1.우선 roboflow를 설치를 한다.
계정을 만들고, universe에 간다.
그런 다음 project 페이지에 간다.
거기에서 프로젝트 공간을 만든다.
2.프로젝트 만들기
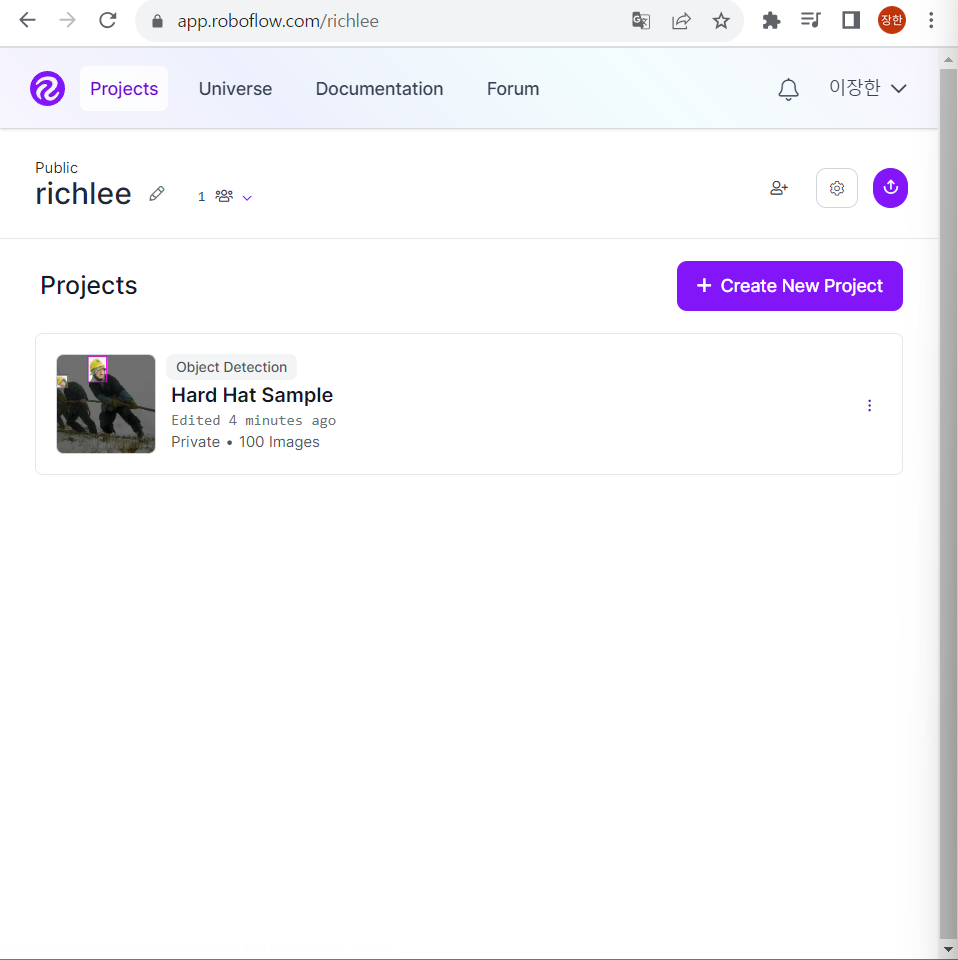
여기서 create new project를 만든다.
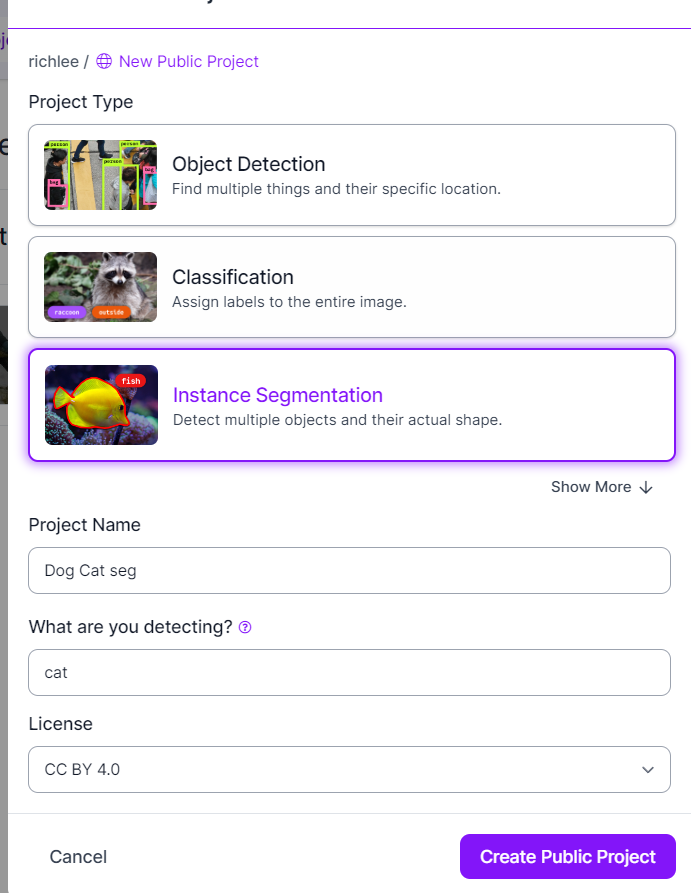
이렇게 설정을 한 다음, 개나 고양이의 사진들을 올린다.
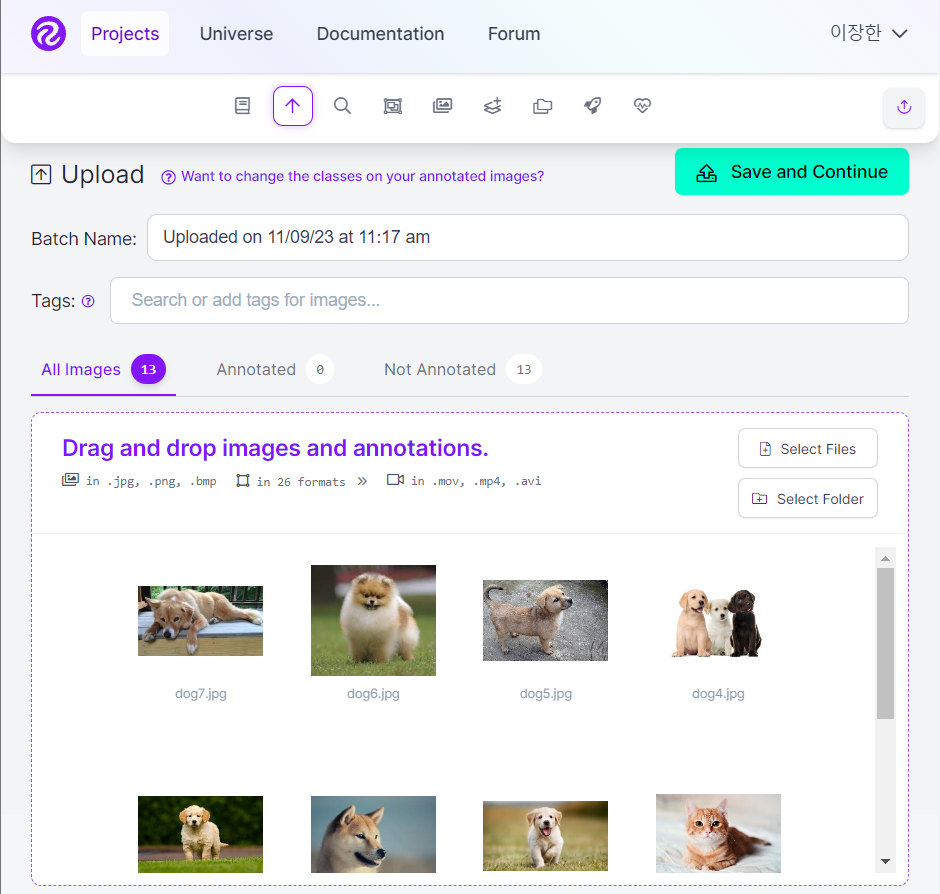
3.이미지를 클릭하면, 이미지의 어떤 부분을 집중할까 포커스를 잡아줘야 한다.
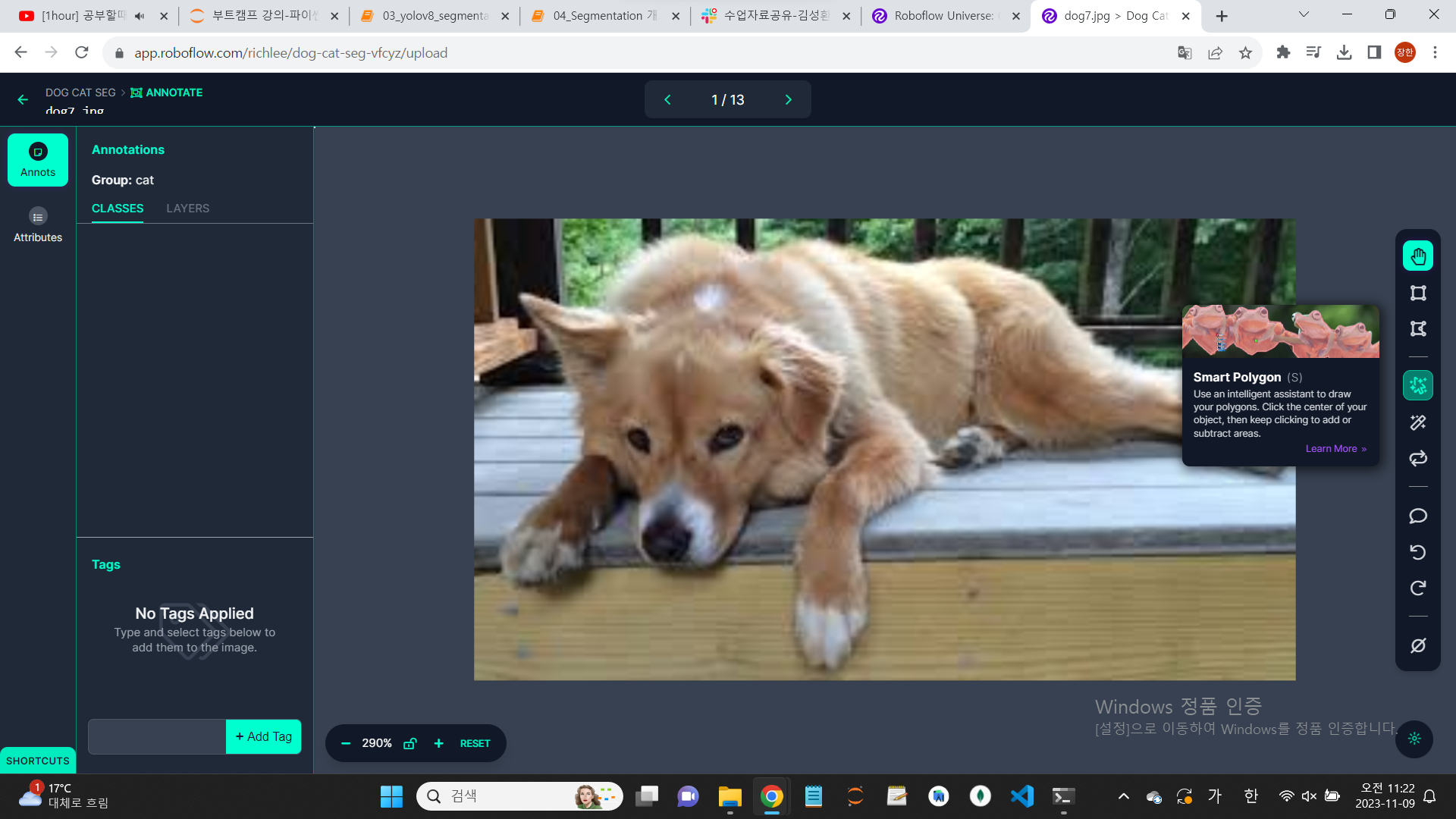
캡쳐 사진의 smart ploygon을 클릭하면, 더 쉽게 영역을 잡을 수 있다.
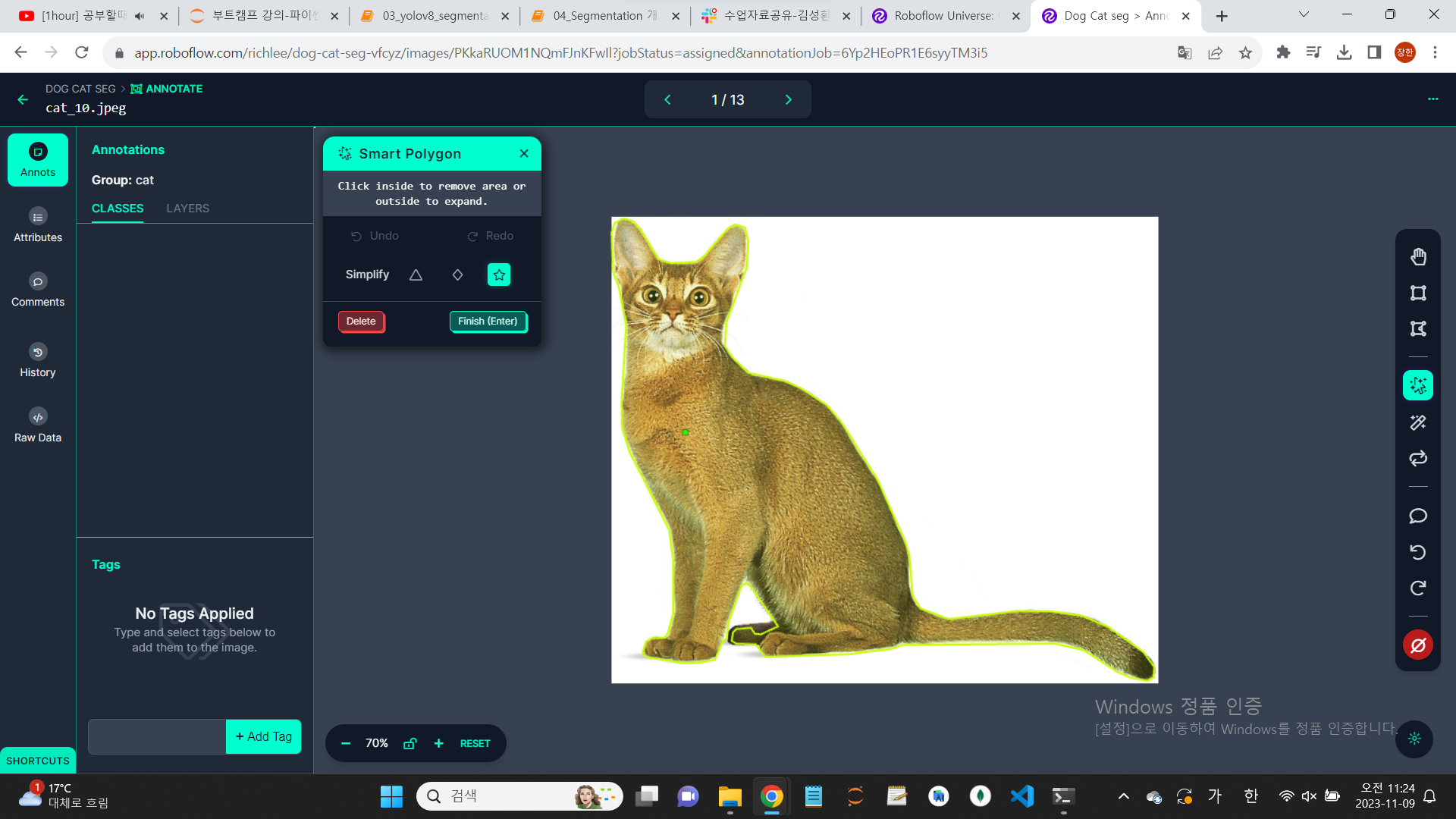
enter를 클릭하면, 자동으로 영역이 설정된다.
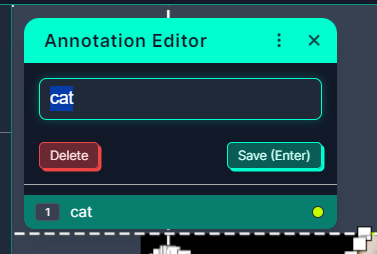
영역 설정 전에, 이런 식으로 데이터를 라벨링 해야 한다.
자, 다른 이미지들도 이런 식으로 데이터를 라벨링(annotate)해야 한다.
4.마무리, 다운로드
라벨링을 마무리 했다면, yolov8로 파일을 다운로드 한다.
(export data를 해야 한다. 혼동주의!)
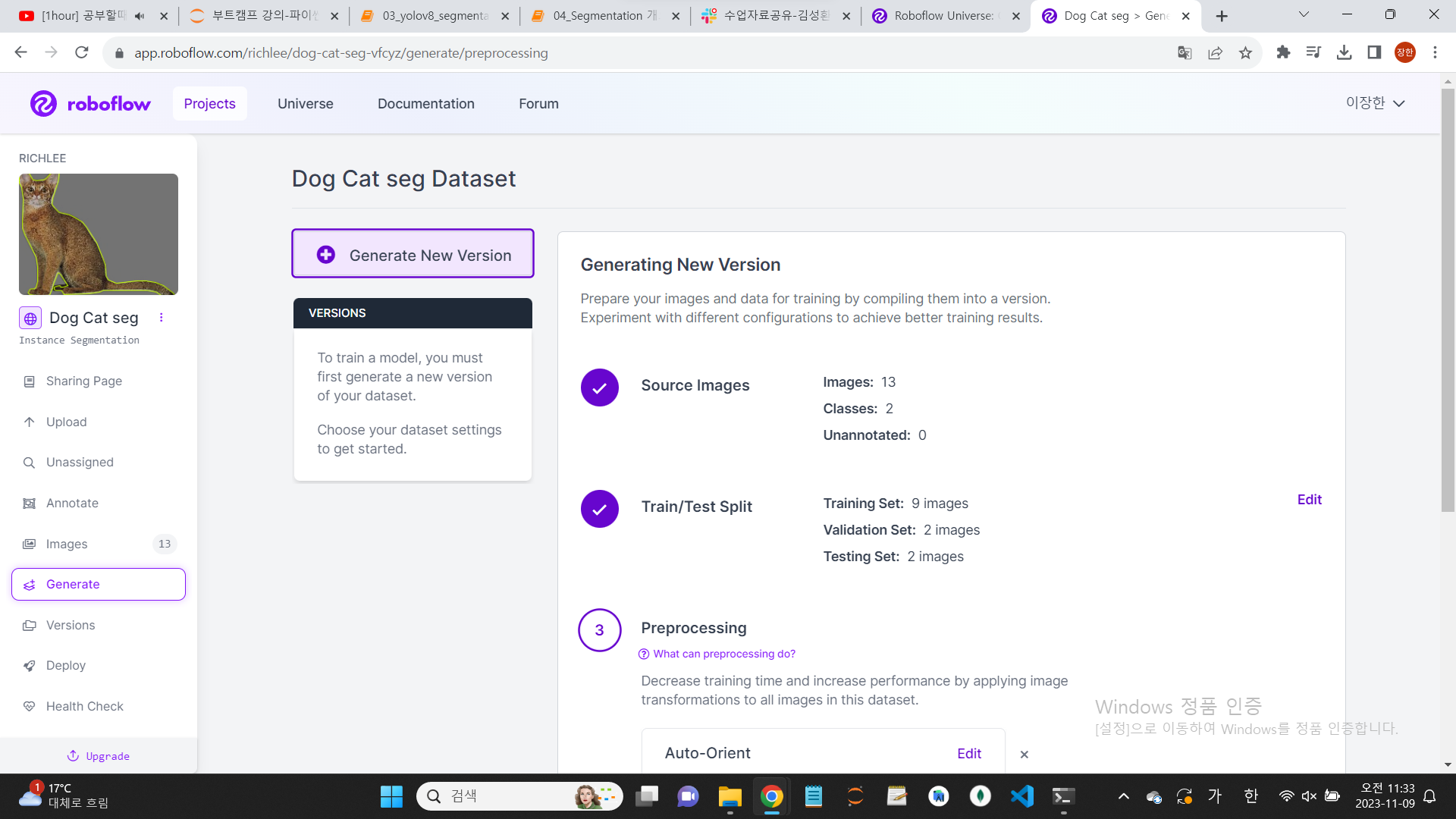
다운로드 하기 전에, 이미지들을 dataset으로 옮긴다.
이 때, 옵션은 'download zip to computer'로 한다.
5.코드 작성
import 할 것들을 import 한다.
그 전에, ultralytics를 설치한다.
!pip install ultralytics #이걸 먼저 설치해야 한다.from ultralytics import YOLO
import cv2
import matplotlib.pyplot as plt
import numpy as np그런 다음, 파일의 경로, 모델, result_list 등을 정의한다.
(아래는 예시의 성격이 강하다.)
file_path="02_test_image_seg/beatles.jpg"
model = YOLO("models/yolov8m-seg.pt")
result_list = model(file_path,save=True,save_txt=True)
다운로드가 잘 된다면, 위와 같은 화면이 나온다.
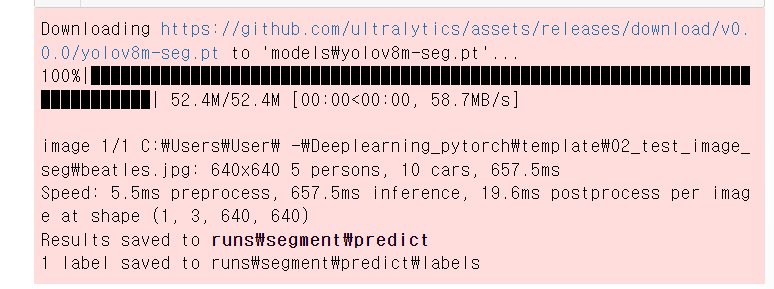
그런 다음, print을 통해 결과를 확인한다.
model = YOLO("models/yolo8m-seg.pt")
file_path2=["02_test_image_seg/beatles.jpg","02_test_image_seg/bus.jpg"]
result_list2 = model(file_path2,save=True,save_txt=True,conf=0.5,verbose=False)
print(type(result_list2),len(result_list2),type(result_list2[0]))아래와 같이 결과가 나온다.
<class 'list'> 2 <class 'ultralytics.engine.results.Results'>6.결과 확인
먼저 imshow라는 함수를 만든다. 과정을 더 간편하게 하기 위해서이다.
def imshow(img):
cv2.imshow("frame",img)
cv2.waitKey()
cv2.destroyAllWindows()#출력 결과 이미지 확인
result = result_list[0]
imshow(result.plot())아래는 결과 이미지이다.

7.bounding box 정보 파악
#bounding box 정보
boxes = result.boxes
#print(type(boxes))
# bbox의 위치 정보
print(boxes.xyxy.shape) #bbox의 좌상단 우하단 x,y 좌표
print(boxes.xyxyn.shape) #bbox의 좌상단 우하단 x,y 좌표 이미지크기 대비 비율
#[15:object개, 4:좌표]
print(boxes.xywh.shape) #bbox의 center x,y 좌표, bbox의 width, height 크기
print(boxes.xywhn.shape) #bbox의 center x,y 좌표, bbox의 width, height 크기 이미지 크기 대비 비율
#bbox 내의 object 분류
print(boxes.cls) #object class index
print(boxes.conf) #object들의 확률아래는 출력되는 값들이다.
torch.Size([15, 4])
torch.Size([15, 4])
torch.Size([15, 4])
torch.Size([15, 4])
tensor([0., 0., 0., 0., 2., 2., 2., 2., 0., 2., 2., 2., 2., 2., 2.])
tensor([0.9563, 0.9443, 0.9350, 0.9329, 0.9099, 0.7731, 0.7397, 0.6489, 0.6446, 0.6224, 0.5632, 0.5442, 0.5372, 0.4989, 0.3224])8.배열 설정
#key는 필요 없고 value는 필요하다.
idx2class = np.array([value for key,value in result.names.items()])
idx2class[boxes.cls.to('cpu').numpy().astype('int')]이런 식으로 코드를 작성하면, 결과는 이렇게 나온다.
array(['person', 'person', 'person', 'person', 'car', 'car', 'car', 'car', 'person', 'car', 'car', 'car', 'car', 'car', 'car'], dtype='<U14')9.segmentation
masks = result.masks
print(type(masks))이런 식으로 코드를 적으면,
<class 'ultralytics.engine.results.Masks'>이런 식으로 코드가 나온다.
그런 다음, xy를 입력한다.
print(len(masks)) #추론한 대상이 몇개인지!
print(type(masks.xy),len(masks.xy)) #찾은 object의 point 좌표들을 리스트로 리턴한다.
print(type(masks.xy[0]),masks.xy[0].shape) #[0]:첫번째 object이는 다음과 같이 출력된다.
15
<class 'list'> 15
<class 'numpy.ndarray'> (374, 2)-----374는 점개수이고, 2는 좌표이다.원래 이미지 크기 대비 비율을 구해보자.
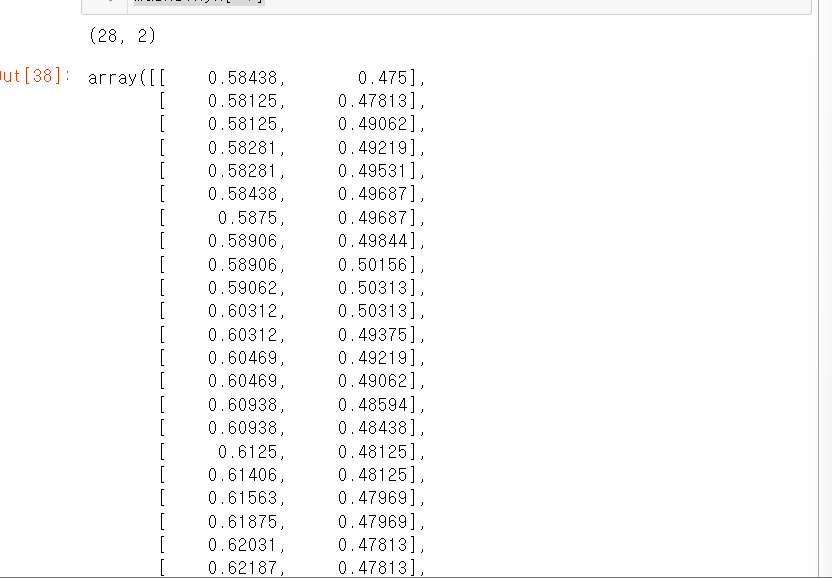
#원래 이미지 크기 대비 비율. xyn
print(masks.xyn[-1].shape)
masks.xyn[-1]다음은 출력값이다.
10.첫번째 대상의 좌표점을 시각화해보자.
#첫번째 대상의 좌표점을 시각화해보자.
obj=np.zeros(result.orig_shape,dtype="uint8")
idx = masks.xy[0].astype('int') #타입을 바꾼다.
y_idx,x_idx = idx[:,0], idx[:,1]
obj[x_idx,y_idx] = 255 #이런 식으로 index 값을 조작을 하자.
plt.imshow(obj,cmap='gray')
plt.show()아래는 결과이다.

11.관련 정보 추출
#이런 식으로 관련 정보를 뽑아낸다.
#boxes: 전체 찾은 object들
#box: 개별 object
for box in boxes:
print(type(box),box.xyxy.shape,box.cls.shape,box.conf.shape)결과
<class 'ultralytics.engine.results.Boxes'> torch.Size([1, 4]) torch.Size([1]) torch.Size([1])
<class 'ultralytics.engine.results.Boxes'> torch.Size([1, 4]) torch.Size([1]) torch.Size([1])
<class 'ultralytics.engine.results.Boxes'> torch.Size([1, 4]) torch.Size([1]) torch.Size([1])
<class 'ultralytics.engine.results.Boxes'> torch.Size([1, 4]) torch.Size([1]) torch.Size([1])
<class 'ultralytics.engine.results.Boxes'> torch.Size([1, 4]) torch.Size([1]) torch.Size([1])
<class 'ultralytics.engine.results.Boxes'> torch.Size([1, 4]) torch.Size([1]) torch.Size([1])
<class 'ultralytics.engine.results.Boxes'> torch.Size([1, 4]) torch.Size([1]) torch.Size([1])
<class 'ultralytics.engine.results.Boxes'> torch.Size([1, 4]) torch.Size([1]) torch.Size([1])
<class 'ultralytics.engine.results.Boxes'> torch.Size([1, 4]) torch.Size([1]) torch.Size([1])
<class 'ultralytics.engine.results.Boxes'> torch.Size([1, 4]) torch.Size([1]) torch.Size([1])
<class 'ultralytics.engine.results.Boxes'> torch.Size([1, 4]) torch.Size([1]) torch.Size([1])
<class 'ultralytics.engine.results.Boxes'> torch.Size([1, 4]) torch.Size([1]) torch.Size([1])
<class 'ultralytics.engine.results.Boxes'> torch.Size([1, 4]) torch.Size([1]) torch.Size([1])
<class 'ultralytics.engine.results.Boxes'> torch.Size([1, 4]) torch.Size([1]) torch.Size([1])
<class 'ultralytics.engine.results.Boxes'> torch.Size([1, 4]) torch.Size([1]) torch.Size([1])
12.bus.jpg 물체의 경계를 찾기
###############bus.jpg 물체의 경계를 찾기(segment)
import cv2
from ultralytics import YOLO
#모델 생성
model = YOLO("models/yolov8m-seg.pt")
#추론
result = model("02_test_image_seg/bus.jpg")[0]
#원본 이미지 크기
shape = result.orig_shape
#print(shape) #h,w
#추론결과를 그릴 원소가 모두 0이고 원본이미지와 같은 크기의 배열
arr=np.zeros(shape,dtype="uint8")
object_mask = np.zeros(shape, dtype="uint8") #찾은 사람들의 pixcel을 표시하는 마스크.
#추론 결과
masks = result.masks #segment 결과
boxes = result.boxes #detect 결과
for mask,box in zip(masks,boxes): #mask: 개별 object
if box.cls.item()==0: #찾은 object가 person이라면
xy = mask.xy[0].astype('int') #mask.xy
#찾은 point들 연결---이를 통해 모양을 출력해낸다.
cv2.polylines(arr,[xy],isClosed=True,color=(255,255,255),thickness=2)
#object mask 생성
#fillpoly를 통해 사람을 구분짓게 한다.
cv2.fillPoly(object_mask, #그릴 대상
[xy], #다각형의 꼭지점들.
255 # 다각형 안쪽을 채울 값.
)
#이미지 출력
imshow(cv2.resize(object_mask,(0,0),fx=0.5,fy=0.5))
이렇게 코드를 입력하면

와 같은 결과가 나온다.
코드에서, 인간만 싹 하고 걸러낸 것을 잘 파악하자.
13.bitwise_and
아래의 코드를 보면 이해가 쉽다.
#bitwise_and(img1,img2 [,mask]) -> img1과 img2의 공통부분만 추출(다른 부분은 0을 반환), mask===>추출할 영역
#img1과 img2의 shape은 같아야 한다.
#공통된 부분만 추출하는 것을 잘 보도록 하자.
a = np.array([1,2,3,100,500])
b = np.array([100,2,300,1,500])
m=np.array([0,255,0,0,0],dtype='uint8') #mask: 이진마스크-(0과 255 두개값으로 구성!) 결과는 255가 있는 index의 결과만 사용한다.
cv2.bitwise_and(a,b,mask=m)
결과는 다음과 같이 나온다.
array([[0],
[2],
[0],
[0],
[0]], dtype=int32)14.찾은 instance만 따내기
12번을 토대로 코드를 작성하면
#찾은 instance만 따내기
person_img = cv2.bitwise_and(result.orig_img,result.orig_img,mask=object_mask)
imshow(cv2.resize(person_img,(0,0),fx=0.5,fy=0.5))아래와 같은 결과가 나온다.

15.custom dataset training
금이 가는 것을 찾아주는 것이다.
우선 사이트에 들어가서 데이터를 다운로드한다.
모델은 당연히 yolov8.
https://universe.roboflow.com/angelo-maglasang-vuuq3/crack_flip_rotate/dataset/1
아래 사이트에서 다운을 받고 압축을 풀어보자.
압축을 풀고, 원하는 위치에 파일을 집어넣자.
그 전에 , ymal 파일을 열어서
경로를 이렇게 바꾸자.
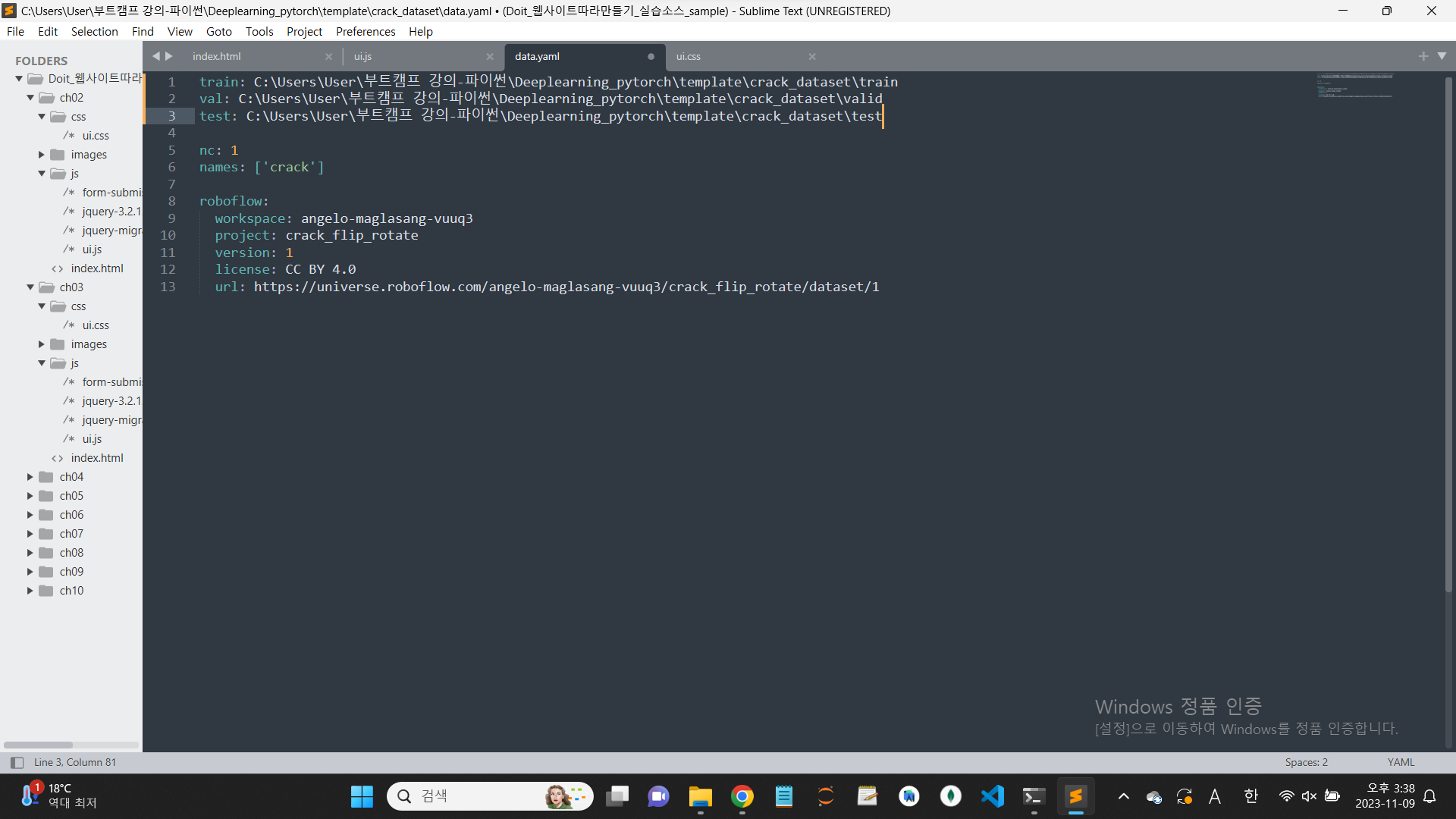
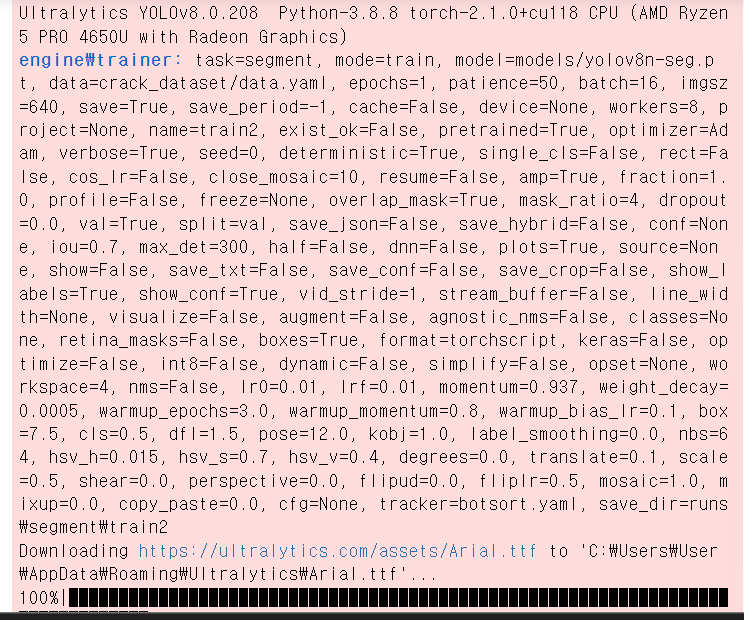
그런 다음 train을 시킨다.
from ultralytics import YOLO
model = YOLO("models/yolov8n-seg.pt")
#fine tuning
model.train(data="crack_dataset/data.yaml",
epochs=1,
imgsz=640,
optimizer='Adam'
) #ymal파일의 위치train이 완료가 되면 다음과 같이 결과가 나온다.
16.학습된 모델을 토대로 추론
먼저 파일 경로를 불러온다.
file_path = glob("02_test_image_seg/crack*.jpg") #crack이 있는거만 출력.
file_path['02_test_image_seg\\crack0.jpg',
'02_test_image_seg\\crack1.jpg',
'02_test_image_seg\\crack2.jpg',
'02_test_image_seg\\crack3.jpg',
'02_test_image_seg\\crack4.jpg',
'02_test_image_seg\\crack5.jpg',
'02_test_image_seg\\crack6.jpg',
'02_test_image_seg\\crack7.jpg',
'02_test_image_seg\\crack8.jpg',
'02_test_image_seg\\crack9.jpg']그런 다음에, crack을 구분하게 하는 코드를 작성하자.
best_model = YOLO("models/best.pt") #best.pt 파일을 미리 업로드하는 것을 잊지 말자!
results = best_model(file_path,save=True,save_txt=True)
#위 코드를 실행해보면 crack을 잘 구분하는 것을 볼 수 있다.결과는 다음과 같이 나온다.

결과를 보고 싶다면, 사진에서 나온 경로로 가면 된다.
그러면 결과가 이렇게 나온다.


