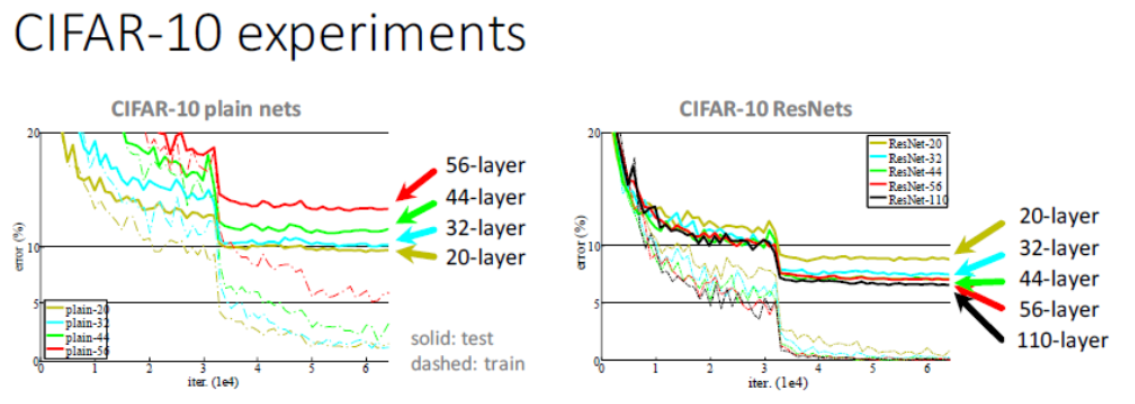
CIFAR-10 ResNets에서는
layer를 많이 쌓은 것이 최적의 결과이다.
그런데, 110개보다 많이 쌓으면 그것도 오류가 난다.
그래도, CIFAR-10보다 개선된 것은 110개보다 더 많이 쌓을 수 있다.
5.MobileNet
근데, 딥러닝이 항상 슈퍼콤뿌따에서 쓰이는 것은 아니다.
스마트폰 같은 환경에서 실행되야 하기도 하다.
그래서, 이런 딥러닝 네트워크를 가볍게 구성하는 방법에 대한 연구가 활성화되었다.
그것과 관련된 것이 바로 MobileNet이다.
저성능 환경에서 실행되기 위해서는 다음과 같은 사항들을 만족시킬 수 있어야 한다.
1.적은 연산량(낮은 계산의 복잡도)을 통한 빠른 실행
2.작은 모델 크기
3.충분히 납득할 만한 정확도
4.저전력 사용
6.Small Deep Neural Network위한 방법
여러가지 방법이 있다.
6.1.Channel Reduction
channel의 개수를 줄인다.
6.2.Distillation & Compression
전자는 큰 모델이 미리 학습한 정보를 작은 모델에 전달하여 성능을 향상시키는 기법이다.
후자는 모델 가지치기 등의 기법을 통해서 네트워크의 크기를 줄이는 기법이다.
6.3.Depthwise Seperable Convolution
Depthwise Convolution과 Pointwise Convolution Layer를 연결한 모델을 구성하여 연산량을 줄인다.
6.4.Remove Fully-Connected Layers
Fully Connected(Dense) Layer들을 Convolution Layer로 대체한다. Convolution Layer는 파라미터를 공유하므로 파라미터 개수가 줄어들어 Network이 경량화된다.
6.5.Kernel Reduction
Kernel(Filter)의 크기를 줄여서 연산량과 파라미터의 수를 줄인다.
6.6.Early Spaced Downsampling
CNN은 Layer block (Conv, pooling)을 거칠수록 output의 size를 줄이는 downsampling을 하게 된다. Downsampling을 초반(bottom)에 크게 하면 네트워크의 크기는 줄어들지만 이미지의 특성을 많이 잃어버리게 되어 성능이 낮아지고, 후반(top)에 많이 하게 되면 성능은 좋아지지만 네트워크의 크기는 크게 줄지 않게 된다. 그래서 전체적으로 균일하게 Downsampling을 하되 그 시점을 튜닝을 통해 찾는다.
(한마디로 '타이밍'을 찾아야 한다는 점이다.)
6.7.결론
Mobilenet은 위의 기법 중 Channel Reduction, Distillation & Compression, Depthwise Seperable Convolution을 적용하여 경량 네트워크를 구현한 모델이다.
7.Depthwise Separable Convolution
Depthwise Convolution 구조에 Pointwise Convolution 구조를 합쳐 기존 Convolution layer보다 연산량을 줄여서 속도를 증가시킨다.
이렇게 하면 속도를 더 증가시킬 수 있다.
8.Depthwise Convolution
자, 위에서는 Depthwise Convolution와 Pointwise Convolution를 같이 쓴다.
그럼, Depthwise Convolution 먼저 알아보자.
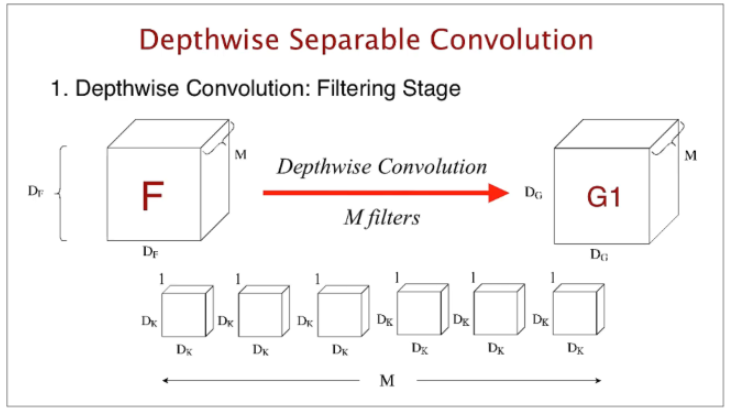
표준 Convolution은 한개의 Filter가 Input의 채널 전체에 대해 Convolution 연산을 한다. 그에 비해 Depthwise Convolution은 한개의 Filter는 한개의 Channel에만 Convolution 연산을 한다.
이렇게 된다면 Feature Map의 크기가 획기적으로 줄어든다.
두개의 그림을 비교해보자.
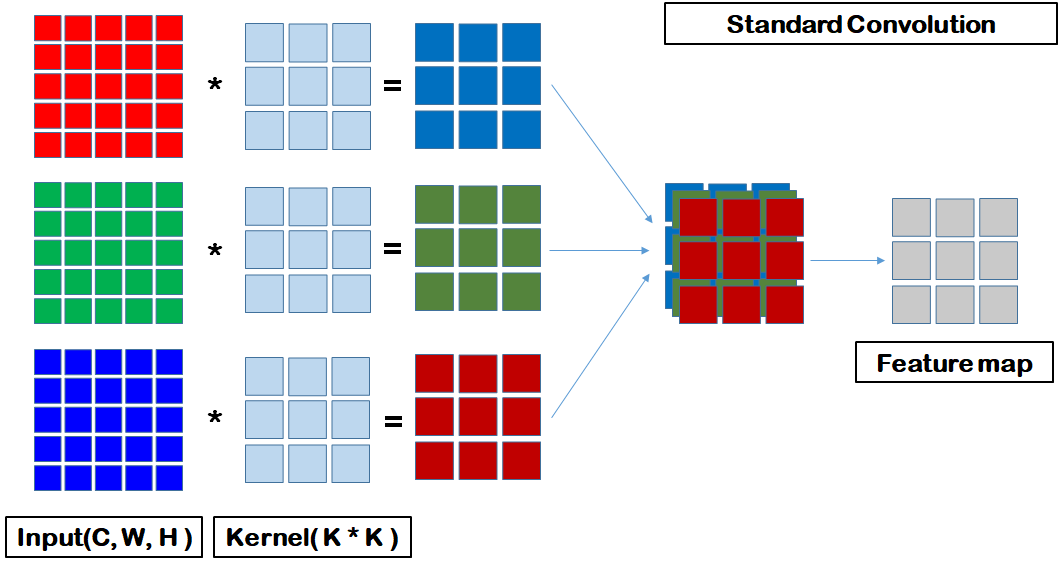
첫번째 그림의 Feature Map의 size를 보자.
Feature Map = Kernel Size x Kernel Size x 3
자, 그럼, 두번째 그림의 Feature Map의 size를 보자.
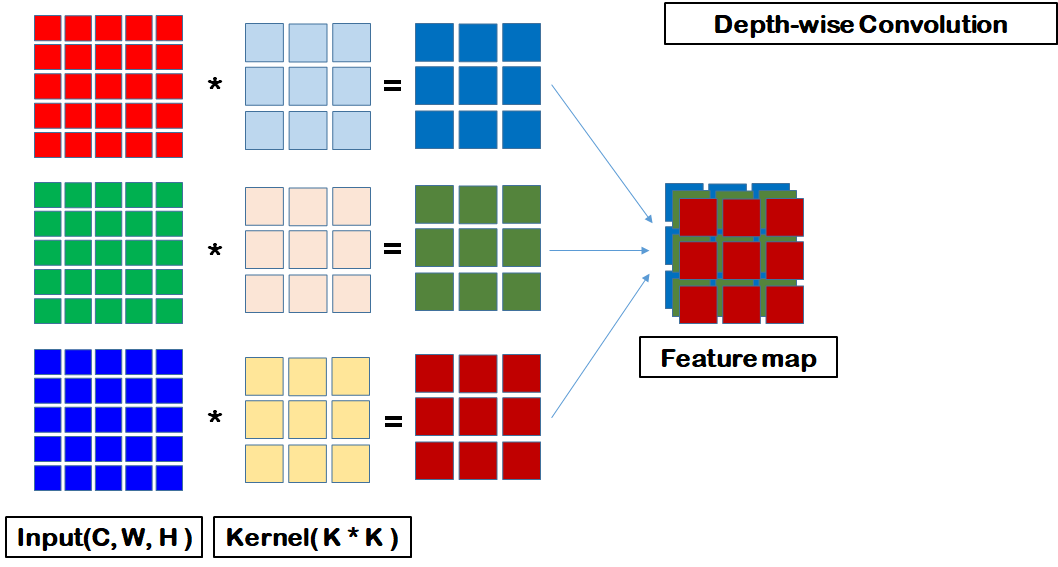
Feature Map = Kernel Size x Kernel Size
가 된다. 한번 통과하면, 하나로 병합되지 않고 (R, G, B)가 각각
Feature Map이 되기 때문이다.
크기가 획기적으로 줄어든다는 것은, 연산량이 획기적으로 줄어든다는 의미이다.
시간이 된다면 이 블로그를 참고하는 것이 좋다.
9.Pointwise Convolution
Pointwise Convolution은 1 X 1 필터를 이용해 Convolution 연산을 처리한다.
Pointwise Convolution을 사용하는 구조를 Bottlenet 이라고 한다.
이 구조는 height와 width를 유지하면서 Channel의 크기를 조절 하기 위하여 사용된다.
위의 설명을 더 자세히 풀면...
채널별로 구해진 feature map을 1x1 kernal Conv 연산으로 하나의channel로 합성을 시킨다.
8번,9번을 그림으로 간략히 한다면 다음과 같다.
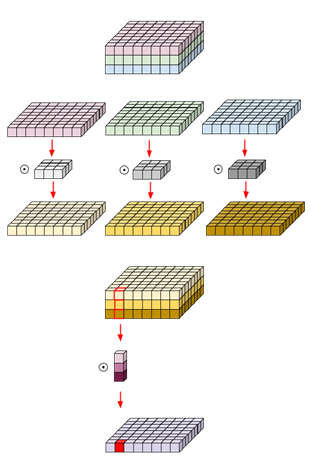
위 두단계의 convolution연산을 이어서 진행 하여 표준 Convolution에
비해 Depthwise convolution으로 연산량을 줄이고 pointwise
convolution으로 출력 결과의 shape은 동일하게 만들어 준다.
10.표준 Convolution과 Depthwise Separable Convolution의 연산량 비교
연산자가 많으니 이해에 시간이 필요할 것이다. 그러나, 중요한 내용이니
이를 잘 이해하도록 하자!
10.1.표준 Convolution 연산
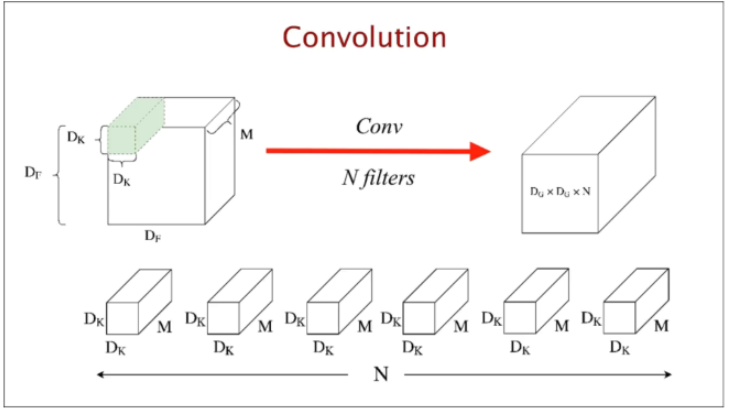
(표준 Convolution 연산에 대한 간략한 그림.)
다음은 input,filter,output등에 대한 정보이다.

위의 정보를 gif으로 나타냈다.
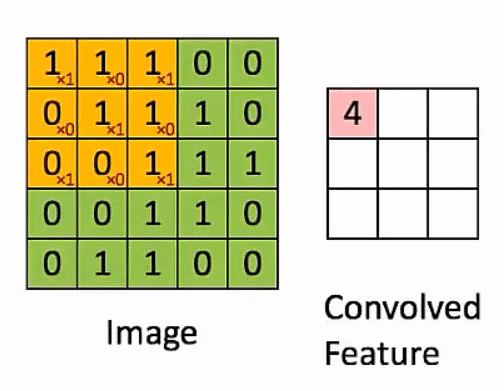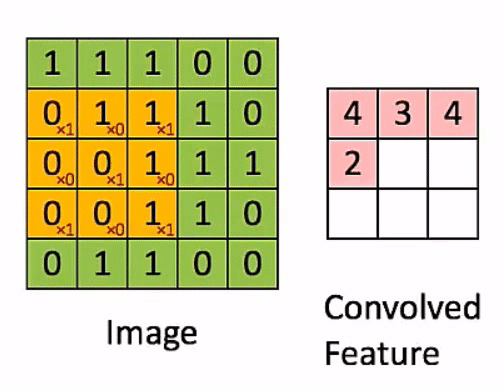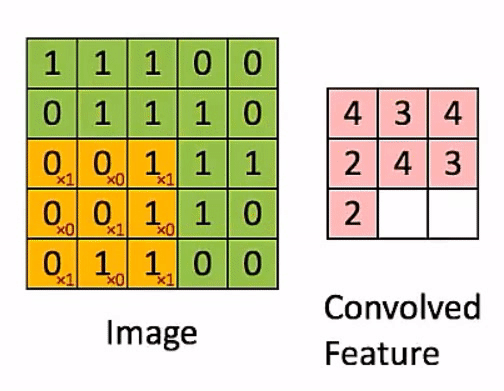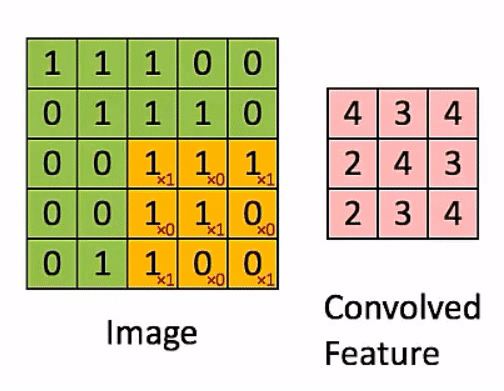

10.2.Depthwise Separable Convolution 연산량