Prompt?
Lanugage Model에 전달하는 질문이나 요청을 사용자가 응답을 유도(prompt)한다는 의미에서 프롬프트라고 합니다. 이와 같이 언어 모델이 원하는 결과를 얻기 위해 text prompt를 사용하고, 이를 공들여 만들고 최적화하는 과정을 프롬프트 엔지니어링이라고 합니다.
~2017 : Task Specific Model(Fully supervised)
RNN, LSTM 등이 있으며, 모델 아키텍쳐를 중심으로 연구가 진행
2017~2019 : Pre-trained model -> Fine-tuning
Transformer 등장 이후, 이를 기반으로 한 BERT, GPT 등 대량의 corpus로 학습된 사전학습 모델이 등장
이를 통해 소량의 다운스트림 데이터만으로 fine-tuning을 거쳐 task specific을 가능하게 함
2019~ : Pre-trained model -> Prompt(zero, few-shot learning)
GPT-1 등장 이후, fine-tuning없이 zero-shot으로 다운스트림 테스크를 풀 수 있는 방버에 대해 연구하기 시작 -> GPT-2 등장
GPT-2에서 사전학습시, downstream task에 대한 설명을 같이 넣어주는 방식인 in-context learning 을 사용하여 사전학습 단계에서 다운스트림 테스크에 관한 정보를 배우게 됨
GPT-2가 등장하고 GPT-3가 등장할 때 까지, 그 사이에 prompt 관련 연구가 진행되었음
Prompt 구성방법
1. 사전학습 모델에 따른 프롬프트의 분류
1) Close-style prompt : 자연어 이해, 자연어 추론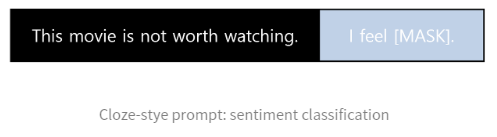
2) Prefix-style prompt : 자연어 생성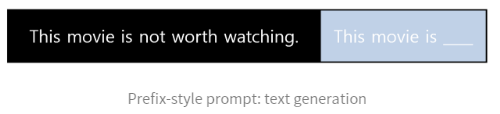
2. prompt 생성 방법에 따른 프롬프트의 분류
1) manual prompt
초창기 프롬프트 관련 연구들로, 사람이 직접 데이터를 보고 생성(LAMA, GPT-3, PET등)
manual prompt는 sub-optimal할 가능성이 큼
데이터마다 상이하게 prompt가 구성되며, 이를 만드는 엔지니어에 따라서도 크게 갈림
2) Auto prompt
모델을 통해 데이터에 맞는 템플릿을 자동으로 생성해줌
탐색하는 범위가 넓은 광범위한 search space를 가짐
3. 형태에 따른 프롬프트의 분류
1) Discrete prompt : 해석적으로 직관적이기에 용이하나, Neural Network는 continuous하기에 sub-optimal가능성이 높음
2) Continuous prompt : prompt 역할을 담당할 가상의 임베딩 벡터를 배정
