Activating More Pixels in Image Super-Resolution Transformer
1. 서론 및 Preview
본 논문에서는 Transformer 기반의 이미지 초해상도(SR) 모델이 성능은 뛰어나지만, 입력 정보를 충분히 활용하지 못하는 한계를 발견했습니다. 이를 해결하기 위해 Hybrid Attention Transformer(HAT)라는 새로운 구조를 제안합니다.
기존 Transformer 모델은 Self-Attention 메커니즘 덕분에 장거리 정보를 잘 처리하지만, 국소적인 정보 처리에서는 제약이 존재했습니다. 본 논문은 이를 극복하기 위해 Channel Attention과 Window 기반의 Self-Attention을 결합한 HAT 모델을 제시합니다. Channel Attention은 전역적인 통계를 잘 반영하고, Window 기반 Self-Attention은 국소적인 정보를 잘 처리하는 장점이 있기 때문에 두 방법을 함께 사용해 서로 보완합니다.
하지만 이 두 메커니즘만으로는 충분하지 않았기 때문에, 추가적으로 Overlapping Cross-Attention 모듈을 도입했습니다. 이 모듈은 인접한 윈도우 간의 상호작용을 강화시켜, 더욱 많은 입력 픽셀을 활성화할 수 있도록 설계되었습니다. 이러한 설계 덕분에, 모델은 더 나은 재구성을 할 수 있게 됩니다.
또한, HAT의 성능을 극대화하기 위해 본 논문에서는 Same-task Pre-training 전략을 도입했습니다. 기존의 IPT나 EDT 모델은 여러 복원 작업이나 다양한 손상 수준을 다룬 사전 학습을 사용했지만, 본 논문은 동일한 SR 작업을 위해 대규모 데이터를 사용한 사전 학습을 제안합니다. 실험 결과, 이 전략이 SR Transformer의 잠재력을 더욱 효과적으로 끌어낼 수 있음을 확인했습니다.
실험적으로 HAT는 기존의 최첨단 모델들을 성능 면에서 큰 폭으로 앞질렀습니다. 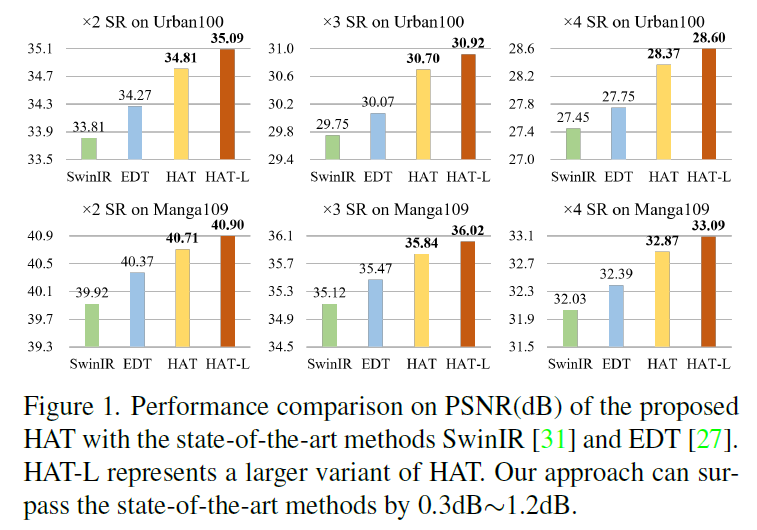 구체적으로, 최대 1.2dB까지 성능 향상을 보여줬으며, 특히 대규모 모델로 확장했을 때 SR 작업의 성능 상한선을 크게 확장할 수 있었습니다.
구체적으로, 최대 1.2dB까지 성능 향상을 보여줬으며, 특히 대규모 모델로 확장했을 때 SR 작업의 성능 상한선을 크게 확장할 수 있었습니다.
정리하면, 본 논문은 HAT 모델을 통해 더 많은 입력 픽셀을 활성화하여 이미지 초해상도 문제에서 더 나은 성능을 달성할 수 있음을 보여줍니다.
2. Related Work
본 논문에서는 이미지 초해상도(SR) 작업에서 Transformer의 잠재력을 최대한 끌어내기 위해, 기존의 방법들과 Transformer 기반 네트워크들의 발전 과정을 살펴보고 있습니다.
먼저, 깊은 신경망을 활용한 이미지 SR 작업을 보면, SRCNN이 처음으로 CNN을 SR에 도입하면서 전통적인 SR 방법들보다 뛰어난 성능을 보였습니다. 이후로도 수많은 딥러닝 모델들이 등장했는데, 예를 들어 Residual Block이나 Dense Block을 적용해 모델의 표현 능력을 강화한 방법들입니다. 그리고 최근에는 Transformer 기반 네트워크들이 등장하면서 SR 작업의 성능을 끊임없이 갱신하고 있습니다.
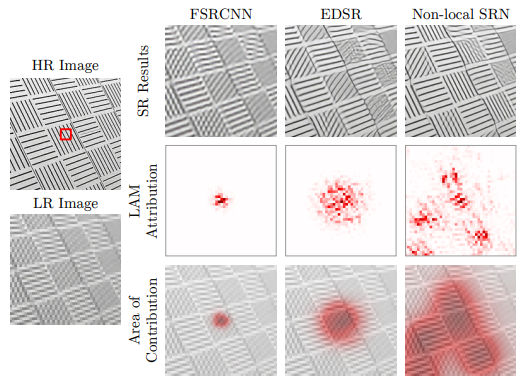
본 논문에서는 LAM(local attribution map) 방법을 사용하여 SR 네트워크가 어떤 입력 픽셀이 최종 성능에 가장 많이 기여하는지 분석했습니다. 이 방법을 통해, 기존의 Transformer 모델이 입력된 픽셀을 충분히 활용하지 못하고 있다는 사실을 발견했습니다. 이를 보완하기 위해 Hybrid Attention Transformer(HAT)를 제안하게 되었죠.
LAM이란?
Interpreting super-resolution networks with local attribution maps, CVPR 2021에 소개된 기법
기존 gradient-based attribution analysis 기법인 integrated-gradient 기법을 image super-resolution으로 확대한 것!
Transformer는 자연어 처리에서 큰 성공을 거두면서 컴퓨터 비전 분야에서도 주목을 받았습니다. 특히 이미지 분류, 객체 탐지, 이미지 분할 같은 고수준 비전 작업에서 Transformer 기반의 방법들이 많이 개발됐고, 이는 장거리 의존성을 잘 모델링할 수 있는 Transformer의 특성 덕분이죠. 하지만 많은 연구에서 여전히 Convolution이 Transformer의 시각적 표현력을 개선할 수 있음을 보여줍니다.
Transformer는 이제 저수준 비전 작업에도 도입되고 있습니다. 예를 들어, IPT는 ViT 스타일의 네트워크를 개발하고, 여러 작업을 결합한 사전 학습을 제안했으며, SwinIR은 이미지 복원을 위한 Transformer 모델을 제안했습니다. 하지만 본 논문은 기존의 Transformer 기반 SR 모델들이 입력 픽셀을 충분히 활용하지 못하는 한계를 지적하고, 이를 극복하기 위해 HAT를 설계하여 더 많은 픽셀을 활성화하고, 더 나은 재구성 결과를 얻을 수 있음을 보여줍니다.
결론적으로, Transformer는 장거리 의존성을 모델링하는 데 강력한 능력을 가지고 있지만, Convolution과 같은 전통적인 방법들과의 결합, 그리고 입력 정보를 보다 효과적으로 활용할 수 있는 전략을 통해 그 잠재력을 극대화할 수 있다는 사실을 다시 한번 확인할 수 있습니다.
3. Methodology
3.1. Motivation
본 논문에서는 Swin Transformer가 이미지 초해상도에서 우수한 성능을 보여주지만, 왜 CNN 기반의 방법보다 더 잘 작동하는지 알아내기 위해 위에서 언급한 LAM(local attribution map)이라는 진단 도구를 사용했습니다. LAM은 특정 영역을 복원하는 데 어느 입력 픽셀이 가장 중요한지 보여주는 기법인데, 이를 통해 Transformer와 CNN의 차이를 분석할 수 있었습니다.
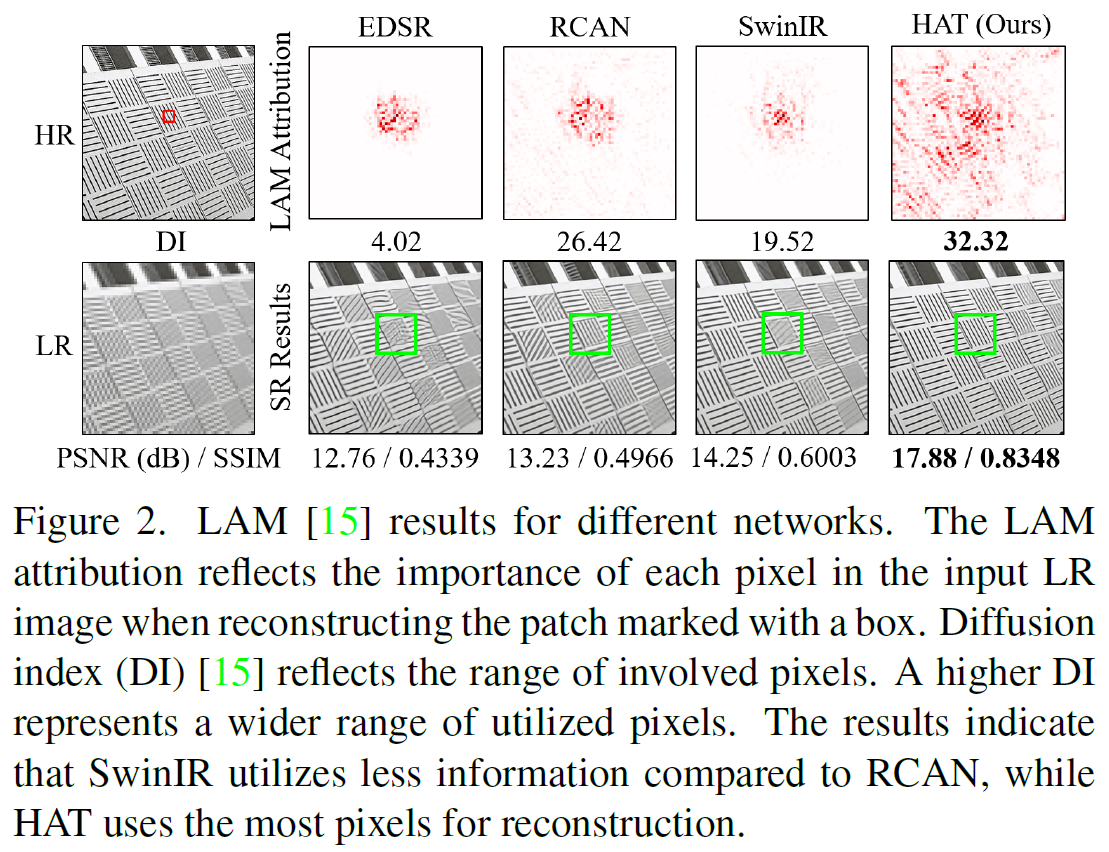
LAM 결과를 보면, SwinIR이 사용하는 정보의 범위가 RCAN 같은 CNN 기반 모델보다 넓지 않았습니다. 직관적으로는 더 많은 입력 정보를 활용할수록 성능이 좋아질 것 같은데, SwinIR은 그만큼의 정보를 사용하지 않으면서도 더 나은 성능을 냅니다.
=> 이건 두 가지 중요한 시사점을 줍니다. 첫째, SwinIR은 CNN보다 훨씬 강력한 매핑 능력을 가지고 있어서, 적은 정보를 사용해도 더 좋은 성능을 내는 거죠. 둘째, SwinIR이 픽셀의 제한된 범위를 사용하다 보니 잘못된 텍스처를 복원할 가능성이 있는데, 더 많은 픽셀을 활용할 수 있다면 성능이 더 향상될 수 있다는 점입니다.
따라서 본 논문에서는 Transformer의 셀프 어텐션 장점을 그대로 살리면서 더 많은 입력 픽셀을 활성화해 더 나은 복원을 할 수 있는 네트워크를 설계했습니다. 본 논문에서 제안한 Hybrid Attention Transformer(HAT)는 이미지 거의 모든 픽셀을 활용해 정확하고 선명한 텍스처를 복원할 수 있었습니다.
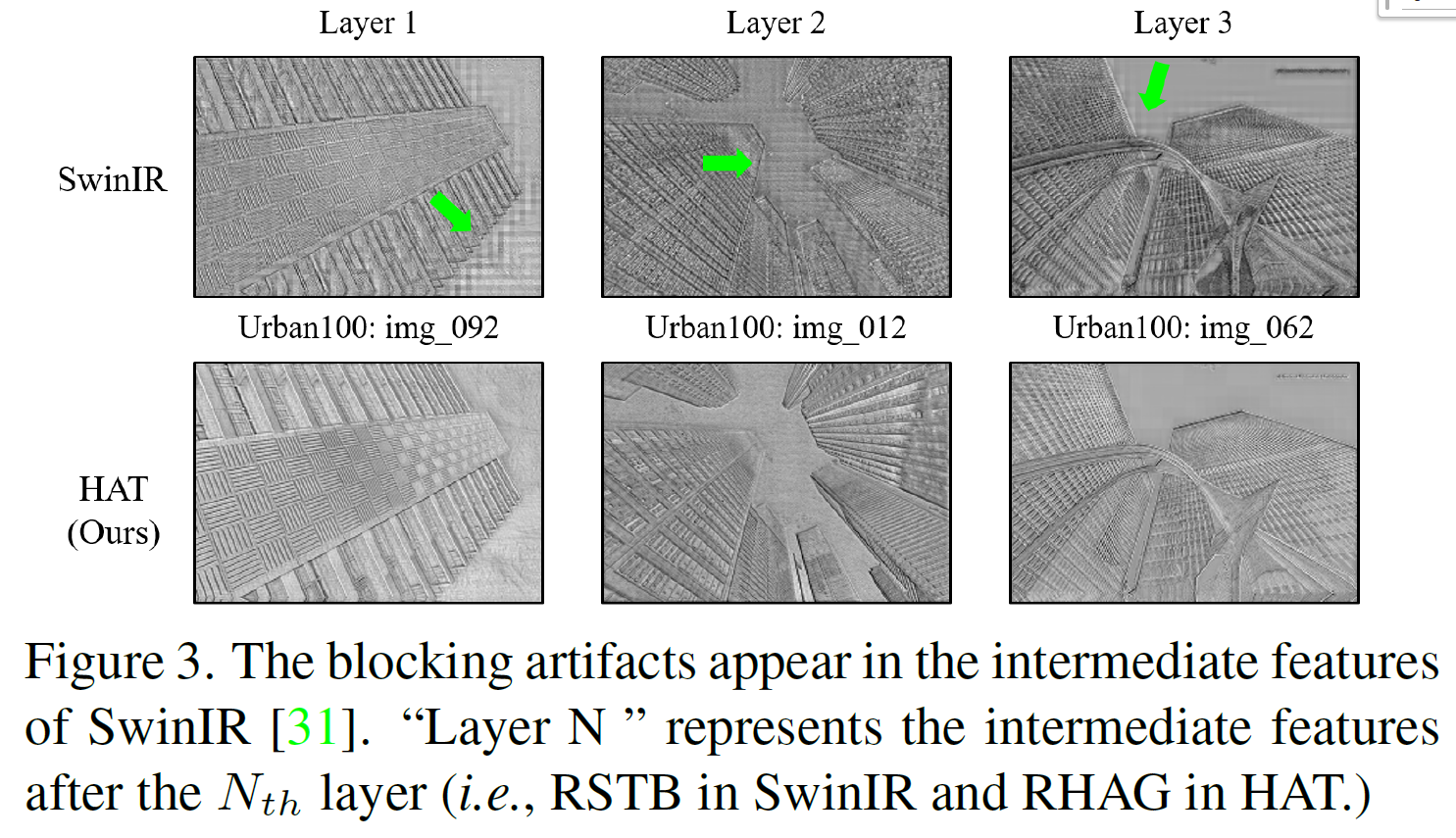
또한 SwinIR의 중간 특징에서 블록 아티팩트가 나타났는데, 이는 window 기반의 파티션 메커니즘 때문이라고 합니다. window 간의 연결이 제대로 이루어지지 않아서 생기는 문제였죠. 이 문제를 해결하기 위해 본 논문에서는 window 사이의 상호작용을 강화해 이러한 아티팩트를 크게 줄였습니다.
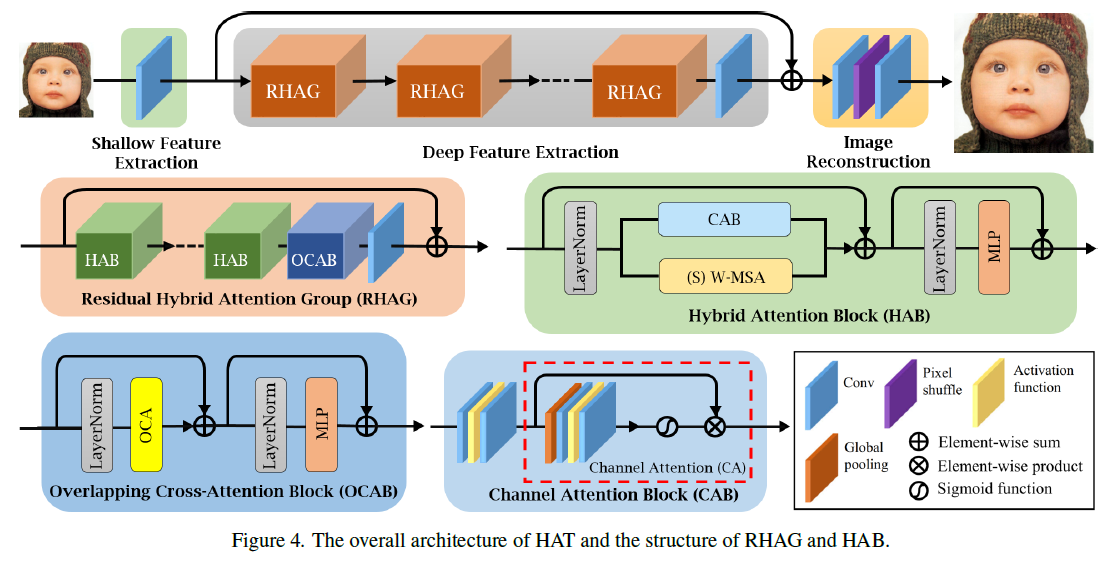
3.2. Network Architecture
본 논문에서 제안한 네트워크는 크게 세 가지로 나뉩니다
: shallow feature extraction / deep feature extraction / image reconstruction.
기본적으로 저해상도 이미지를 입력받아서 고해상도 이미지를 복원하는 구조입니다.
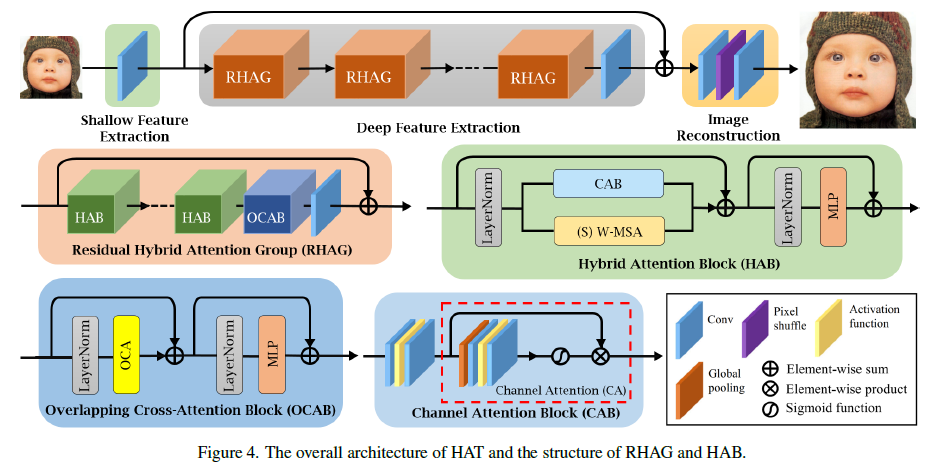
먼저, 저해상도 입력에 대해 shallow feature를 추출합니다. 이렇게 추출된 faeture를 여러 개의 RHAG를 통해 deep한 feature를 뽑게 됩니다. 여기서 global residual connection을 통해 앞에서 추출한 shallow feature와 지금까지 추출한 deep feature를 결합해 줍니다.
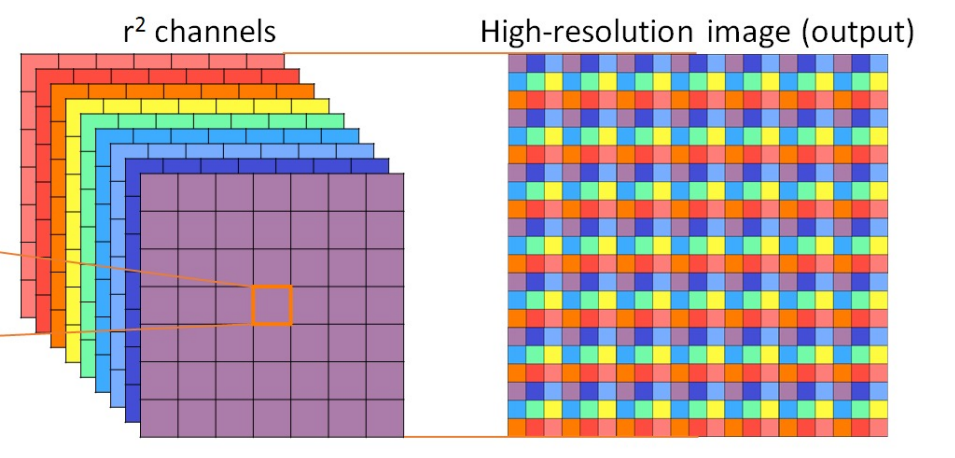
마지막으로 image reconstruction에서는 pixel-shuffle에 기반하여 고해상도 이미지를 만들어 내는 것 입니다.
(여기서 L1 loss function으로 최적화를 진행합니다.)
High Resolution을 얻기 위한 Pixel Shuffle이란?
코드 : torch.nn.PixelShuffle / PixelUnshuffle
본 아키텍쳐에 OCAB가 존재하는데 이 부분에 대해서 자세하게 살펴보겠습니다.
본 논문에서 기존 Swin Transformer의 윈도우 기반 셀프 어텐션 방식에서 발생하는 한계를 극복하기 위해 Overlapping Cross-Attention Block (OCAB)을 도입했습니다. 이 블록은 윈도우 간 연결성을 직접적으로 강화하고, 셀프 어텐션의 표현력을 높이는 데 중점을 두고 있습니다.
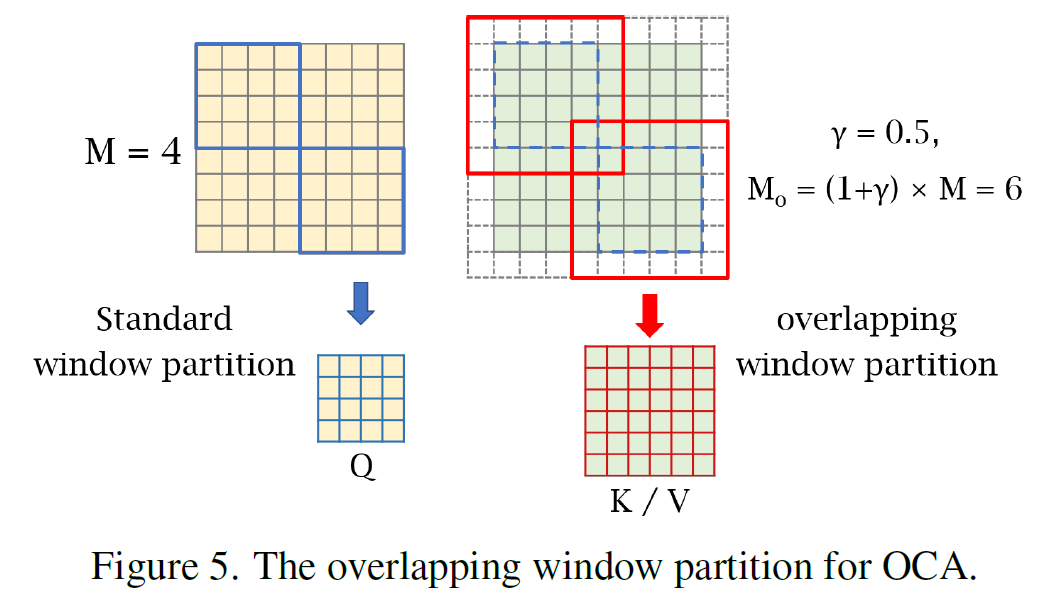
OCAB의 구성은 크게 두 가지로 나눌 수 있습니다: Overlapping Cross-Attention (OCA) 레이어와 MLP 레이어입니다. OCA는 본질적으로 Swin Transformer 블록과 비슷하지만, 윈도우를 나누는 방식에 차이가 있죠. 본 논문에서는 서로 다른 윈도우 크기를 사용해서 입력 특징을 분할하는데, 이것이 기존 방식과 차별점입니다.
기존의 WSA(Window-based Self-Attention)에서는 동일한 윈도우 내에서 쿼리, 키, 값을 계산하지만, OCA에서는 더 큰 필드에서 키와 값을 가져와 더 많은 정보를 활용해 쿼리를 처리해요. 이를 통해 더 넓은 범위의 유용한 정보를 쿼리에 반영할 수 있는 것 입니다.
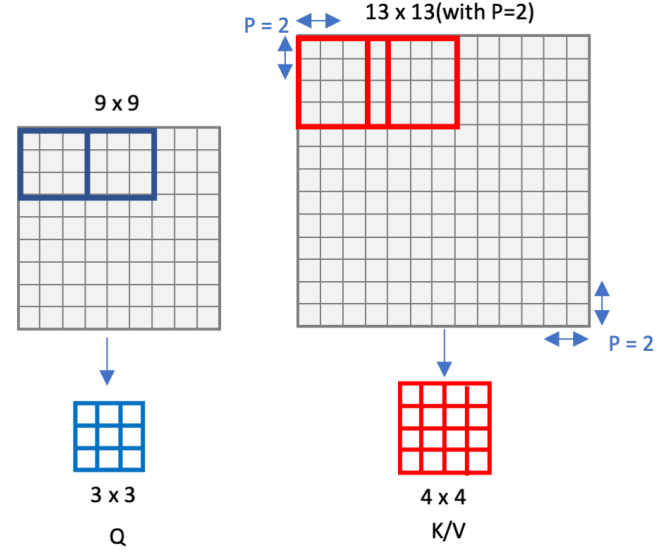
물론, 비슷한 방식으로 기존에 겹치는 윈도우를 활용하는 모듈이 Multi-resolution Overlapped Attention (MOA)로 존재합니다. 하지만 MOA는 윈도우 특징을 토큰으로 사용해 글로벌 어텐션을 계산하는 반면, 본 논문에서 제안한 OCA는 각 윈도우 내에서 픽셀 토큰을 사용한 크로스 어텐션을 계산한다는 점에서 근본적인 차이가 있습니다.
이렇게 OCAB를 통해 윈도우 간의 정보 교환을 강화하고, 이를 통해 네트워크가 더 많은 픽셀 정보를 활용하도록 유도하면서도 계산 효율성을 유지할 수 있게 됩니다.
3.3. The Same-task Pre-training
본 논문에서는 Same-task Pre-training이라는 전략을 제안합니다. 기존 연구들은 주로 여러 과제를 동시에 학습하는 Multi-task pre-training을 많이 사용했지만, 본 논문은 같은 작업에서 pre-training을 수행함으로써 더 간단한 방식으로도 성능을 향상시킬 수 있음을 보여줍니다.
pre-training이 효과적이라는 건 많은 고수준 비전 작업에서도 입증된 사실이죠. 예를 들어, IPT에서는 노이즈 제거나 비 제거, 초해상도 같은 여러 저수준 작업을 학습하고, EDT에서는 특정 작업의 다양한 열화 수준에 대해 pre-training을 수행했습니다. 하지만 이러한 기존 연구들은 대부분 여러 작업을 동시에 학습해 목표 작업에 미치는 영향을 분석하는 데 집중했습니다.
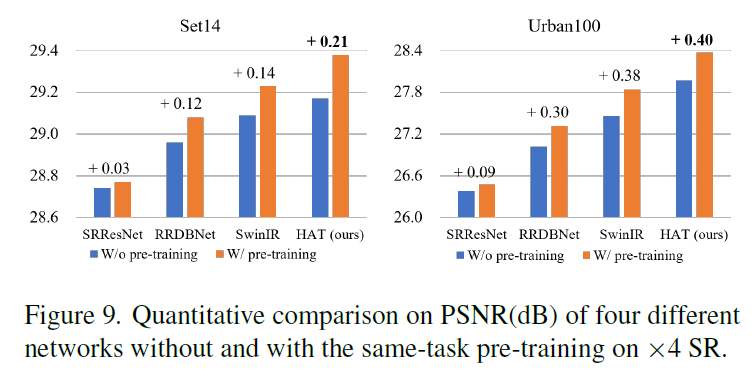
본 논문에서는 이와는 다르게, 같은 작업을 대규모 데이터셋에서 pre-training함으로써 더 단순하지만 효과적인 방식을 제시합니다. 예를 들어, 4배 확대 초해상도(×4 SR) 모델을 학습하고 싶다면, 처음부터 ImageNet 데이터셋에서 4배 확대 초해상도 모델을 먼저 학습한 뒤, 이를 더 작은 특정 데이터셋인 DF2K로 파인튜닝합니다. 이렇게 같은 작업에 대한 pre-training을 통해 성능 개선이 가능하다는 것을 보여줘요.
여기서 중요한 포인트는 충분한 pre-training 반복 학습 횟수와 적절한 작은 학습률이 pre-training 전략의 효과를 극대화하는 데 매우 중요하다는 것 입니다. 이는 Transformer 모델이 일반적인 지식을 학습하기 위해 더 많은 데이터와 반복 학습이 필요하고, 특정 데이터셋에 오버피팅을 방지하기 위해 파인튜닝 시 작은 학습률이 필요하기 때문입니다.
이렇게 본 논문에서는 단일 작업에서 더 큰 데이터셋을 사용한 pre-training이 더 간단하면서도 효과적인 전략임을 증명했습니다.
5. Conclusion
본 논문에서는 image super-resolution 분야에서 새로운 하이브리드 어텐션 트랜스포머 모델인 HAT을 제안합니다. 이 모델은 channel attention과 self-attention을 결합하여 더 많은 픽셀을 활성화하고, 이를 통해 고해상도 이미지 복원을 달성합니다.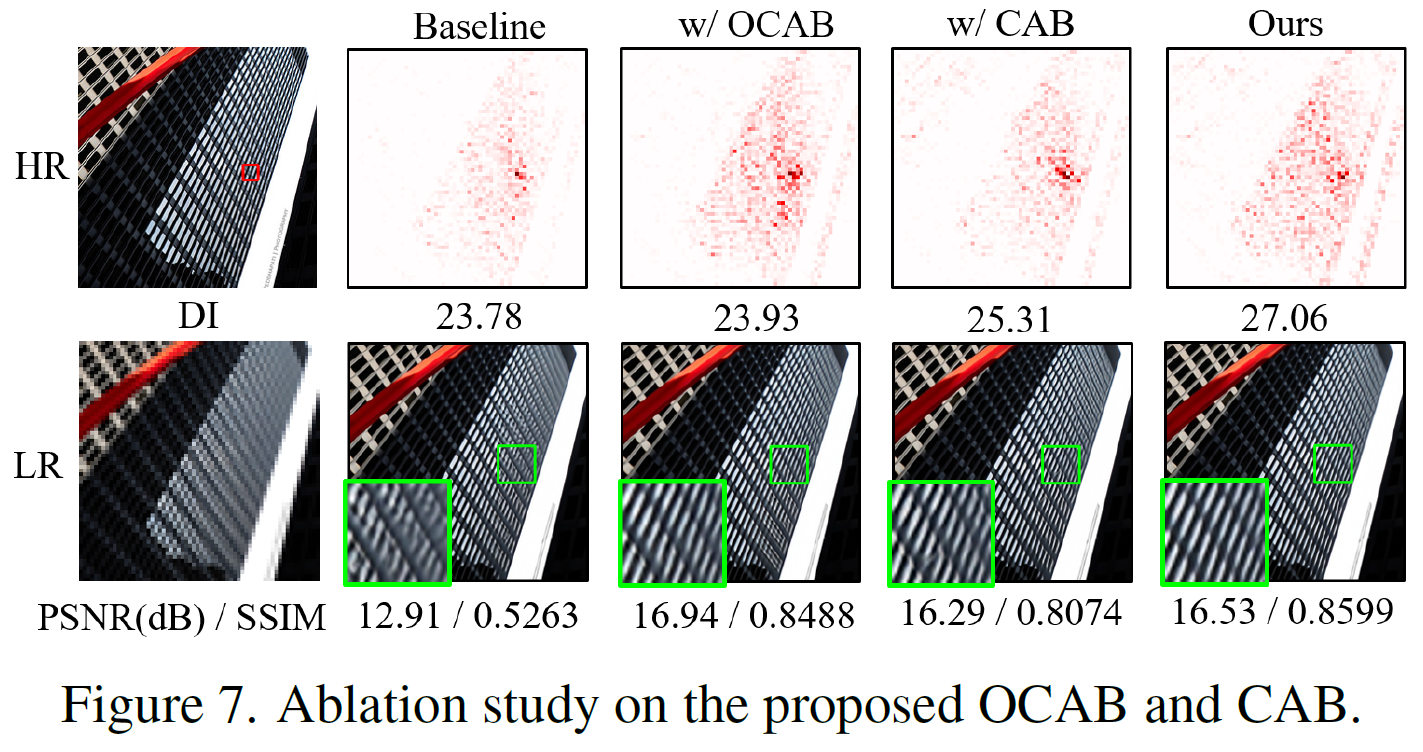
HAT은 두 가지 주요 구성 요소를 포함하고 있습니다. 첫째, 채널 어텐션을 통해 입력 이미지의 각 채널에서 중요한 정보를 강조하여 복원 성능을 향상시킵니다. 둘째, overlapping cross-attention module을 도입하여 윈도우 간 정보 상호작용을 강화합니다. 이 모듈은 윈도우 크기를 다르게 설정하여 입력 feature를 겹치도록 나누어, 더 많은 정보가 서로 연결되도록 합니다.

또한, 본 논문에서는 동일 작업을 위한 same-task pre-training 전략을 도입했습니다. 이 전략은 대규모 데이터셋(ex. ImageNet)에서 같은 작업에 대해 사전 학습을 수행하여 HAT의 잠재력을 더욱 극대화합니다. 이러한 프리트레이닝 전략은 모델의 성능을 크게 향상시키며, HAT이 기존의 최신 방법들보다 정량적, 정성적으로 우수한 성능을 보임을 보여줍니다.
실험 결과, 제안된 모듈과 프리트레이닝 전략이 효과적이라는 것이 입증되었dmau, HAT은 다양한 벤치마크 데이터셋에서 다른 최신 방법들보다 월등한 성능을 나타냄을 확인합니다.
