Skip-gram model
Skip-gram model은 중심 단어(Center Word)를 바탕으로 주변 단어들(Target Word)을 예측하는 방법입니다.
예시 문장 : The fat cat sat on the table

'sat'을 이용하여 주변 단어를 예측합니다. 앞뒤 몇 개의 단어를 활용할지는 window size로 정해줍니다. 예를 들어 window size=2라면, 중심 단어 sat의 앞 [The, fat], 뒤 [on the] 를 활용하게 됩니다. 즉, window size=m이라면 활용하는 주변 단어의 개수는 총 2m개 입니다. 예측 모델 학습을 위한 데이터셋은 윈도우를 옆으로 한 단어씩 sliding하여 주변 단어와 중심 단어의 세트를 변경하며 만듭니다.(sliding window)
Skip-gram model 인공신경망
위의 예시를 도식화하면 아래와 같은데, 입력층에는 중심단어의 원핫벡터가 입력에 들어갑니다. hidden layer를 통과하며 output layer에서 주변 단어를 예측한 벡터를 출력합니다. skip gram model은 단일 은닉층만 존재하여 shallow neural network model입니다.
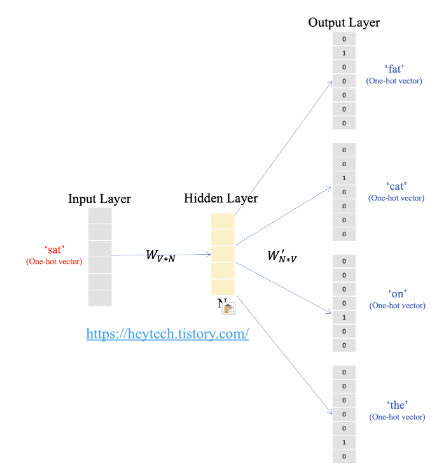
N은 은닉층의 크기이며, V는 단어 집합의 크기입니다.
원핫벡터가 입력으로 들어오면 가중치 행렬 W(VxN input word matrix)에 의해 은닉층의 크기만큼 맞춰주고, W'(NxV output word matrix)을 곱한 후 softmax를 취해 예측값을 도출합니다.
위의 예시로 들자면 원핫벡터 차원 7에 N=5라고 하면, W는 7x5, W'은 5x7 행렬이됩니다. 두 가중치 행렬은 아예 서로 다른 행렬이며, 학습 전에 랜덤한 값을 갖습니다.
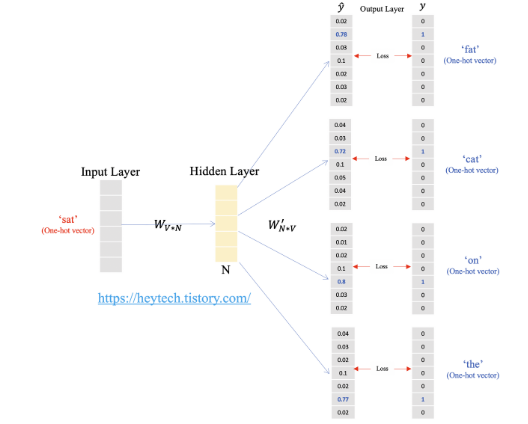
이렇게 도출한 예측값과 실제값의 loss(cross entropy)를 이용하여 학습을 진행합니다.

좋은 글 잘 읽었습니다, 감사합니다.