A Deep Reinforcement Learning Approach for Automated Cryptocurrency Trading
서론 및 Preview
본 논문에서는 딥 강화학습을 이용한 자동화된 암호화폐 거래 시스템을 제안하고, 특히 비트코인을 대상으로 연구가 진행됩니다. 두 가지 강화학습 알고리즘인 Double Deep Q-Network(D-DQN)과 Dueling Double Deep Q-Network(DD-DQN)이 약 4년 동안의 데이터를 사용해 비교되었으며, 이 두 모델의 성능을 평가하기 위해 두 가지 보상 함수가 실험되었습니다: Sharpe ratio reward function과 profit reward function입니다. 그 결과, Sharpe ratio를 기반으로 한 Double Deep Q-Network가 비트코인 거래에서 가장 높은 수익을 보여줬다는 것을 본 논문에서는 실험적으로 증명합니다.
본 논문에서 다룬 강화학습은 에이전트가 주어진 환경에서 스스로 학습하여 최적의 행동을 찾아가는 과정입니다. 여기서 D-DQN과 DD-DQN 두 알고리즘 모두 기본적으로 Q-learning 알고리즘을 기반으로 하고 있는데, 이를 통해 에이전트는 시장 데이터를 바탕으로 적절한 매매 전략을 도출합니다. D-DQN은 기존의 Q-learning에서 발생할 수 있는 과적합(overestimation) 문제를 해결하기 위해 두 개의 네트워크를 사용하는 방식으로 설계되었으며, DD-DQN은 이 구조에 추가로 dueling architecture를 적용해 특정 상태에서 더 나은 결정을 내릴 수 있도록 강화되었습니다.
Sharpe ratio는 금융 자산의 위험 대비 수익을 측정하는 지표로, 이를 보상 함수로 활용하면 리스크 관리가 더 잘 이루어진 거래 시스템을 설계할 수 있습니다. 반면, 수익 보상 함수는 단순히 최종 수익을 극대화하는 것을 목표로 합니다. 실험 결과, 수익만을 추구하는 보상 함수보다 샤프 비율 기반 보상 함수를 사용한 모델이 더 나은 성능을 보였으며, 이는 리스크 조정 후 수익률에서 큰 차이를 만들어냈습니다.
결론적으로 D-DQN과 DD-DQN을 적용한 실험에서, DD-DQN이 더 복잡한 시장 상황에서도 더 나은 성과를 보여주었으며, 특히 이중 신경망을 사용해 과적합 문제를 효과적으로 해결함으로써 더 안정적인 수익을 낼 수 있음을 실험적으로 증명합니다.
2. Cryptocurrency and Bitcoin
본 논문에서는 암호화폐와 비트코인, 그리고 이를 활용한 자동화된 거래 시스템에 대해 다룹니다. 암호화폐는 디지털 또는 가상 화폐로, 교환 수단으로 사용됩니다. 쉽게 말해서, 이는 특정 조건이 충족되지 않으면 누구도 변경할 수 없는 데이터베이스 내 제한된 항목들로 이루어져 있습니다. 비트코인은 2009년에 등장한 이후 가장 널리 알려진 암호화폐 중 하나로, 전통적인 화폐와 비교될 수 있을 만큼 가치를 인정받고 있습니다. 비트코인의 거래는 암호화 기법을 사용하는 네트워크 노드에 의해 검증되며, 이 거래는 블록체인이라 불리는 공개 분산 원장에 기록됩니다.
비트코인의 가격 정보는 특정 시간 간격에 따라 캔들스틱 차트(OHLC)로 표현됩니다. 캔들은 자산의 일정 기간 동안의 네 가지 가격 측정값, 즉 시가, 고가, 저가, 종가로 구성됩니다. 시가와 종가는 일반적으로 상자 모양으로 표시되며, 고가와 저가는 위아래로 뻗은 "꼬리"로 표시됩니다. 이러한 캔들은 더 큰 캔들로 쉽게 집계될 수 있으며, 예를 들어 1시간 캔들은 1분 단위의 60개의 캔들을 합쳐서 만들 수 있습니다.
2.1 Automated trading
자동화된 거래는 자산의 매수 또는 매도를 자동으로 결정하는 절차로 볼 수 있습니다. 보통 자동화된 거래 절차는 가까운 미래에 긍정적인 수익이 발생할지를 예측하는 데 중점을 둡니다. 즉, 주어진 자산을 매수할지, 매도할지 또는 보유할지를 결정하는 규칙을 따르게 됩니다.
자동화된 거래 절차는 시간 t에서 자산의 가격 가 주어졌을 때, 향후 h 시간 뒤의 예상 가격 와 현재 가격을 비교해 다음과 같은 결정을 내립니다: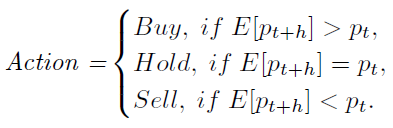
즉, 가 보다 크면 매수하고, 작으면 매도하며, 같으면 아무 행동도 하지 않는 방식입니다. 여기서 h는 미래의 시간 간격을 나타냅니다.
본 논문에서는 롱(long)과 숏(short)이라는 두 가지 시장 주문을 사용합니다. 롱 거래는 > 일 때 매수하여 시장이 상승할 때 수익을 얻는 방법이고, 숏 거래는 < 일 때 매도하여 시장이 하락할 때 수익을 얻는 방법입니다. 또한, 거래 전략을 정의할 때 흔히 사용되는 두 가지 명령은 stop-loss와 take-profit입니다.
Q ) stop-loss와 take-profit 란?
stop-loss와 take-profit은 거래자가 위험 관리와 수익 실현을 위해 자주 사용하는 두 가지 주요 주문 방식입니다. 각각의 개념을 더 자세히 설명하자면:
- stop-loss:
stop-loss는 특정 자산의 가격이 미리 설정한 손실 한도에 도달할 경우, 자동으로 해당 자산을 매도하는 주문입니다. 즉, 거래자가 예상한 방향과 반대로 가격이 움직여 손실이 발생할 가능성이 있을 때, 그 손실을 일정 수준에서 제한하기 위해 사용됩니다.
예시: 만약 비트코인을 $40,000에 매수했는데, 시장 상황이 악화될 것을 우려하여 $38,000에서 스탑-로스를 설정했다면, 비트코인의 가격이 $38,000에 도달하면 자동으로 매도됩니다. 이를 통해 추가적인 손실을 막고, 큰 하락에서 포지션을 보호할 수 있습니다.
즉, 시장 변동성에 의해 발생할 수 있는 감당할 수 없는 손실을 방지하는 것입니다. 거래자가 직접 시장을 모니터링하지 못하는 상황에서도 자동으로 매도되기 때문에 위험 관리의 중요한 도구로 사용됩니다.
- take-profit:
take-profit은 반대로, 자산 가격이 미리 설정한 수익 목표에 도달했을 때, 자동으로 해당 자산을 매도하여 수익을 확정 짓는 주문입니다. 자산의 가격이 목표 수익을 달성했을 때 자동으로 포지션을 종료함으로써, 추가적인 상승을 기다리다가 수익을 잃는 상황을 방지할 수 있습니다.
예시: 비트코인을 $40,000에 매수하고, 가격이 $45,000까지 오를 것을 예상하여 테이크-프로핏을 $45,000에 설정했다면, 비트코인의 가격이 $45,000에 도달하면 자동으로 매도됩니다. 이로써 거래자는 목표한 수익을 실현하고 시장의 갑작스러운 하락 위험에서 벗어날 수 있습니다.
take-profit은 과도한 욕심으로 인해 수익을 실현하지 못하고 손실로 전환되는 상황을 방지하기 위한 도구입니다. 미리 설정된 목표에 도달하면 즉시 수익을 실현할 수 있도록 도와줍니다.
4. Q-learning Trading System
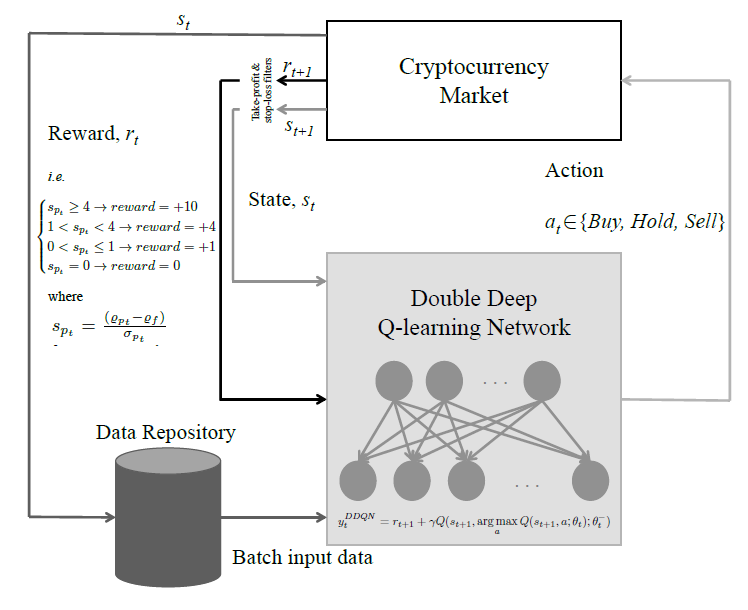
본 논문에서는 Q-learning을 기반으로 한 암호화폐 거래 시스템을 제안합니다.
이 시스템은 두 가지 방법론을 사용해요: 더블 딥 Q-네트워크(D-DQN)와 듀얼링 더블 딥 Q-네트워크(DD-DQN)입니다.
여기서 에이전트는 비트코인 시장의 상태에 따라 행동을 결정하고, 그 행동은 매수(buy), 보유(hold), 매도(sell)로 구분됩니다. 예를 들어, 비트코인을 매수하면 지갑에 추가되고, 매도하면 이익이나 손실을 계산하는 방식입니다.
거래 과정에서 stop-loss는 -5%, take-profit은 +12%로 설정되어 있어요. 예를 들어, 포트폴리오 손실이 5% 이상이면 모든 포지션이 자동으로 종료되고, 이익이 12%에 도달하면 자동으로 수익이 확정되죠.
-
exploration-exploitation 딜레마
강화학습에서는 exploration과 exploitation 사이의 균형이 중요합니다. exploration은 에이전트가 새로운 행동을 시도하면서 환경에 대한 정보를 수집하는 과정이고, exploitation은 현재 알고 있는 정보를 바탕으로 최대한 이익을 얻으려는 시도입니다. 본 논문에서는 ϵ-greedy 기법을 사용해요. 초기에는
ϵ=1로 설정해 모든 행동을 무작위로 선택하게 하고, 관측 횟수가 300번에 도달한 후 ϵ=0.12로 조정해 더 안정적인 행동을 선택하게 만듭니다. 거래 시에는 매수나 매도 시 0.3%의 거래 비용이 부과됩니다. -
Reward Function
에이전트의 학습을 위해 두 가지 보상 함수가 사용됩니다. 첫 번째는 Sharpe ratio이고, 두 번째는 단순 수익 함수입니다. Sharpe ratio은 포트폴리오 수익률을 위험(수익률의 표준편차)으로 나눈 값으로 정의됩니다: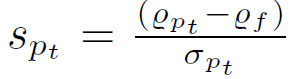
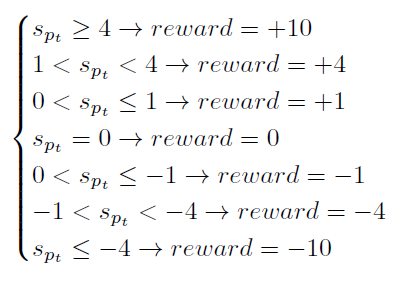
두 번째 방법론은 아래와 같습니다.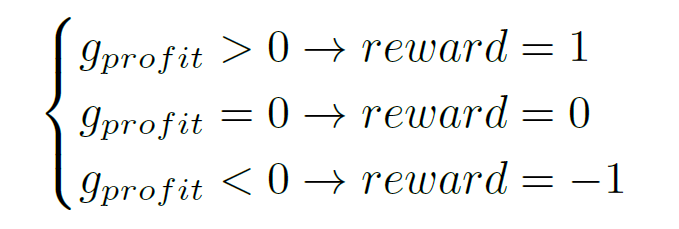
따라서 이러한 reward를 기반으로 아래와 같은 딥강화학습 방법론이 적용되며, DQN에 기반한 Double DQN과 Dueling Double DQN이 사용됩니다.
(활성화 함수로는 Leaky ReLU를 사용하고, 할인율 γ는 0.98로 설정)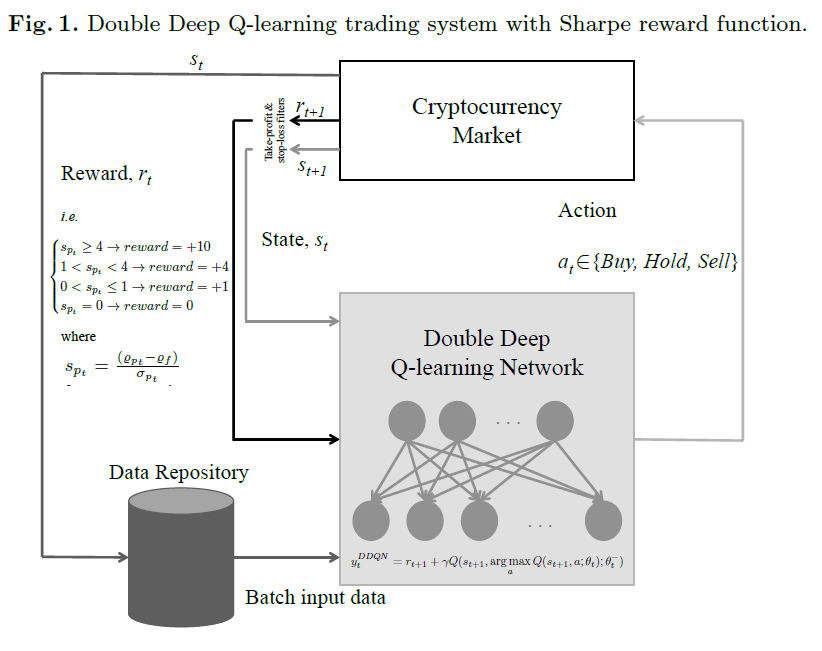
5 Experimental Data and Results
본 논문에서는 비트코인 거래 시스템을 자동화하기 위한 Q-러닝 기반의 알고리즘을 테스트했습니다. 사용된 데이터는 2014년 12월 1일부터 2018년 6월 27일까지의 비트코인 역사적 데이터를 기반으로 하며, 데이터를 분당으로 수집해 총 200만 개의 행과 8개의 변수(time stamp, OHLC(Open, High, Low, Close) values, volume in bitcoin, Volume in USD, Weighted Bitcoin Price)를 포함합니다. 이 데이터를 시간별로 집계해 최종적으로 3만 개 이상의 관찰값을 얻게 되었고, 이걸로 Q-러닝 시스템을 진행하게 됩니다.
- Q-러닝 기반 거래 시스템 설정
본 논문에서는 총 네 가지의 설정을 사용해 Q-러닝 시스템을 테스트했습니다.
Double Deep Q-Network (D-DQN)을 사용한 수익 보상 함수(ProfitD-DQN)
Double Deep Q-Network (D-DQN)을 사용한 샤프 비율 보상 함수(SharpeD-DQN)
Dueling Double Deep Q-Network (DD-DQN)을 사용한 수익 보상 함수(ProfitDD-DQN)
Dueling Double Deep Q-Network (DD-DQN)을 사용한 샤프 비율 보상 함수(SharpeDD-DQN)
이 네 가지 설정은 Deep Q-Network (DQN)을 기반으로 한 수익 보상 함수와 샤프 비율 보상 함수를 사용한 두 가지 다른 시스템과 비교되어 실험되었습니다.
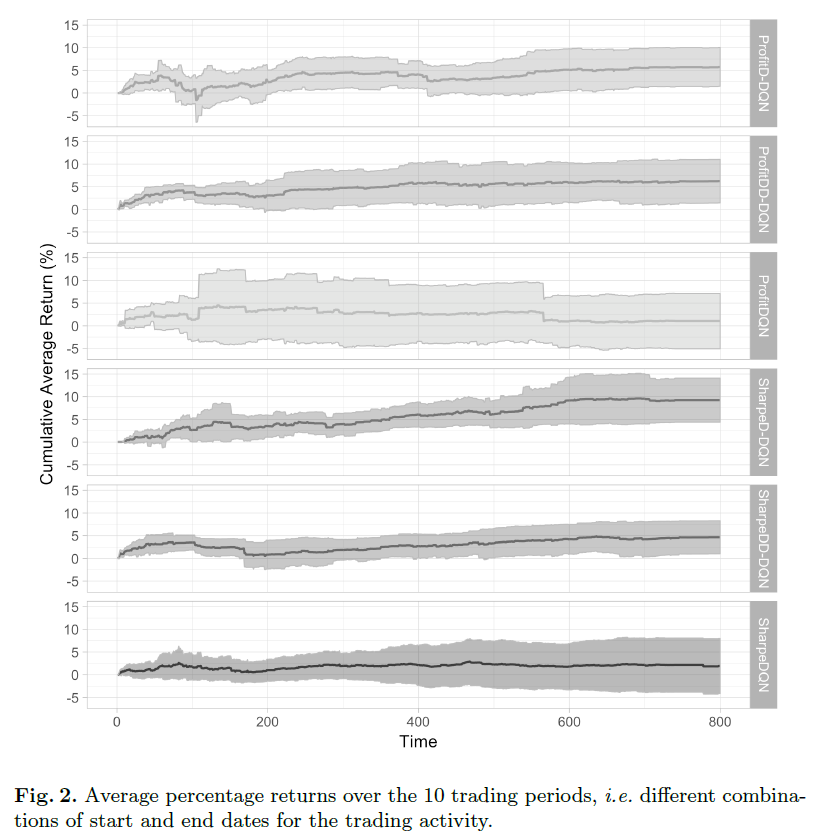
이 네 가지 설정의 성능은 10개의 다른 기간을 샘플링해 평가했습니다. 각 기간은 4000개의 관찰값으로 구성되며, 이 중 80%는 훈련에, 20%는 테스트에 사용되었습니다. 결과는 아래와 같습니다.
6 Conclusions and Future Work
본 논문에서는 딥 강화 학습을 활용한 거래 시스템을 비트코인 시간별 가격 데이터로 테스트했습니다. Double Deep Q-learning Network와 Dueling Double Deep Q-learning Network가 사용되었으며, 이들과 간단한 Deep Q-learning Network를 비교했습니다.
두 가지 보상 함수 1) Sharpe Ratio와 2)Profit을 사용해 성능을 평가했고, 비트코인 데이터(2014년 12월 1일~2018년 6월 27일)를 통해 테스트한 결과, 모든 시스템이 평균적으로 긍정적인 수익률을 보였습니다. 특히, SharpeD-DQN이 가장 높은 평균 수익률(8%)을 기록함을 확인할 수 있었습니다.
하지만 연구에는 한계점이 생각해 본다면, 다양한 성능 지표를 사용한 접근 방식의 필요성과 불확실성 추정도 고려되어야 할 것으로 생각됩니다.
이에 더하여 뉴스 데이터와 같은 추가적인 데이터를 거래 시스템에 통합하여 활용된다면, 현재 연구된 방안 뿐 아니라, Anomaly Detection 부문에서도 유용하게 사용될 것으로 생각됩니다.
