1.Pretrained Model
다른 목적을 위해 미리 학습이 된 모델이다.
그런 것을 내 모델에 전이시키는 것을 Transfer Learning이라고 한다.
대부분 내가 만들려는 네트워크 모델에 pretrained model을 포함시켜서 사용한다.
이렇게 하는 이유는, 딥러닝같은 경우는 업데이트가 굉장히 많이 된다.
그래서 그런 흐름에 올라타기 위해서, 최신 부분을 그냥 따오는 경우가 많다.
그렇기 때문에, Transfer Learning을 쓰는 경우가 많다.
2.Pytorch에서 제공하는 Pretrained Model
우선 파이토치에서도 여러가지를 제공하고 있다.
대표적으로는 hugging face가 있다.
빅데이터계의 플레이스토어 같은 개념이다.

이 사이트를 통해 머신러닝 관련 최신 기술을 쓸 수 있다.
정말이지 위 사진처럼 사이트를 만든 사람을 hug하고 싶어진다.
이 외에도, 파이토치 사이트 자체적으로도 여러가지 모델을을 제공해주기도 한다.
아래는 사이트 링크.
또한, paperswithcode에서 State Of The Art(SOTA) 논문들과 그 구현된 모델을 확인할 수 있다.
State Of The Art(SOTA): 특정 시점에 특정 분야에서 가장 성능이 좋은 모델을 말한다.
아래는 paperswithcode 사이트이다.
이 사이트에서 모델을 검색하면, 여러가지 깃허브 사이트 링크가 뜬다.
그 링크로 가서 설명서를 읽고 그대로 쓰면 된다.
3.VGGNet Pretrained 모델을 이용해 이미지 분류
파이토치가 제공하는 VGG 모델은 ImageNet dataset으로 학습을 시킨 weight을 제공한다.
120만장의 trainset, 1000개의 class으로 구성된 데이터셋이다.
Output으로 1000개의 카테고리에 대한 확률을 출력한다.
꽤 오래된 모델이다. 8년 정도 되었는데, 현재까지도 성능이 매우 좋다.
우선 ImageNet 1000개의 class 목록을 다운로드하자.
이를 하기 위해서, wget이라는 라이브러리를 설치하고 import 하자.
이 코드를 실행할 때, 코드를 1번만 실행해야 파일을 여러번 다운받지 않을 수 있다.
# ImageNet 1000개의 class 목록
#wget이라는 라이브러리를 설치하고 import 한다.
#!pip install wget
import wget
url = 'https://gist.github.com/yrevar/942d3a0ac09ec9e5eb3a/raw/238f720ff059c1f82f368259d1ca4ffa5dd8f9f5/imagenet1000_clsidx_to_labels.txt'
imagenet_filepath = wget.download(url)
#url은 1000개의 클래스를 텍스트로 만든 것이다.
#이 코드를 실행하면, 가상환경에 대상 파일이 다운된 것을 볼 수 있다.아래 사진을 보면, 알맞게 다운이 된 것을 볼 수 있다.

4.이름을 출력하기 위한 코드들이다.
세세한 설명은 코드 안에 적어두었다.
우선 index_to_class라는 dict을 만든다.
with open (imagenet_filepath,"rt") as fr:
index_to_class = eval(fr.read())
#eval이라는 함수: 파이썬코드를 문자열로 넣으면, 알아서 해석해서 실행해준다.
#eval을 통해 index_to_class에 dict 형태로 넣었다.
print(type(index_to_class))그런 다음, 이런 식으로 이름을 출력한다.
#이런 식으로, 이름을 출력할 수 있다.
index_to_class[110]결과값:'flatworm, platyhelminth'
그런 다음, 추론할 이미지를 다운로드한다.
# 추론할 이미지 다운로드
import requests
from io import BytesIO
from PIL import Image
img_url = 'https://upload.wikimedia.org/wikipedia/commons/thumb/2/25/Common_goldfish.JPG/800px-Common_goldfish.JPG'
# img_url = 'https://cdn.download.ams.birds.cornell.edu/api/v1/asset/169231441/1800'
# img_url = 'https://blogs.ifas.ufl.edu/news/files/2021/10/anole-FB.jpg'
res = requests.get(img_url) #url로 요청해서 응답을 받는다. 그 페이지에서 값을 받는 거지.
test_img = Image.open(BytesIO(res.content)) #응답받은 것이 binary 파일일 경우에는 이렇게 한다.
#content 메소드를 통해 컨텐츠만 받는다.
test_img아래는 출력된 이미지이다.

여담으로 img_url을 여러개 적으면, 코드를 출력할 때마다 여러개의 이미지
를 출력받을 수 있다.
5.VGGNet Pretrained 모델을 이용해 이미지 분류-본격적인 코드
VGG19모델을 활용한다.
먼저 load_model_vgg를 정의하고 다운받자.
##torchvision에서 제공하는 Pretrained 모델을 다운로드
#VGG19 모델
#weights:학습된 파라미터들을 같이 다운로드 받는다는 의미이다. Image Net 데이터셋으로 학습한 파라미터를 받는다.
#IMAGENET1K_V1 :Image net 버전1로 학습된 파라미터
#IMAGENET1K_V2 :Image net 버전2로 학습된 파라미터
#모델에 따라서, v2버전을 없을 수 있다.
#models.VGG19_Weights.DEFAULT - 둘 중에 기본 데이터셋으로 설정된 것을 받는다.
load_model_vgg = models.vgg19(weights=models.VGG19_Weights.IMAGENET1K_V1)
다운로드 화면이다.

그 다음은 alex 모델을 통한 download이다.
#alex 모델을 통해서 한번 해보자.
#이 모델은 10여년전에 혜성처럼 나타난 모델인데,
#도태되지 않고 최신 흐름에 따라 계속해서 변화하고 있는 모델이다.
load_model_alex = models.alexnet(weights=models.AlexNet_Weights.DEFAULT)다운로드 화면이다.
그런 다음, model들에 대한 정보를 summary를 통해 보자.
summary(load_model_vgg,(100,3,224,224))아래는 결과이다.
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
VGG [100, 1000] --
├─Sequential: 1-1 [100, 512, 7, 7] --
│ └─Conv2d: 2-1 [100, 64, 224, 224] 1,792
│ └─ReLU: 2-2 [100, 64, 224, 224] --
│ └─Conv2d: 2-3 [100, 64, 224, 224] 36,928
│ └─ReLU: 2-4 [100, 64, 224, 224] --
│ └─MaxPool2d: 2-5 [100, 64, 112, 112] --
│ └─Conv2d: 2-6 [100, 128, 112, 112] 73,856
│ └─ReLU: 2-7 [100, 128, 112, 112] --
│ └─Conv2d: 2-8 [100, 128, 112, 112] 147,584
│ └─ReLU: 2-9 [100, 128, 112, 112] --
│ └─MaxPool2d: 2-10 [100, 128, 56, 56] --
│ └─Conv2d: 2-11 [100, 256, 56, 56] 295,168
│ └─ReLU: 2-12 [100, 256, 56, 56] --
│ └─Conv2d: 2-13 [100, 256, 56, 56] 590,080
│ └─ReLU: 2-14 [100, 256, 56, 56] --
│ └─Conv2d: 2-15 [100, 256, 56, 56] 590,080
│ └─ReLU: 2-16 [100, 256, 56, 56] --
│ └─Conv2d: 2-17 [100, 256, 56, 56] 590,080
│ └─ReLU: 2-18 [100, 256, 56, 56] --
│ └─MaxPool2d: 2-19 [100, 256, 28, 28] --
│ └─Conv2d: 2-20 [100, 512, 28, 28] 1,180,160
│ └─ReLU: 2-21 [100, 512, 28, 28] --
│ └─Conv2d: 2-22 [100, 512, 28, 28] 2,359,808
│ └─ReLU: 2-23 [100, 512, 28, 28] --
│ └─Conv2d: 2-24 [100, 512, 28, 28] 2,359,808
│ └─ReLU: 2-25 [100, 512, 28, 28] --
│ └─Conv2d: 2-26 [100, 512, 28, 28] 2,359,808
│ └─ReLU: 2-27 [100, 512, 28, 28] --
│ └─MaxPool2d: 2-28 [100, 512, 14, 14] --
│ └─Conv2d: 2-29 [100, 512, 14, 14] 2,359,808
│ └─ReLU: 2-30 [100, 512, 14, 14] --
│ └─Conv2d: 2-31 [100, 512, 14, 14] 2,359,808
│ └─ReLU: 2-32 [100, 512, 14, 14] --
│ └─Conv2d: 2-33 [100, 512, 14, 14] 2,359,808
│ └─ReLU: 2-34 [100, 512, 14, 14] --
│ └─Conv2d: 2-35 [100, 512, 14, 14] 2,359,808
│ └─ReLU: 2-36 [100, 512, 14, 14] --
│ └─MaxPool2d: 2-37 [100, 512, 7, 7] --
├─AdaptiveAvgPool2d: 1-2 [100, 512, 7, 7] --
├─Sequential: 1-3 [100, 1000] --
│ └─Linear: 2-38 [100, 4096] 102,764,544
│ └─ReLU: 2-39 [100, 4096] --
│ └─Dropout: 2-40 [100, 4096] --
│ └─Linear: 2-41 [100, 4096] 16,781,312
│ └─ReLU: 2-42 [100, 4096] --
│ └─Dropout: 2-43 [100, 4096] --
│ └─Linear: 2-44 [100, 1000] 4,097,000
==========================================================================================
Total params: 143,667,240
Trainable params: 143,667,240
Non-trainable params: 0
Total mult-adds (T): 1.96
==========================================================================================
Input size (MB): 60.21
Forward/backward pass size (MB): 11889.03
Params size (MB): 574.67
Estimated Total Size (MB): 12523.91
==========================================================================================summary의 핵심은 여러가지 과정을 거쳐, 결국 1000개의 데이터를 출력한
다는 것이다.
또한, channel은 계속 늘어나고, size는 계속 줄어드는 것을 볼 수 있다.
6.이미지 전처리
우선 이미지를 불러오자. 위의 금붕어를 불러오는 코드 부분만 가져온다.
img_url = 'https://upload.wikimedia.org/wikipedia/commons/thumb/2/25/Common_goldfish.JPG/800px-Common_goldfish.JPG'
#img_url = 'https://cdn.download.ams.birds.cornell.edu/api/v1/asset/169231441/1800'
#img_url = 'https://blogs.ifas.ufl.edu/news/files/2021/10/anole-FB.jpg'
#img_url = 'https://i.namu.wiki/i/uk5VsDTA_sXLvqe0Rwj8E678mIj4SkhbUqRyS27TEvVsFVliMwtuO6BpLe9N65IYG5c2XgWndG13sQiReZoz1A.webp'
res = requests.get(img_url) # url로 요청-> 응답 받기.
test_img = Image.open(BytesIO(res.content))
# 응답받은 것이 binary 파일일 경우. BytesIO(binary) => bytes타입 입출력이 가능한 객체.
test_img그런 다음, compose를 통해 resize와 totensor 함수를 정의한다.
#전처리
test_transform = transforms.Compose([
transforms.Resize((224,224),antialias=True),
transforms.ToTensor()
#PIL.Image -> torch.Tensor, 0~1 scaling, channel first 처리
])resize를 한 다음 totensor를 해야 tensor를 통해 데이터를 분석할 수 있다.
위에서 만든 test_transform에 test_img을 넣는다.
그런 다음, 변환된 텐서의 size와 min,max 값 등을 비교한다.
input_data = test_transform(test_img)
#test_img 가 resize가 되고, totensor로 바뀐다.
print(type(input_data),input_data.shape,input_data.min(),input_data.max())
결과는 다음과 같다.
<class 'torch.Tensor'> torch.Size([3, 224, 224]) tensor(0.) tensor(1.)
그런 다음, unsqueeze를 통해 batch 축을 추가한다.
unsqueeze 함수는 차원을 추가해주는 함수이다.
#batch 축을 추가.
input_data = input_data.unsqueeze(dim=0)
input_data.shape이 코드의 결과는 다음과 같다.
torch.Size([1, 3, 224, 224])
7.이미지 전처리의 결과 출력
결과를 출력하기 전에 모델을 device로 이동한다.
이 과정을 하지 않으면 정확도가 획기적으로 떨어진다.
model = load_model_vgg.to(device)그런 다음, input_data도 device로 이동한다.
pred1 = model(input_data.to(device))그런 다음, pred1 값을 출력하면 다음과 같다.
tensor([[ 7.5550e+00, 1.9456e+01, 2.2286e+00, 5.0233e+00, 5.7304e+00,
8.6615e+00, 4.3098e+00, 4.3814e+00, 4.2033e+00, 1.9452e-01,
-2.1743e-01, -1.9233e+00, -2.9189e-01, -2.3287e+00, -1.5496e-01,
4.4604e-01, -1.9084e+00, -2.1240e+00, -3.2998e+00, -2.1678e+00,
-3.5763e+00, 2.4558e+00, 2.0008e+00, -4.2179e-01, -3.4825e+00,
1.7884e-01, 1.0089e+01, 8.2823e+00, 2.8615e+00, 2.1868e+01,
(중략)그런 다음, Softmax에 pred1을 넣어 확률값으로 바꾼다.
추론 결과를 확률로 변환한다.
#Softmax에 pred1을 넣어 확률값으로 바꾼다.
#추론 결과를 확률로 변환한다.
pred_prob1 = torch.nn.Softmax(dim=-1)(pred1)
#추론 label, 확률값을 조회한다.
label1 = pred_prob1.max(dim=-1).indices
prob1 = pred_prob1.max(dim=-1).values
#추론 label을 이용해서 label name을 조회한다.
labelname1 = index_to_class[label1.item()]이제, 결과를 출력한다.
print(label1.item(),labelname1)
print("확률:",prob1.item())결과는 다음과 같이 나온다.
1 goldfish, Carassius auratus
확률: 0.5251456499099731
과연. glodfish는 우리말로 금붕어니까, 이미지 추론이 잘 된 것을 볼 수 있다.
8.전이학습-Transfer learning
전이학습은 사전에 학습된 신경망의 구조와 파라미터를 재사용해서 새로운
모델의 시작점으로 삼고 해결하려는 문제를 위해 다시 학습시키는 것이다.
전이학습을 통해 다음을 해결할 수 있다.
데이터가 부족한 문제를 해결할 수 있고,
가장 중요한 것은
적은 노력으로 좋은 성능의 모델을 쉽게 만들 수 있다.
그래서, 전이학습을 많이 이용한다.
9.자세한 설명
기존의 모델이 있으면, 그 중 일부의 layer를 버리고
버린 부분을 새로운 부분으로 대체한다.
그리고, 그 일부 부분만 새로 학습을 한다.
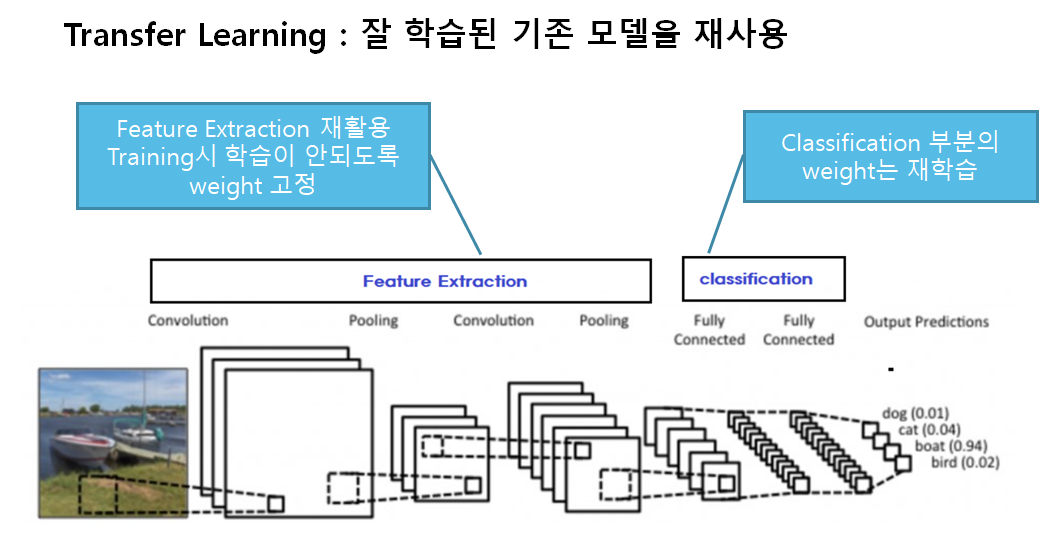
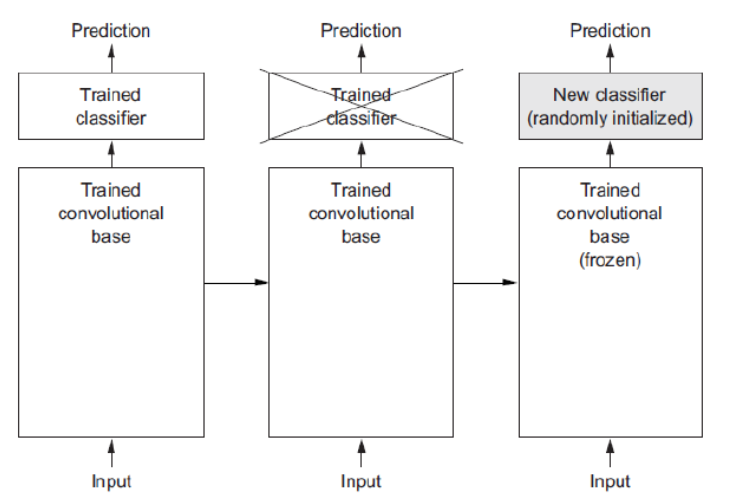
위의 그림을 보면, 두번째 classifier가 가위표가 쳐져있고,
그 옆에는 new classifier가 있다.
이는 일부를 버리고 새로운 부분을 학습한다는 것을 보여준다.
10.Feature extraction 재사용
Pretrained Model에서 Feature Extractor만 가져오고 추론기만 새로
정의한 뒤 그 둘을 합쳐서 모델을 만드는 것이다.
이와 관련된 용어가 바로 Backbone, Base network라고 한다.
전체 네트워크에서 Feature extraction의 역활을 담당하는 부분이다.
딥러닝에서 'Backbone으로는 뭐를 썼고...'라는 말이 많이 나오는데,
여기에서 나온 말이다.
11.fine-tuning (미세조정)
fine tuning은 원래는 학습을 시키지 않는 Pretrained 모델을
내가 학습시켜야 하는 데이터셋으로 재학습시키는 것이다.
이 때, 수정은 하는데 그렇게 많이 수정하지는 않는다.
그래서, 튜닝이라는 용어를 쓰고, 미세조정이라는 말을 쓰는 것이다.
물론, Feature Extractor의 가중치들도 조정 한다.
fine-tuning에 관한 전략은 다음과 같다.
총 3가지 전략이 있다.
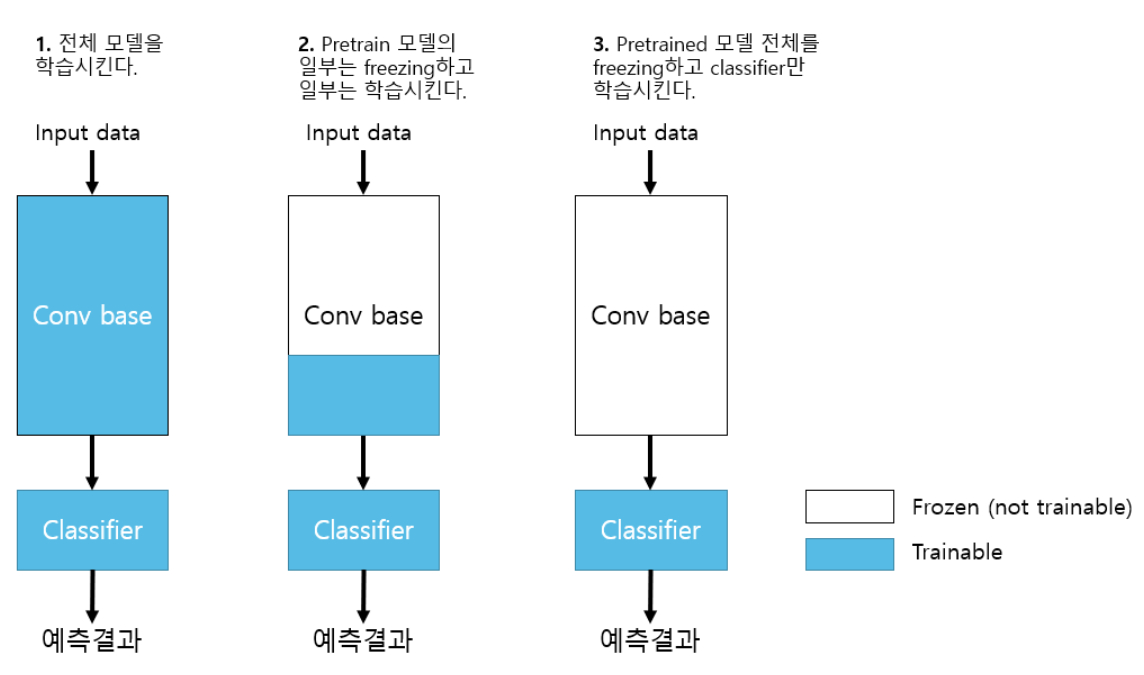
각 전략에는 조건이 있다.
12.각 조건에 대한 표이다.

참고로, pretrain dataset 말고, 내가 학습시키고자 하는 dataset을
Custom dataset이라고 한다.
표를 보면 이해가 잘 가지만,
데이터간 유사도도 적고 적은 데이터셋을 쓸 때는 2번 전략을 쓰는 것을
유의하자.
데이터가 적으면 최대한 tuning을 안하는 것이 좋지만(성능이 떨어질 가능
성이 있으니까),
데이터셋 자체가 작기 때문에 일부분이라도 튜닝을 해서 더 높은 정확도를
노리는 것이다.
13.본격적인 코드
우선 결과를 출력해주는 코드를 짠다.
%%writefile module/utils.py
#위의 줄은 파일을 따로 만들어 덮어씌우는 것이다.
import matplotlib.pyplot as plt
def plot_fit_result(train_loss_list,train_acc_list,val_loss_list,val_acc_list):
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
plt.title("Loss")
plt.plot(train_loss_iist,label="Train")
plt.plot(val_loss_iist,label="Validation")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.subplot(1,2,2)
plt.title("Accuracy")
plt.plot(train_acc_list,label="Train")
plt.plot(val_acc_list,label="Validation")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.tight_layout()
plt.show()그런 다음 import을 한다.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models, datasets, transforms
from torchinfo import summary
from module.train import fit
from module.utils import plot_fit_result
import os
from zipfile import ZipFile
!pip install gdown -U
import gdown
device = 'cuda' if torch.cuda.is_available() else "cpu"
device그런 다음, download를 위한 코드를 작성한다.
# download
url = 'https://drive.google.com/uc?id=1YIxDL0XJhhAMdScdRUfDgccAqyCw5-ZV'
path = r'data/cats_and_dogs_small.zip'
gdown.download(url, path, quiet=False)이 코드에 따르면, 주피터 노트북에서 data파일 밑에 zip파일이 다운받아진다.

다음은 압축을 푸는 과정이다.
#압축 풀기 - zip
image_path = os.path.join("datasets","cats_and_dogs_small") #압축 풀 경로
with ZipFile(path) as zfile: #Zipfile(압축파일경로)
zfile.extractall(image_path) #extractall(압축 풀 디렉토리 경로) #경로 생략-현재 dir에 푼다.
위와 같이 압축을 풀면, 실제로 압축이 풀려서 폴더가 생긴다.
14.Dataset,Dataloader 생성
우선 train_transform을 생성하자.
#transform 정의
#Trainset: Image augmentation + Resize + ToTensor
train_transform = transforms.Compose([
transforms.Resize((224,224)), #Image Net 학습 모델: input size:224*224
# 상수 -> 1-상수 ~1+상수 범위에서 변환.
transforms.ColorJitter(brightness=0.3,contrast=0.3,saturation=0.5,hue=0.15)
transforms.RandomHorizontalFlip(), #p=0.5(default)
transforms.RandomVerticalFlip(),
transforms.RandomRotation(degrees=90) #-90~+90 범위에서 회전.
transforms.ToTensor(),
transforms.Normalize((0.485,0.456,0.406),(0.229,0.224,0.225))
#채널별:(평균),(표준편차) #(각 픽셀값-평균)/표준편차
#위의 주석과 같은 정보를 토대로 정규화를 한다.
])그런 다음, test_transform을 생성하자.
유의할 것은, 우리는 '성능'을 예측하는 것이기 때문에, 이미지를 굳이 변
형시킬 필요가 없다는 것이다.
test_transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize((0.485,0.456,0.406),(0.229,0.224,0.225))
])그런 다음 dataset을 정의한다.
#dataset
train_set = datasets.ImageFolder(os.path.join(image_path,"train"),transform=train_transform)
#path.join을 통해 경로를 붙여준다.
valid_set = datasets.ImageFolder(os.path.join(image_path,"validation"),transform=test_transform)
test_Set = datasets.ImageFolder(os.path.join(image_path,"test"),transform=test_transform)
#train만 train_transform을 쓰고 나머지는 다 test_transform이다.
그런 다음, 하이퍼파라미터와 dataloader를 생성한다.
##하이퍼파라미터 정의
BATCH_SIZE = 256
N_EPOCH = 1
LR=0.001dataloader를 정의하게 전에 유의해야 할 것이 있다.
dataloader를 정의할 때,
os.cpu_count()
함수를 통해 cpu를 세고 그 수만큼 코드를 돌릴 건데,
full로 돌린다면, 코드를 돌리면서 유튜브는 볼 수 없다.
dataloader의 코드이다.
###DataLoader
#num_workers는 data를 load와 함께 병렬 처리하겠다는 것이다.
train_loader = DataLoader(train_set,batch_size=BATCH_SIZE,drop_last=True,
shuffle=True, num_workers=os.cpu_count())
#data를 load할 때 병렬처리하겠다. => 한번에 몇개씩 동시에 loading할지.
#os.cpu_count() ->cpu 프로세서 개수
#근데, 프로세서 개수를 풀로 돌릴 경우, 코드를 실행하면서 유튜브를 보는 것은 안된다.
valid_loader = DataLoader(valid_set,batch_size=BATCH_SIZE,num_workers=os.cpu_count())
valid_loader = DataLoader(test_set,batch_size=BATCH_SIZE,num_workers=os.cpu_count())
아래는 데이터 확인용 코드들이다. 코드를 확인하면 아래와 같은 이미지를 볼 수 있다.
15.pretrained 모델 가져오기
먼저 vgg19 모델을 가져온다.
model = models.vgg19(weights=models.VGG19_Weights.DEFAULT)
그런 다음 파라미터를 확인한다.
###파라미터 확인 - trainable상태를 확인한다.
for param in model.parameters():
print(param.shape,param.requires_grad) #채널:3개, 사이즈:3*3, 개수:64
#bias:64개
#위 순서대로 우리에게 주는 것이다.
# break그런 다음 parameter를 학습이 안되도록 한다.
#parameter를 frozen =>학습이 안되도록 한다.
#방법:requires_grad를 모두 false로 바꾼다.
for param in model.parameters():#model.parameters 함수에 관한 것을 잘 파악하자.
param.requires_grad = False for param in model.parameters():
print(param.requires_grad)이 코드를 돌리면 결과값이 모두 false가 된다.
16.summary
#summary하기
summary(model,(1,3,224,224))
#유의깊게 봐야할 것은 Trainable params가 0개라는 것이다.밑은 출력값이다. Trainable params의 값을 잘 보자.
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
VGG [1, 1000] --
├─Sequential: 1-1 [1, 512, 7, 7] --
│ └─Conv2d: 2-1 [1, 64, 224, 224] (1,792)
│ └─ReLU: 2-2 [1, 64, 224, 224] --
│ └─Conv2d: 2-3 [1, 64, 224, 224] (36,928)
│ └─ReLU: 2-4 [1, 64, 224, 224] --
│ └─MaxPool2d: 2-5 [1, 64, 112, 112] --
│ └─Conv2d: 2-6 [1, 128, 112, 112] (73,856)
│ └─ReLU: 2-7 [1, 128, 112, 112] --
│ └─Conv2d: 2-8 [1, 128, 112, 112] (147,584)
│ └─ReLU: 2-9 [1, 128, 112, 112] --
│ └─MaxPool2d: 2-10 [1, 128, 56, 56] --
│ └─Conv2d: 2-11 [1, 256, 56, 56] (295,168)
│ └─ReLU: 2-12 [1, 256, 56, 56] --
│ └─Conv2d: 2-13 [1, 256, 56, 56] (590,080)
│ └─ReLU: 2-14 [1, 256, 56, 56] --
│ └─Conv2d: 2-15 [1, 256, 56, 56] (590,080)
│ └─ReLU: 2-16 [1, 256, 56, 56] --
│ └─Conv2d: 2-17 [1, 256, 56, 56] (590,080)
│ └─ReLU: 2-18 [1, 256, 56, 56] --
│ └─MaxPool2d: 2-19 [1, 256, 28, 28] --
│ └─Conv2d: 2-20 [1, 512, 28, 28] (1,180,160)
│ └─ReLU: 2-21 [1, 512, 28, 28] --
│ └─Conv2d: 2-22 [1, 512, 28, 28] (2,359,808)
│ └─ReLU: 2-23 [1, 512, 28, 28] --
│ └─Conv2d: 2-24 [1, 512, 28, 28] (2,359,808)
│ └─ReLU: 2-25 [1, 512, 28, 28] --
│ └─Conv2d: 2-26 [1, 512, 28, 28] (2,359,808)
│ └─ReLU: 2-27 [1, 512, 28, 28] --
│ └─MaxPool2d: 2-28 [1, 512, 14, 14] --
│ └─Conv2d: 2-29 [1, 512, 14, 14] (2,359,808)
│ └─ReLU: 2-30 [1, 512, 14, 14] --
│ └─Conv2d: 2-31 [1, 512, 14, 14] (2,359,808)
│ └─ReLU: 2-32 [1, 512, 14, 14] --
│ └─Conv2d: 2-33 [1, 512, 14, 14] (2,359,808)
│ └─ReLU: 2-34 [1, 512, 14, 14] --
│ └─Conv2d: 2-35 [1, 512, 14, 14] (2,359,808)
│ └─ReLU: 2-36 [1, 512, 14, 14] --
│ └─MaxPool2d: 2-37 [1, 512, 7, 7] --
├─AdaptiveAvgPool2d: 1-2 [1, 512, 7, 7] --
├─Sequential: 1-3 [1, 1000] --
│ └─Linear: 2-38 [1, 4096] (102,764,544)
│ └─ReLU: 2-39 [1, 4096] --
│ └─Dropout: 2-40 [1, 4096] --
│ └─Linear: 2-41 [1, 4096] (16,781,312)
│ └─ReLU: 2-42 [1, 4096] --
│ └─Dropout: 2-43 [1, 4096] --
│ └─Linear: 2-44 [1, 1000] (4,097,000)
==========================================================================================
Total params: 143,667,240
Trainable params: 0
Non-trainable params: 143,667,240
Total mult-adds (G): 19.65
==========================================================================================
Input size (MB): 0.60
Forward/backward pass size (MB): 118.89
Params size (MB): 574.67
Estimated Total Size (MB): 694.16
==========================================================================================17.classifer를 정의해서 model에 추가한다.
#classifer를 정의해서 model에 추가한다.
#VGG19의 attribute 변수 classifier 추론기가 정의설정되어 있는 상태.
## =>새로운 추론기(개/고양이 분류)를 정의한 뒤 classifier attribute 변수에 할당한다.
model.classifier = nn.Sequential(
nn.Linear(512*7*7,4096),
nn.ReLU(),
nn.Dropout(p=0.3),
nn.Linear(4096,4096),
nn.ReLU(),
nn.Dropout(p=0.3),
nn.Linear(4096,2) #개/고양이 두개 class를 분류한다. 그래서 out을 2로 한다.
)
그런 다음, summary를 통해 정보를 파악한다.
#summary를 통해 정보를 파악한다.
#summary를 통해 보면, 학습이 되는 부분이 있고 안되는 부분이 있다는 사실을 잘 파악하자.
summary(model,(1,3,224,224))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
VGG [1, 2] --
├─Sequential: 1-1 [1, 512, 7, 7] --
│ └─Conv2d: 2-1 [1, 64, 224, 224] (1,792)
│ └─ReLU: 2-2 [1, 64, 224, 224] --
│ └─Conv2d: 2-3 [1, 64, 224, 224] (36,928)
│ └─ReLU: 2-4 [1, 64, 224, 224] --
│ └─MaxPool2d: 2-5 [1, 64, 112, 112] --
│ └─Conv2d: 2-6 [1, 128, 112, 112] (73,856)
│ └─ReLU: 2-7 [1, 128, 112, 112] --
│ └─Conv2d: 2-8 [1, 128, 112, 112] (147,584)
│ └─ReLU: 2-9 [1, 128, 112, 112] --
│ └─MaxPool2d: 2-10 [1, 128, 56, 56] --
│ └─Conv2d: 2-11 [1, 256, 56, 56] (295,168)
│ └─ReLU: 2-12 [1, 256, 56, 56] --
│ └─Conv2d: 2-13 [1, 256, 56, 56] (590,080)
│ └─ReLU: 2-14 [1, 256, 56, 56] --
│ └─Conv2d: 2-15 [1, 256, 56, 56] (590,080)
│ └─ReLU: 2-16 [1, 256, 56, 56] --
│ └─Conv2d: 2-17 [1, 256, 56, 56] (590,080)
│ └─ReLU: 2-18 [1, 256, 56, 56] --
│ └─MaxPool2d: 2-19 [1, 256, 28, 28] --
│ └─Conv2d: 2-20 [1, 512, 28, 28] (1,180,160)
│ └─ReLU: 2-21 [1, 512, 28, 28] --
│ └─Conv2d: 2-22 [1, 512, 28, 28] (2,359,808)
│ └─ReLU: 2-23 [1, 512, 28, 28] --
│ └─Conv2d: 2-24 [1, 512, 28, 28] (2,359,808)
│ └─ReLU: 2-25 [1, 512, 28, 28] --
│ └─Conv2d: 2-26 [1, 512, 28, 28] (2,359,808)
│ └─ReLU: 2-27 [1, 512, 28, 28] --
│ └─MaxPool2d: 2-28 [1, 512, 14, 14] --
│ └─Conv2d: 2-29 [1, 512, 14, 14] (2,359,808)
│ └─ReLU: 2-30 [1, 512, 14, 14] --
│ └─Conv2d: 2-31 [1, 512, 14, 14] (2,359,808)
│ └─ReLU: 2-32 [1, 512, 14, 14] --
│ └─Conv2d: 2-33 [1, 512, 14, 14] (2,359,808)
│ └─ReLU: 2-34 [1, 512, 14, 14] --
│ └─Conv2d: 2-35 [1, 512, 14, 14] (2,359,808)
│ └─ReLU: 2-36 [1, 512, 14, 14] --
│ └─MaxPool2d: 2-37 [1, 512, 7, 7] --
├─AdaptiveAvgPool2d: 1-2 [1, 512, 7, 7] --
├─Sequential: 1-3 [1, 2] --
│ └─Linear: 2-38 [1, 4096] 102,764,544
│ └─ReLU: 2-39 [1, 4096] --
│ └─Dropout: 2-40 [1, 4096] --
│ └─Linear: 2-41 [1, 4096] 16,781,312
│ └─ReLU: 2-42 [1, 4096] --
│ └─Dropout: 2-43 [1, 4096] --
│ └─Linear: 2-44 [1, 2] 8,194
==========================================================================================
Total params: 139,578,434
Trainable params: 119,554,050
Non-trainable params: 20,024,384
Total mult-adds (G): 19.64
==========================================================================================
Input size (MB): 0.60
Forward/backward pass size (MB): 118.88
Params size (MB): 558.31
Estimated Total Size (MB): 677.80
==========================================================================================18.학습
##학습시키기
model = model.to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),lr=LR)
result = fit(train_loader,valid_loader,model,loss_fn,optimizer,N_EPOCH,
save_best_model=False,device=device,mode="multi")19.코드들을 구글 드라이브에 올리기
지금까지 한 코드를 구글 드라이브에 업로드한다.

그런 다음 colab으로 연다.
유의해야 할 것은, 이미 설치했던 라이브러리를 깔거나, 파일을 또 만들어야 한다는 점이다. 애초에 다른 환경에서 실행하니까 당연하다.
colab으로 옮길 때, model_save_path을 따로 지정하는 것을 잊지 말자.
다음은 colab으로 했을 때의 코드이다.
##학습시키기
#save_best_model을 True로 해서 파일을 저장한다. 그런 다음, model_save_path을 통해 경로를 지정한다.
model_save_path = "/content/drive/MyDrive/pytorch/models/cat_dog_model1.pth"
model = model.to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),lr=LR)
result = fit(train_loader,valid_loader,model,loss_fn,optimizer,N_EPOCH,save_model_path=model_save_path,
save_best_model=True,device=device,mode="multi")
결과는 다음과 같다.
Epoch[1/20] - Train loss: 0.67309 Train Accucracy: 0.45150 || Validation Loss: 0.51342 Validation Accuracy: 0.50600
====================================================================================================
저장: 1 - 이전 : inf, 현재: 0.5134203457273543
Epoch[2/20] - Train loss: 0.45222 Train Accucracy: 0.68900 || Validation Loss: 0.07140 Validation Accuracy: 0.97200
====================================================================================================
저장: 2 - 이전 : 0.5134203457273543, 현재: 0.07139905821532011
Epoch[3/20] - Train loss: 0.27646 Train Accucracy: 0.78700 || Validation Loss: 0.04739 Validation Accuracy: 0.98600
====================================================================================================
저장: 3 - 이전 : 0.07139905821532011, 현재: 0.04738660389557481
Epoch[4/20] - Train loss: 0.27583 Train Accucracy: 0.78400 || Validation Loss: 0.05063 Validation Accuracy: 0.98500
====================================================================================================
Epoch[5/20] - Train loss: 0.23353 Train Accucracy: 0.79900 || Validation Loss: 0.06130 Validation Accuracy: 0.98100
====================================================================================================
Epoch[6/20] - Train loss: 0.24804 Train Accucracy: 0.80000 || Validation Loss: 0.06732 Validation Accuracy: 0.98200
====================================================================================================
Epoch[7/20] - Train loss: 0.22372 Train Accucracy: 0.81150 || Validation Loss: 0.05885 Validation Accuracy: 0.98100
====================================================================================================
Epoch[8/20] - Train loss: 0.23593 Train Accucracy: 0.80050 || Validation Loss: 0.06645 Validation Accuracy: 0.98200
====================================================================================================
Epoch[9/20] - Train loss: 0.22132 Train Accucracy: 0.81450 || Validation Loss: 0.06342 Validation Accuracy: 0.98100
====================================================================================================
Epoch[10/20] - Train loss: 0.20517 Train Accucracy: 0.81650 || Validation Loss: 0.06533 Validation Accuracy: 0.98300
====================================================================================================
Epoch[11/20] - Train loss: 0.20931 Train Accucracy: 0.81950 || Validation Loss: 0.08246 Validation Accuracy: 0.98000
====================================================================================================
Epoch[12/20] - Train loss: 0.19672 Train Accucracy: 0.82050 || Validation Loss: 0.06091 Validation Accuracy: 0.97900
====================================================================================================
Epoch[13/20] - Train loss: 0.19738 Train Accucracy: 0.81750 || Validation Loss: 0.07300 Validation Accuracy: 0.98100
====================================================================================================
Early stopping: Epoch - 12
611.5815060138702 초특징적인 것은, train 정확도가 조금 떨어진다.
valid는 정확한데 말이다.
이는 image augmentation 때문이다.
계속해서 새로운 것을 학습하니까... 반복하지는 못하니까 정확도가
떨어질 수 밖에 없다.
20.testset으로 검증.
#테스트셋으로 검증한다.
from module.train import test_multi_classification
best_model = torch.load(model_save_path)loss, acc = test_multi_classification(test_loader,best_model,loss_fn,device=device)
print(loss,acc) #최종검증!출력값이 나온다.
0.04738660389557481 0.986
결과적으로, 정확도가 많이 개선이 된 것을 볼 수 있다.
21.Backbone의 일부를 fine tuning
Top(출력)쪽의 레이어들을 tuning한다.
다른과정은 다 동일하다.(import, 파일 지정, 압축 풀기 등)
우리가 봐야 할 것은,
일부분만 잘라서 데이터를 조회한다는 것이다.
일부분 봐야 할 부분만 코드를 따 왔으니, 이 설명만 잘 보면 된다.
1.우선 model2를 따로 정의하고, 정보를 출력한다.
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(17): ReLU(inplace=True)
(18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(19): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(24): ReLU(inplace=True)
(25): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(26): ReLU(inplace=True)
(27): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): ReLU(inplace=True)
(32): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(33): ReLU(inplace=True)
(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(35): ReLU(inplace=True)
(36): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)우리는 0-36 중에서 대부분을 frozen 할 것이고, 나머지만 쓸 것이다.
아래는 그 코드.
#conv base(backbone) layer를 조회->0 ~ 36 중에서 0~29:frozon,30~36:trainable을 한다고 가정한다.
for idx, layer in enumerate(model2.features): #안의 함수들을 하나하나 뽑아낸다.
#print(idx,type(layer))
if idx<30:
#frozen
for param in layer.parameters():
#model.parameters(), layer.parameters() -> 구성 weight, bias를 반환하는 generator이다.
print(param.shape)
print("---------------")
#grad를 false로 만든다.
param.requires_grad = False결과를 보자.
for i,p in enumerate(model2.parameters()):
print(i,p.requires_grad)#결과
0 False
1 False
2 False
3 False
4 False
5 False
6 False
7 False
8 False
9 False
10 False
11 False
12 False
13 False
14 False
15 False
16 False
17 False
18 False
19 False
20 False
21 False
22 False
23 False
24 False
25 False
26 True
27 True
28 True
29 True
30 True
31 True
32 True
33 True
34 True
35 True
36 True
37 True2.classifier를 변경한다.
model2.classifier = nn.Sequential(
nn.Linear(512*7*7,4096),
nn.ReLU(),
nn.Dropout(p=0.3),
nn.Linear(4096,4096),
nn.Dropout(p=0.3),
nn.Linear(4096,2)
)3.그런 다음 손실함수나 옵티마이저를 설정한 뒤, 학습시킨다.
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model2.parameters(),lr=LR)
##학습시키기
model_save_path = "/content/drive/MyDrive/pytorch/models/cat_dog_model2.pth"
model2 = model2.to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model2.parameters(),lr=LR)
result = fit(train_loader,valid_loader,model2,loss_fn,optimizer,N_EPOCH,
save_best_model=False,device=device,mode="multi")
이렇게 학습을 하면, 일부분만 학습이 되며,
validation 정확도는 98프로 정도 나온다.
결국, 정확도에 큰 차이는 없지만,
그래도 조금은 나아지는 경향이 있다.
