본 내용은 in-context learning 내용을 감사히 참고하여 작성하였습니다.
in-context learning?
말 그대로 prompt 내 맥락적 의미(in-context)를 모델이 이해하고(learning), 이에 대한 답변을 생성하는것이며, 프롬프트의 내용만으로 하고자 하는 task 를 수행하는 작업입니다.
in-context learning은 프롬프트 엔지니어링을 통해 이루어집니다.
in-context learning의 특징은 fine-tuning 처럼 모델의 weight를 업데이트 하지 않고, 별도의 모델 학습과정이 존재하지 않습니다.
미세조정 Fine-tuning(FT)
원하는 task에 맞는 data set을 통해 taks-specific fine-tuning을 실시합니다. 이 fine-tuning의 장점은 성능이 매우 좋다는 것이며, 단점은 각 task를 학습할 때 마다 수 많은 데이터가 필요하다는 것 입니다.
in-context learning 종류
1. Few-shot(FS)
모델이 추론 과정에서 몇 개의 예시만을 볼 수 있지만, 직접 학습에 활용하지 않기에 가중치 업데이트를 하지 않는 조건입니다. 보통 task에 대한 설명과 함께 task에 관한 K개(:context window, 10~100개)의 예시를 이용합니다. 이후 마지막으로 단 한 개의 문맥이 주어지면 모델이 답을 생성하는 것 입니다. 이에 대한 장점은 task-specific한 데이터에 대한 필요성을 줄여주며, 지나치게 크고 좁은 분포를 갖는 미세조정용 데이터셋을 학습할 필요성을 줄일 수 있습니다. 반면 단점으로는 Fine-tuning 방식의 SOTA에 비해 성능이 떨어진다는 점입니다.
ex)
Prompt: 빨간 사과는 red 사과라고 할께,
노란 바나나는 yellow 바나나야,
그럼 노란 사과는?
GPT: 노란 사과는 "yellow 사과"입니다.
2. One-shot(1S)
task에 대한 예시가 하나만 주어지는 것으로, 굳이 위의 few-shot과 one-shot을 나누는 이유는 one-shot이 인간의 커뮤니케이션과 비슷하기 때문이라고 합니다.
ex)
Prompt: 빨간 사과는 red 사과라고 할께.
노란 바나나는?
GPT: 노란 바나나는 "yellow 바나나"입니다.
3. Zero-shot(0s)
어떤 task인지에 대한 설명만 주어지며, 따로 예시가 주어지지 않습니다. 이 방법은 최대한의 편의, 견고함에 대한 가능성, 거짓된 상관성 회피를 제공하지만, 가장 어려운 조건입니다. 어떤 경우에는 사람조차 예시가 없이 task에 대한 설명만으로는 이해하지 못 할 수도 있기 때문입니다.(ex) 200m달리기 세계 기록에 대한 테이블을 생성해라 : 이는 테이블 형식과 같은 구체적인 내용이 없기에 굉장히 모호한 요청) 그럼에도 zero-shot의 일부 셋팅은 사람들이 task를 수행하는 방식과 가장 가깝기에 사용됩니다.
ex)
Prompt: 빨간 사과가 영어로 뭐야?
GPT: "Red Apple"
이러한 in-context learning은 사람의 입장에서는 당연한 듯 보이지만, 딥러닝 모델로 따지면 신기한 일 입니다.
학습되지 않은 내용에 대해 별도의 weight 업데이트 없이 고정된 모델이 그냥 말한대로 된다?!?!
마치 사람과 같이 유연성, 유동성, 일반성, 적응성들을 포함하게 되는 것 입니다.
HMM의 베이지안 추론
위에서 설명한 내용을 Hidden Markov Model의 Bayesian inference로 설명하는 시도도 있다고 합니다!
An Explanation of In-context Learning as Implicit Bayesian Inference.
우선 HMM이 무엇일까요?
HMM : Hidden Markow Model : 은닉 마르코프 모델
Markov chain
Markov chain(마르코브 성질을 지닌 이산확률과정(discrete-time stochastic process))을 전제한 모델입니다. 마르코브 체인의 핵심은 한 상태의 확률은 단지 그 이전 상태에만 의존한다는 것이 핵심입니다.은닉 마르코프 모델
이는 각 상태(state)가 마르코프체인을 따르되, 은닉(hidden)되었다고 가정합니다.
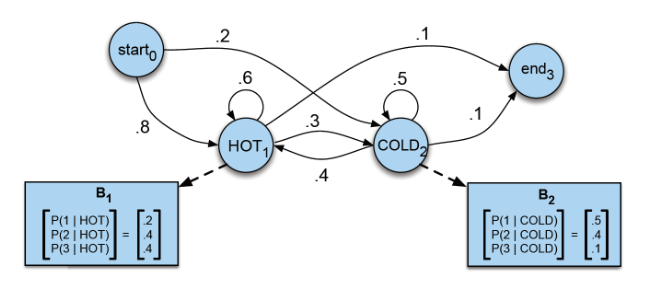
이에 대한 예시로, 100년 전 날씨를 알고 싶은데, 당시 아이스크림 소비기록만 있다고 가정하겠습니다.( : 관측치 뒤에 은닉되어 있는 상태. 이 상태를 추정하는 것 )
이 때, 아이스크림의 연쇄적인 소비 기록을 통해 해당 날씨가 무엇이었는 지 예측하는 것 입니다.
위를 보시면, B1은 날씨가 더울 때, 아이스크림 1개 소비할 확률은 0.2, 2,3개 소비할 확률은 각 0.4라는 것 입니다. 이 B1은 날씨가 더울 때에 대한 조건부 확률이므로 HOT이라는 은닉상태 와 연관이 있는 것 입니다. B 행렬은 방출확률이라고 불립니다. 위의 예로는 HOT이라는 은닉 상태로부터 관측치가 튀어나올 확률이라는 의미입니다.
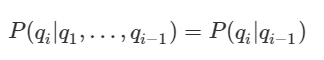
GPT를 위에서 설명한 HMM으로 표현하면 아래와 같이 표현이 가능하며, 여기서 Θ는 task를 푸는 concept들의 집합이고 o는 생성된 토큰입니다. 이를 베이즈 이론으로 표현한 것 입니다. 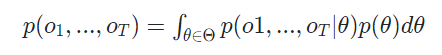
이 모델에 대해 inference는 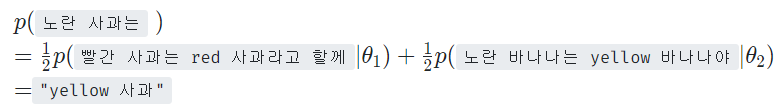
로 표현할 수 있습니다.
이러한 in-context learning(few-shot) 과정은 아래와 같은 MLE로 풀어볼 수 있습니다.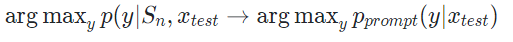
Sn : In-context 예시
**위를 xtest가 주어졌을 때, Sn을 이용하여 y가 출력될 확률이 최대가 되도록 하는 것**이는 다시 말해, 예시가 많으면 많을 수록 더 많은 베이지안 추론이 일어나며, 이를 통해 prediction이 정확해질 수 있다는 의미입니다. 즉, zero, one shot 보다 few-shot의 성능이 우수함에 대한 증거가 되는 것 입니다.
실제로 GPT에 많은 예시와 함께 질문을 던지면, 더욱 상세하고 알맞은 답변을 얻을 수 있습니다.
하지만 "왜 GPT가 HMM으로 표현되어야 하는 가"에 대해서는 직접적인 설명은 불가합니다.
결과적으로 GPT와 같은 거대 모델은 다양한 언어 task 수행이 가능한 Hidden Markov Model 로 간주할 수 있고, 주어진 prompt를 추론하는 과정은 MLE 과정으로 이해할 수 있습니다. : 추론이라는 과정도 최적화 방법이 될 수 있다는 것 입니다.
개인적으로 HMM의 베이지안 추론으로 결과를 확인해볼 수 있다는 과정이 정말 흥미롭게 다가왔습니다.
이를 이용한 MLE, 그렇기에 예시가 많을 수록 베이지안 추론이 더 많이 일어나고, one,zero-shot보다 few-shot에서 우수한 성능을 얻을 수 있다는 논리.
너무 재밌게 읽을 수 있었던 내용이었습니다!
참고 : https://ratsgo.github.io/machine%20learning/2017/03/18/HMMs/
https://velog.io/@dongyoungkim/GPT-fine-tuning-5.-in-context-learning
