
HPA(Horizontal Pod Autoscaler)란?
HPA는 파드 개수를 자동으로 늘렸다 줄였다 해주는 컨트롤러이다.
보통 CPU 사용량이나 메모리 사용량, 혹은 커스텀 메트릭을 기준으로 스케일링한다.
동작 흐름은 대략 이렇다.
- metrics-server 가 각 파드/노드의 CPU·메모리 사용량을 모은다.
- HPA 컨트롤러가 metrics.k8s.io API를 통해 현재 사용량을 읽는다.
- Deployment 에 설정된 목표 사용률(target) 과 비교한다.
- 목표보다 높으면 파드 수 증가, 낮으면 파드 수 감소를 시도한다.
즉, “이 서비스 CPU 사용률이 50% 넘으면 파드를 더 늘려라”와
같은 정책을 선언형으로 걸어두는 오브젝트가 HPA이다.
실습
이번 실습 흐름은 다음과 같다.
1.nginx-hpa Deployment 생성 (CPU requests 포함)
2.Service 생성 (클러스터 안에서 부하 걸기 용)
3.HPA 생성 (CPU 50% 기준, 1~5개로 스케일)
4.kubectl top / kubectl get hpa -w 로 스케일링 확인
(부하 걸어서 파드가 늘어나는지 보기)
1. HPA 대상 Deployment 만들기
먼저 CPU 요청량이 설정된 간단한 nginx Deployment 를 만든다.
파일명: nginx-hpa-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-hpa
labels:
app: nginx-hpa
spec:
replicas: 1 # 시작은 1개
selector:
matchLabels:
app: nginx-hpa
template:
metadata:
labels:
app: nginx-hpa
spec:
containers:
- name: nginx
image: nginx:1.21.0
ports:
- containerPort: 80
resources:
requests: # ★ HPA가 쓸 CPU 기준
cpu: "100m" # 0.1코어
memory: "128Mi"
limits:
cpu: "500m"
memory: "256Mi"적용 및 확인 명령어
kubectl apply -f nginx-hpa-deploy.yaml
kubectl get deploy nginx-hpa
kubectl get pods -l app=nginx-hpa -o wide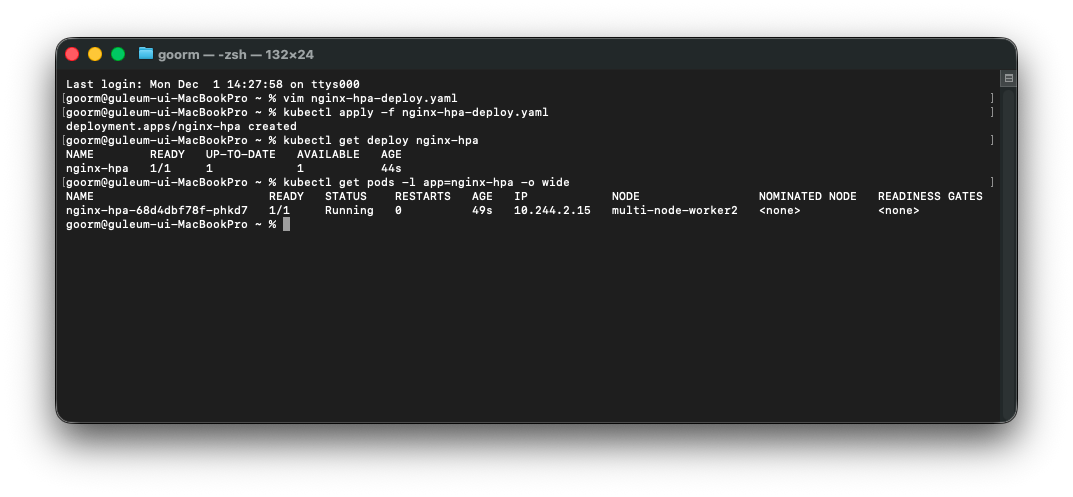
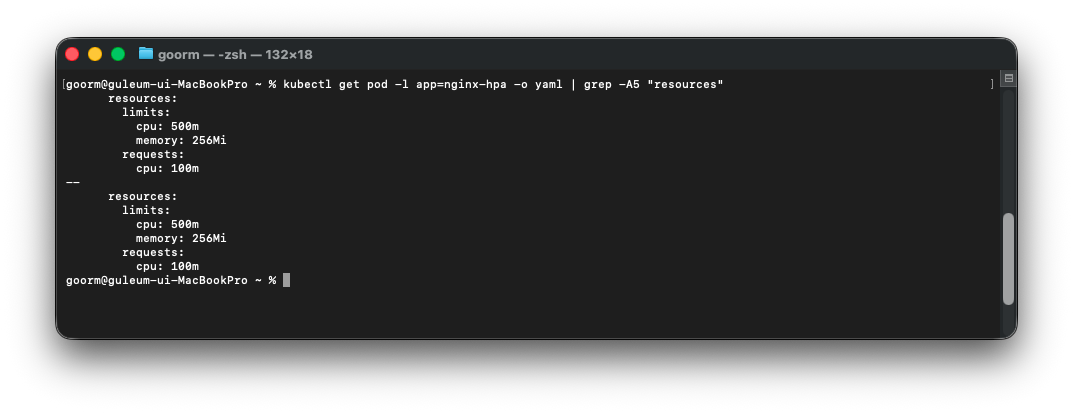
kubectl get pod -l app=nginx-hpa -o yaml | grep -A5 "resources"그리고 위 명령어로 cpu요청이 설정됐는지 확인할 수 있다.
2. Service 생성 (부하 걸어줄 엔드포인트)
클러스터 안에서 부하를 걸기 위해 ClusterIP 서비스 하나를 만든다.
파일명: nginx-hpa-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-hpa-svc
spec:
selector:
app: nginx-hpa
ports:
- port: 80
targetPort: 80적용 & 확인 명령어
kubectl apply -f nginx-hpa-svc.yaml
kubectl get svc nginx-hpa-svc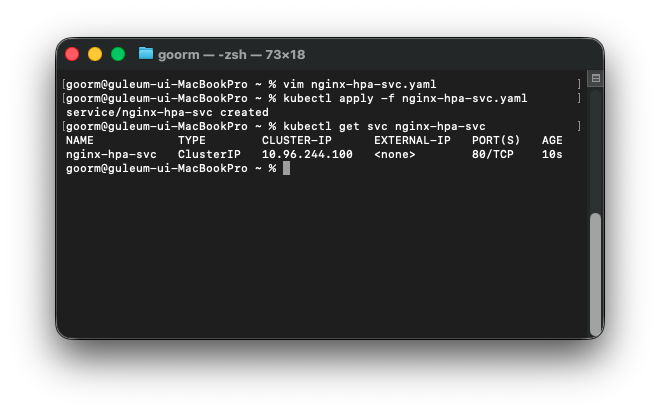
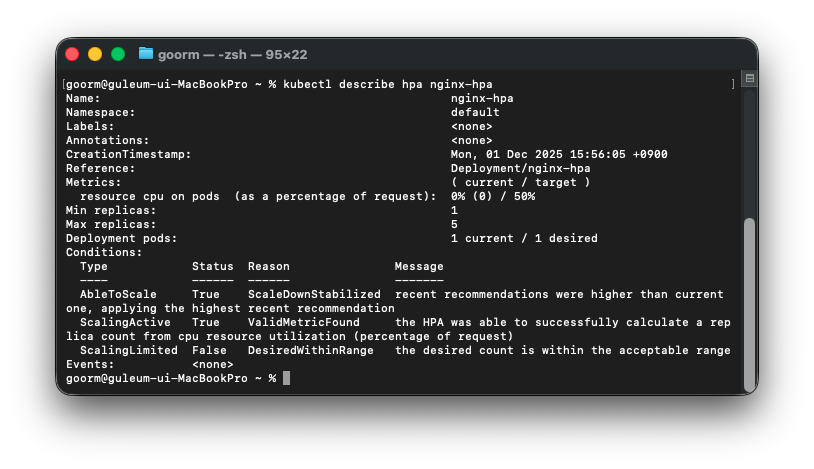
3. HPA 생성하기
이번에는 HPA 리소스를 직접 YAML로 만들어본다.
CPU 사용률 50%를 기준으로, 최소 1개 ~ 최대 5개까지 자동 조절하도록 한다.
파일명: kubectl delete pod load-generator
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
scaleTargetRef: # 어떤 Deployment를 스케일링할지
apiVersion: apps/v1
kind: Deployment
name: nginx-hpa
minReplicas: 1 # 최소 파드 개수
maxReplicas: 5 # 최대 파드 개수
metrics:
- type: Resource
resource:
name: cpu # CPU 기준으로 스케일링
target:
type: Utilization
averageUtilization: 50 # CPU 사용률 50%를 목표로적용&확인 명령어
kubectl apply -f nginx-hpa-hpa.yaml
kubectl get hpa
kubectl describe hpa nginx-hpa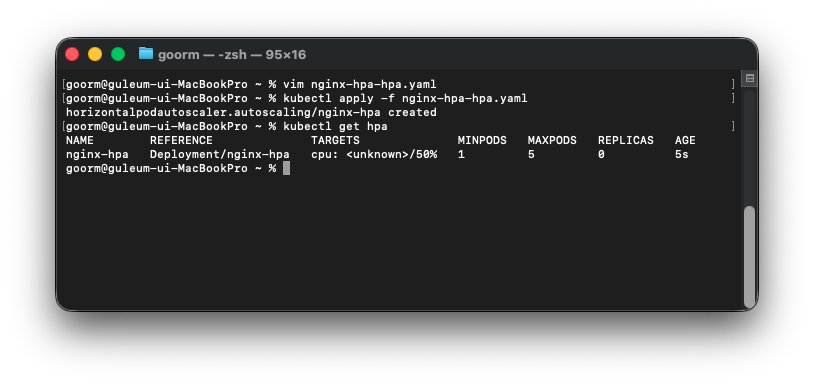
4. 부하 걸어서 스케일링 테스트
이제 실제로 CPU 사용량을 늘려서 HPA가 파드를 늘리는지 확인해본다.
1. 다른 터미널에서 HPA 상태 관찰
다른 터미널에서 HPA 상태를 watch 걸어둔다.
kubectl get hpa nginx-hpa -w2. 부하를 거는 Pod 만들기
클러스터 내부에서 nginx 서비스에 계속 요청을 보내 CPU를 올려본다.
kubectl run load-generator --image=busybox \
--restart=Never -- /bin/sh -c \
"while true; do wget -q -O- http://nginx-hpa-svc; done"이렇게 하면 load-generator 파드가 nginx 서비스로 계속 HTTP 요청을 보내면서 CPU를 태운다.
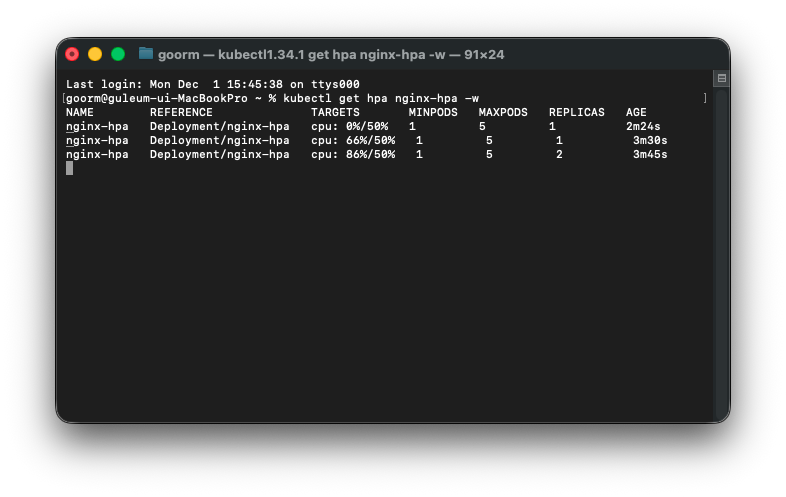
이렇게 계속해서 cpu 점유율이 높아지는 것을 볼 수 있다.
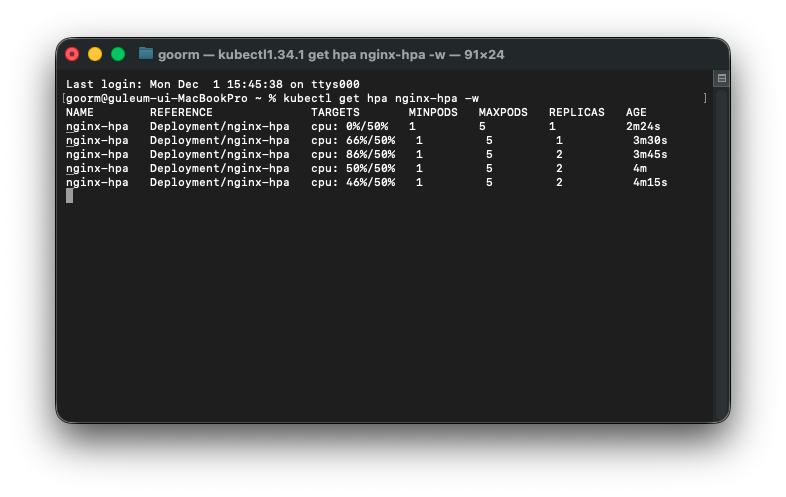
3. CPU 사용량과 HPA 반응 확인
kubectl top pods -A | grep nginx-hpa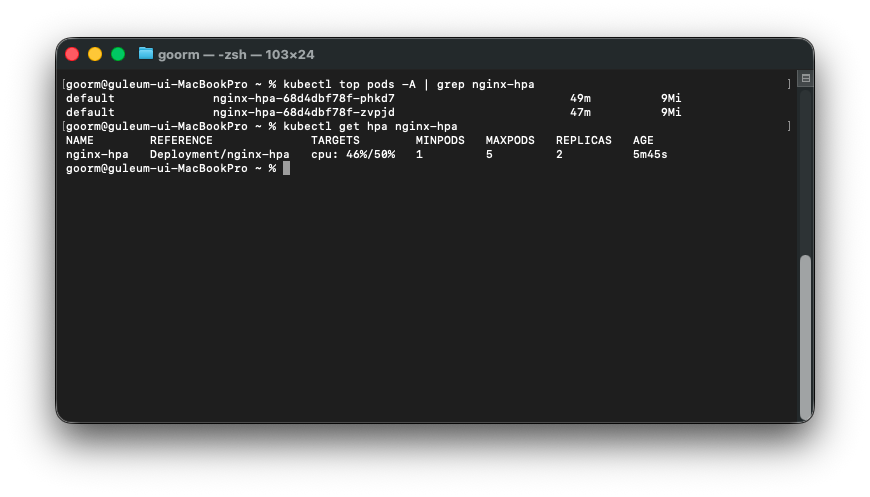
이렇게 변하는 모습을 볼 수 있다.
4. 부하 제거 후 스케일 다운
부하를 멈추려면 load-generator 파드를 지우면 된다.
다음 명령어를 통해 파드를 지운다.
kubectl delete pod load-generator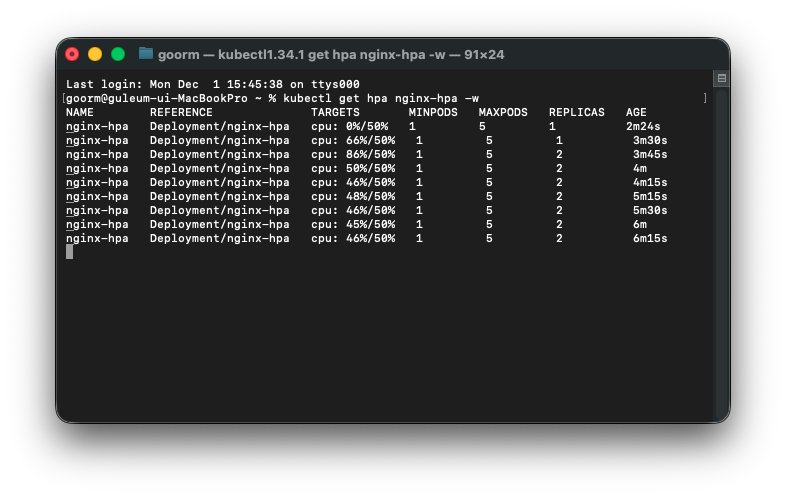
이게 파드를 지우기 전 상태이며,
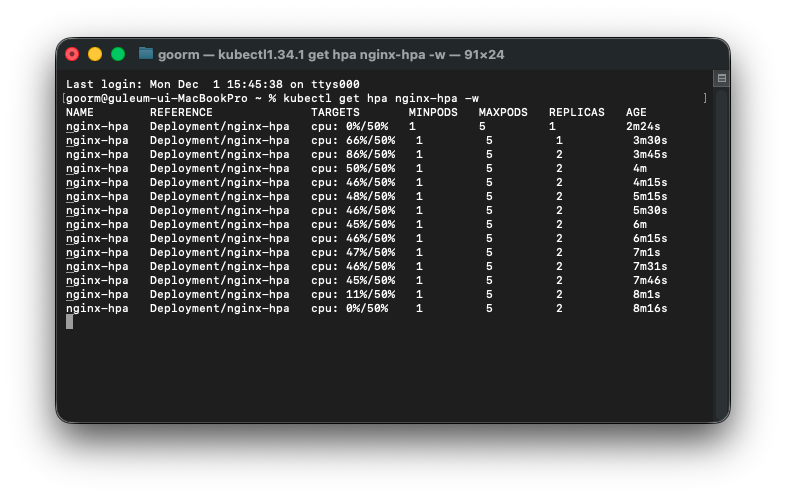
파드를 지운 후, 이렇게 점유율이 낮아진 것을 확인할 수 있다.
참고자료:
[쿠버네티스 공식 홈페이지 - Horizontal Pod Autoscaling]
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/?utm_source=chatgpt.com
[쿠버네티스 공식 홈페이지 - Resource Management for Pods and Containers]
https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/?utm_source=chatgpt.com
