Pipeline
지금까지 Single Cycle과 Multiple Cycle에 대해서 알아 보았다.
이제는 이들의 장점들을 결합한 Pipeline에 대해 알아보자!
CPU설계의 대부분은 Pipelining설계로 이루어져 있다.
이것을 쓰는 목적은 CPU의 성능을 향상시키는 것 인데, 이 이유는 한 번에 여러 명령어가 CPU에서 실행되기 때문이다. 이와 같이 각 실행의 시간은 똑같지만 잘 파이프라이닝을 함으로 단위 시간 당 일의 양을 늘려 빠른 시간 내에 수행이 끝나도록 하는 것이 주 목적이다.
여기서도 마찬가지로 Multiple에서 잘 고려해야할 문제와 같이 각 시간이 얼마나 걸리는 지를 고려하여 밸런스를 잘 분배해야 한다.
Q. 그렇다면 Pipelining을 함으로 무조건 시간이 빨라질까?
이를 한 번 수학적으로 살펴보자.
Pipelining이 없을 때 걸리는 시간은 Ts = n T 라고 하고,
Pipelining이 있을 때 걸리는 시간은 Tp = (n+k-1) T/k 라고 할 수 있다.
이 때, Speed up을 구하면 Sp = Ts/Tp = (n* k) / (n+k-1) = k / (1+k/n-1/n)이 된다.
여기서 n이 굉장히 큰 수가 된다면 k가 되기에 수행 시간이 줄어듬을 수식적으로 확인할 수 있다.
따라서 Pipelining stage가 늘어남에 따라 Speed up이 일어난다고 이야기 할 수 있다.
그렇다면 실제 MIPS에 있어서 Pipelining을 어떻게 하는 지 살펴보자.
우선 다섯 가지 종류로 나누어 볼 수 있다.
-
Instruction fetch step (IF)
-
Instruction decide/register fetch step (ID)
-
Execution/effective address step (EX)
-
Memory access (MEM)
-
Register write-back step (WB)
이는 Multiple cycle과 똑같아 보이지만 굉장히 중요한 큰 차이점을 가지고 있다.
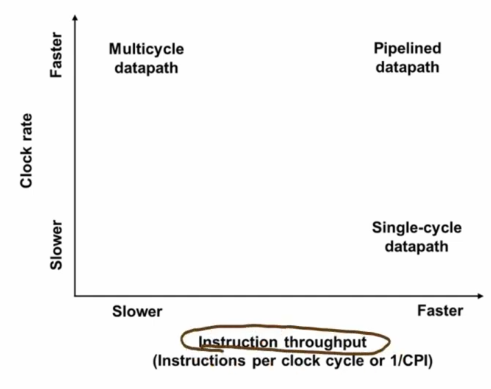
바로 IF -> ID -> EX -> MEM -> WB 이 실행될 때, 하나씩 넘어가는 것이 아니라 하나가 끝나면 그 즉시 바로 다음 단계가 그 자리에서 수행이 되는 것이다!
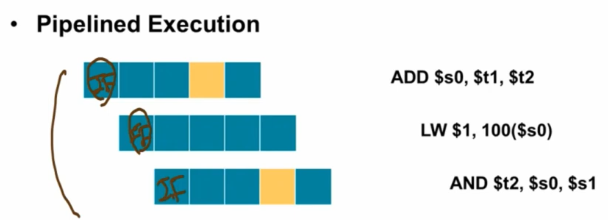
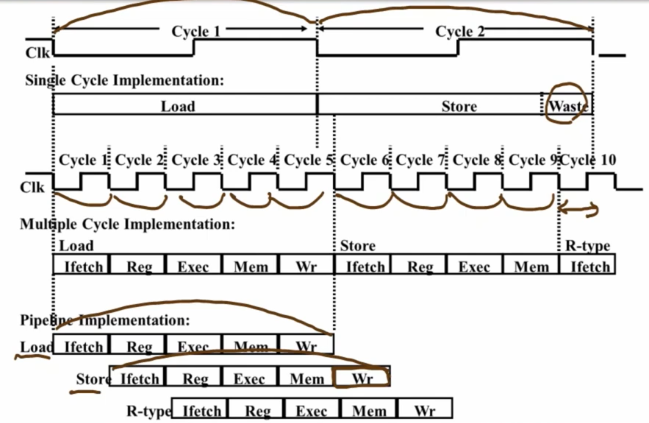
아래와 같이 세 가지를 비교할 수 있으며, Single Cycle과 달리 Multiple Cycle에서 cycle의 길이를 가변적으로 함으로 Waste부분의 이점을 얻을 수 있고, Pipelining에서는 모두 똑같은 Cycle주기를 갖지만 설계를 함으로 Multiple 보다 단축된 시간을 얻을 수 있게 되는 것이다!
이제는 Pipelining을 돕거나 방해하는 조건을 확인해 보자.
MIPS에서 Pipelining을 하기 좋은 이유는 모든 명령어의 길이가 똑같다. 그렇기에 실행시간이 일정하게 된다. 이에 대한 이점은 항상 32비트 명령어이기에 일정한 속도로 명령어를 읽을 수 있어 IF단의 시간이 똑같아 파이프라이닝이 쉽고, instruction memory에서 가져오는 시간이 단축될 수 있다.
이를 통해 명령어가 굉장히 규칙적으로 실행되고, 실행되는 시간이 예측 가능하며 쉽게 파이프라이닝이 가능하다.
=> 파이프라이닝을 할 때 발생하는 어려움들이 세 가지 존재한다.
1) structural hazards
메모리가 하나밖에 없을 경우 ex) instruction memory가 하나 밖에 없을 경우 Pipelining을 하기가 어렵다. 왜냐하면 계속해서 IF에서 access를 하려고 하고 MEM에서도 access를 하려고 하는데 하나로는 벅차기 때문이다.
2) data hazards
서로 다른 명령어들 간의 dependency가 있는 경우이다. 어떤 명령어를 실행하기 위해서 이전 명령어를 받아와야 하는데, 만약 받아 오기 위해서 이전 명령이 끝나야 한다면 Pipelining을 하기에 어려울 것이다.
3) control hazards
명령어들이 저장되어 있는 순서대로 실행된다면 혹은 다음 번 명령어가 무엇인지 안다면 Fetch를 미리미리 해 두어 파이프라인에 넣어 두는 것인데, 만약 jump나 beq의 경우는 이것을 지키지 않는다. 기록된 순서를 뛰어 넘어 실행하는 것이기에 이 때는 Pipelining이 깨지게 되는 것이다.
=> 이 이외에도 modern processor에서 exception handling이나 out-of-order execution 등들에 의해 Speed up을 떨어지게 만들고, Pipelining을 복잡하게 만드는 것이다.