구글의 RT-2
구글이 세계 최초로 '로봇 제어 인공지능 모델'을 개발했다!
이름은 RT-2 : Robot Transformer 2로 '시각-언어-행동(vision-language-action, VLA)' 모델이다. 이는 언어모델을 이용하여 text 및 음성 등 자연어로 로봇의 행동을 제어할 수 있는 인공지능 모델이다.
이 모델은 VLA라는 시각적 언어 행동 모델을 적용했다.
시각 언어 모델(VLM)인 'PaLM-E' 와 트랜스포머 기반 언어 모델 을 결합하여 이미지를 인식하거나 단어를 들으면 별도로 학습하지 않아도 동작에 바로 적용할 수 있다는 것이 특징이다. 즉, 사전학습이 필요없다!
이 모델을 통해 로봇은 사용자의 명령어에 웹에서 텍스트 및 이미지 데이터를 수집 및 해석하고 그에 맞는 작업을 실행한다.
: 명령이 들어오면 웹 및 로봇 데이터에서 학습하고 -> 이 지식을 로봇 제어를 위한 일반화된 지침으로 변환 후 실행
예를 들어, "이전에는 로봇이 쓰레기를 버릴 수 있게 하려면 쓰레기를 식별하고 주워서 버릴 수 있도록 명시적으로 사전학습을 진행해야 했지만" , "RT-2는 웹 데이터를 통해 학습한 지식으로 쓰레기가 무엇인지 알고 있고, 청소하는 방법에 대한 아이디어까지 가지고 있는 것이다."
또한 "쓰레기"(과자봉지, 바나나껍질,...)와 같은 추상적인 단어도 비전 언어 교육 데이터에서 이를 이해하고 작업을 수행할 수 있다고 한다.
이는 명령을 받았을 때, (일반화 능력, 의미론적 이해력, 시각적 이해력, ...)을 기반으로 명령을 해석하고, 그에 맞는 추론을 하여 응답 및 행동을 하게 되는 것이다.
하지만 정확하고 많은 정보를 제공해야 하는 챗봇과는 달리, 이 모델은 구체적인 정보들을 학습할 필요가 없다. 사과를 인식한다고 해서 사과의 역사 및 뉴턴과 같은 부가적인 정보들을 알 필요가 없기에, 이러한 데이터를 제한할 필요가 있다고 한다.
정리하자면, 이러한 로봇 제어를 위해 RT-2는 하나 이상의 이미지를 입력으로 받아 자연어 텍스트를 나타내는 토큰 시퀀스를 생성하는 VLM(Vision-Language-Model)을 기반으로 구축되다.
(이 VLM은 시각적 질문 응답, 이미지 캡션 또는 객체 인식과 같은 작업을 수행하기 위해 웹규모의 데이터로 성공적으로 사전 훈련 되었다)
(PaLI:공동으로 확장된 다국어 언어 이미지 모델)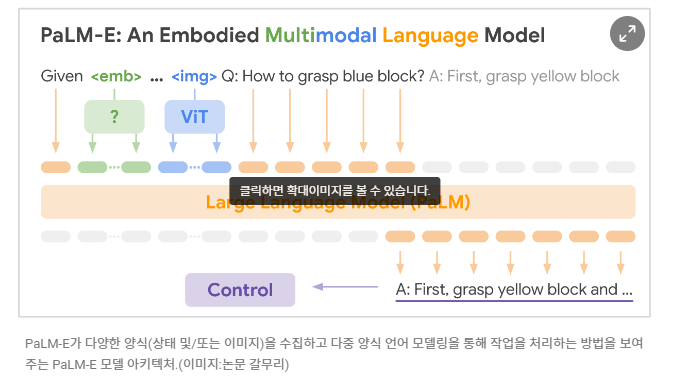
결론적으로, RT-2는 VLM(시각 언어 모델)이 로봇 데이터와 VLM 사전 훈련을 결합하여 로봇을 prompt를 통해 직접 제어할 수 있는 강력한 VLA(시각 언어 행동 모델)로 변환할 수 있음을 보여준 것이다.
출처 : https://zdnet.co.kr/view/?no=20230731082144
https://www.aitimes.kr/news/articleView.html?idxno=28629
