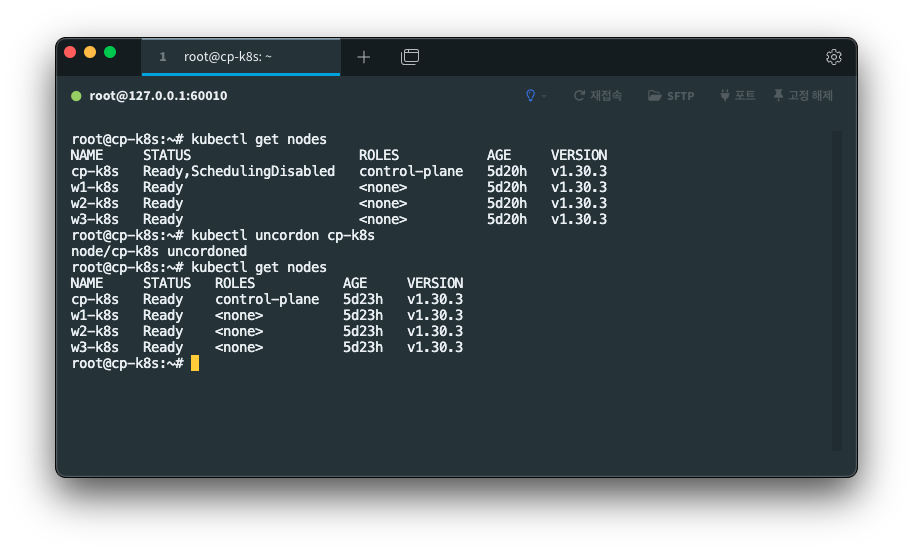
컴퓨터가 절전상태가 되거나 가상머신을 껐다 킬 때마다 노드의 상태가 매우 불안정해졌다.
심지어 오늘은 Ready,SchedulingDisabled상태로 떠서
대체 왜 그런지 이해하고 해결하고자 마음먹었다.
(이전에 찍어놨던 스냅샷으로 복원하고 싶었지만 해결해보기로 했다.)
왜 마스터가 SchedulingDisabled 상태가 됐을까?
문제가 발생한 원인을 정확히 알고 싶어서 공식 문서와 GitHub 이슈들을 찾아봤다.
먼저 Kubernetes 공식 Node API 문서에서는 unschedulable 필드를 이렇게 설명한다.
“Unschedulable indicates that the node is not allowed to schedule new pods.”
— Kubernetes 공식 문서(NodeSpec)
즉, 노드가 스케줄링 불가 상태라는 뜻이며,
kubectl cordon 같은 명령을 실행했을 때 이 플래그가 설정된다.
실제로 kubectl cordon 문서에서도 이렇게 명시되어 있다.
“Mark node as unschedulable.”
— kubectl cordon 공식 문서
즉, 노드를 cordon하면 Node.status에 SchedulingDisabled가 뜨는 것은 “정상적인 동작”이란 뜻.
그럼 나는 cordon을 하지도 않았는데 왜 이 상태가 되었을까?
구글링 중 Kubernetes GitHub Issue에서
다음과 같은 내용을 발견했다.
노드가 재부팅, 가상머신 일시정지(suspend),
네트워크가 끊긴 상태에서 kubelet이 다시 연결되기 전 상황에서
unschedulable 상태가 남아버릴 수 있다.
(노드가 재부팅 후 unschedulable 상태로 남는 사례)
- github 주소
즉,
내 환경은 VirtualBox로 구성된 멀티노드 클러스터라서
컴퓨터가 절전모드가 되거나 VM을 껐다 켜는 과정에서
마스터 노드의 kubelet이 불완전하게 복구된 것으로 보였다.
해결방법
그래서 해결 방법은 간단했다.
kubectl uncordon cp-k8s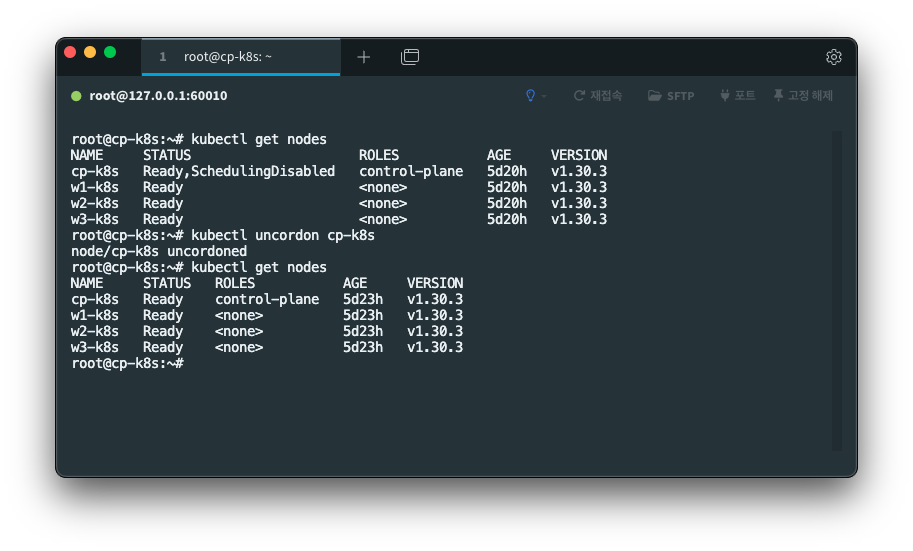
이 명령을 실행한 뒤 노드 상태가 정상적으로 복구되었고,
Prometheus UI가 다시 정상적으로 접속되었다.
uncordon 명령어를 쳐주니 정상으로 돌아왔다.
기존에 썼던
cordon, uncordon 게시물 게시물과 병행해서 읽으니
더 이해가 잘 갔다.
쉽게 해결되어 다행이다..
정리
- SchedulingDisabled = NodeSpec.unschedulable = 스케줄 막힘
- cordon은 공식적으로 “unschedulable 상태로 표시하는 명령”
- VM 재부팅 / sleep / 네트워크 장애 시 unschedulable 플래그가 남을 수 있음
→ GitHub Issue에서 실제 사례 확인 - 해결: kubectl uncordon <.node>
