Data Augmentation
https://github.com/KiHwanLee123/Coursera---GAN/blob/main/DataAugmentation.ipynb
Application of GAN
- Image to Image
1) GauGAN

2) Super Resolution – sharpened image
3) multimodal image to image translation ex) cat to dog
4) Text to image
5) Image and Landmark to Video ex) image + face landmark -> talking heads
6) image filters
7) image editing
8) stylized images
9) data augmentation

Data Augmentation
real data가 너무 비싸거나, 흔하지 않은 경우 사용
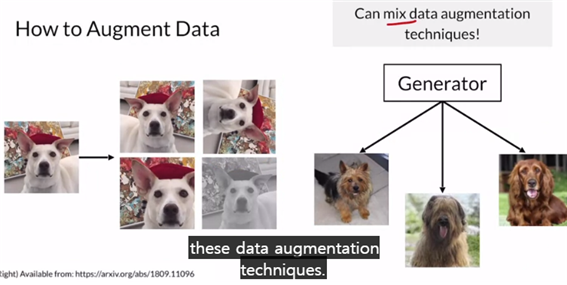
인조적으로 만들어진 이미지를 사용하는 것을 효과가 없습니다. 즉, 이를 현실화를 한 후 data로 사용해야 하는데, 이럴 경우 GAN을 통한 real image generate를 통해 만들어 낼 수 있습니다.

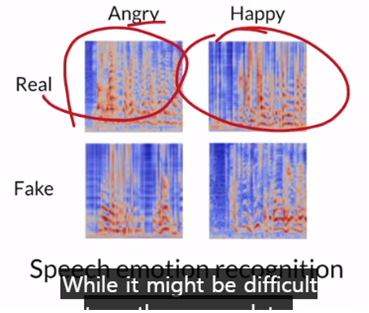
음성의 경우도 주로 spectrogram을 사용하는데, 이 spectrogram을 generate함으로 angry happy 등 감정의 음성들을 생성해 낼 수 있습니다.
GAN의 장단점
이러한 GAN의 장점으로는 수작업으로 생성해낸 이미지 보다 훨씬 유용한 것으로 나타났습니다. 또한 라벨링 된 데이터들을 conditional GAN으로 생성해 낼 수도 있고, downstream model의 일반화 성능을 올릴 수 있습니다.
하지만 단점으로는 다양성이 training set의 모든 것으로 제한된다는 것입니다. 따라서 GAN 생성 데이터로 실제 클래스를 보강하고 싶지만 GAN에서 배울 수있는 샘플이 많지 않으면 여전히 다양성이 제한됩니다. 또한 GAN이 training set을 모방하기 시작하면 데이터 증강 측면에서도 도움이되지 않는다는 단점이 존재합니다.
GANs for Privacy
오른쪽이 생성 된 샘플이고 왼쪽은 real data입니다. 이는 굉장히 유사하며 개인 프라이버시가 잘 지켜지지 않음을 볼 수 있습니다. 따라서 이 데이터를 사후 처리하여 실제와 충분히 가깝게 보이는 샘플이 어떤 식으로든 제거되거나 어떤 식으로든 사용되지 않도록 할 수 있는 몇 가지 방법이 있습니다. 하지만 이는 꽤 어려운 방법입니다.

GANs for Anonymity
1) Concealing identity
2) Stealing identity
3) DeepFakes
정체성을 은폐하는 것은 꽤 어렵습니다. 하지만 이는 무조건 지켜져야 하며, 예를 들어 범죄에 대한 증인, 안전을 위해 자신을 은폐해야 하는 다양한 활동가들 같이 이들을 위해서는 정체성을 잘 숨길 수 있게 해야 합니다.
