고려대학교 강화학습
1.고려대학교 강화학습(오승상교수님) - 1. DRL Introduction

이제부터는 강화학습을 알아보겠습니다!강화학습은 기본적으로 Markov Decision Process라는 확률 모델을 기반으로 하고 있습니다. 저희가 다루는 모형에 대한 수학적인 모델링이기 때문에 Markov Decision Process를 잘 이해할 필요가 있습니다.
2.고려대학교 강화학습(오승상교수님) - 2. Markov property

이번 포스터에서 다룰 내용은 Markov Decision Process로 마르코브 의사결정 과정이라고 합니다!이 마르코브 의사결정 과정을 잘 설명할 수 있는 Grid world라는 모델을 소개하겠습니다.이 모델은 Dynamic programming과 Reinforcem
3.고려대학교 강화학습(오승상교수님) - 3. Markov Decision Process

오늘 다루어 볼 내용은 Markov Decision Process MDP : 마코프 의사결정 과정 이라고 합니다!MDP는 강화학습을 구현하는 기본적인 수학적 확률 모델입니다.Stochastic process {St}는 random variable의 컬렉션이라고 하는데
4.고려대학교 강화학습(오승상교수님) - 4. Reward and Policy

이번 포스터는 reward, return, policy등에 대해 알아보겠습니다.우선 reward에 대해 살펴보겠습니다.Reward는 Rt로 표현하며, agent가 한 행동이 얼마나 좋은지 안 좋은지 feedback하는 scalar값을 말합니다.agent는 한 polic
5.고려대학교 강화학습(오승상교수님) - 5. Bellman Equation

이번에는 Bellman Equation을 알아보겠습니다.컴퓨터가 계산하기 위해 수학적으로 잘 정리한 것이 MDP입니다. 이 MDP를 해결하기 위해 가장 기초적인 개념이 value ft인데 이 value ft을 계산하기 위한 것이 Bellman Equation입니다.우선
6.고려대학교 강화학습(오승상교수님) - 6. Bellman Equation 2

이전 포스터에서는 Bellman expectation Equation을 알아보았습니다. 강화학습의 목적은 value ft을 찾는 것이 아닌 reward를 최대화할 수 있는 policy를 찾는 것 입니다. 이를 optimal policy라고 하고, 이것을 찾기 위한 o
7.고려대학교 강화학습(오승상교수님) - 7. Dynamic Programming

이번 포스터는 Dynamic Programming으로 동적계획법에 대해 알아보겠습니다!복잡한 문제를 여러개의 간단한 문제로 나누어 효율적으로 푸는 방법입니다.DP는 planning (계획) 으로 <-> learning (학습) 과 상반됩니다.DP는 복잡한 문제를
8.고려대학교 강화학습(오승상교수님) - 8. Value Iteration

이번 포스터에서는 Value iteration에 대해 알아보겠습니다!Markov Decision Process문제를 해결하기 위해 나온 방법으로 DP와 강화학습이 있었습니다. Markov Decision Process문제를 해결한다는 것은 궁극적으로 optimal po
9.고려대학교 강화학습(오승상교수님) - 9. Policy Iteration

Dynamic programming 중에서 두 번째 방법인 policy iteration에 대해 알아보겠습니다.이전 포스터에서는 value iteration에 대해 알아봤는데 bellman potimality eq를 이용하였습니다. 이를 만족하는 optimal stat
10.고려대학교 강화학습(오승상교수님) - 10. Reinforcement Learning

이번 포스터부터는 Reinforcement Learning에 대해 알아보겠습니다!우선 DP와 RL에 대해 알아보겠습니다.가장 큰 차이는 DP는 planning, RL은 learning입니다.value ft table을 잘 업데이트 하는 것이 중요합니다.모든 state에
11.고려대학교 강화학습(오승상교수님) - 11. Monte Carlo method 1

이번 포스터에서는 Monte Carlo method에 대해 알아보겠습니다.MC는 반복적으로 random sampling을 사용하여 수칙 결과를 얻는 것 입니다.VAE 이해하기 위한 내용(3) - Monte carlo Algorithm이를 참고하시면 이해가 수월할 것 같
12.고려대학교 강화학습(오승상교수님) - 12. Monte Carlo method 2

이번 포스터에서는 이전 monte carlo에 이어 ε-greedy에 관해 알아보겠습니다!Exploitation : 이미 알고 있는 정보 내에서 가장 최선의 선택을 하는 것ex) 이미 알고 있는 밥집 중에서 가장 맛있는 집을 찾는 것이미 맛있는 곳을 가기에 안전하지만
13.고려대학교 강화학습(오승상교수님) - 13. Temporal Difference Learning

이번에는 Monte carlo method가 아닌 Temporal Difference Learning에 대해 알아보겠습니다! Temporal Difference Learning는 시간차학습을 말합니다. TD라고 하며 대표적인 알고리즘으로 Sarsa와 Q-learning
14.고려대학교 강화학습(오승상교수님) - 14. Temporal Difference Learning 2
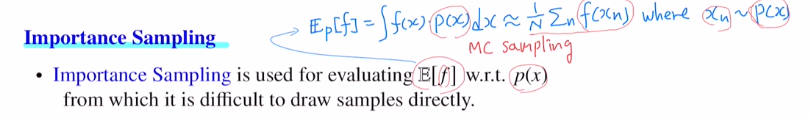
이번 포스터에서는 importance sampling에 대해 알아보겠습니다!MC, Sarsa의 경우느 target policy와 behavior policy가 같은 on policy입니다.이 경우 behavior policy를 임의적으로 다르게 하여 off policy
15.고려대학교 강화학습(오승상교수님) - 15. Temporal Difference Learning 3

이번 포스터에서는 강화학습에 관련된 몇 가지 예시와 sarsa와 q learning을 변형한 알고리즘을 알아보겠습니다.A에서 B로 갈 때 reward=0입니다. B에서 terminal state로 갈 때는 두 가지 종류로 나뉘어 1 or 0을 얻을 수 있습니다. 확률은
16.고려대학교 강화학습(오승상교수님) - 16. Deep Reinforcement Learning
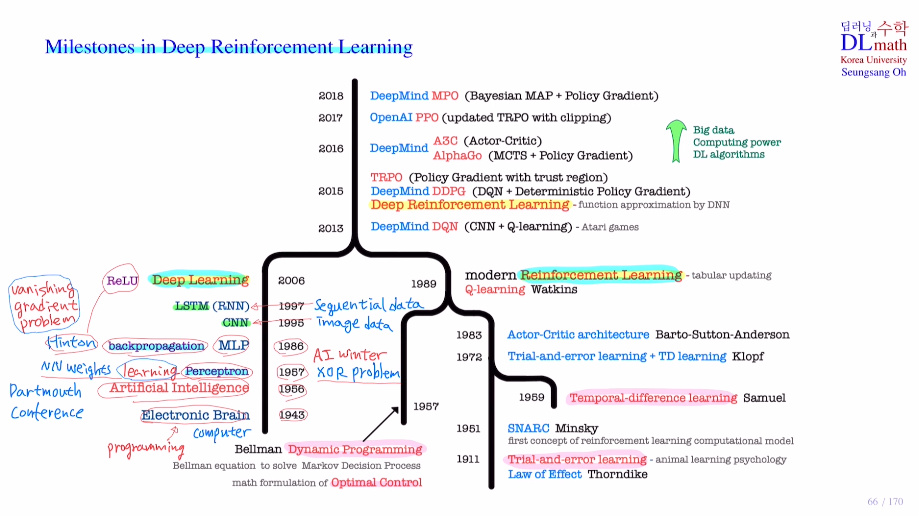
이제부터는 심층 강화학습 Deep Reinforcement Learning에 대해 알아보겠습니다! 우선 RL과 DRL의 차이를 알아보겠습니다. RL은 tabular updating method를 사용하고, DRL은 Function approximation metho
17.고려대학교 강화학습(오승상교수님) - 17. DQN 1
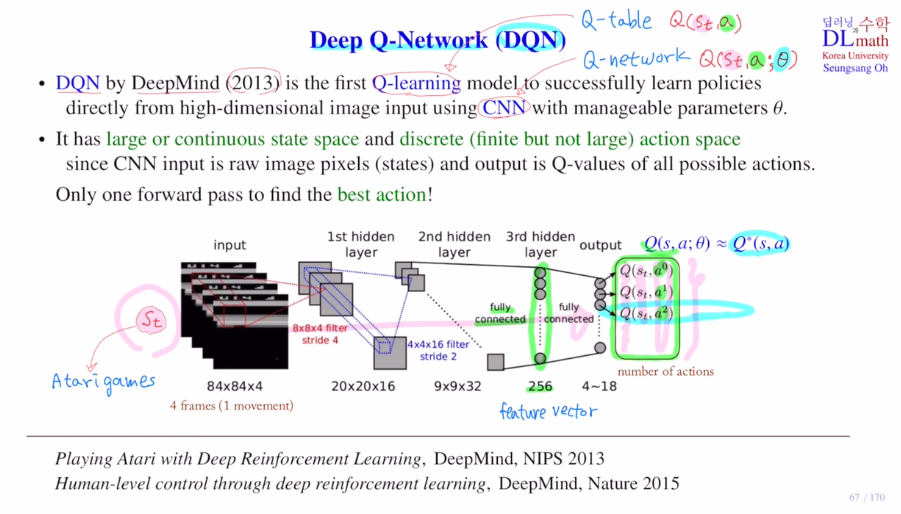
이번 포스터부터는 DQN을 배우겠습니다!DQN은 Q-learning과 CNN을 합쳐서 만든 것 입니다.이제는 Q-table을 사용하지 않고 Q-network를 통해 approximate합니다.궁극적으로 Qlearning을 적용할 때, 모든 action에 대해 Q val
18.고려대학교 강화학습(오승상교수님) - 18. DQN 2

이번에는 네이브 DQN의 문제를 해결하기 위해 나온 방법들을 이어서 알아보겠습니다!Target network : to overcome the non-statoinary target problem기존 Q네트워크를 업데이트 할 때 loss ft을 minimize하는 방향으
19.고려대학교 강화학습(오승상교수님) - 19. DQN variant

이번 포스터에는 DQN의 변형들을 알아보겠습니다!우선 Multi-step Learning에 대해 알아보겠습니다.DQN의 loss ft을 보면 target에 rt+1이 있습니다. 하지만 게임을 할 때 바로 다음 step의 reward도 중요하지만 어떨 때는 10step이
20.고려대학교 강화학습(오승상교수님) - 20. Dueling DQN
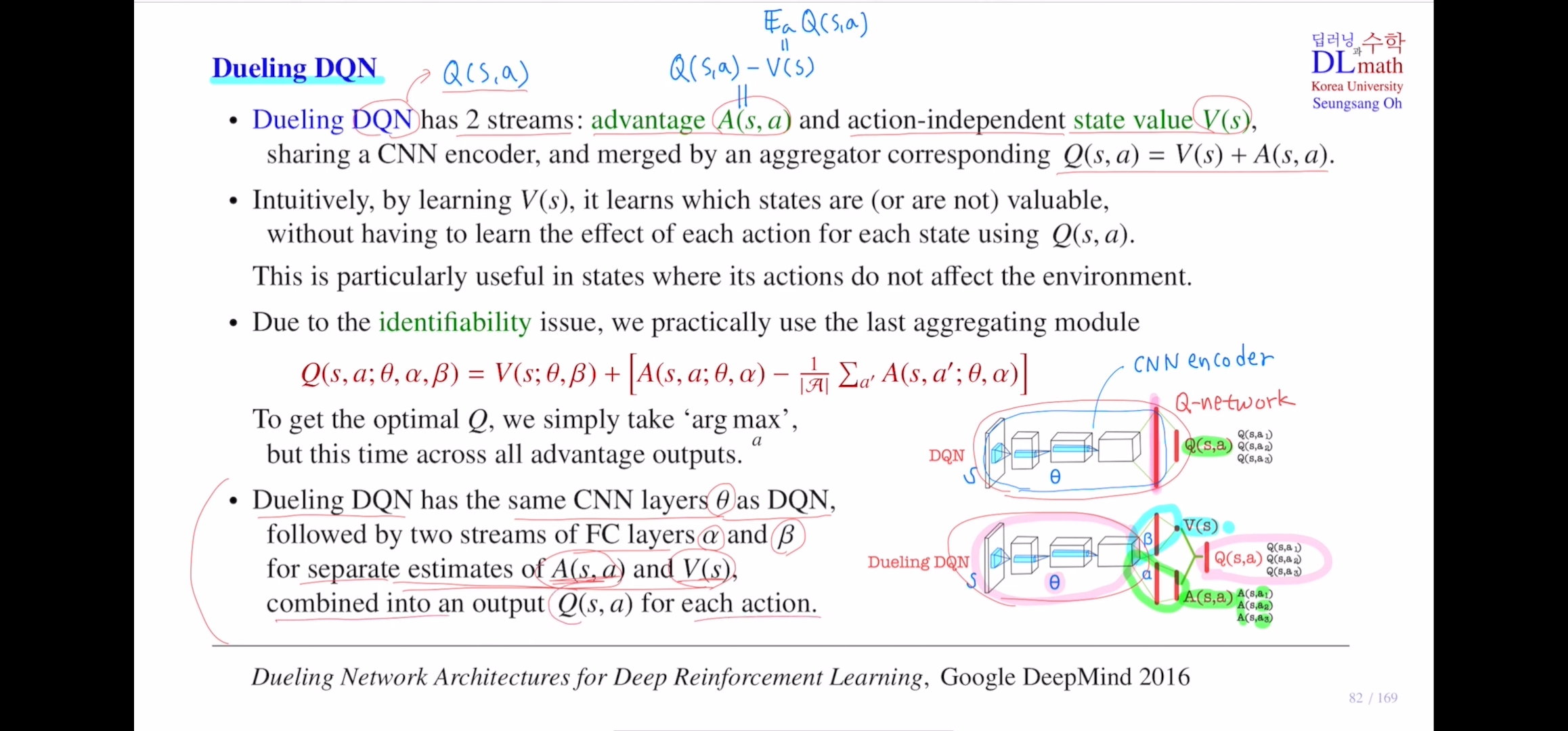
오늘은 dqn의 같은 계열로 dueling dqn을 알아보겠습니다!기존의 dqn은 output으로 모든 action에 대한 q value 값을 출력하는 것 이었습니다. 그래서 dqn의 핵심인 st가 들어오면 cnn을 사용합니다.dueling dqn은 q value ft
21.고려대학교 강화학습(오승상교수님) - 21. Policy Gradient algorithm

이번 포스터에서는 Policy Gradient algorithm에 대해 알아보겠습니다!이 알고리즘은 강화학습을 해결하는데 중요한 알고리즘입니다.DQN에서는 state space가 너무 넓기에 해결하는 방법들을 이전 포스터에서 알아봤습니다. DQN은 action spac
22.고려대학교 강화학습(오승상교수님) - 22. REINFORCE

Policy gradient는 DQN과는 구별되는 두 가지 특징이 있습니다.첫 번째는 neural network로 Q ft이 아닌 policy를 직접 학습한다는 점입니다. 따라서 output이 stochastic으로 action이 나옵니다. output으로 직접 act
23.고려대학교 강화학습(오승상교수님) - 23. Actor-Critic method

이번 포스터에서는 Actor-Critic method에서 알아보겠습니다!우선 DRL을 복습하자면Funcion approximation method로 state-action value ft이나 policy 를 DNN을 통해 approximating하는 것 이었습니다.va
24.고려대학교 강화학습(오승상교수님) - 24. A3C 1

이전 포스터에서 Actor Critic method를 알아봤는데, 이번 포스터에서는 Actor Critic알고리즘의 대표적인 A3C를 알아보겠습니다!A3C는 여러개의 네트워크를 같이 운용합니다. 하나는 global network이고, 나머지는 multiple worke
25.고려대학교 강화학습(오승상교수님) - 25. A3C 2

이전 포스터에 이어서 Asynchronous Advantage Actor-Critic :A3C를 알아보겠습니다!이번 포스터에는 Advantage부분을 집중해서 알아보겠습니다.Critic network에서 ad ft(=Qft - Vft)을 사용하는데 Q ft을 그대로 사
26.고려대학교 강화학습(오승상교수님) - 26. DDPG

지난 포스터까지는 Deep Reinforcement learning으로 DQN, REINFORCE, A3C를 알아보았다면, 이번 포스터부터는 Policy Gradient DRL으로 DDPG, TRPO, PPO에 대해서 알아보겠습니다!Deep Deterministic P
27.고려대학교 강화학습(오승상교수님) - 27. TRPO 1

이번 포스터에서는 Trust Region Policy Optimization: TRPO에 대해 알아보겠습니다!DDPG는 conti action space에서 다룰 수 있다는 장점이 있었습니다. 이를 다루기 위해서 stochastic이 아닌 deterministic po
28.고려대학교 강화학습(오승상교수님) - 28. TRPO 2

이번 포스터에서는 TRPO의 Minorization-Maximization algorithm을 통해 DDPG에서 어려움을 겪었던 monotonic improvement를 어떻게 해결할지 알아보겠습니다!1) old policy의 에타값을 사용해 추가적인 부분만 계산합니다
29.고려대학교 강화학습(오승상교수님) - 29. TRPO 3

TRPO에서는 Minorization-Maximization algorithm과 Trust region을 사용했습니다.Trust region을 사용하면 object ft인 expected return의 monotonic improvement가 보장되었고, 그렇기에 st
30.고려대학교 강화학습(오승상교수님) - 30. PPO

이전 포스터까지에서는 TRPO를 알아보았다면, 이번 포스터에서는 Proximal Policy optimization: PPO을 알아보겠습니다! TRPO에서는 monotonic improvement를 보장하기 위해 surrogate obeject ft을 MM알고리즘을
31.고려대학교 강화학습(오승상교수님) - 31. Distributional Reinforcement Learning

이번 포스터부터는 Distributional Reinforcement Learning에 대해 알아보겠습니다! 대표적인 알고리즘은 C51, QR-DQN, IQN이 있습니다. Distributional Reinforcement Learning의 기본 개념들을 알아보겠습니
32.고려대학교 강화학습(오승상교수님) - 32. C51

Distributional Reinforcement learning을 사용한 C51을 알아보겠습니다!Categoricla DQN이라고도 합니다.기본 아케텍쳐는 DNQ을 따르고 있고, distribution을 출력하는데 categorical하게 본다고 해서 categor
33.고려대학교 강화학습(오승상교수님) - 33. QR-DQN

이번 포스터는 QR-DQN에 대해서 알아보겠습니다!QR은 Quantile Regression입니다.여기서 재밌는 점은 기존에 이론적으로는 훌륭하나 practical하게 사용하기에는 어려웠던 wasserstein metric을 사용할 수 있게 됩니다.QR-DQN에서는 기
34.고려대학교 강화학습(오승상교수님) - 34. IQN

이번 포스터에서는 Implicit Quantile Network: IQN을 알아보겠습니다!우선 Distributional Reinforcement learing을 상기시켜 보겠습니다.이것의 핵심은 reward의 randomness에 초점을 맞춘 것 입니다.reward를