헬름 설치하기
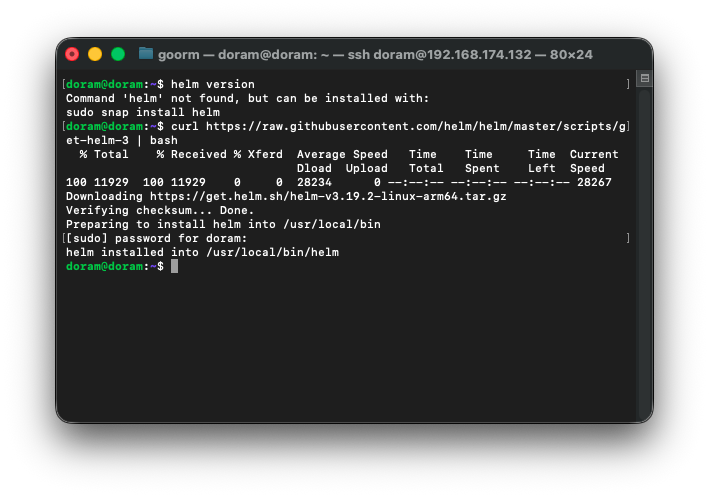
일단 프로메테우스를 설치하는데, 헬름이 설치되어 있지 않아서(helm version 했을 때 찾을 수 없었다.)
curl https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 | bash위 명령어를 통해 헬름을 설치해줬다.
프로메테우스 설치 전 과정
Prometheus 공식 repo 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts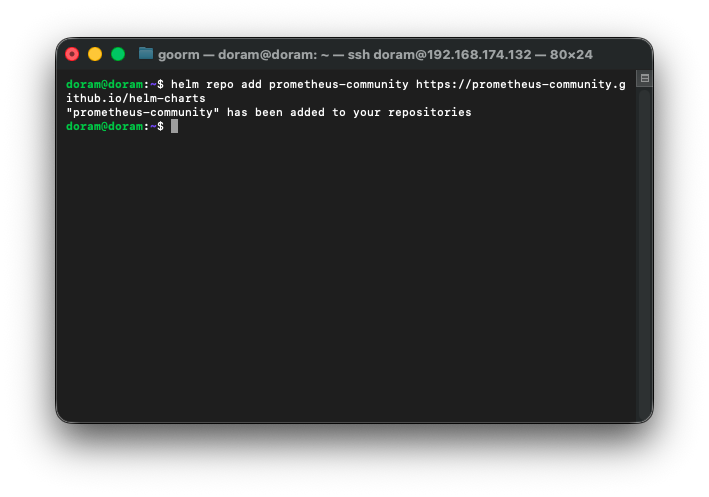
repo 업데이트
helm repo update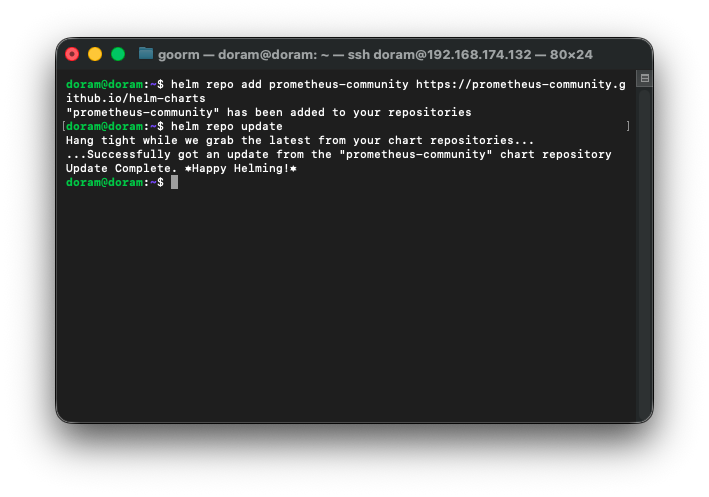
kubelet 초기화하기(컨트롤 플레인 초기화(재설치 시))
sudo kubeadm reset -f
sudo systemctl stop kubelet
sudo systemctl stop containerd
sudo rm -rf /etc/kubernetes
sudo rm -rf /var/lib/etcd
sudo rm -rf /var/lib/kubelet
sudo systemctl start containerd컨트롤 플레인 초기화(kubeadm init)
sudo kubeadm init --pod-network-cidr=192.168.0.0/16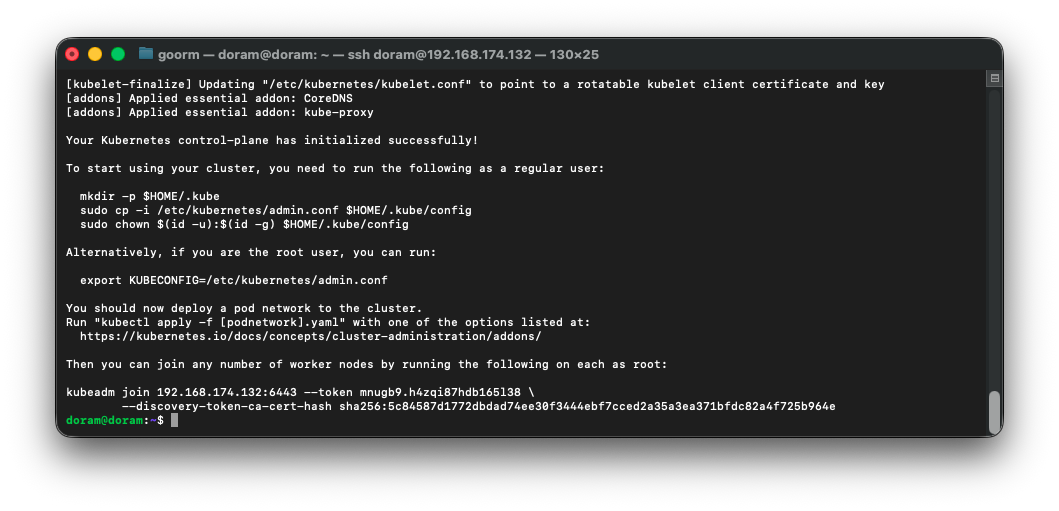
하면 이렇게 join할 수 있는 명령어가 뜬다.
kubectl 환경 설정(KUBECONFIG 등록)
이 작업은 kubectl 명령어를 쓸 수 있게 admin.conf 를 내 홈디렉토리에 등록하는 작업이다.
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config후,
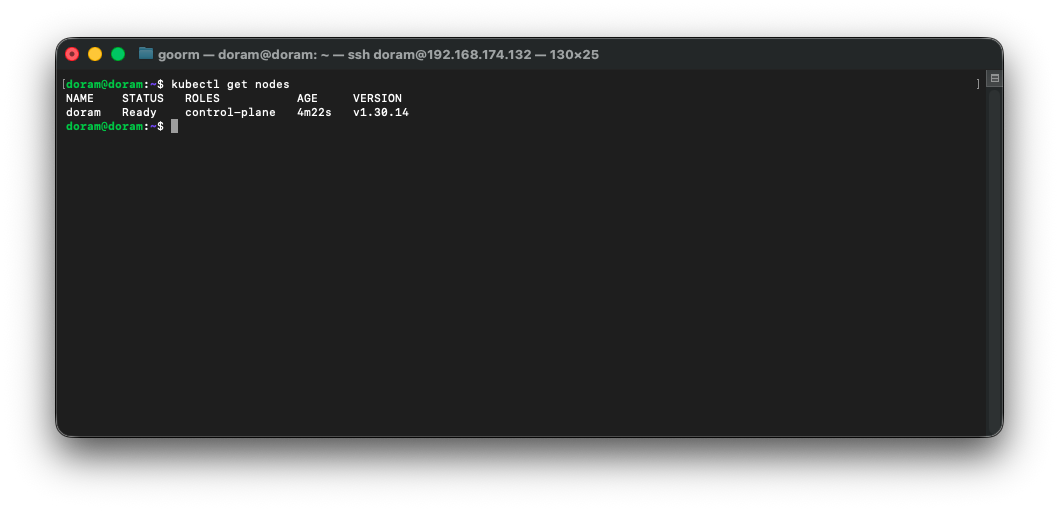
kubectl get nodes하면
master 1개가 NotReady로 뜨게 된다.
CNI(Network Plugin) 설치 – Calico 적용
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.2/manifests/calico.yaml명령어를 실행한다.
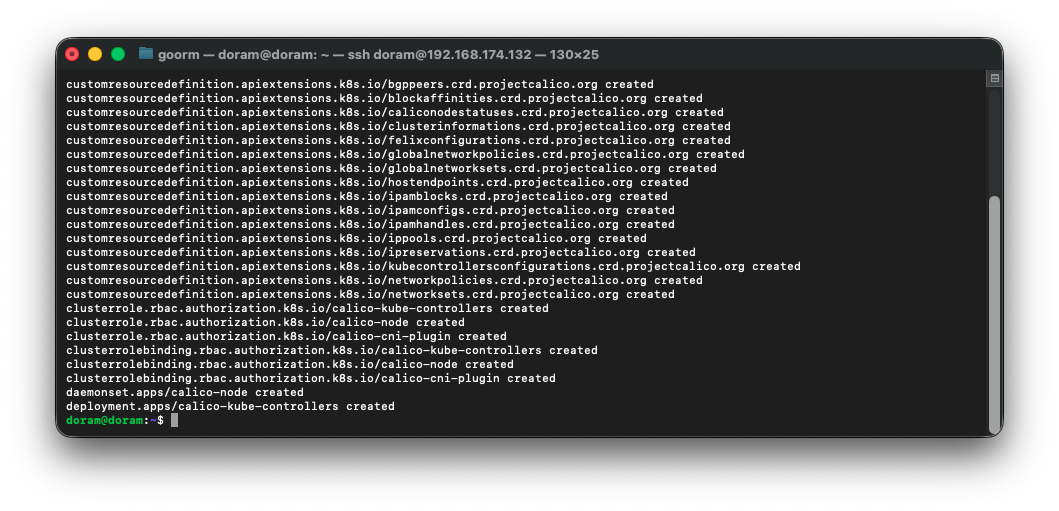
그럼 다음과 같이 created 되는 것을 확인할 수 있는데,
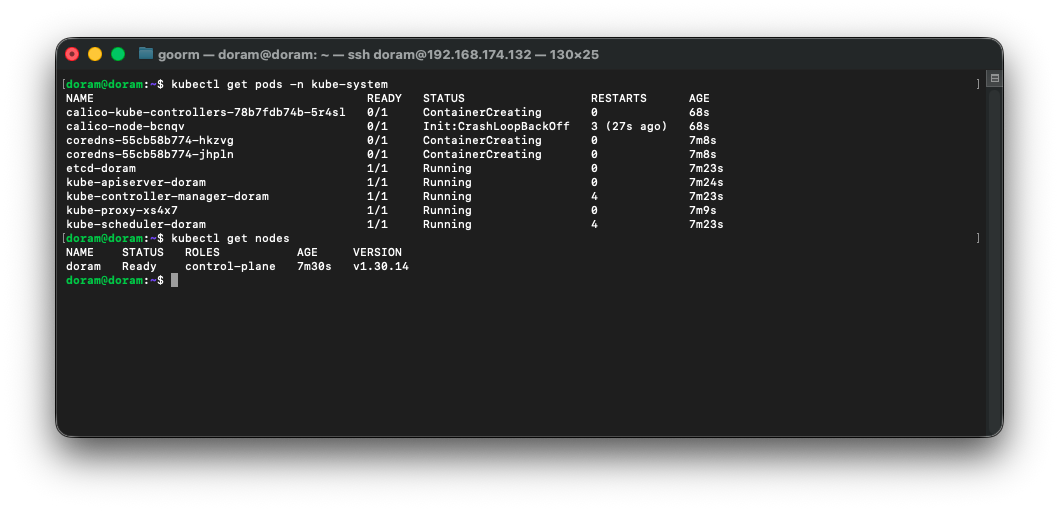
kubectl get pods -n kube-system
kubectl get nodes해서 보면 노드가 Ready로 바뀌는 것을 확인할 수 있다.
워커 노드 초기화 및 클러스터 합류 준비
워커용 새 노드에서 다음과 같이 명령어를 실행한다.
sudo kubeadm reset -f
sudo systemctl stop kubelet
sudo systemctl stop containerd
sudo rm -rf /etc/kubernetes /var/lib/kubelet /var/lib/etcd
sudo systemctl start containerd (필요 시)워커 -> 컨트롤 플레인 Ping 날리기
ping -c 3 192.168.174.132했을 때
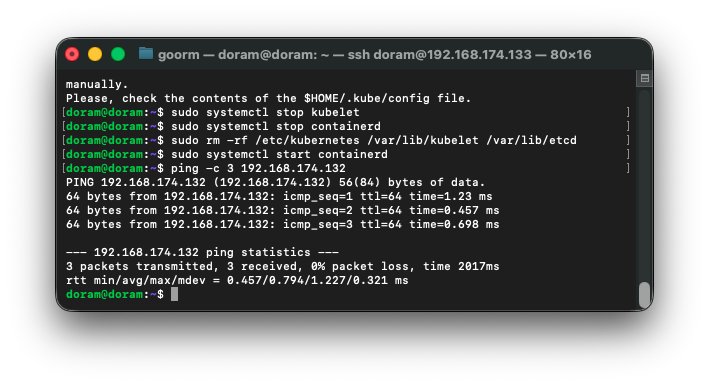
다음과 같이 되는 것을 확인할 수 있다.
워커 노드 이름 충돌 해결 (Hostname 변경)
나의 경우에는 join하려는 워커 노드 hostname이 doram인데,
그런데 클러스터 안에 이미 마스터 노드 이름도 doram 이라서
에러가 떴다. 그래서 워커의 hostname을 바꿔주었다.
sudo hostnamectl set-hostname worker1그런 다음,
sudo nano /etc/hosts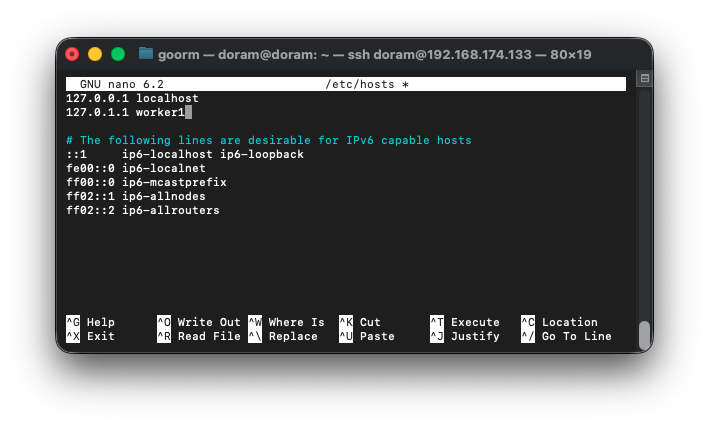
이렇게 /etc/hosts 안에서 doram -> worker1로 바꿔주었다.
그런 다음 다시, kubelet 데이터를 완전 삭제해주었다.
sudo kubeadm reset -f
sudo systemctl stop kubelet
sudo systemctl stop containerd
sudo rm -rf /etc/kubernetes /var/lib/kubelet /var/lib/etcd
sudo systemctl start containerd워커 조인하기
sudo kubeadm join 192.168.174.132:6443 --token mnugb9.h4zqi87hdb165l38 \
--discovery-token-ca-cert-hash sha256:5c84587d1772dbdad74ee30f3444ebf7cced2a35a3ea371bfdc82a4f725b964e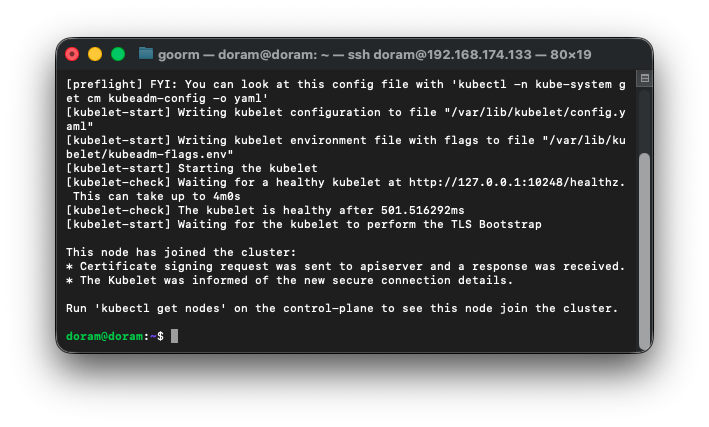
이제 조인이 완벽하게 되는 것을 확인할 수 있다.
마스터 노드에서 확인
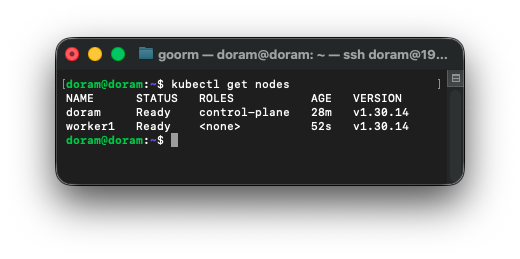
이제 마스터 노드에서 2개의 노드가 뜨는 것을 확인할 수 있다.
프로메테우스 설치
이제 컨트롤 플레인에서 프로메테우스를 설치하면 된다.
helm install prometheus prometheus-community/prometheus \
--set pushgateway.enabled=false \
--set alertmanager.enabled=false \
--set server.service.type="LoadBalancer" \
--set server.global.scrape_interval="15s" \
--set server.global.evaluation_interval="15s" \
--set server.extraFlags[0]="web.enable-lifecycle" \
--set server.extraFlags[1]="storage.tsdb.no-lockfile" \
--namespace=monitoring \
--create-namespace위 명령어를 실행하여 프로메테우스를 설치해준다.
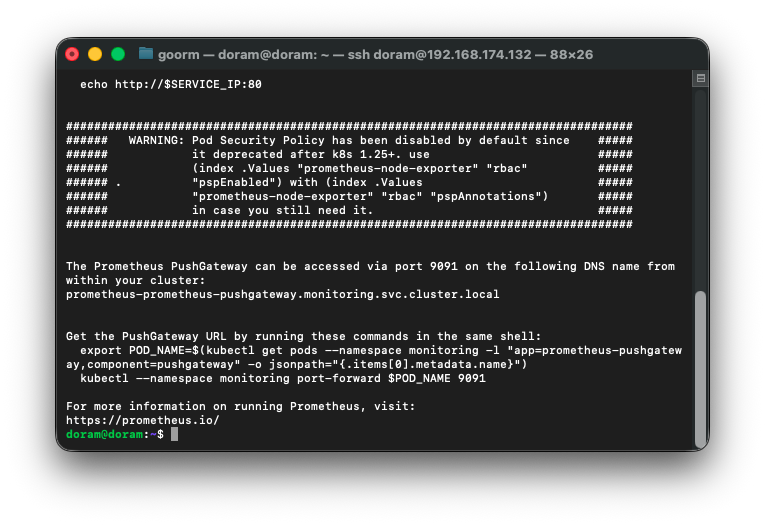
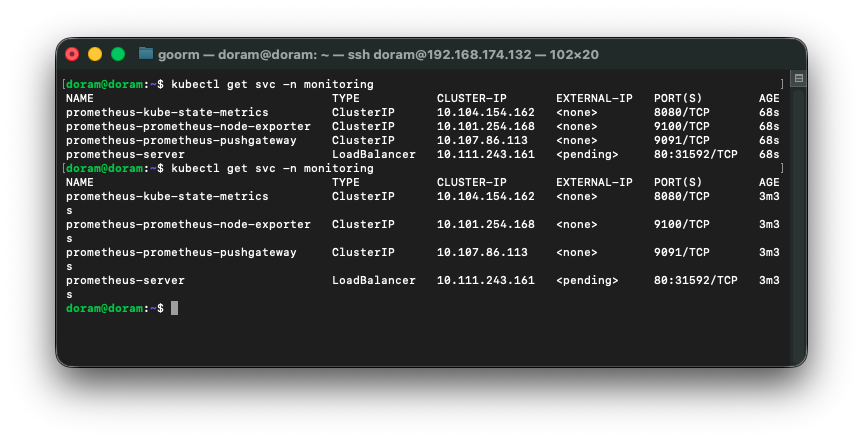
프로메테우스 설치 확인
Pod 확인
kubectl get pods -n monitoring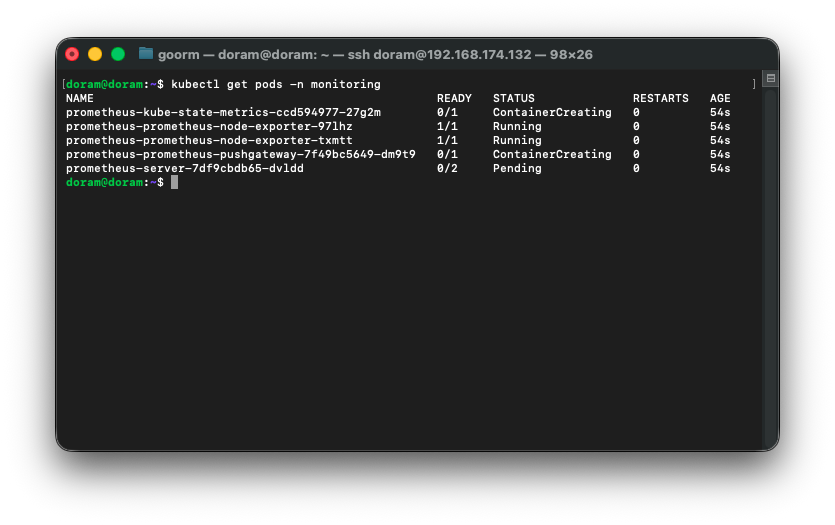
Service 확인
kubectl get svc -n monitoring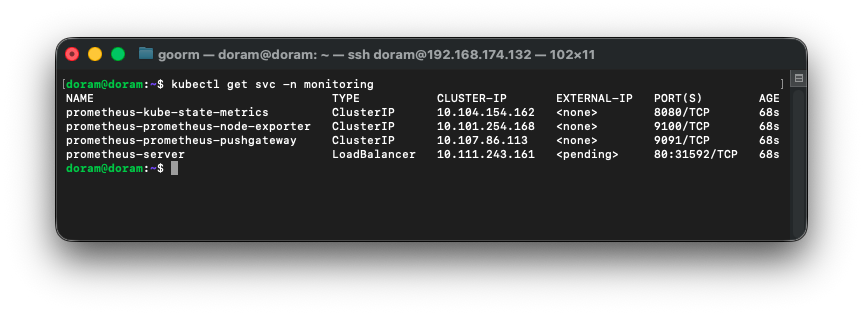
이제 프로메테우스 설치가 성공적으로 끝이난 줄 알았다.
알고보니 프로메테우스 서버에서 external ip가 pendding이 아니라 할당이 되어야 하는 것이었다.
사유는 다음과 같았다.
external ip가 계속 pending 뜨는 이유는 100% 확률로
너 지금 사용하는 환경(VMware / Fusion / VirtualBox / Parallels 등)은
LoadBalancer 타입의 서비스를 자동으로 할당해주는 클라우드가 아니기 때문이다.
즉:
- AWS → ELB 자동 생성됨
- GCP → GLB 자동 생성됨
- Azure → LB 자동 생성됨
- VM 방식의 로컬 쿠버네티스 → LB 없음 → pending 뜸
따라서 로드밸런서 기능을 쓰기위해 MetalLB를 설치하기로 했다.
해결방법 MetalLB설치
1. MetalLB 설치
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.14.5/config/manifests/metallb-native.yaml2. IP 풀 설정 (VM 네트워크에 맞게 수정)
네트워크가 192.168.174.0/24라면
파일 명 : metallb-config.yaml
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
namespace: metallb-system
name: default-pool
spec:
addresses:
- 192.168.174.200-192.168.174.250
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
namespace: metallb-system
name: l2
spec:
ipAddressPools:
- default-pool적용 명령어
kubectl apply -f metallb-config.yaml했는데 에러가 떴다.
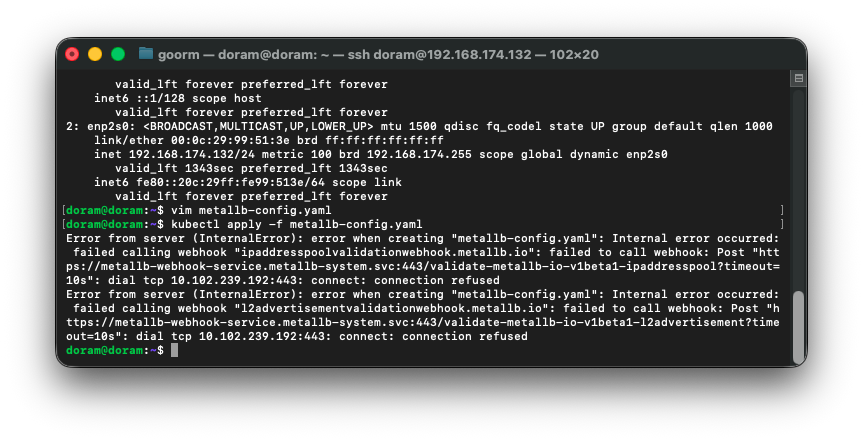
그래서 MetalLB상태를 확인하고 기존 MetalLB를 삭제하고 다시 설치하기로 했다.
3. 기존 MetalLB 삭제
kubectl delete ns metallb-system4. MetalLB 재설치
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.14.3/config/manifests/metallb-native.yaml5. 설치 후 확인
kubectl get pods -n metallb-system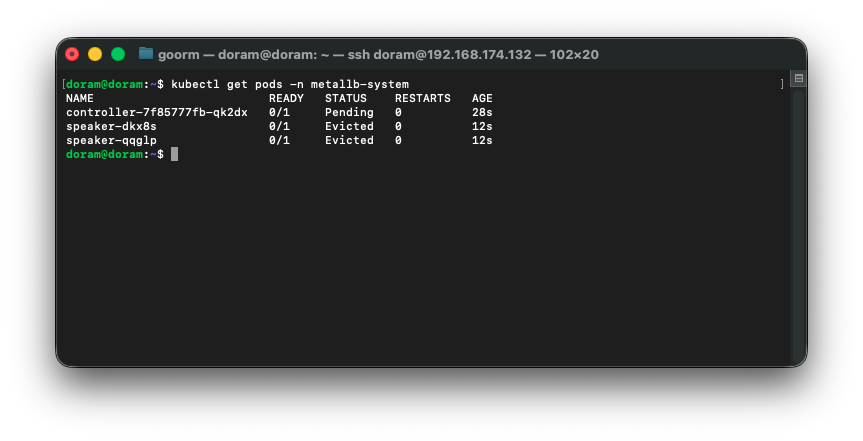
이렇게 Running 상태가 떠야 하는데, evicted 상태가 떴다.
메모리나 디스크가 부족하기 때문에 뜬 것이다.
poweroff 한 다음에 다시 키면 ip가 바뀌고 설정도 다시 해줘야하기 때문에, ip를 고정해주기로 했다.
6. 우분투 내부에서 Static IP 고정
/etc/netplan/*.yaml열고 내용을 수정해준다.
sudo nano /etc/netplan/00-installer-config.yamlnetwork:
version: 2
ethernets:
enp2s0:
dhcp4: false
addresses:
- 192.168.174.132/24
routes:
- to: 0.0.0.0/0
via: 192.168.174.2
nameservers:
addresses:
- 8.8.8.8
- 1.1.1.1
sudo chmod 600 /etc/netplan/00-installer-config.yaml그리고 해당 명령을 실행해서 퍼미션 문제를 해결한다.
DHCP 클라이언트를 종료해준 후 , 적용해준다.
sudo dhclient -r enp2s0
sudo netplan apply마지막으로 인터페이스를 재시작해준다.
sudo ip link set enp2s0 down
sudo ip link set enp2s0 upsudo ip link set enp2s0 down 하면 통신이 끊겨서
가상환경 안에서 코드를 쳐줘야 한다.
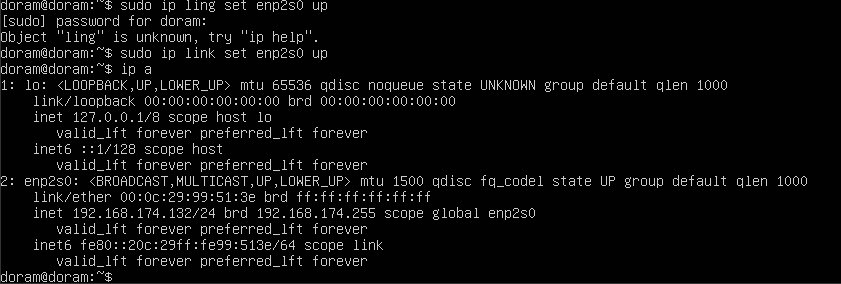
이렇게 완벽하게 올라온 것을 확인할 수 있다.
클러스터가 정상인지 확인해준다.
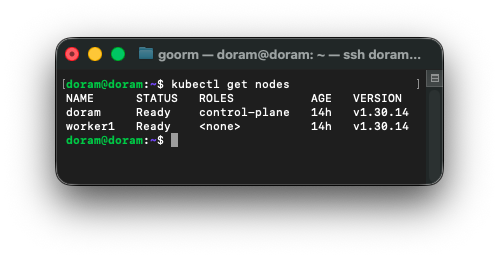
정상인 것을 확인할 수 있으며, 다시 MetalLB 삭제 후 재설치해준다.
그런 후 에러가 생겼다.
7. DNS 문제 해결
Ubuntu는 systemd-resolved 때문에 /etc/resolv.conf 를 직접 수정해도 무효일 때가 많다.
따라서 resolv.conf 직접 수정 후 systemd-resolved 재시작해준다.
sudo bash -c 'echo "nameserver 8.8.8.8" > /etc/resolv.conf'
sudo systemctl restart systemd-resolved이후 ping 테스트를 하여 답이 오면 해결된 것이다.
ping -c 3 raw.githubusercontent.com했는데 네임스페이스가 망가지고 Ping테스트도 안되어 근본부터 고치기로 했다.
8. default route추가
현재 나의 상태는
➡ default route(인터넷으로 나가는 길) 이 사라지고,
➡ 그래서 8.8.8.8도 못 나가고, github도 못 나간다.
➡ NAT 게이트웨이(192.168.174.2)로 나가는 경로가 없다.
이 3가지의 상태이며 즉, LAN안에서는 통신이 가능한 상태이며 인터넷은 안되는 상태이다.
그래서 default route추가하여 해결하기로 했다.
sudo ip route add default via 192.168.174.2 dev enp2s0하여 디폴트 루트를 추가하였다.
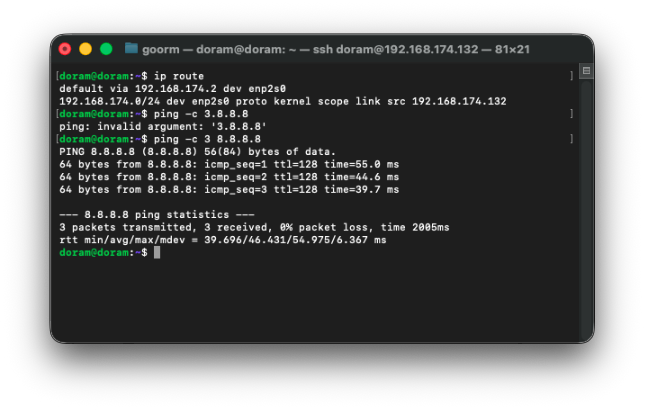
이제 디폴트 루트도 성공적으로 추가되고 ping도 제대로 되는 것을 확인할 수 있다.
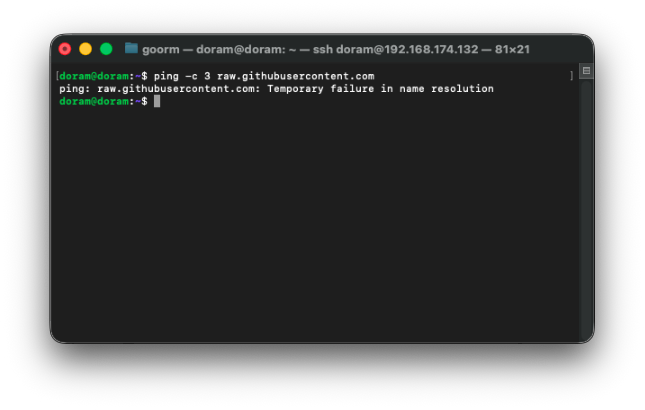
그런데 깃허브로의 ping test는 성공하지 못한 것을 확인할 수 있다.
이제 인터넷 자체는 복구되었는데
DNS만 고장난 상태이다.
이제 DNS만 고치면 된다.
9. DNS 고치기
일단 resolv.conf를 재생성해준다.
/etc/resolv.conf 는 systemd-resolved가 관리해야 해야하기 때문에
다음과 같이 명령어를 실행해준다.
sudo rm -f /etc/resolv.conf
sudo ln -s /run/systemd/resolve/stub-resolv.conf /etc/resolv.conf
sudo systemctl restart systemd-resolved그런 다음, 확인해준다.
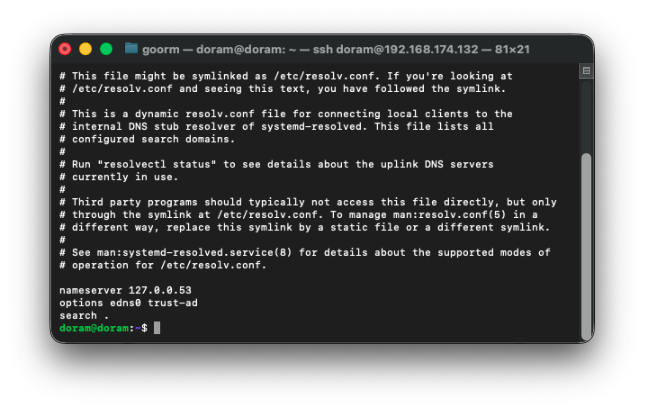
정상인 것을 확인할 수 있다.
또한,
Ubuntu의 기본 DNS가 깨졌기 때문에
강제로 8.8.8.8을 넣어주면 해결할 수 있다.
sudo mkdir -p /etc/systemd/resolved.conf.d
echo -e "[Resolve]\nDNS=8.8.8.8\nFallbackDNS=1.1.1.1" | sudo tee /etc/systemd/resolved.conf.d/dns.conf
sudo systemctl restart systemd-resolved후, DNS를 확인해준다.
resolvectl status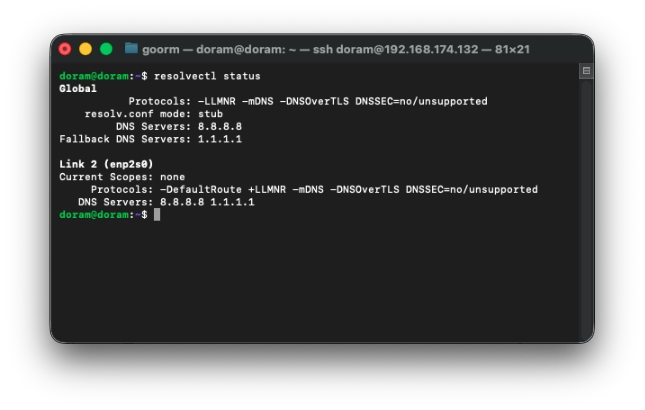
이제 DNS가 정상인 것을 확인할 수 있으며 정말 마지막으로 ping 테스트를 진행해준다.
ping -c 3 raw.githubusercontent.com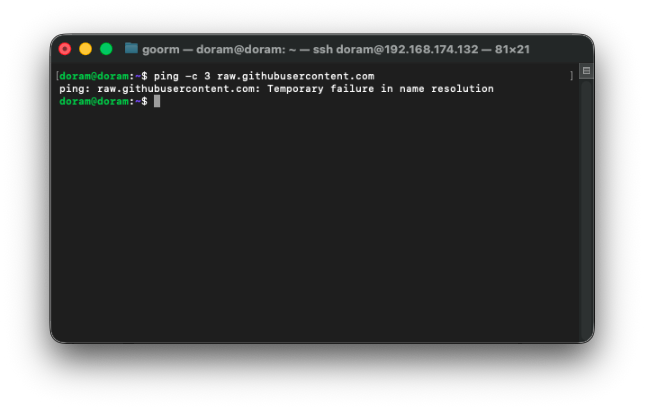
실패를 했다.
이정도까지 되니 머리가 점점 아파져왔지만
원인을 찾아보니 resolv.conf 링크 상태 확인을 해야한다고 나와 있어서, 다시 점검해보기로 했다.
resolv.conf 파일 확인하기
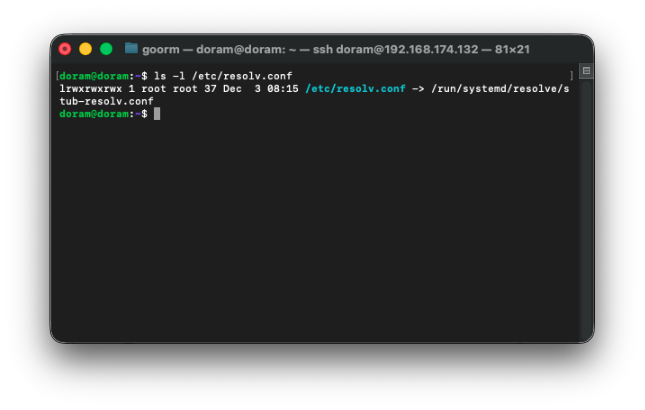
나의 경우 이렇게, 정상으로 나와서 이것은 문제가 아닌 것으로 판별되었다.
10. NAT 어댑터 리셋 (VMware)
시원하게 어댑터를 리셋시키기로 했다.
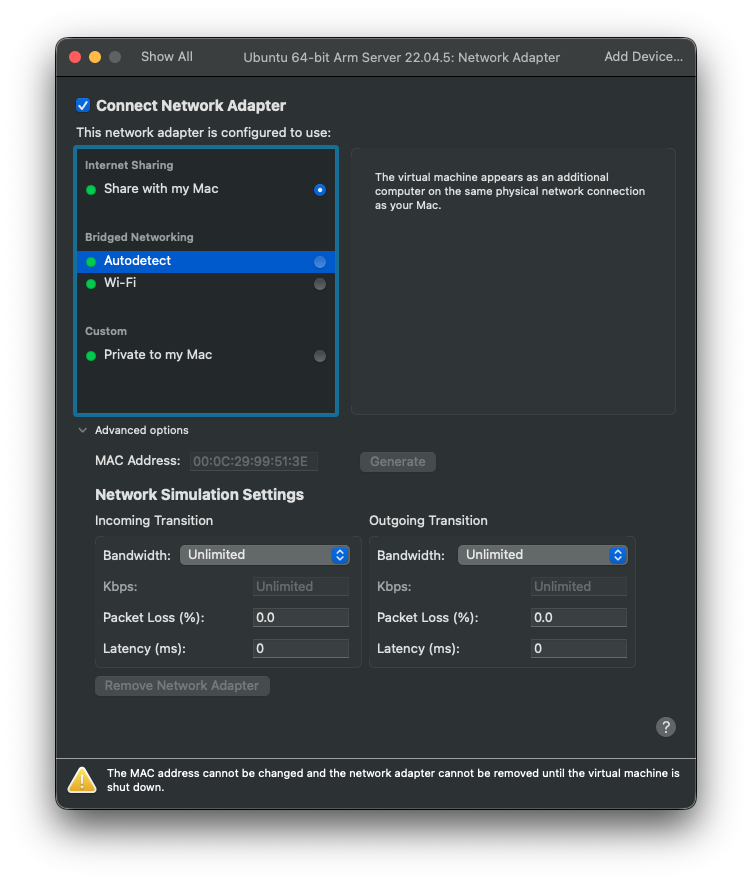
여기에서
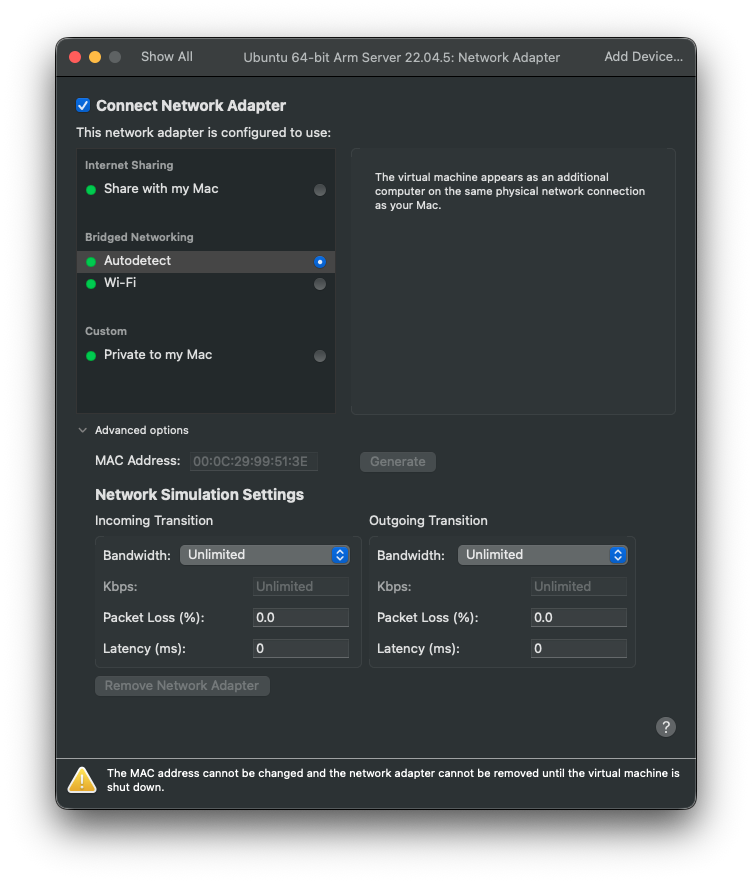
Autodetect로 바꾸고, vm을 재부팅해야한다.
바꾼 후,
sudo reboot명령어를 쳐서 재부팅시켜준다.
그래도 해결이 안됐다.
11. default root 제거
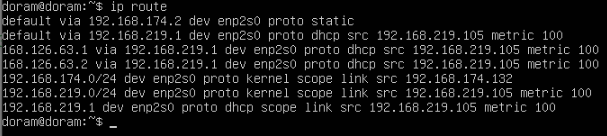
현재 이렇게 디폴트 라우트가 두개라 삭제해주기로 했다.
sudo ip route del default via 192.168.219.1 dev enp2s0
sudo ip route del 192.168.219.0/24 dev enp2s0그리고 추가로
sudo ip route del 168.126.63.1 dev enp2s0얘도 삭제를 한다.(219 대역이 만든 잘못된 라우트다.)
12. netplan 고정 IP 설정
sudo nano /etc/netplan/00-installer-config.yamlnetplan 고정 IP 설정을 열고 내용을 다음과 같이 바꿔준다.
network:
version: 2
ethernets:
enp2s0:
dhcp4: false
addresses:
- 192.168.174.132/24
routes:
- to: default
via: 192.168.174.2
nameservers:
addresses:
- 8.8.8.8
- 1.1.1.1이제 퍼미션 오류를 해결하기 위해
다음 명령어를 쳐준다.
sudo chmod 600 /etc/netplan/00-installer-config.yaml그리고 netplan 파일을 확인해보았다.
sudo cat /etc/netplan/00-installer-config.yaml
이렇게 결과가 떴다.
/etc/netplan/00-installer-config.yaml 파일 자체가 없다는 뜻이며,
그래서 netplan이 DHCP 기본 설정으로 자동 revert 돼서
192.168.219.x 경로가 자꾸 생겨난 것이었다.
그래서 netplan 디렉토리 안 상태를 확인해보기로 했다.

이렇게 현재 두개가 나오는데, 50-cloud-init.yaml은 cloud-init 기본 설정이 계속 네트워크를 덮어쓰는 원인이며
파일 이름 변경해서 netplan이 무시하도록 만들기로 하였다.
sudo mv /etc/netplan/50-cloud-init.yaml /etc/netplan/50-cloud-init.yaml.bak13. 00-installer-config.yaml 파일 수정
또한 다음 명령어를 통해 00-installer-config.yaml 파일을 수정한다.
sudo nano /etc/netplan/00-installer-config.yamlnetwork:
version: 2
renderer: networkd
ethernets:
enp2s0:
dhcp4: false
addresses:
- 192.168.174.132/24
routes:
- to: default
via: 192.168.174.2
nameservers:
addresses:
- 8.8.8.8
- 1.1.1.1또한 퍼미션을 수정한 뒤 설정을 적용한다.
sudo chmod 600 /etc/netplan/00-installer-config.yaml
sudo netplan apply
이렇게 정상적용된 것을 확인할 수 있다.
14. ip&ping test
마지막으로 ip와 라우터를 확인해준다.
ip a
ip route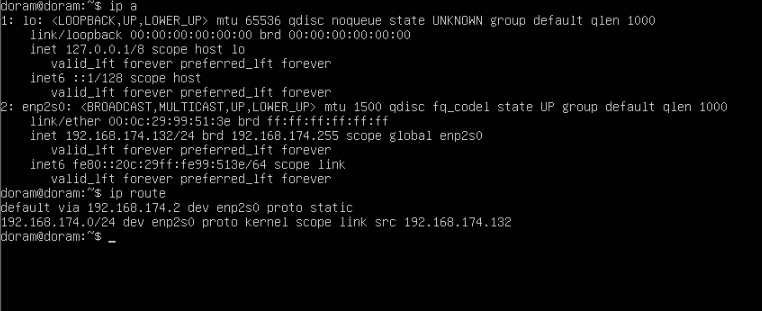
그리고 제일 문제가 많았던 ping 테스트도 해준다.
ping -c 3 192.168.174.2
ping -c 3 8.8.8.8
ping -c 3 google.com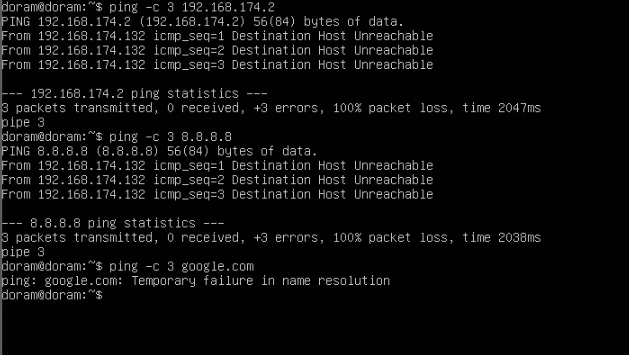
실패했다. 실패 원인은,
ip도 붙어있고, 라우팅 테이블도 정상이고, DNS도 설정되어 있ㅋ는데
게이트웨이가 죽어 있어서 문제가 생긴 것이다.
15. 네트워크 모드 다시 잡기
일단 vm을 재부팅 한 후 ip a 명령어를 통해 다시 ip와 게이트웨이를 확인한다.
sudo reboot
ip a
ip route재부팅을 하고 확인을 하니 이렇게 나왔다.
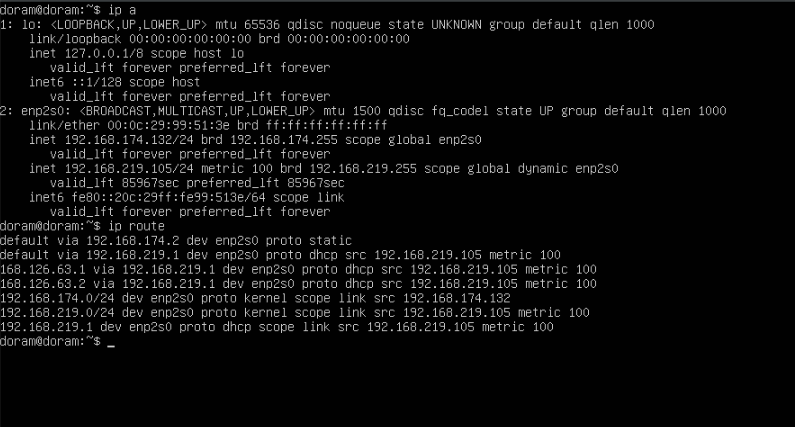
network 설정에 들어가서 브릿지 -> wifi로 선택하기로 했다.
16. 네트워크 변경
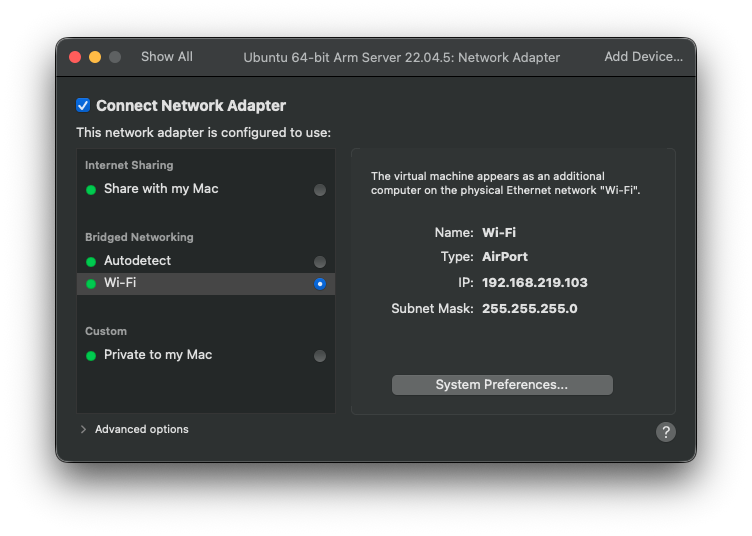
다음과 같이 설정했다.
그리고 vmWare을 끄고 다시 대역을 확인했다.
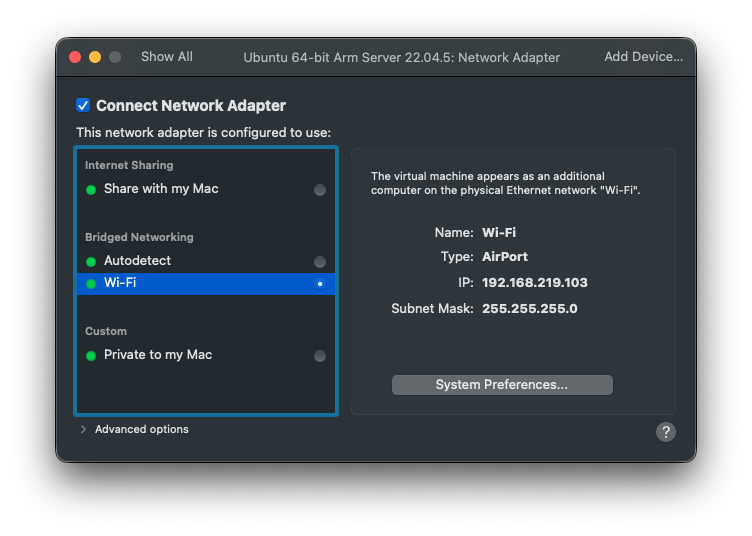
그런데 공유기 대역이 특이해서 브릿지가 꼬여서 맥이랑 NAT으로 연결로 설정을 바꾸기로 했다.
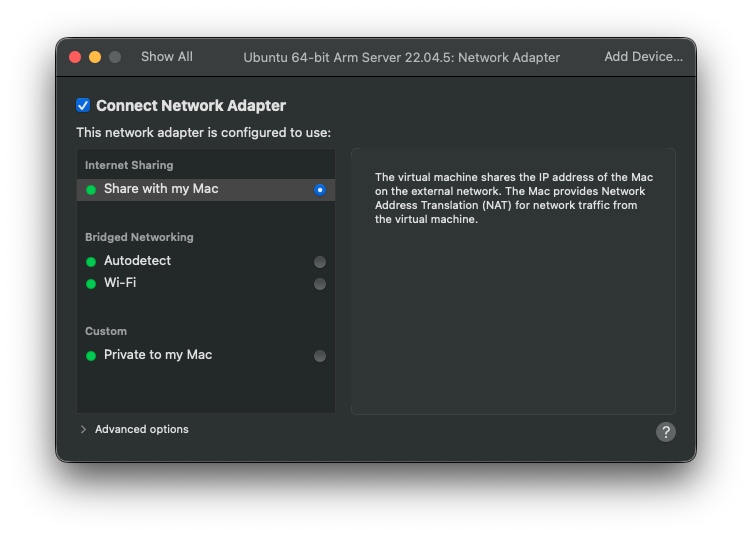
17. ip&ping test
ip a
ip route
ping -c 3 8.8.8.8
ping -c 3 google.com한 결과이다.
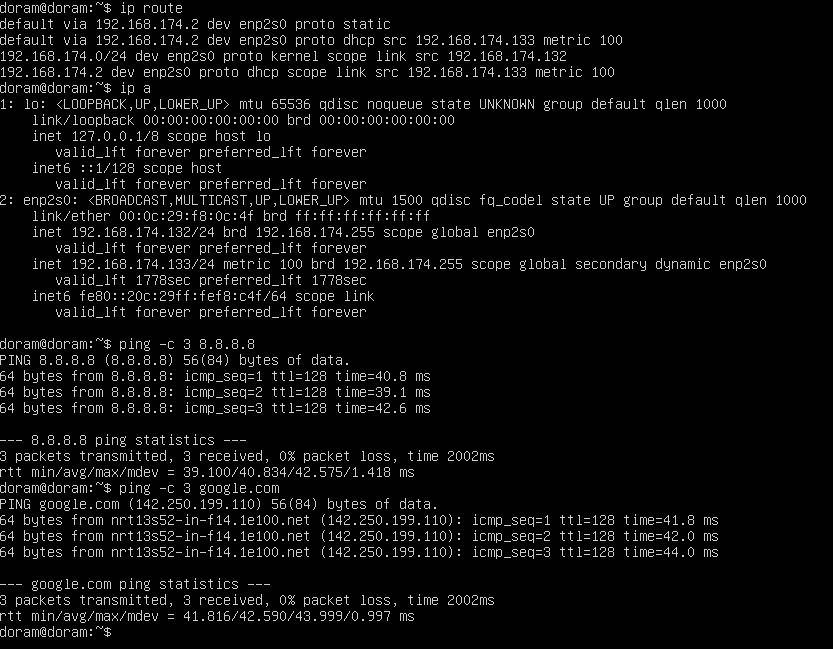
인터넷과 모든것이 정상이 되었다.
18. MetalLB 재설치
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.14.3/config/manifests/metallb-native.yaml또한 MetalLB config 파일은 다음과 같이 설정해준다.
파일 명 :metallb-config.yaml
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: first-pool
namespace: metallb-system
spec:
addresses:
- 192.168.174.200-192.168.174.220
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: advert
namespace: metallb-system그런 다음 확인해준다.
kubectl get pods -n metallb-system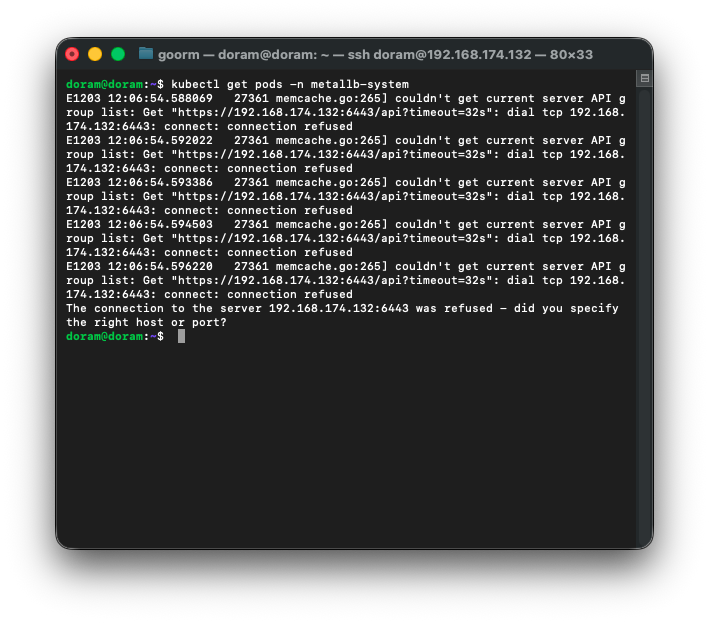
kubelet 서버가 제대로 안 올라온 상태인것이다.
또한 k8s 클러스터를 제대로 설치해준다.
19. master 노드 재구성
다음과 같이 실행한다.
sudo swapoff -a
sudo apt update && sudo apt upgrade -y
sudo apt install containerd -y
그다음 컨테이너 기본 설정을 해준다.
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml
sudo systemctl restart containerd
sudo systemctl enable containerd20. k8s 설치
sudo apt-get install -y apt-transport-https ca-certificates curl
sudo curl -fsSLo /usr/share/keyrings/kubernetes-archive-keyring.gpg \
https://packages.cloud.google.com/apt/doc/apt-key.gpg
echo "deb [signed-by=/usr/share/keyrings/kubernetes-archive-keyring.gpg] \
https://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.listsudo apt update
sudo apt install -y kubeadm kubelet kubectl
sudo systemctl enable kubelet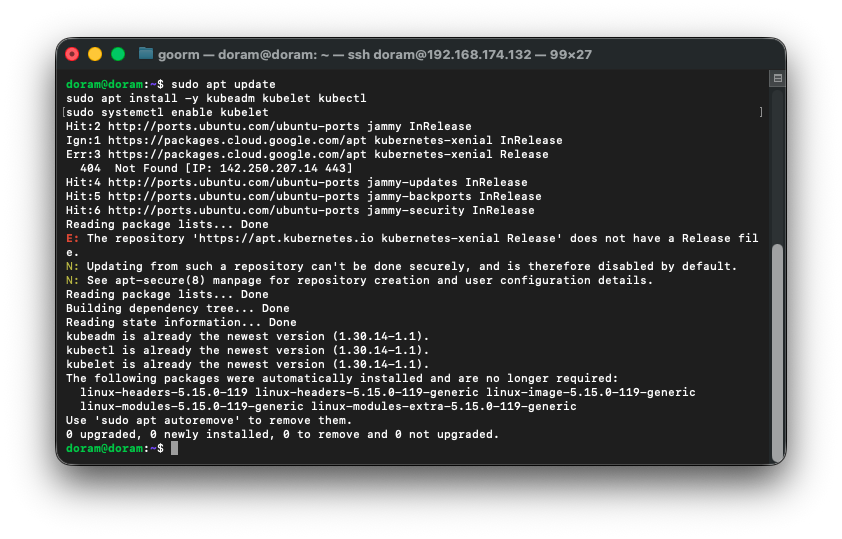
설치가 잘 되었다.
sudo kubeadm init \
--pod-network-cidr=192.168.0.0/16 \
--apiserver-advertise-address=192.168.174.132이제 해당 명령어를 실행하면 kubectl이 동작하게 된다.
21. CNI(Calico) 설치
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.2/manifests/calico.yaml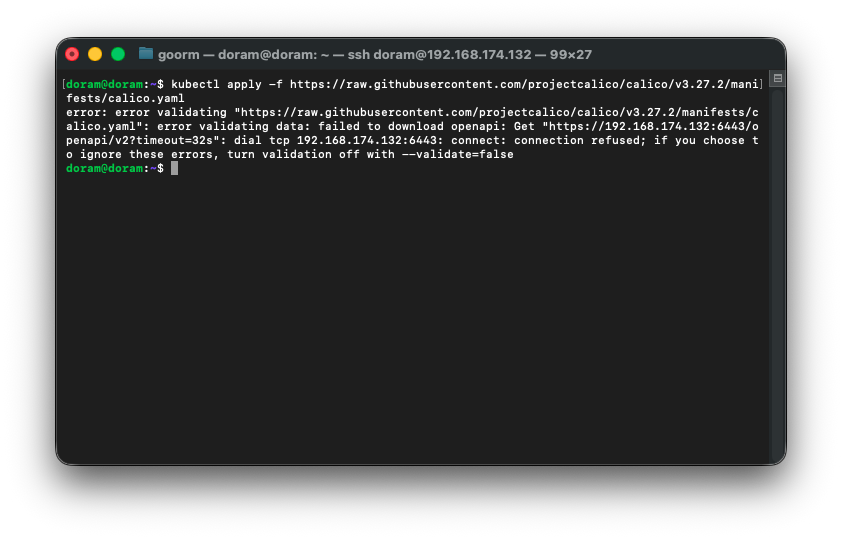
이렇게 떴는데, 이는 kubeadm init을 안 해서 그렇게 된 것이다.
22. kubeadm init
저장소 잘못된 파일 제거를 한 후 init을 진행한다.
sudo rm /etc/apt/sources.list.d/kubernetes.list
sudo apt update그다음 kubeconfig를 설정해준다.
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config23. 프로세스 종료
과거 kubeletdl 10250 프로세스를 잡고 있어서 실패를 했다.
그래서 문제 프로세스를 종료 후, 이전 kubernetes 데이터를 완전 삭제 후, 재시작 준비 및 다시 init을 실행했다.
1) 해당 프로세스 종료
sudo systemctl stop kubelet
sudo kill -9 8642) 이전 쿠버네티스 데이터 완전 삭제
sudo rm -rf /etc/kubernetes
sudo rm -rf /var/lib/kubelet
sudo rm -rf /var/lib/etcd
sudo rm -rf /etc/cni/net.d3) kubelet 다시 정리 후 재시작 준비
sudo kubeadm init \
--pod-network-cidr=192.168.0.0/16 \
--apiserver-advertise-address=192.168.174.1324) kubeadm init 다시 실행
sudo kubeadm init \
--pod-network-cidr=192.168.0.0/16 \
--apiserver-advertise-address=192.168.174.132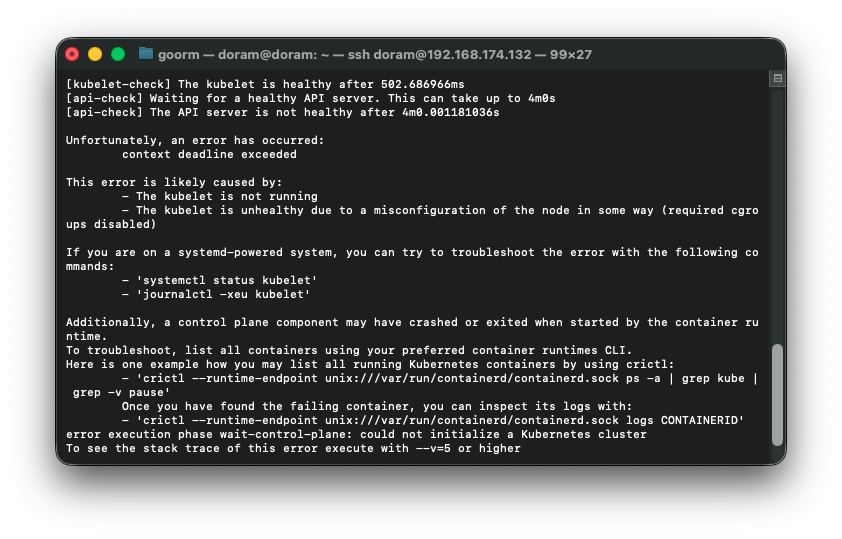
거의 다 됐는데 마지막에 에러가 떴다.
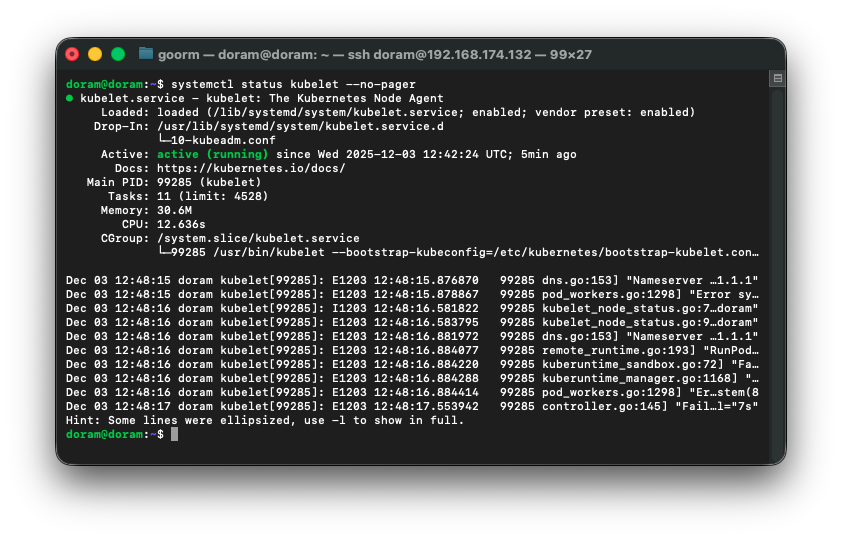
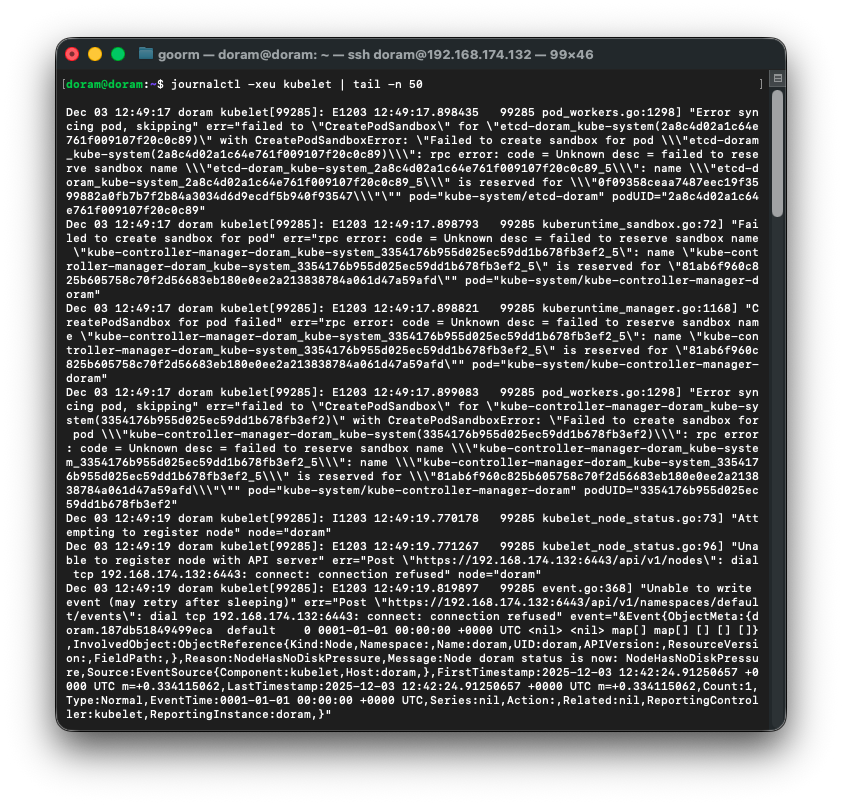
로그를 확인해보니, 로그가 반복해서 뜨고 있는데
예전에 실패했던 kubeadm init 의 잔여 컨테이너·샌드박스가 containerd 안에 남아 있어서
새로운 etcd / apiserver / scheduler static pod 를 만들려고 하면
containerd 가 이름이 중복됐다고 거부하는 상황이다.
그래서 excd sandbox 를 못 만드는 것이다.
24. containerd 내부의 기존 Kubernetes 컨테이너 / 샌드박스 모두 제거
해결 절차는 다음과 같다.
containered 에 있는 모든 kube관련 컨테이너를 조회하고 전부 삭제한다.
그리고 kubeadm 잔여 파일들을 삭제한다.
- 모든 컨테이너 조회
sudo crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock ps -a | grep kube- 전부 삭제(container + sandbox 전체)
sudo crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock rm -f $(sudo crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock ps -aq)sudo crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock sandboxes- kubeadm 잔여파일 완전 제거
sudo rm -rf /etc/kubernetes
sudo rm -rf /var/lib/kubelet
sudo rm -rf /var/lib/etcd
sudo rm -rf /etc/cni/net.d
sudo rm -rf /run/kubeadm25. 컨테이너 / kubelet 재시작
1) containered 정리 및 재시작
sudo systemctl restart containerd2) 현재 Sandbox / Pod 상태 다시 확인
sudo crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock pods
sudo crictl ps -a
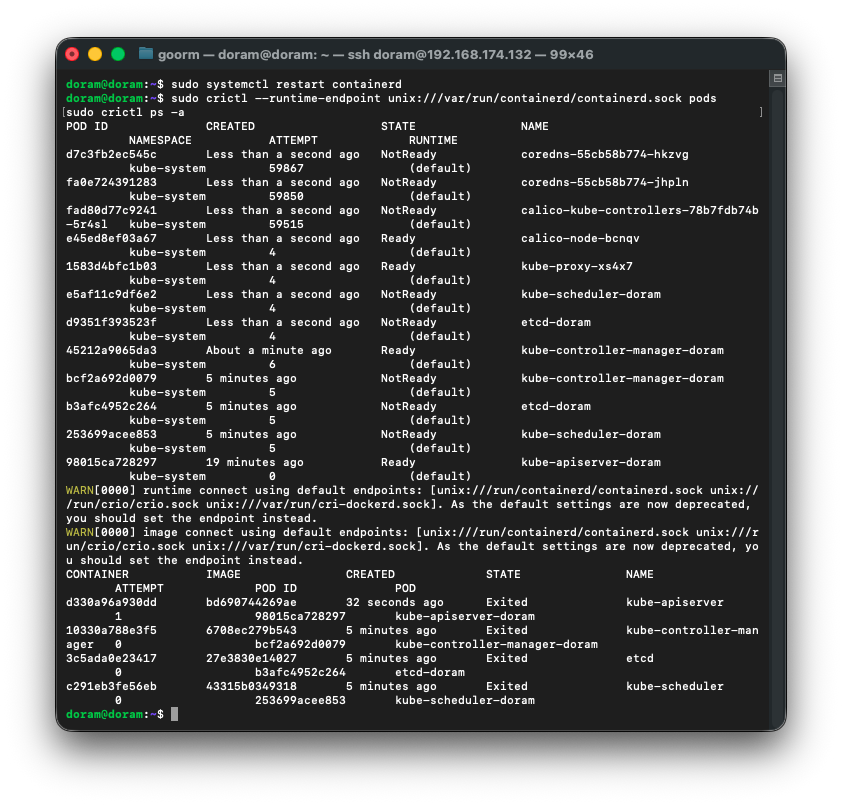
26. etcd apiserver 살리기
1) /etc/kubernetes/manifests 내부 파일 존재 확인
ls -l /etc/kubernetes/manifests했을 때, 밑 4개가 있어야 한다.
etcd.yaml
kube-apiserver.yaml
kube-controller-manager.yaml
kube-scheduler.yaml
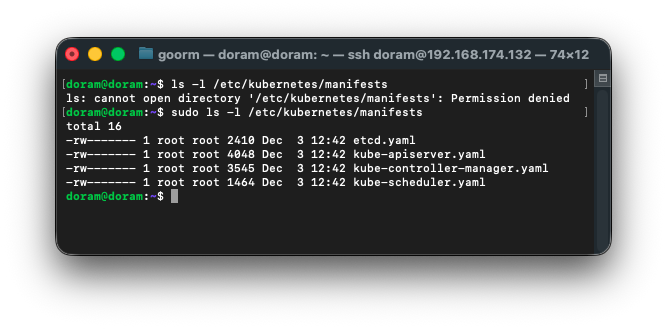
다행히도, 존재했다.
2) kube-apiserver 실제 오류 로그 확인
sudo crictl logs d330a96a930dd여기서 apiserver가 왜 죽었는지 로그가 보인다.
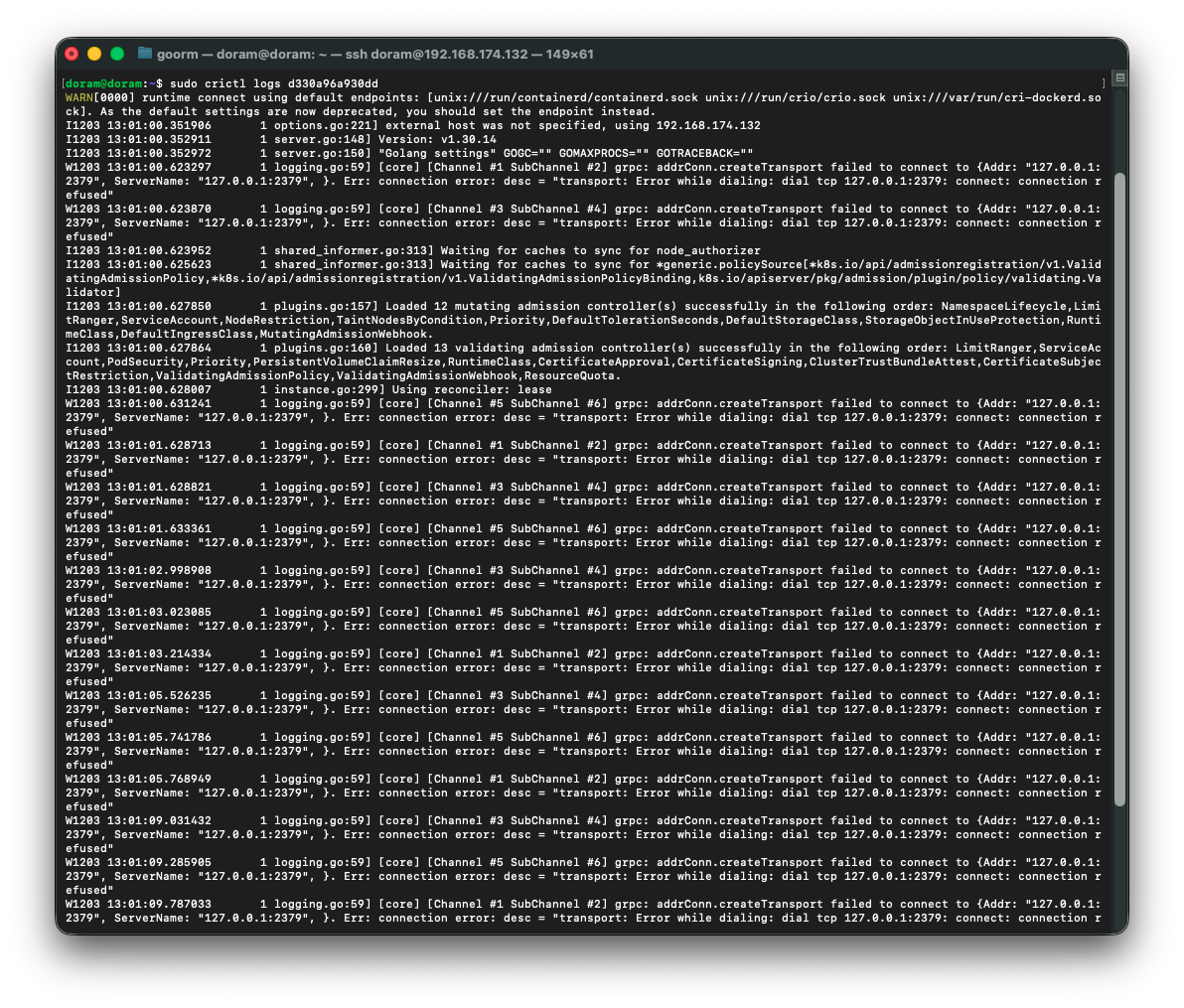
3) etcd 오류 로그 확인
sudo crictl logs 3c5ada0e23417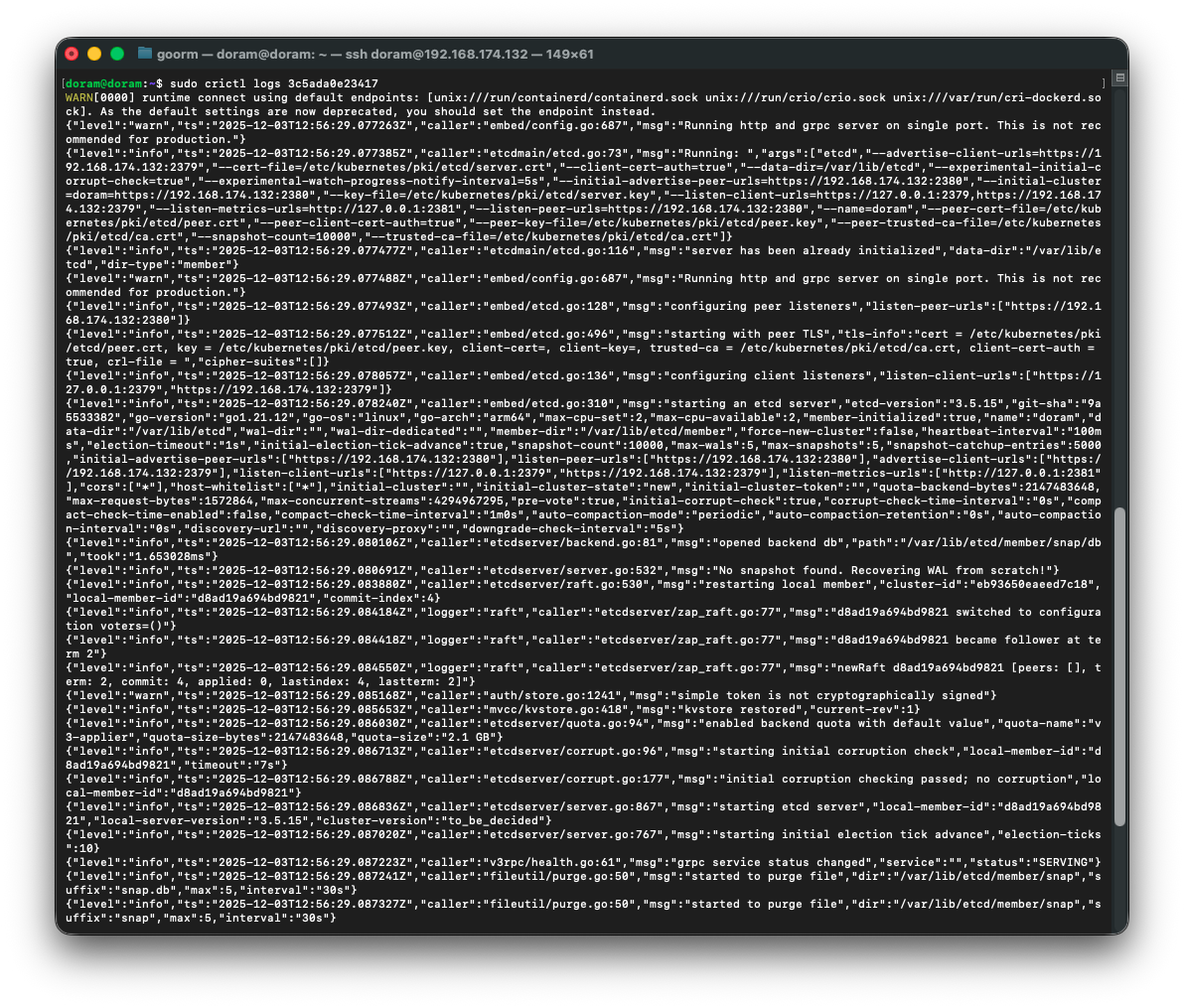
로그를 보니 문제가 보였다. 인증서 문제였다.
27. 인증서 살리기
1) apiserver에서 사용하는 etcd 인증서 실제로 존재하는지 확인
sudo grep -R "etcd" -n /etc/kubernetes/manifests/kube-apiserver.yaml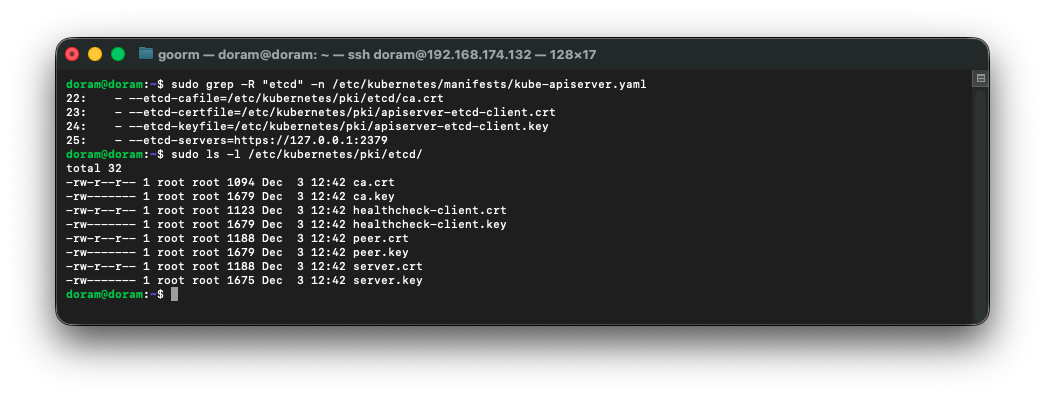
확인해보니 apiserver 인증서 경로가 잘못되었다.
그래서 인증서를 재생성 하기로 했다.
sudo kubeadm init phase certs etcd
sudo kubeadm init phase certs apiserver-etcd-client인증서가 잘 생성되었는지 다음 명령어를 통해 확인할 수 있다.
sudo ls -l /etc/kubernetes/pki/ | grep apiserver-etcd-client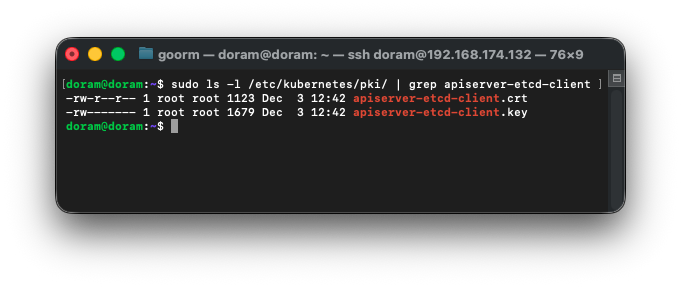
이 두개가 떠있는 것을 확인하여 정상 생성된 것을 확인할 수 있다.
그런데 확인해보니
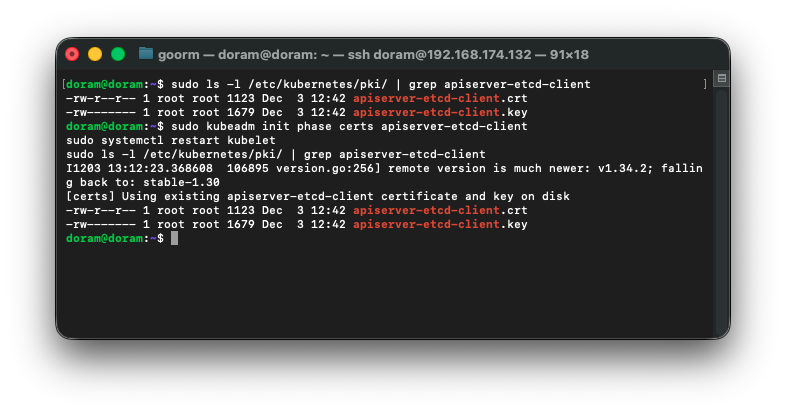
apiserver 가 계속 죽는 이유는, etcd 연결 주소가 잘못되어서 붙을 수 있도록 ip를 변경해준다.
28. 인증서 경로 맞춰주기
sudo nano /etc/kubernetes/manifests/kube-apiserver.yaml를 통해 컨피그 파일을 열어준 후,
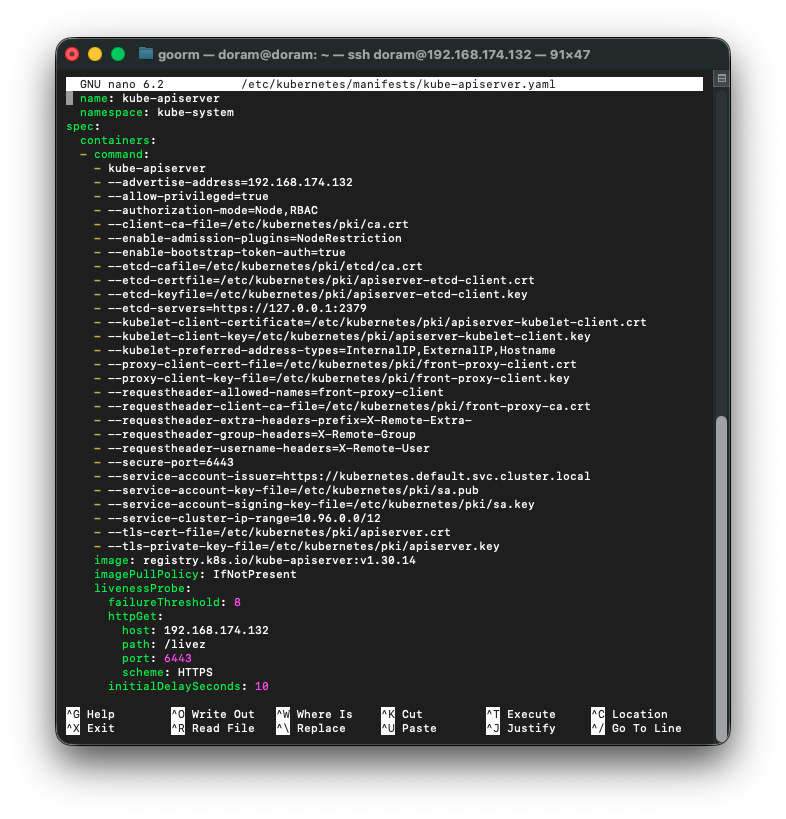
여기에서
--etcd-servers=https://127.0.0.1:2379 이 줄을,
--etcd-servers=https://192.168.174.132:2379
이렇게 수정해준다.
그런 다음 조금 기다린 후,
sudo crictl ps -a | grep kube-apiserver
journalctl -u kubelet -f
kubectl get nodes해당 명령어를 치고 apiserver가 running상태가 되는 것을 확인한다.
evicted가 떴다.
poweroff 후, 메모리랑 cpu를 늘려줬다.
28. vm 재부팅
vm 을 재부팅해준다.
29. 로그 재확인
1)kubelet 상태 확인
sudo systemctl status kubeletactive (running) 떠야한다.
2)노드 상태 확인
kubectl get nodes -o wide여기서 ready가 떠야 하는데, 응답 불가 상태가 나왔다.
3) kube-apiserver 파드 컨테이너 로그 확인
sudo crictl ps -a | grep kube-apiserver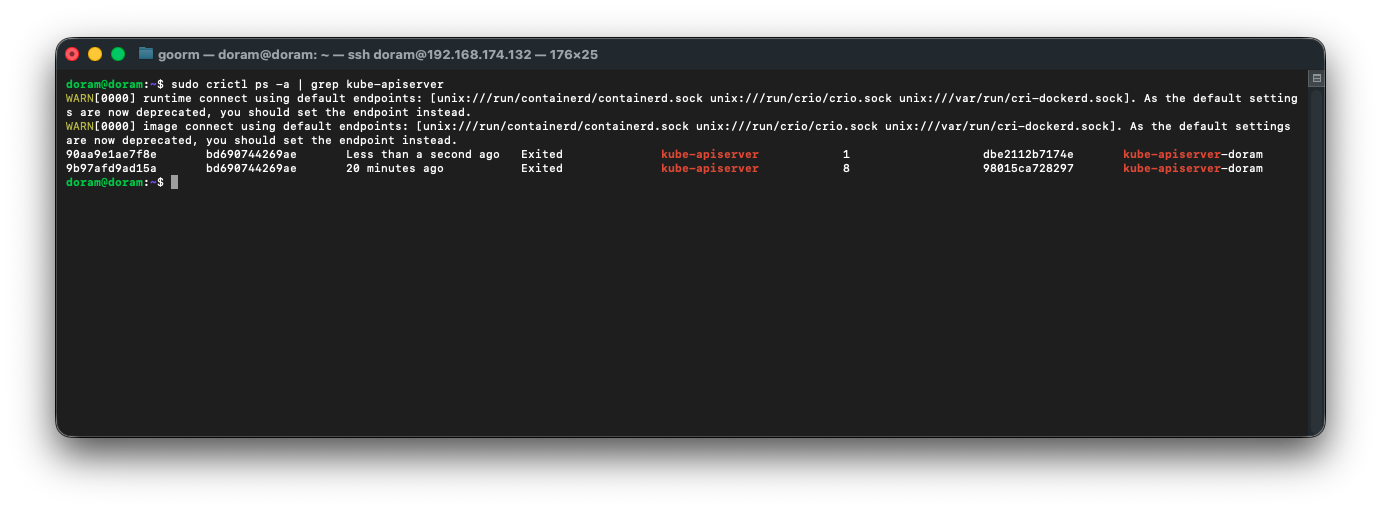
4) 가장 최근 kube-apiserver 컨테이너 로그 확인
sudo crictl logs 90aa9e1ae7f8e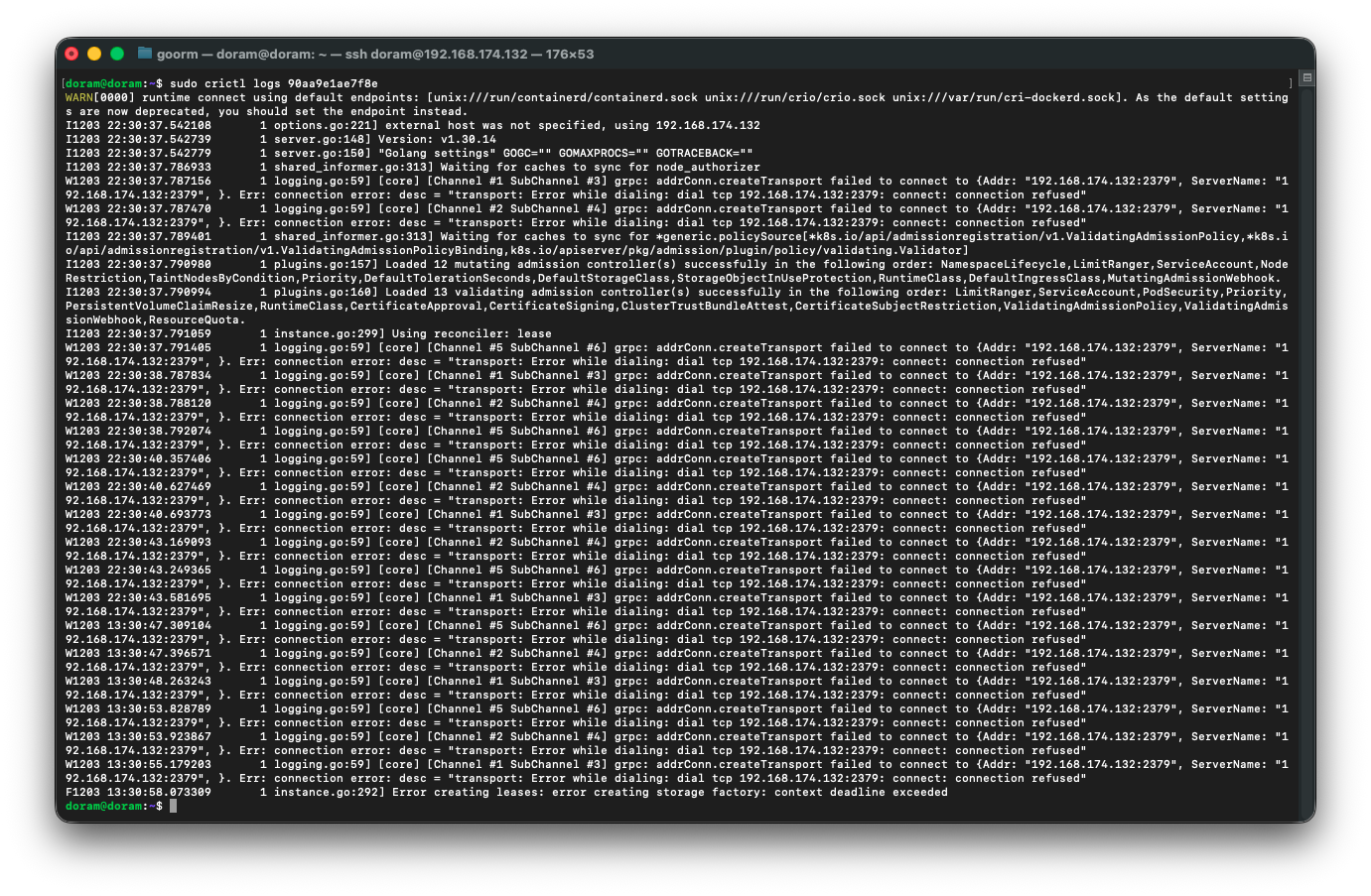
5) etcd 컨테이너 확인
sudo crictl ps -a | grep etcd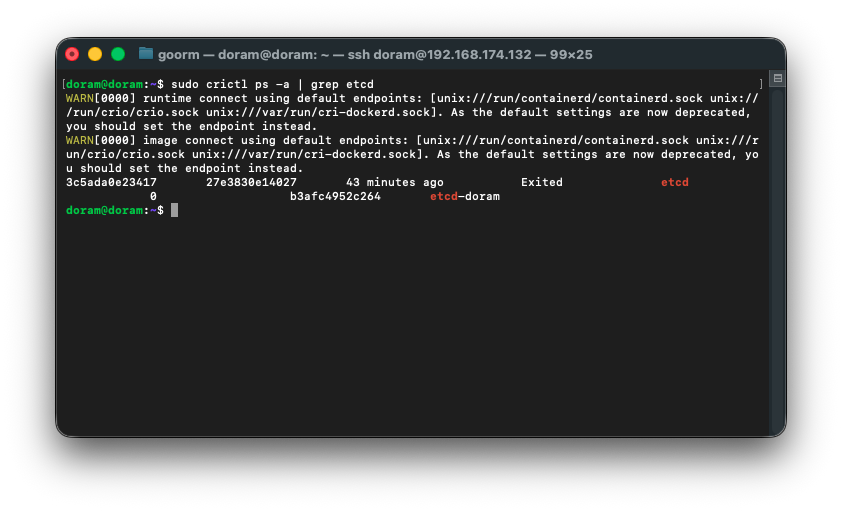
하고 나온 컨테이너 id(3c5ada0e23417)로
sudo crictl logs 3c5ada0e23417 | head -n 40하여 로그를 확인해준다.
확인해보니 인증서 재발급이 필요한 상황으로 판단되었다.
30. apiserver-etcd-client 인증서 재발급
sudo kubeadm init phase certs apiserver-etcd-client --v=5
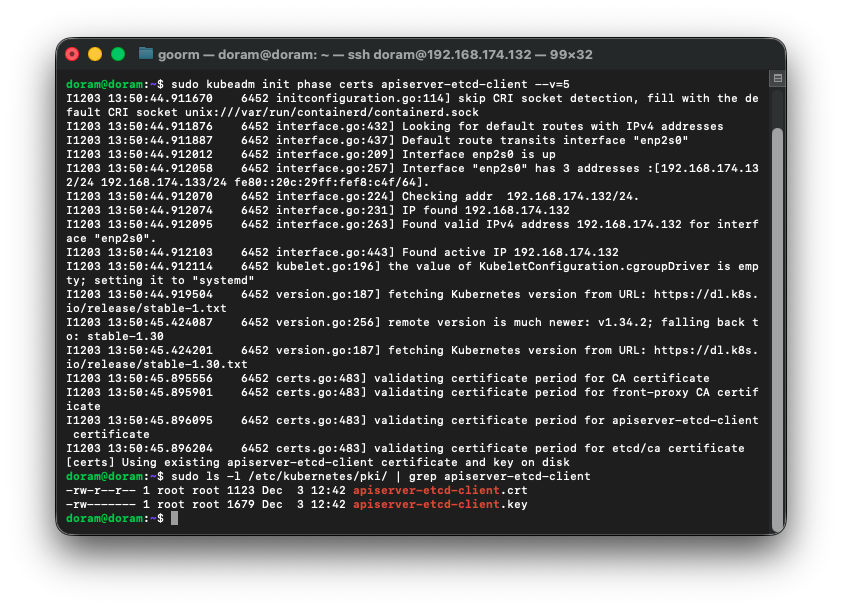
재발급을 하려는데 이미 있다고 재생성이 되지 않는다.
따라서 강제로 기존 인증서를 백업 후 삭제해준다.
1) 기존 인증서 강제로 백업 후 삭제
sudo mv /etc/kubernetes/pki/apiserver-etcd-client.crt /etc/kubernetes/pki/apiserver-etcd-client.crt.bak
sudo mv /etc/kubernetes/pki/apiserver-etcd-client.key /etc/kubernetes/pki/apiserver-etcd-client.key.bak2) 삭제되었는지 확인
ls -l /etc/kubernetes/pki/ | grep apiserver-etcd-client3) 인증서 강제로 재생성
sudo kubeadm init phase certs apiserver-etcd-client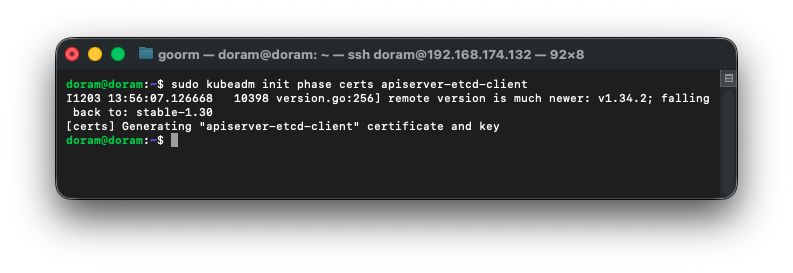
4) 인증서 확인
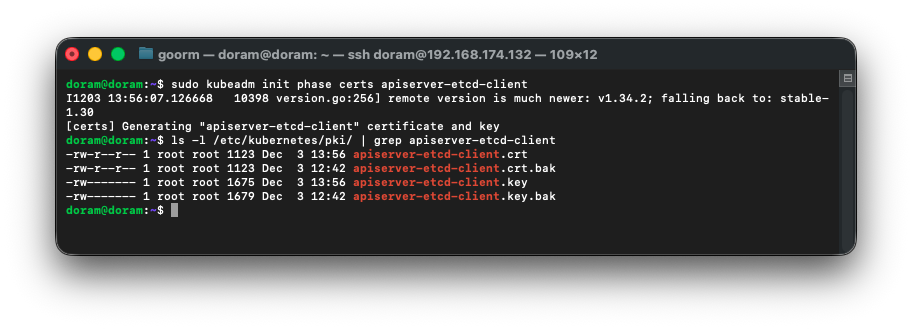
오늘 날짜로 생성된 것을 확인할 수 있다.
31. kuelet 재시작
sudo systemctl restart kubelet
sudo crictl ps -a | grep kube-apiserver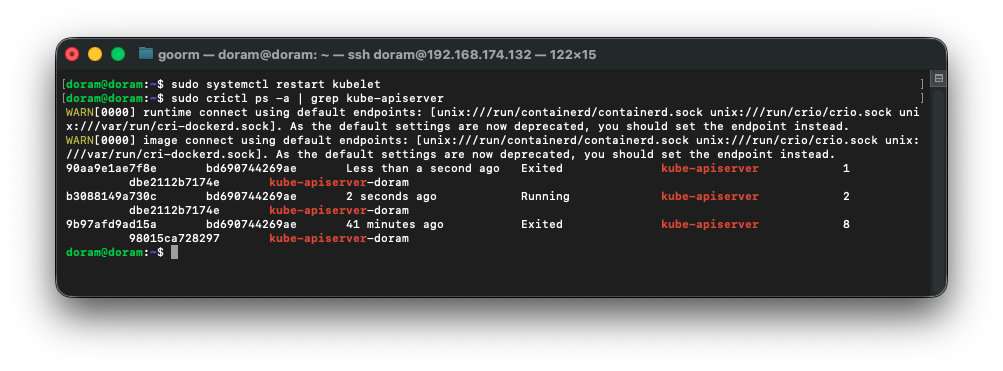
32. API 서버 응답 확인
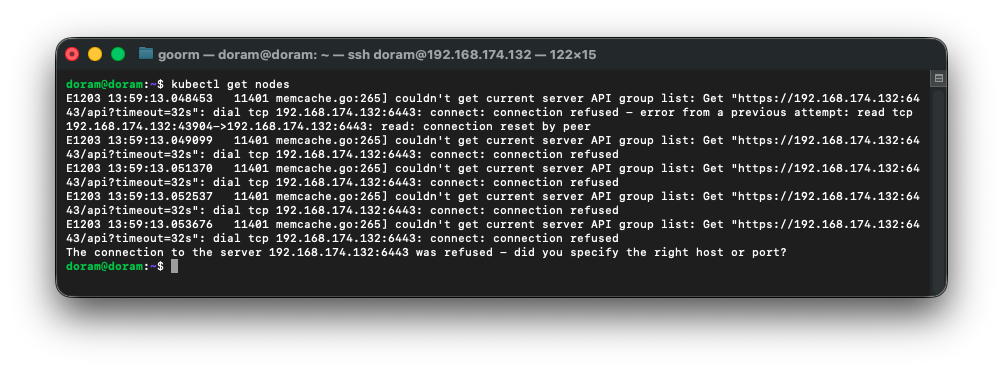
이렇게 에러가 떴다. kube-apiserver 컨테이너는 Running 상태인데, kubectl 이 6443 포트 접속 불가라고 나온다.
따라서 kube-apiserver 컨테이너 로그를 확인한다.
sudo crictl ps -a | grep kube-apiserver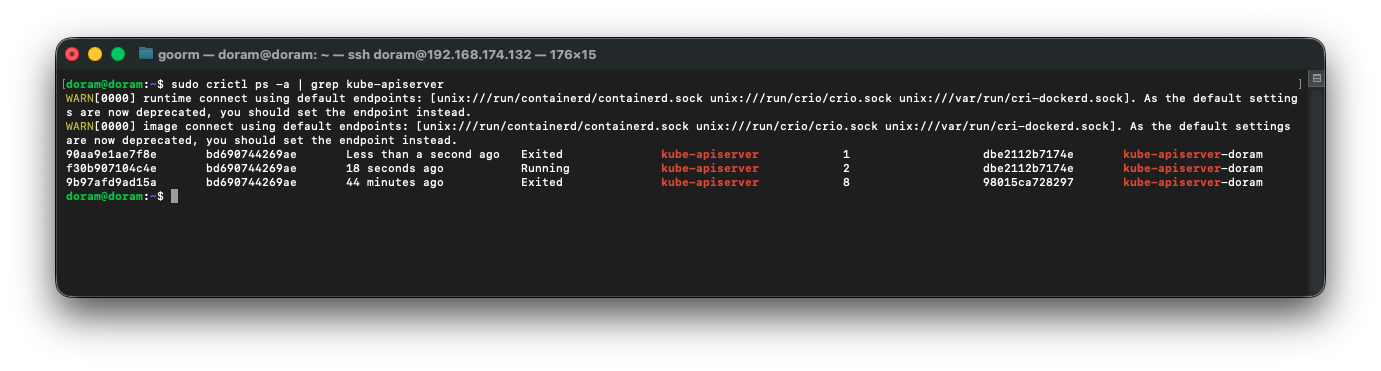
여기에서 running 상태인 것의 로그를 확인한다.
sudo crictl logs f30b907104c4e | head -n 50근데 컨테이너는 재시작되면서 계속 죽고 재시작되고 반복되어서
로그를 보려는 순간 죽어서
최근에 생성된 kube-apiserver 컨테이너 id를 확인하고 바로 2초 안에 로그를 찍어야 한다.
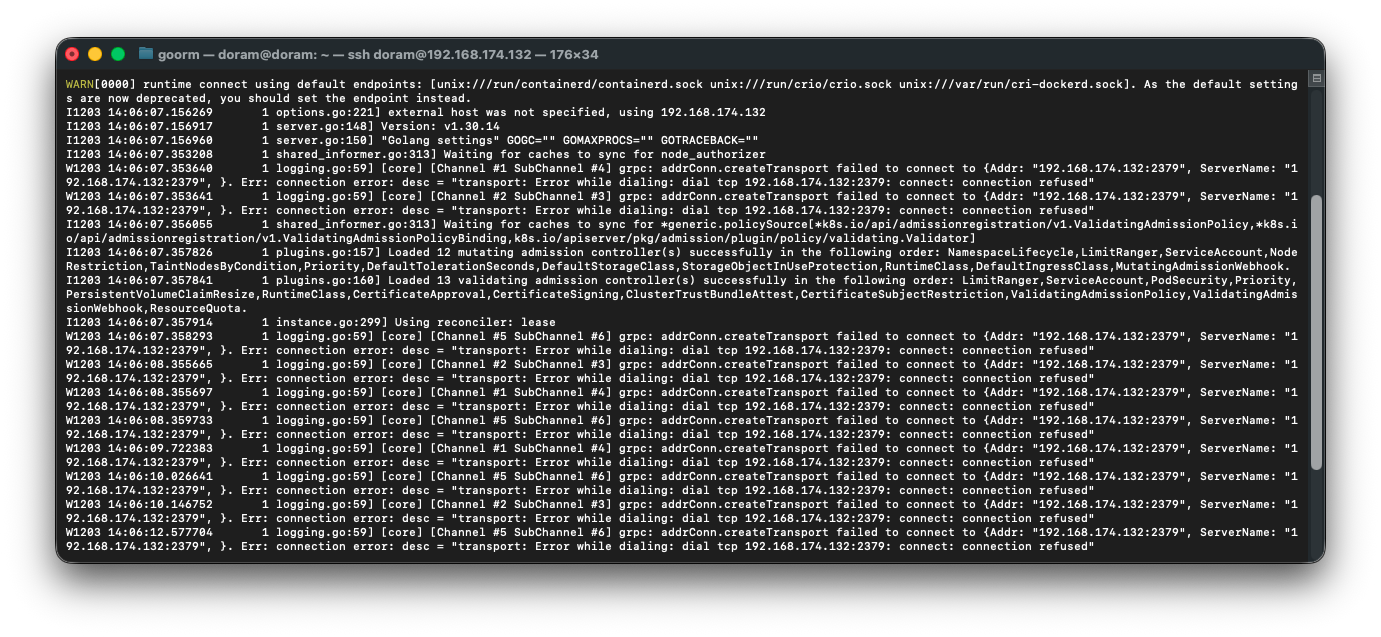
로그를 본 결과,
etcd가 죽어있어서 Kube-apiserver가 포트 6443을 못 열고 죽고 있다.
33. etcd 컨테이너 상태 확인
1) etcd 컨테이너 상태 확인
sudo crictl ps -a | grep etcd
2) etcd 로그 확인
sudo crictl logs 3c5ada0e23417 | head -n 50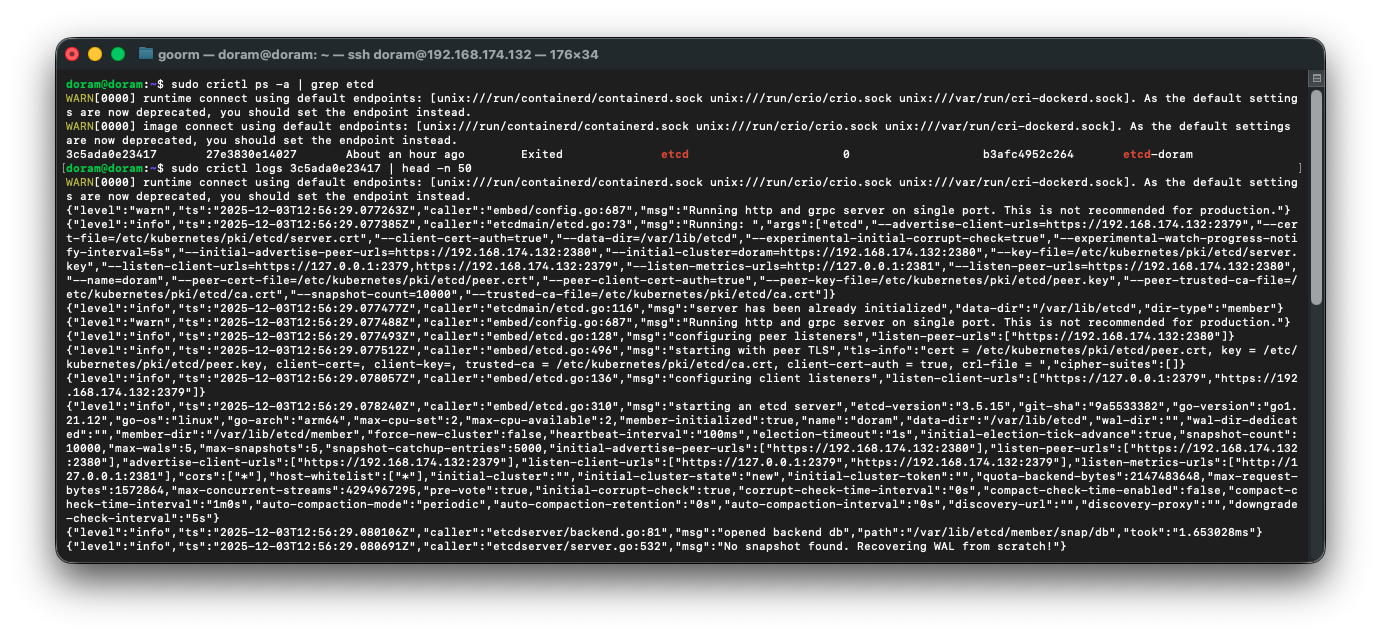
이렇게 결과가 나왔다.
결론적으로는 etcd는 잘 떴는데, 재부팅 하는 과정에서 ip충돌이 생겼고 kube-apiserver가 etcd에 접속을 못하는 상황이다.
34. kubelet 재시작
1) enp2s0 인터페이스 IP 중 하나만 남기고 나머지 제거
현재 enp2s0 상태 확인 후, 174.133/24 하나만 남겨야 한다.
ip a show enp2s0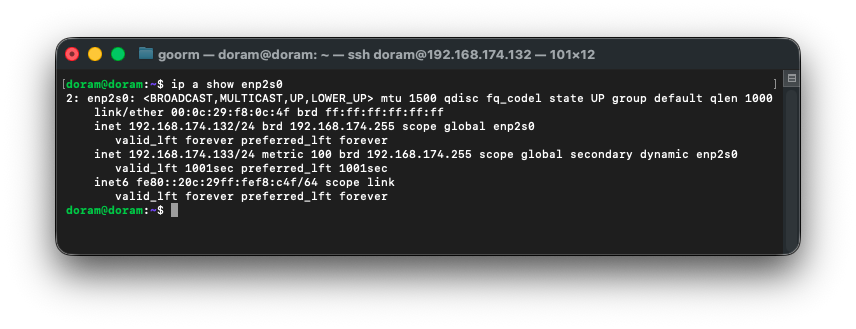
따라서 secondary IP(192.168.174.133)를 제거해준다.
sudo ip addr del 192.168.174.133/24 dev enp2s0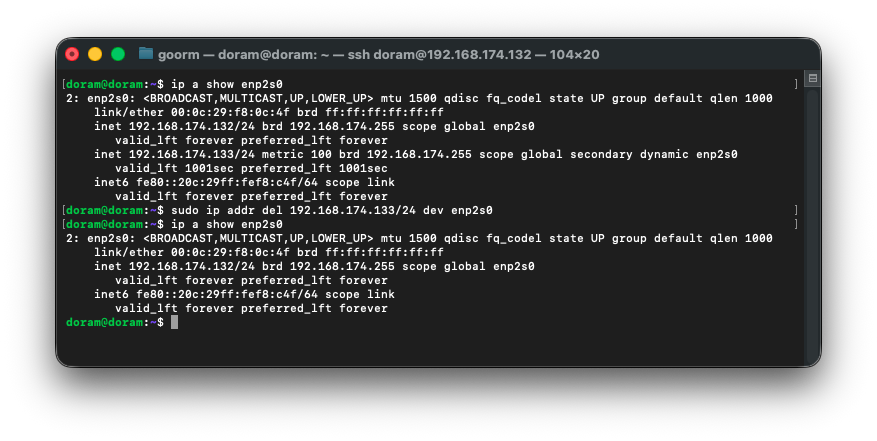
2) netplan 확인 및 제거
sudo cat /etc/netplan/*.yaml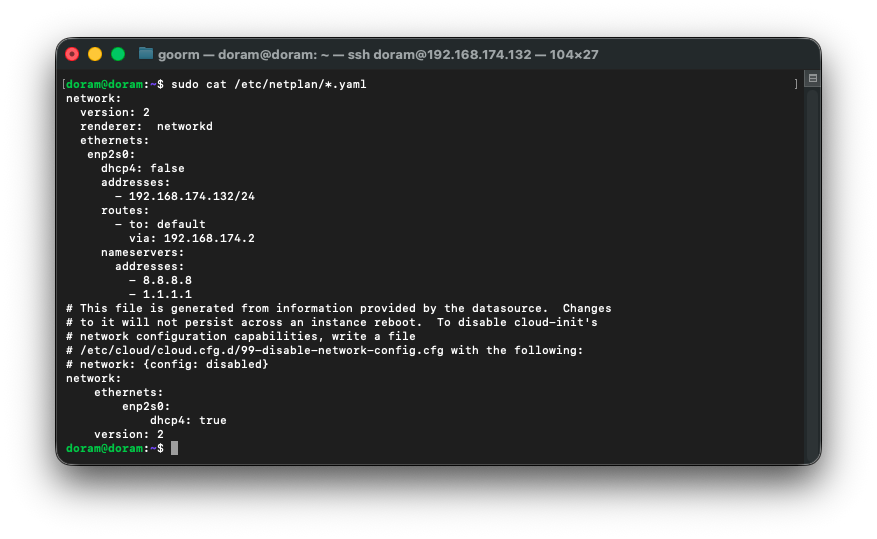
rm 및 vim으로 파일 삭제 및 다시 생성하기로 했다.
sudo rm -f /etc/netplan/*.yamlsudo vim /etc/netplan/01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
enp2s0:
dhcp4: false
addresses:
- 192.168.174.132/24
routes:
- to: default
via: 192.168.174.2
nameservers:
addresses:
- 8.8.8.8
- 1.1.1.1그런 다음, 네트워크를 끈다.
echo "network: {config: disabled}" | sudo tee /etc/cloud/cloud.cfg.d/99-disable-network-config.cfg
그런 다음, 적용해준다.
sudo netplan apply그리고 남아 있는 DHCP IP를 삭제해준다.
sudo ip addr del 192.168.174.133/24 dev enp2s0 2>/dev/null그리고 재부팅해준다.
그리고 ip를 확인해준다.
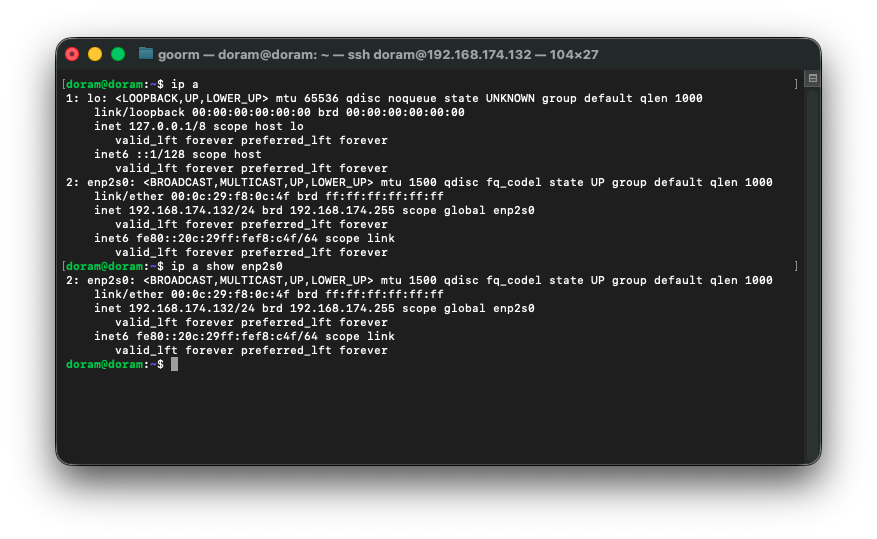
35. kubelet 재시작, apiserver, etcd 확인
1) Kubelet 재시작
sudo systemctl restart kubelet
2) apiserver 컨테이너 상태 확인
sudo crictl ps -a | grep kube-apiserverapi server Running인 것까지 확인했는데,
3) apiserver 로그 확인
sudo crictl logs 52479dc8eb402 | head -n 504) etcd 붙었는지 확인
sudo crictl ps -a | grep etcd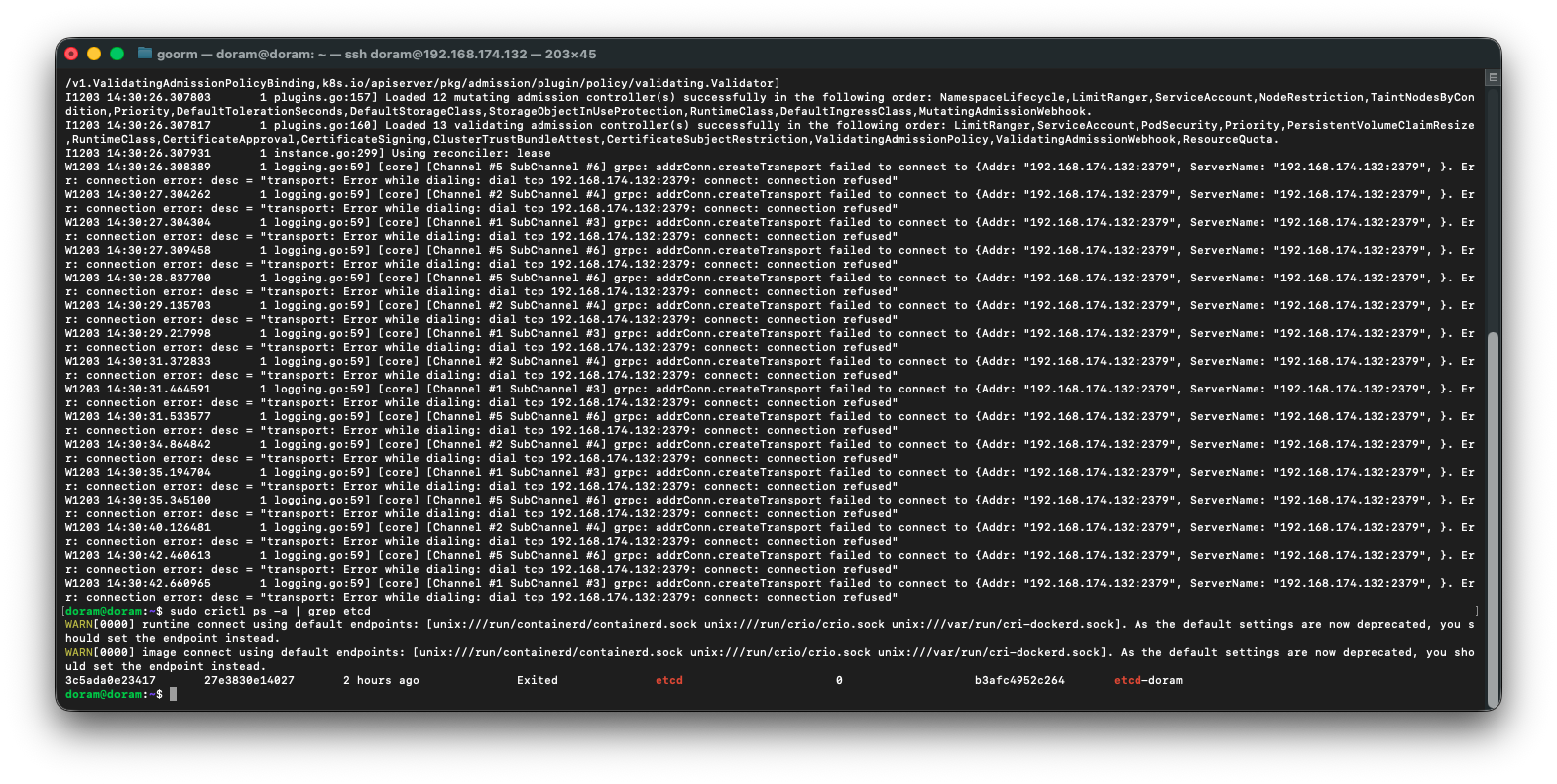
왜 에러가 떴는지 로그는 정상적으로 나와서
sudo systemctl stop kubelet
sudo rm -rf /var/lib/etcd
sudo systemctl start kubelet
sudo crictl ps -a | grep etcd다음 명령어를 실행해보기로 했다.
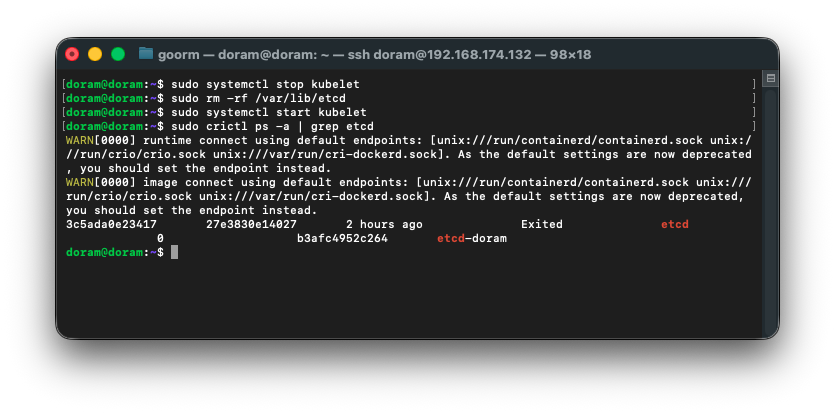
36. static pod yaml 고치기
1) etcd manifest 실제 존재 확인
sudo ls -l /etc/kubernetes/manifests/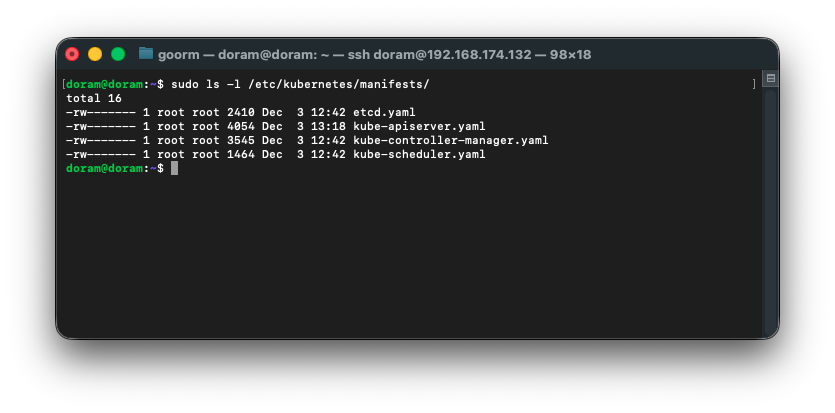
여기에 etcd.yaml 파일이 있으므로 내용을 확인해본다.
2) etcd manifest 내용 확인
sudo cat /etc/kubernetes/manifests/etcd.yaml
doram@doram:~$ sudo cat /etc/kubernetes/manifests/etcd.yaml
apiVersion: v1
kind: Pod
metadata:
annotations:
kubeadm.kubernetes.io/etcd.advertise-client-urls: https://192.168.174.132:2379
creationTimestamp: null
labels:
component: etcd
tier: control-plane
name: etcd
namespace: kube-system
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://192.168.174.132:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt
- --client-cert-auth=true
- --data-dir=/var/lib/etcd
- --experimental-initial-corrupt-check=true
- --experimental-watch-progress-notify-interval=5s
- --initial-advertise-peer-urls=https://192.168.174.132:2380
- --initial-cluster=doram=https://192.168.174.132:2380
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --listen-client-urls=https://127.0.0.1:2379,https://192.168.174.132:2379
- --listen-metrics-urls=http://127.0.0.1:2381
- --listen-peer-urls=https://192.168.174.132:2380
- --name=doram
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
image: registry.k8s.io/etcd:3.5.15-0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /health?exclude=NOSPACE&serializable=true
port: 2381
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
name: etcd
resources:
requests:
cpu: 100m
memory: 100Mi
startupProbe:
failureThreshold: 24
httpGet:
host: 127.0.0.1
path: /health?serializable=false
port: 2381
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
volumeMounts:
- mountPath: /var/lib/etcd
name: etcd-data
- mountPath: /etc/kubernetes/pki/etcd
name: etcd-certs
hostNetwork: true
priority: 2000001000
priorityClassName: system-node-critical
securityContext:
seccompProfile:
type: RuntimeDefault
volumes:
- hostPath:
path: /etc/kubernetes/pki/etcd
type: DirectoryOrCreate
name: etcd-certs
- hostPath:
path: /var/lib/etcd
type: DirectoryOrCreate
name: etcd-data
status: {}
doram@doram:~$
현재 이렇게 되어있다.
yaml 파일은 아주 멀쩡하다.
37. var/lib/etcd 디렉터리 권한 문제 해결
1) kubelet 완전히 멈추기
sudo systemctl stop kubelet2) etcd 데이터 디렉터리 완전히 삭제
sudo rm -rf /var/lib/etcd3) 디렉터리 다시 생성 + 권한 맞게 설정
sudo mkdir -p /var/lib/etcd
sudo chown root:root /var/lib/etcd
sudo chmod 700 /var/lib/etcd싱글 노드 kubeadm etcd는 700 root:root 여야 정상 작동한다.
권한이 틀리면 etcd가 db 초기화를 못 해서 바로 죽는다.
4) kubelet 재시작
sudo systemctl start kubelet5) etcd 컨테이너 생성 확인
sudo crictl ps | grep etcd여기서
Running 이 떠야 한다.
6) kube-apiserver도 자동으로 살아날 것
etcd가 살아야 kube-apiserver도 연결된다.
sudo crictl ps | grep kube-apiserver7) 확인하기
sudo crictl ps | grep etcd
sudo crictl ps | grep kube-apiserver
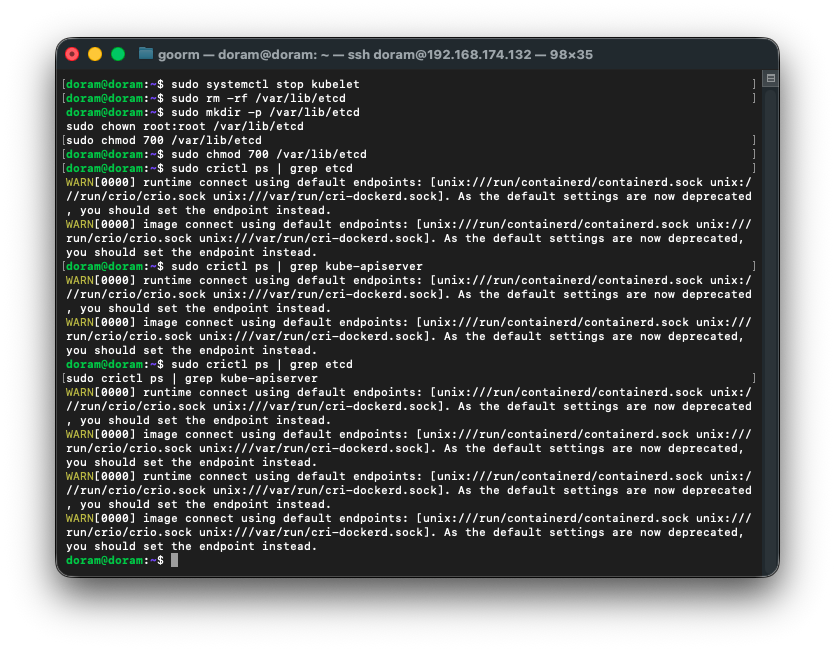
38. kubelet 다시 켜기
sudo systemctl start kubelet그런 다음 , 오랜 시간 기다린 후 다음 명령어를 실행해준다.
sudo crictl ps | grep etcd
sudo crictl ps | grep kube-apiserver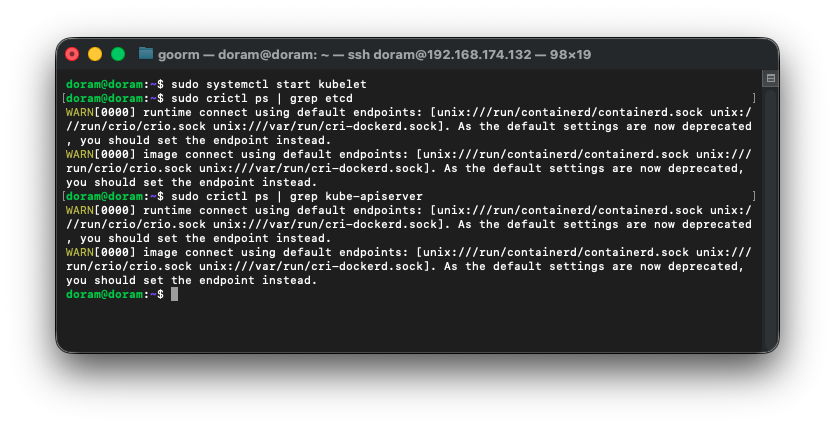
39. kubelet 로그 확인
sudo journalctl -u kubelet -n 50 --no-pager
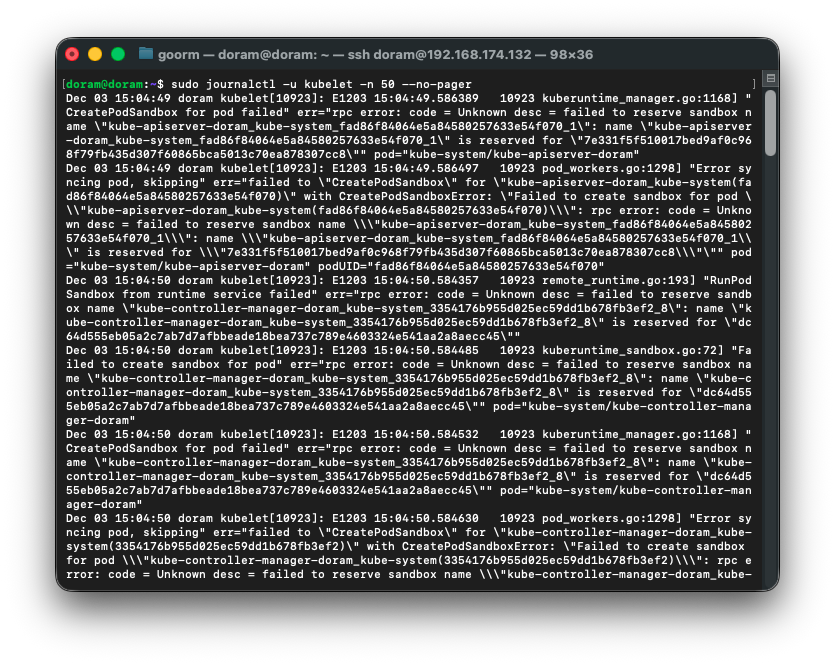
로그를 보니 containerd 내부에 “이전 static pod sandbox”가 남아 있어 이름이 충돌된다.
따라서 kubelet 끄고 containered 모든 컨테이너를 삭제해준다.
40. kubelet 끄고, containered 삭제 및 재시작
1) kubelet 끄기
sudo systemctl stop kubelet2) containerd 모든 컨테이너 삭제
sudo crictl ps -a
sudo crictl pods -a3) static pod 디렉토리 확인
ls -l /etc/kubernetes/manifests4) kubelet 재시작
sudo systemctl start kubelet5) 다시 상태 확인
sudo crictl ps | grep etcd
sudo crictl ps | grep kube-apiserver41. kubelet 완전히 중지 및 컨테이너 제거 및 확인, pod 제거
1) kubelet 완전히 중지
sudo systemctl stop kubelet2) 모든 컨테이너 제거
sudo crictl rm -f $(sudo crictl ps -aq)삭제 후 다시 확인:
sudo crictl ps -a→ 아무것도 안 나와야 정상이다.
3)모든 pod(sandbox) 제거
crictl은 -a 옵션 없으니까 이렇게 해야한다.
파드 ID만 출력:
sudo crictl pods -q삭제:
sudo crictl rmp -f $(sudo crictl pods -q)확인:
sudo crictl pods→ 비어 있어야 정상.
4) 남은 파드 전부 강제삭제
sudo crictl rmp -f $(sudo crictl pods -q)sudo crictl pods했을 때 아무것도 안 나와야 한다.
5) 컨테이너도 다 삭제
sudo crictl rm -f $(sudo crictl ps -aq)그리고 확인해준다.
sudo crictl ps -a
6) kubelet 재시작
sudo systemctl restart kubelet
그리고 확인해준다.
sudo crictl ps | grep etcd
sudo crictl ps | grep kube-apiserver
sudo crictl ps | grep scheduler
sudo crictl ps | grep controller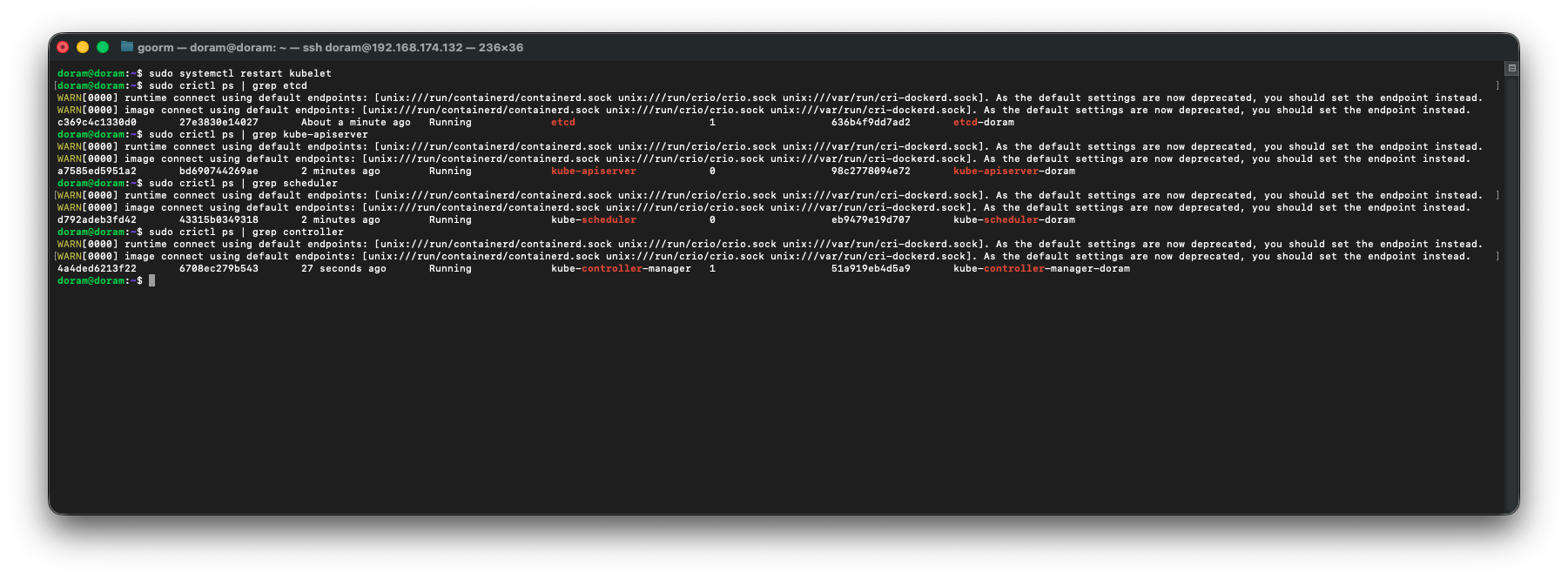
드디어 정상작동하는 것을 확인할 수 있다.
42. 노드 Ready 확인
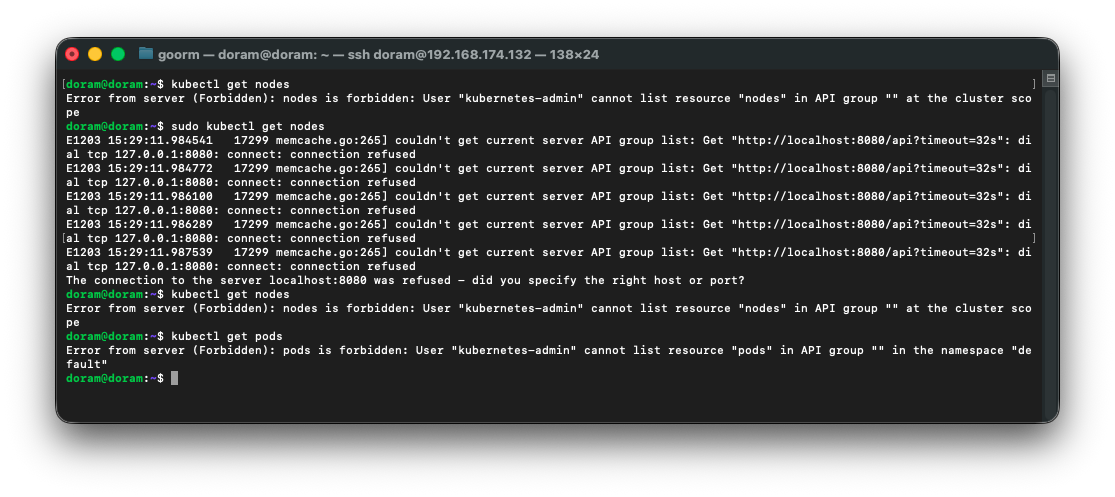
노드를 확인하려는데 kubeconfig가 깨져서 권한이 없다는 메세지가 뜨는 것이다.
이유를 확인하니 config가 깨졌다.
43. kubeadm이 자동으로 생성한 admin.conf 를 다시 복사하기
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config그리고 다시 확인해준다.
kubectl get nodes
kubectl get pods -A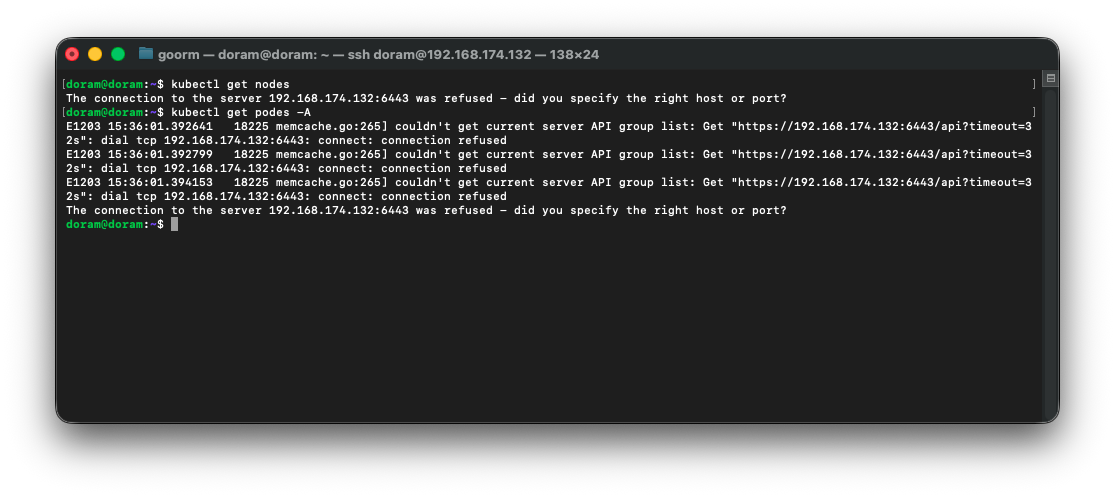
이렇게 떴는데, API server가 안 떠 있어서 그런것이었다.
44. API Server 다시 띄우기
1) apiserver / etcd 상태 다시 확인
sudo crictl ps | grep kube-apiserver
sudo crictl ps | grep etcd2) 6443 포트 열려있는지 확인
sudo ss -tlnp | grep 64433) apiserver 로그 직접 보기
sudo crictl logs $(sudo crictl ps -q --name kube-apiserver)
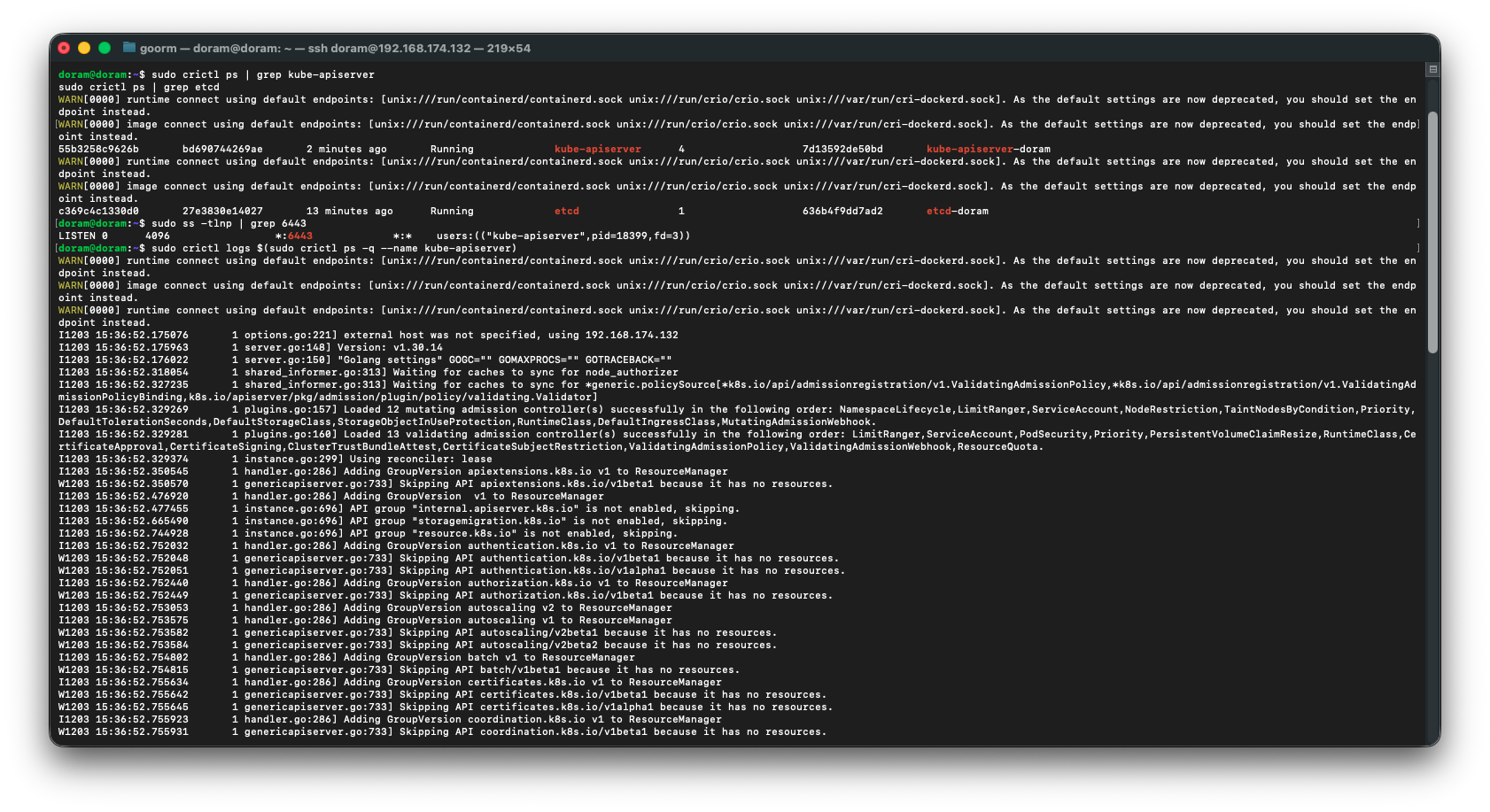
etcd 데이터 날렸는데
kubelet이 Node 다시 등록하기 전에 RBAC/토큰/인증이 꼬여서 해당 일이 일어났다.
45. kubelet 인증 파일 삭제 및 재등록
1) kubelet 인증 파일 삭제
sudo systemctl stop kubelet
sudo rm -f /var/lib/kubelet/pki/kubelet-client*
sudo rm -f /var/lib/kubelet/pki/kubelet.crt
sudo rm -f /var/lib/kubelet/kubeconfig2) kubelet 재시작
sudo systemctl start kubelet
sudo systemctl restart kubelet3) 30초 기다린 뒤 Node 확인
kubectl get nodes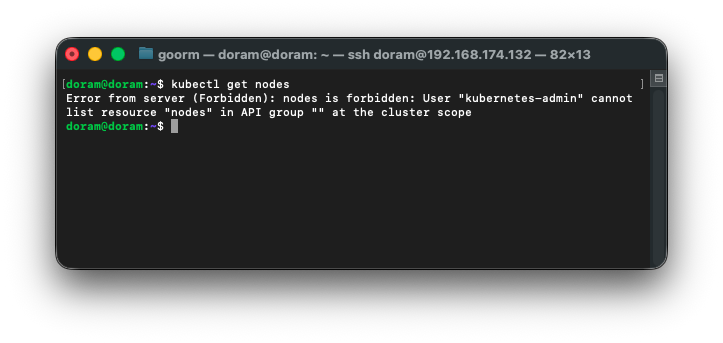
아직도 안되었다.
그래서 다음 행동을 하였다.
4) kubeadm 클러스터 자격증명 재생성
sudo kubeadm init phase kubeconfig kubelet
sudo systemctl restart kubelet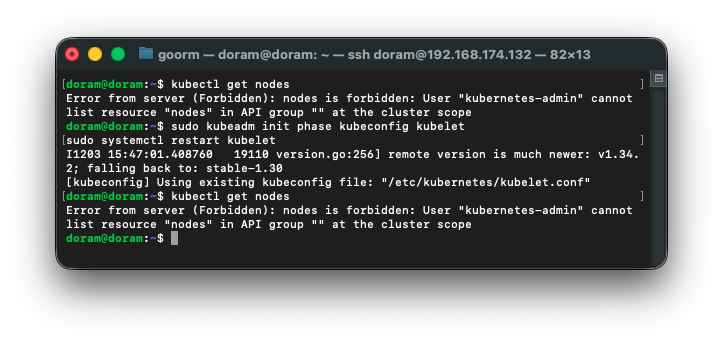
확인해보니, kube-apiserver나 kubelet 문제가 아니라
RBAC가 날아간 상태라 다시 만들어주어야 한다.
46. RBAC 생성
sudo kubectl apply -f - <<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubernetes-admin-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: kubernetes-admin
EOF
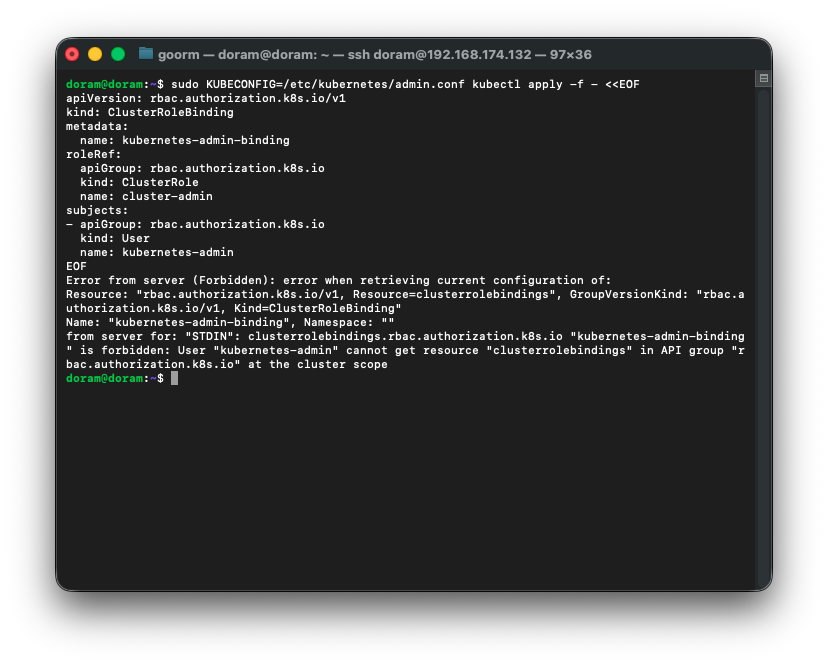
위와같이 뜨는데, 지금 admin.conf 자체가 ‘kubernetes-admin’으로 인식되지 않고 있다는 뜻이다.
따라서 kubeadm init을 재실행 시켜서 관리자 권한을 복구한다.
47. kubeadm 재생성
sudo kubeadm init phase upload-config kubeadm
그다음,
sudo kubeadm init phase upload-config kubelet
그리고
sudo kubeadm init phase kubeconfig all
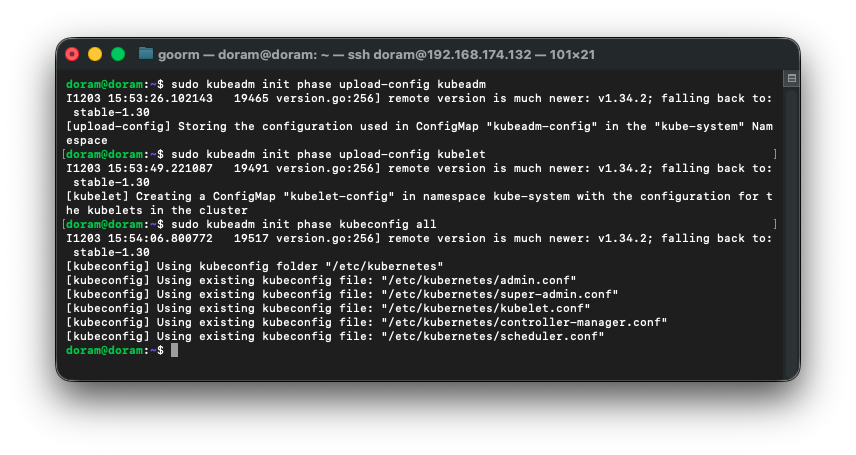
이렇게 아직까지는 정상적으로 진행되었다.
48. 기본 Addon + RBAC 강제 재적용
sudo kubeadm init phase addon all그런 다음,
kubectl get nodes를 실행해준다.
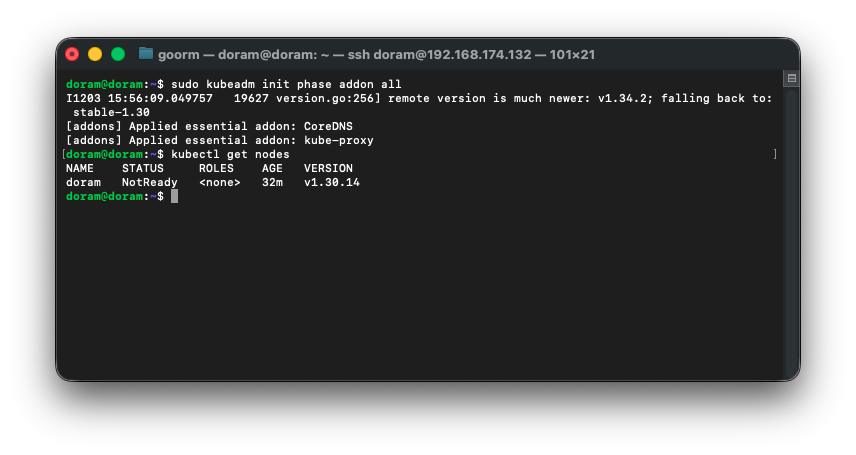
49. CNI 설치(실패)
NotReady는 Calico가 설치되지 않아서 그런것이라
Calico를 설치한다.
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.3/manifests/calico.yaml그 후, 다시 상태를 확인한다.
kubectl get nodes
kubectl get pods -A | grep calico
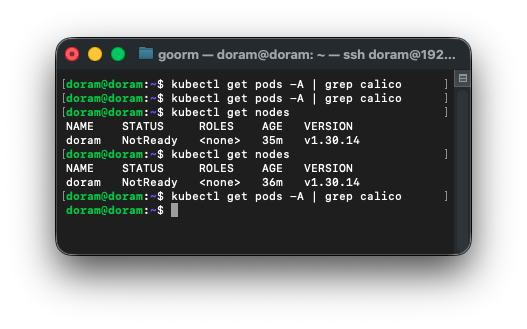
아무것도 안 뜨는 것은 네트워크 애드온 설치가 실제로 적용이 안됐다. 그래서
cni가 제대로 설치가 아직 안 했거나 중간에 실패한 경우이다.

아무 설정이 안 나오는것을 보니 네트워크 CIDR 빠진 것이다.
그래서 클러스터 초기화를 하기로 결정했다.
sudo kubeadm reset -f
sudo rm -rf /etc/cni/net.d
sudo kubeadm init --pod-network-cidr=192.168.0.0/16
50. kubeconfig 적용
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
그리고 확인한다.
kubectl get nodes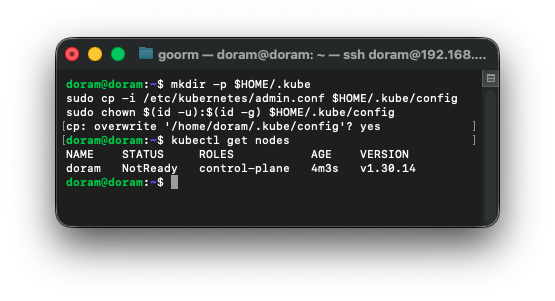
NotReady지만 괜찮다.
51. Flannel설치
Calico가 오류가 많이 나서 Flannel로 설치하기로 했다.
kubectl apply -f https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
kubectl get pods -n kube-system
kubectl get nodes하고나서 모든 pod가 Running이 되고,
node가 running 상태가 되어야 하는데 다음과 같이 떴다.
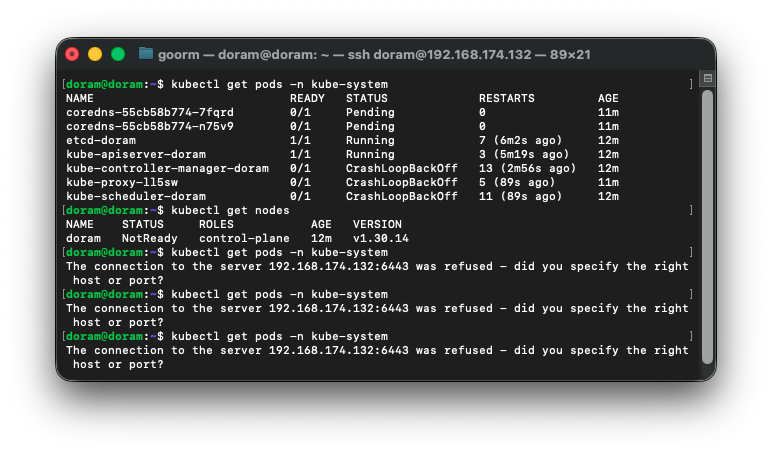
실제 집 네트워크가 불안정하여 그런 것 같다.
52. Caclico 다시 설치
caclico 설치하다 잘 안되어 flannel을 설치하기로 했는데, flannel도 에러떠서
그냥 calico를 다시 설치하기로 했다.
1) 과거 설치했던 설정들, 리소스 삭제
sudo rm -rf /etc/cni/net.d/*kubectl delete -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.3/manifests/calico.yaml2) kubelet 재시작
sudo systemctl restart kubelet3) calico 재설치
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.3/manifests/calico.yaml4) 상태 확인
kubectl get pods -n kube-system | grep calico
kubectl get nodes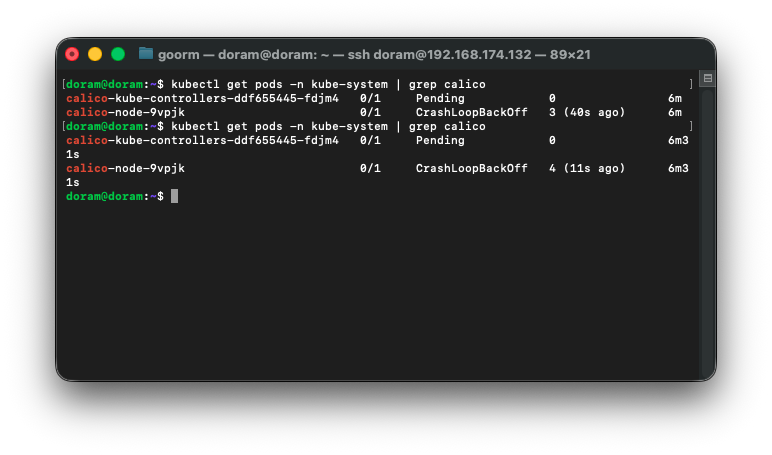
CrashLoopBackOff, running 상태가 반복적으로 나타나서
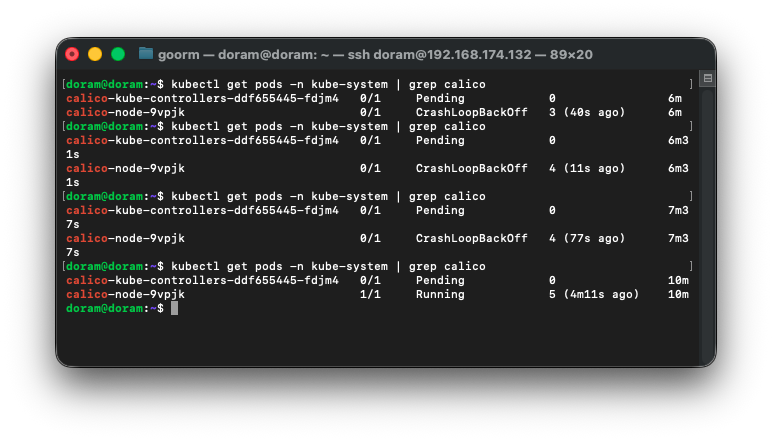
일단 기다려보기로 했다.
중간에 네트워크가 끊긴 것 같아서 오류가 뜬 것 같았다.
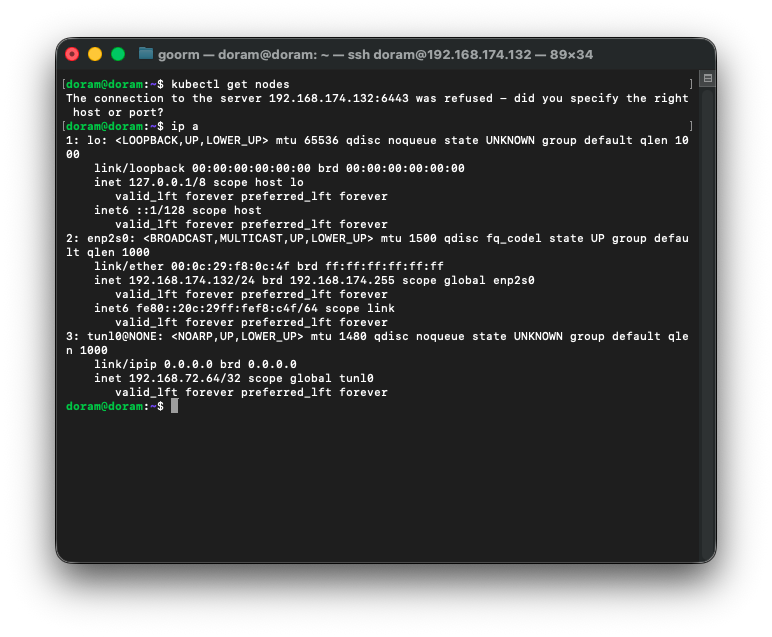
tunl0 인터페이스가 다시 살아났다.
5) Calico 먼저 완전히 삭제 및 다시 설치 하기로 했다.
sudo rm -rf /etc/cni/net.d/*kubectl delete -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.3/manifests/calico.yamlkubectl delete daemonset calico-node -n kube-system --force --grace-period=0
kubectl delete deployment calico-kube-controllers -n kube-system --force --grace-period=0caclico crd도 싹 삭제해준다.
kubectl delete crd bgpconfigurations.crd.projectcalico.org \
bgppeers.crd.projectcalico.org \
felixconfigurations.crd.projectcalico.org \
ippools.crd.projectcalico.org \
clusterinformations.crd.projectcalico.org \
kubecontrollersconfigurations.crd.projectcalico.org \
networkpolicies.crd.projectcalico.org --force --grace-period=0그런 다음 kubelet 을 재시작해주고 kubectl get nodes 하여 notReady 상태인 것을 확인한다.
마지막으로 calico maifest 버전을 설치해준다.
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.3/manifests/calico.yaml
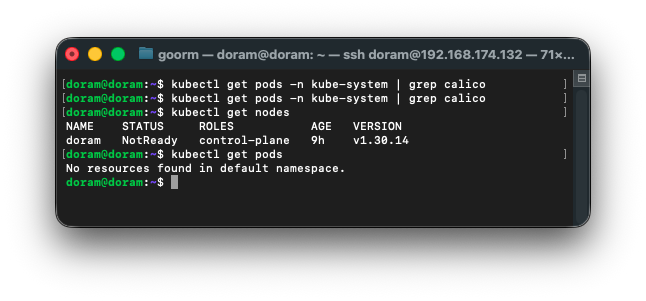
자꾸 api server 가 끊겼다 안 끊겼다 해서 봤더니 CPU 및 메모리가 꽉차서 문제가 된 로그를 확인할 수 있었다. 따라서 가상환경을 끈 후,
다시 리소스를 늘렸다.
그런 후, 네임스페이스 및 찌꺼기 파일들을 삭제하였으며
헬름 및 프로메테우스 재설치를 했더니 설치가 성공적으로 된 것을 확인할 수 있었다.
