
이전 포스터에서 Actor Critic method를 알아봤는데, 이번 포스터에서는 Actor Critic알고리즘의 대표적인 A3C를 알아보겠습니다!
A3C는 여러개의 네트워크를 같이 운용합니다. 하나는 global network이고, 나머지는 multiple worker agents를 갖습니다. 구조는 모두 같지만 각자 작업을 달리 하고 나중에 global network로 통합하는 구조를 갖습니다.
multiple worker agents는 parallel합니다. 환경은 동일하지만 각 agent마다 각기 다른 trajectory들을 만들어 냅니다.(multiple instances) temporal correlation problem이 각 agent에는 일시적으로 생길 수 있습니다. DQN에서는 Experience replay를 사용했습니다. 여기서는 중요한 것은 각 agent가 아닌 global network의 파라미터 업데이트 입니다. 따라서 global network입장에서는 각각 agent가 업데이트를 하러 올 텐데 이 agent들 사이에는 서로 다른 방법으로 학습했기에 correlation이 크지 않습니다. 따라서 temporal correlation problem이 심각하지 않습니다. 따라서 Experience replay를 사용하지 않습니다.
궁극적으로 global network의 파라미터를 업데이트 하는데 업데이트 하는 방시이 asynchronously하게 합니다.
synchronously는 각 agent들이 다 학습을 마친 후에 전체적으로 한 꺼번에 agent에 있는 값들을 동시에 global network에 업데이트하는 방법을 말합니다.
asynchronously는 각 agent가 학습을 마치면 다른 agent와 관계없이 독자적으로 global network에 업데이트 하는 것을 의미합니다.
A3C에서는 critic network이 advantage ft을 estimate하도록 사용합니다.
advantage ft은 Q - V한 것 입니다. 이렇게 되면 두 개의 네트워크가 필요하기에 복잡해지는 단점이 있습니다. 따라서 Q value ft대신 n-step return Gt(n)을 사용합니다. 이렇게 되면 ㅏㄸ로 Q network를 만들 필요가 없게 되어 하나의 네트워크만 필요하게 됩니다.
actor critic으로 당연히 policy gradient algorithm을 사용합니다. 그렇기에 output으로 conti action space을 출력할 수 있습니다.!
대부분 Dueling,Prioritized Double DQN보다 A3C가 속도도 빠르고 성능도 우수하게 나옵니다.
또한 conti motor control problems에서도 꽤 많은 성공을 거둡니다.
A3C는 Asynchronous로 agent들이 주어진 환경을 copy해서 각자의 파라미터를 독자적으로 운영하며 알아서 global network에 넘겨 update하게 됩니다.(agent들이 일정 수 만큼 gradient를 업데이트하고 그 gradient를 global network로 넘겨 update를 진행합니다.)
각 agent들은 global network를 학습하는데만 사용하고 test할 때는 모두 사용하지 않습니다.
agent가 Asynchronous하게 global network를 업데이트한다는 말은 global network를 copy하여 agent에 붙입니다. 그 후 agent에 state st가 들어오면 여기서 action을 선택할 수 있게 됩니다. 이 action을 가지고 환경에 적용하여 reward와 next state를 얻습니다. 이를 반복하면 일정량의 trajectory를 얻게 됩니다. 이 trajectory를 가지고 agent의 파라미터를 업데이트 합니다. 이 때 gradient값들을 계산하는데 이 gradient를 누적하여 최종적으로 global network에 업데이트하는 것 입니다. 학습이 마쳐지면 다른 agent와 독자적으로 바로 업데이트합니다.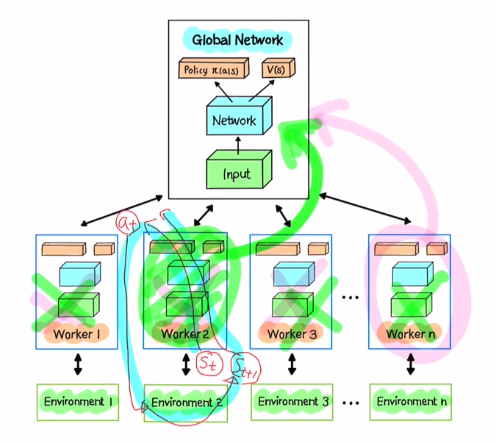
multiple agent를 사용하면 non-stationary problem과 temporal correlation이 생기는 것을 막을 수 있습니다. 각기 다른 policy를 적용하기 때문에 Exploration이 적용됩니다. 따라서 stationary하고 robust하게 됩니다.
Asynchronous Implementation
Worker agent는 독자적으로 parallel training을 합니다.
agent가 업데이트 되는 순서대로 global network의 파라미터인 세타와 파이를 업데이트합니다.
한 agent가 global network에 업데이트를 완료했다면, 현재까지 업데이트 된 global의 파라미터를 그대로 copy하여 agent에 적용합니다.
trajectory segment로 tmax step만큼 돌리고 global에 업데이트합니다.
agent가 학습을 마친 후 global에 업데이트 할 때는 파라미터를 그대로 copy해서 붙이는 것은 아닙니다. 이렇게 되면 이전의 다른 agent의 노력이 사라지게 됩니다.
따라서 우선 각 agent가 tmax만큼 gradient를 업데이트할 텐데 이것을 accumulated gradient라고 하겠습니다. 이 gradient값으로 global의 파라미터에 더하여 업데이트를 해줍니다. actor에 대해서는 step size를 곱하여 더하주고, critic은 step size만큼 곱하고 빼주게 됩니다.
agent수가 많을 수록 빠르게 학습하게 됩니다.
고려대학교 오승상 교수님 강화학습 강의 : https://www.youtube.com/watch?v=YJi3sBv2fRg
