0.자세한 코드는 필자의 깃허브에 코드를 업로드 해 놓았다.
코드를 한번 훑어보고, 이 요약본을 읽어보는 식으로 학습을 하면 이해가
빠를 것이다.
https://github.com/guraudrk/bootcampcode_Deeplearning_pytorch1.mnist 이미지 분류
흑백 손글씨 숫자 10개를 범주로 분류해 놓은 데이터셋이다.
6만개의 train 이미지와 1만개의 test 이미지로 구성이 된다.
2.mnist를 하기 위해서는
torch와 그것과 연관된 DataLoader,datasets,transforms 들을 import 해야 한다.
3.그 다음에 여러번 사용할 값들을 저장할 변수를 정해야 한다.
batch_size는 모델의 파라미터를 업데이트할 때 사용할 데이터의 개수이다.
데이터가 많으니 batch_size를 따로 정한다.
전체 train dataset을 한번 학습한 것을 1 epoch라고 한다.
학습률은 lr이라고 한다. 파라미터를 update를 할 때 gradient 값에 곱해줄 값이다.
step은 파라미터를 1번 업데이트 하는 단위이다.
DATASET_SAVE_PATH,MODEL_SAVE_PATH은 데이터들을 저장할 디렉토리 경로이다.
4.MNIST dataset loading
1.우선 mnist 데이터셋을 다운로드 하고, dataset 객체를 생성한다.
객체 생성은
train_set = datasets.MNIST(root=DATASET_SAVE_PATH,
train=True, #trainset:훈련용이다.
download=True, #root에 저장된 데이터파일들이 없을 때 다운로드를 받을지 여부에 대해.
transform = transforms.ToTensor() #데이터 전처리. (전처리:변환하지 않고 쓰겠다.)
) #데이터셋을 저장할 디렉토리 경로.와 같이 생성한다.
2.ToTensor() : ndarray, PIL.Image 객체 -> torch.Tensor로 변환한다. Pixcel값을 정규화한다.(normalization)
3.ToTensor를 통해 testset을 설정해준다.
유의해야 할 점은 train이 아닌 test이기 때문에 이를 false라고 해야 한다는 점이다.
test_set = datasets.MNIST(root=DATASET_SAVE_PATH,
train=False,
download=True,
transform=transforms.ToTensor()) #trainset이 False라고 설정하면 된다.이렇게 실행을 하면, dataset이라는 파일이 하나 생긴다.
5.DataLoader
dataset을 모델에 어떻게 제공할지를 설정한다.
이 때, 훈련용 dataloader와 평가용 dataloader를 둘 다 load하는 것이 중요하다.
Dataset을 모델에 어떻게 제공할지를 설정 => 학습/평가시 설정된 대로 데이터를 loading한다.
#훈련용 DataLoader
train_loader = DataLoader(train_set,#Dataset
batch_size=BATCH_SIZE, #BATCH_SIZE를 설정한다.
shuffle = True, #한 epoch이 끝이나면 다음 epoch전에 데이터를 섞을지의 여부.(디폴트:false)
drop_last=True,#마지막 batch의 데이터수가 batch_size보다 적을 경우 버릴지(학습에 사용안함) 여부(디폴트:false)
)
#평가용 dataloader
test_loader = DataLoader(test_set,batch_size=BATCH_SIZE,shuffle=True)
6.네트워크 모델 정의
class로 정의: nn.Moudle을 상속해서 정의한다.
아래는 예시이다.
코드가 살짝 복잡하니, 주의깊게 학습해야 한다.
class MnistModel(nn.Module):
def __init__(self):
"""
모델 객체 생성시 모델을 구현(정의)할 때 필요한 것들을 초기화한다.
필요한 것: Layer들. 등등.....
"""
super().__init__()
self.lr1 = nn.Linear(28*28,128) #input feature의 크기, output size(임의지정)
self.lr2 = nn.Linear(128,64)
self.lr3 = nn.Linear(64,10) #784-----128-----64------10 이런 순으로 간다.
#이 때, 10은 '각 범주의 확률'이 된다.
### Acrivation함수 --->비선형함수 :ReLU (비선형:직선형이 아니라는 것이다.)
self.relu = nn.ReLU() #중간중간의 결과값을 변형을 시킬 것이다. sigmoid 함수 대신에 이걸 쓴다.
#x값이 뭐냐에 따라서 증감이 달라지는 것이다. 그래서 선형이 아니라 비선형.
#input으로 x를 받으면, x와 0을 비교해서 더 큰걸 받는다. 그래서 함수 그래프 그림이 약간 재미있어진다.
#이 부분에서 정의한 함수들 (4개)를 토대로 forward 함수 부분에서 계산을 할 것이다.
def forward(self,x):
"""
input data를 입력받아서 output 데이터를 만들 때 까지의 계산 흐름을 정의한다.
====> forward propagation
parameter
x: 입력데이터
return
torch.Tensor: 출력데이터(모델 예측결과.)
"""
#init 에서 생성한 함수들을 이용해서 계산
### x->1차원으로 변환 -> lr1 ->relu ->lr2 ->relu ->lr3 ->output
pass #나중에 구현
#input(batch_size,channel,height,width) => (batch_size,전체 pixcel)
#전체 pixcel은 channel,height,width을 곱한 것이라고 볼 수 있다.
x = torch.flatten(x,start_dim=1) #(b,c,h,w)=>(b,c*h*w) #1치원으로 변환
x = self.lr1(x) #lr1
x = self.relu(x)#relu
x = self.lr2(x)
x = self.relu(x)
output = self.lr3(x)
return output7.그런 다음 정의한 모델 클래스로부터 모델 객체를 생성하면 된다.
model = MnistModel()
print(model)결과
MnistModel(
(lr1): Linear(in_features=784, out_features=128, bias=True)
(lr2): Linear(in_features=128, out_features=64, bias=True)
(lr3): Linear(in_features=64, out_features=10, bias=True)
(relu): ReLU()
)
8.모델의 연산 흐름 및 정보를 확인하기 위해서는 torchinfo 패키지를 활용한다.
----이는 깃허브의 코드를 통해 자세히 알 수 있다. 필수적인 정보까지는 아니다.
9.모델 추론
train dataset의 첫번째 배치를 이용해서 모델을 추론하자.
next와 iter 함수가 어떻게 쓰였는지에 대해 복습이 필요하다.
x_batch,y_batch = next(iter(train_loader)) #(input,output) -----각각 학습을 시킨 것과 시키지 않은 것이다.
print(x_batch.shape,y_batch.shape)추론 부분
pred_batch = model(x_batch) #model의 forward() 메소드가 실행.
pred_batch.shape근데, 나오는 값과 원래 값을 비교하면 당연히 틀리다.
학습을 시키지 않았으니까 그렇다.
코드를 통해 몇개 정도 맞춘 것인지 계산을하면, 10개중에 1개정도밖에 맞추지 못했다.
이건 그냥 찍은 거잖아!
10.train
자, 10프로라는 아름다운(?) 정답률을 소유한 것을 보았으니,
이제 본격적으로 train을 할 차례이다.
아래는 모델, loss function, optimizer를 생성하는 코드이다.
###모델을 device로 옮긴다.(모델을 이용한 계산을 cpu에서 할지, gpu에서 할지...)
###모델을 이용한 계산을 cpu에서 할지 gpu에서 할지....
###참고로 device로 옮긴다는 것은 model, 주입할 input data, output data 등을 모색한다는 것이다.
model = model.to(device)
###loss function
# 분류문제: cross entropy, 이중분류문제: binary crossentropy ====> log loss라고 이야기한다. 보통은 log을 쓰거든.
#다중분류:label이 여러개 이진분류: yes/no 분류
loss_fn = nn.CrossEntropyLoss() #nn.functional.cross_entropy() 함수를 써도 된다.
#이 방법은 객체를 생성해서 거시기를 하는 것이다.
#####Optimizer =====> 모델 파라미터들을 최적화
optimizer = torch.optim.Adam(model.parameters(), #최적화 대상 파라미터들
lr=LR
)
#이번에는 아담이라는 옵티마이저를 쓰자.
##어처피 뭘 쓰든, 경사하강법을 쓰는 것은 동일하다. 그러니 별 상관은 없어.
###
이를 통해 모델의 파라미터들을 반환한다.
a = next(model.parameters())
print(a.shape)
a출력 결과
torch.Size([128, 784])
Parameter containing:
tensor([[ 0.0280, 0.0249, 0.0018, ..., -0.0298, -0.0170, 0.0021],
[ 0.0175, 0.0110, 0.0196, ..., 0.0019, -0.0293, 0.0263],
[-0.0313, -0.0249, 0.0098, ..., -0.0216, -0.0161, 0.0245],
...,
[-0.0190, -0.0195, -0.0312, ..., -0.0185, -0.0318, 0.0007],
[-0.0289, 0.0342, -0.0083, ..., 0.0281, -0.0264, -0.0153],
[ 0.0249, -0.0169, -0.0304, ..., -0.0206, 0.0059, -0.0022]],
requires_grad=True)
결과를 보면, 784라는 사이즈가 그대로 유지가 되었음을 알 수 있다.
11.학습 및 검증
유의점
이 코드를 완벽하게 이해하기 위해서는 gradient나 backward등의 함수들을 숙지해야 할 필요가 있다.
#학습 => train(훈련) + validation(1 epoch 학습한 모델성능을 검증.)
## 에폭별 학습 결과를 저장할 리스트들
train_loss_list =[] #train set으로 검증 시의 loss
val_loss_list =[] #test set으로 검증 시의 loss
val_accuracy_list =[] #test set으로 검증 시의 accuracy(정확도)
start = time.time()
#Train
for epoch in range(N_EPOCH):
#먼저 학습을 한다!
model.train()#모델을 train 모드로 변경한다.
train_loss = 0.0 #현재 epoch의 학습 결과 loss를 저장할 변수.
#batch 단위로 학습한다.
for X_train,y_train in train_loader: #batch 단위 (input,output) 튜플로 반환.
#1.x,y를 device로 옮긴다. (model,X,y는 같은 device 상에 위치해야 한다.)
#같은 device 상에 위치하지 않으면 오류가 난다.
X_train,y_train = X_train.to(device),y_train.to(device)
#추론
pred = model(X_train)
#3.loss 계산
loss = loss_fn(pred,y_train) #args 순서: (모델예측값, 정답)
#4. 모델의 파라미터 업데이트
## 1.파라미터의 gradient값들을 초기화
optimizer.zero_grad()
#2.gradient 계산 =====> 계산결과는 파라미터. grad 속성에 저장.
loss.backward()
#3.파라미터(weight,bias) 업데이트(파라미터 - 학습률*grad)
optimizer.step()
###현재 batch의 loss 값을 train_loss 변수에 누적한다.
train_loss += loss.item() #Tensor -> 파이썬 값
#1epoch 학습 종료
#epoch의 평균 loss를 계산해서 리스트에 저장.(train_loss:step별로 loss를 누적했으므로 평균을 반드시 내 줘야 한다.)
train_loss_list.append(train_loss/len(train_loader)) #step수로 나눈다.
#################################################
# validate(검증) -test set(학습할 때 사용하지 않았던 테스트셋을 이용)
#################################################
model.eval() #모델을 검증(평가) 모드로 변환.
## 현재 epoch에 대한 검증경과를 저장할 변수
val_loss =0.0
val_acc = 0.0
#모델 추정을 위한 연산 -forward propagation
## 검증/평가/서비스 ->gradient 계산이 필요없다. => 도함수를 계산할 필요가 없다.
with torch.no_grad():
## batch 단위로 검증
for X_val, y_val in test_loader:
#1.device로 옮기기
X_val,y_val =X_val.to(device),y_val.to(device)
#2.모델을 이용해 추론
pred_val = model(X_val)
#3.검증
##1.loss 계산 + val_loss에 누적
val_loss = val_loss + loss_fn(pred_val,y_val).item() #item 함수는 값만 빼오는 것이다.
##2.정확도(accuarcy):맞은것개수/전체개수
val_acc = val_acc + torch.sum(pred_val.argmax(axis=-1)==y_val).item()
#식을 자세히 보면 충분히 이해가 가는 부분이니, 복습 시간에 이를 잘 파악하도록 하자.
#test set 전체에 대한 검증이 완료 => 현 epoch에 대한 검증 완료
## val_loss, val_acc 값을 리스트에 저장한다.
val_loss_list.append(val_loss / len(test_loader)) #loss는 step 수로 나눈다.
val_accuracy_list.append(val_acc/len(test_loader.dataset)) #정확도를 append한다.
#현재 epoch train 결과를 출력
print(f"[{epoch+1:2d}/{N_EPOCH:2d}] Train Loss: {train_loss},Val Loss:{train_loss_list[-1]},Val loss:{val_loss_list[-1]}, Val Accuracy: {val_accuracy_list[-1]}")
#보면 점점 loss가 줄어들고, accuracy가 증가했음을 알 수 있다.
#보통은 accuracy가 아닌 loss를 기준으로 성능을 판단한다.이 코드를 실행하면, 기계가 학습을 시작해서 우리가 원하는 지표들을 출력해준다.
시간은 대략 2~5분 정도 걸린다.
근데 데이터의 양이나 반복의 양을 늘리면 시간이 더 걸리겠지?
아래는 결과의 예시(일부)이다.
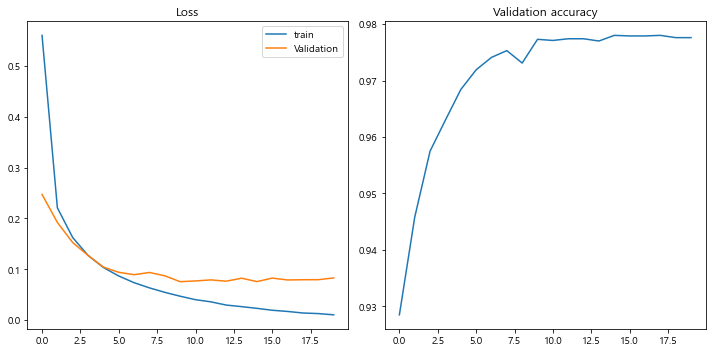
loss는 줄고, accuracy는 증가하는 것을 볼 수 있다.
[ 1/20] Train Loss: 127.25238919258118,Val Loss:0.5438136290281247,Val loss:0.2544334940612316, Val Accuracy: 0.9286
[ 2/20] Train Loss: 51.21423093229532,Val Loss:0.2188642347533988,Val loss:0.18922494240105153, Val Accuracy: 0.9444
[ 3/20] Train Loss: 37.68041828274727,Val Loss:0.16102742855874902,Val loss:0.13634217181243002, Val Accuracy: 0.9573
[ 4/20] Train Loss: 29.40886839106679,Val Loss:0.12567892474814868,Val loss:0.11831049602478742, Val Accuracy: 0.9619
[ 5/20] Train Loss: 23.719699501991272,Val Loss:0.1013662371879969,Val loss:0.10411972063593566, Val Accuracy: 0.9678
12.학습 로그 시각화
epoch별 loss, accuracy의 변화흐름을 시각화한다.
#epoch 별 loss,accuracy의 변화흐름을 시각화
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
plt.plot(range(N_EPOCH),train_loss_list,label="train")
plt.plot(range(N_EPOCH),val_loss_list,label="Validation")
plt.title("Loss")
plt.legend() #이것을 통해 train과 validation을 잘 파악한다.
plt.subplot(1,2,2)
plt.plot(range(N_EPOCH),val_accuracy_list)
plt.title("Validation accuracy")
plt.tight_layout()
plt.show()
#근데 보면 학습을 너무 많이 시키면 loss가 미세하게 늘어나는 것을 볼 수 있다.아래는 결과 그래프이다.
12.학습된 모델 저장 및 불러오기
1.저장
이런 식으로 저장한다.
숙지해야 할 것은 os.path.join을 통해 파일의 경로를 새롭게 설정한다는 점이다.
save_path = os.path.join(MODEL_SAVE_PATH,"mnist")
os.makedirs(save_path,exist_ok=True)
save_file_path = os.path.join(save_path,"mnist_mlp.pth") #파일을 만듬.
print(save_file_path)그런 다음,
torch.save(model,save_file_path) #파일을 저장. 이렇게 저장한다.
2.불러오기
### 모델 불러오기
load_model = torch.load(save_file_path)
load_model이렇게 모델을 불러온 다음,
from torchinfo import summary
summary(load_model,(BATCH_SIZE,1,28,28))
#잘 학습이 된 것인지 확인하기 위해 summary를 통해 정보를 확인한다.
summary를 통해 잘 학습이 된 것인지 확인한다.
결과는 이런 식으로 나오니 참고하길 바란다.
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
MnistModel [256, 10] --
├─Linear: 1-1 [256, 128] 100,480
├─ReLU: 1-2 [256, 128] --
├─Linear: 1-3 [256, 64] 8,256
├─ReLU: 1-4 [256, 64] --├─Linear: 1-5 [256, 10] 650
Total params: 109,386
Trainable params: 109,386
Non-trainable params: 0Total mult-adds (M): 28.00
Input size (MB): 0.80
Forward/backward pass size (MB): 0.41
Params size (MB): 0.44Estimated Total Size (MB): 1.65
13.모델 평가
자.....이제 떨리고도 떨리는 모델 평가 시간이다.
복잡한 코드를 통해 우리가 얻을 수치는 test loss와 test accuracy이다.
이 점을 유의해서 코드를 잘 보도록 하자.
#device로 옮기기
load_model = load_model.to(device)
#평가모드 변환
load_model.eval()
test_loss, test_acc = 0.0,0.0
with torch.no_grad():
for X,y in test_loader:
#device 옮기기
X,y = X.to(device),y.to(device)
#추정
pred = load_model(X)
#평가 -loss, accuracy
test_loss += loss_fn(pred,y)
test_acc += torch.sum(pred.argmax(axis=-1)==y).item()
test_loss /= len(test_loader) #step 수로 나누기.
test_acc /= len(test_loader.dataset) #총 데이터수로 나누기.
print(f"Test loss: {test_loss},Test accuracy: {test_acc}")
#'최종 모델의 성과가 이정도 입니다!'라는 것을 알려주는 코드이다.결과는 아래와 같이 나온다.
Test loss: 0.08296414464712143,Test accuracy: 0.9776
14.새로운 데이터 추론
전체적인 흐름을 다 파악하고, 그런 다음에 코드를 보도록 하자. 그래야 이해가 더 빠르다.
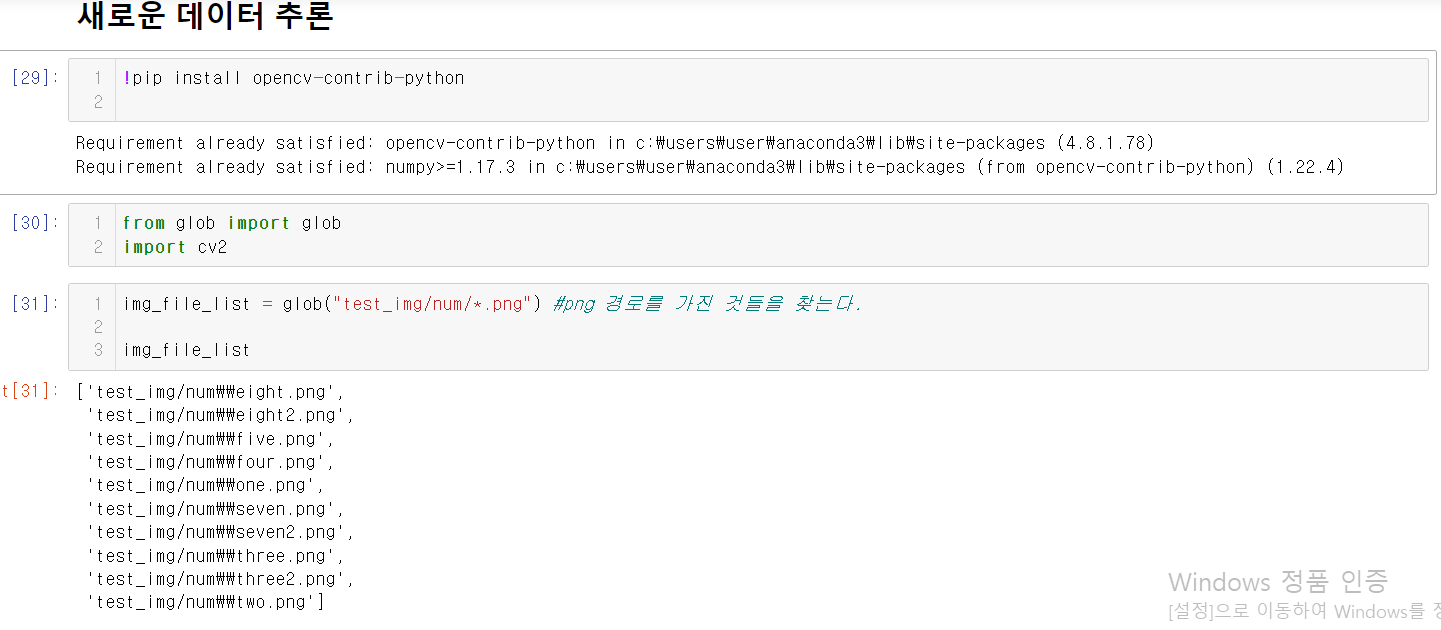
1.glob 코드를 통해 png 경로를 가진 것을의 리스트를 불러온다.
2.개수에 따라 zero로 tensor를 만든다.(사이즈를 잘 맞출것!)
3.이를 통해 추론을 한다.
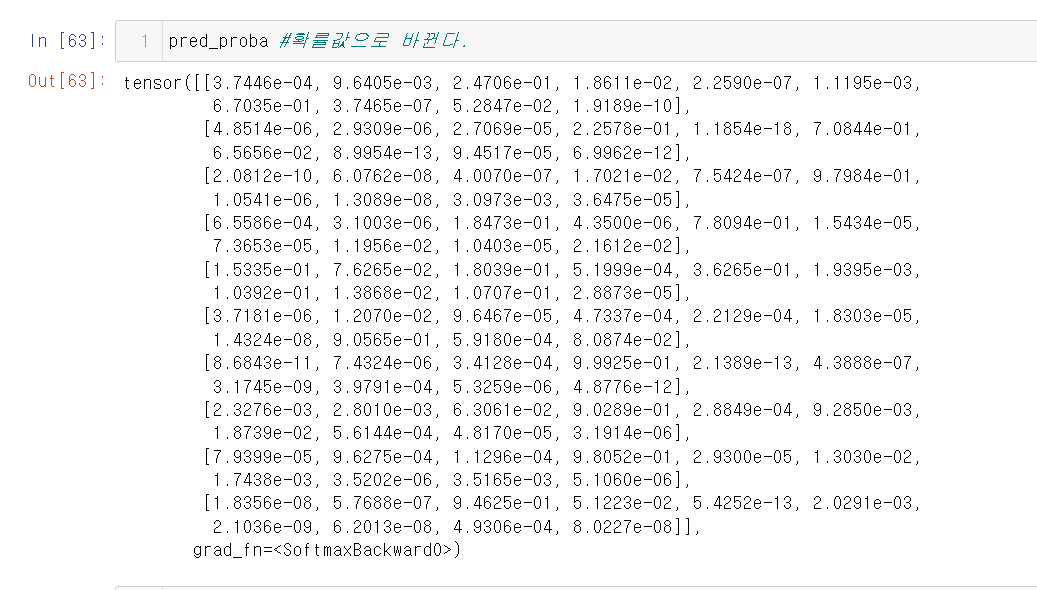
4.그러면 값이 나온다. 이를 확률값으로 변환한다. 이를 가능하게 해 주는 것이 바로 softmax 함수이다.
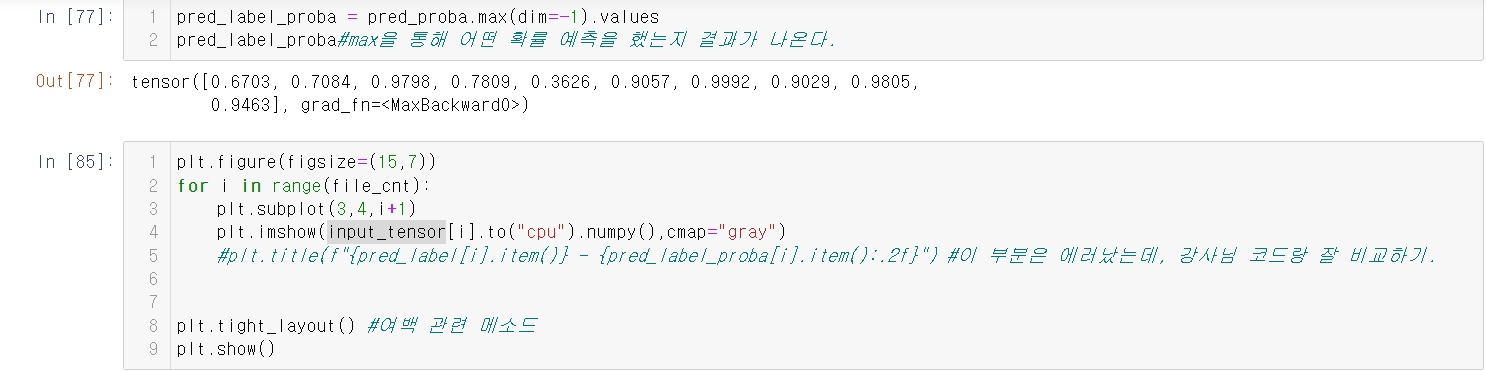
5.max 함수와 values 함수를 통해 확률 예측을 어떻게 했는지 파악한다.
6.그런 다음, plt를 통해 값을 출력한다.
다음은 코드 이미지이다.