이상현상이 뭘까요❓
이상 현상은 데이터베이스 설계에서 발생하는 비정상적인 동작이나 결과를 나타내는 용어입니다. 주로 데이터 베이스의 정규화 과정에서 발생하는 문제를 가르키는데, 이상현상에는삽입 이상,갱신 이상,삭제 이상이 포함 될 수 있습니다.
🔎 삽입 이상(Insertion Anomaly)에 대해서 설명해주세요
Insertion Anomaly란 새로운 데이터를 삽입할 때 발생하는 문제를 말합니다. 특정 행를 추가하려면 그 행에 연관된 다른 속성들도 함께 제공해야 하는데, 이것이 불가능하거나 부정확하면 데이터베이스에 삽입할 수 없게 됩니다.
🔎 갱신 이상(Update Anomaly)에 대해서 설명해주세요
Update Anomaly는 데이터의 중복으로 인해 발생하는 문제를 의미합니다. 데이터를 갱신할 때 중복된 값 중 일부만 갱신되어 데이터의 불일치가 발생할 수 있습니다.
🔎 삭제 이상(Delete Anomaly)에 대해서 설명해주세요
Delete Anomaly는 특정 데이터를 삭제할 때, 그 데이터와 관련된 다른 데이터도 함께 손실되는 현상을 말합니다. 예를들어, 특정 부서의 모든 직원이 퇴사하면 부서 정보도 함께 삭제되는 경우가 있습니다.
- 예시 1
| 학번 | 이름 | 전공 |
|---|---|---|
| 001 | 홍길동 | 컴퓨터 |
| 002 | 이순신 | 역사 |
| 003 | 강감찬 | 컴퓨터 |
- 예시 2
| 주문번호 | 고객명 | 제품명 |
|---|---|---|
| 001 | 홍길동 | 노트북 |
| 002 | 이순신 | 스마트폰 |
| 003 | 강감찬 | 노트북 |
🔎 함수 종속성이 무엇인가요?
함수 종속성은 한 테이블의 속성 A가 다른 속성 B에 종속되는 의존 관계를 나타냅니다. 예를 들어, 학생 테이블에서 학번이 주어지면 이름과 성적이 결정되는 경우, "학번 -> 이름, 성적"은 함수 종속성입니다.
🔎 완전 함수적 종속은 뭔가요?
완전 함수적 종속은 어떤 테이블의 모든 속성들이 기본 키(Primary Key)에 대해 완전하게 함수 종속적인 경우를 말합니다. 예를들어, 학생 테이블에서 학번이 주어지면 이름과 전공이 완전히 결정되는 경우,"학번 -> 이름, 학번 -> 성적"은 완전 함수적 종속입니다.
🔎 부분 함수적 종속은 뭔가요?
부분 함수적 종속은 기본 키(Primary Key)의 일부만에도 다른 속성이 함수 종속되는 경우를 의미합니다. 예를들어, 예시 2번에서 주문번호와, 제품명이 주어지면 고객명이 결정되는 경우, "주문번호, 제품명 -> 고객명"은 부분 함수적 종속입니다.
🔎 이행적 함수적 종속은 뭔가요?
이생적 함수적 종속은 A가 B에 함수 종속이고(A->B), B가 C에 함수 종속인 경우(B->C), A가 C에 이행적으로 함수 종속되는 상태를 말합니다. 예를 들어, 학생 테이블에서 "학번->이름"과 "이름->전공"이 주어졌을 때, "학번->전공"은 이행적 함수적 종속입니다. 즉, 학번을 통해 이름을 찾고 이름을 통해 정공을 찾을 수 있는 상태가 됩니다.
✅ 종속성을 이용하는 것에 대한 목적이 뭘까?
종속성을 이용하는 이유는 각 데이터베이스의 데이터의 속성 혹은 속성의 집합이 변경 될 때, 다른 속성 값에 영향을 미치는 종속관계에 대한데이터의 일관성 과 무결성을 유지하기 위함입니다. 이를 통해 데이터의 불일치나 이상 현상을 방지하고 데이터베이스의 정확성을 보장합니다.
- 이러한 데이터 무결성과 일관성을 유지하는데
정규화의 과정을 거치게 되는데 그 부분은 다음부터 알아보자
🔎 정규화(Normalization)에 대해서 설명해주세요
Normalization은 데이터베이스의 중복을 최소화하고 데이터의 일관성과 무결성을 유지하기 위한 프로세스입니다. 예를들어, 학생 정보를 담은 테이블을 보겠습니다.

| 학번 | 이름 | 과목 | 성적 |
|---|---|---|---|
| 001 | 홍길동 | 수학 | 90 |
| 001 | 홍길동 | 영어 | 85 |
| 002 | 이순신 | 수학 | 95 |
| 002 | 이순신 | 영어 | 88 |
이 경우, 학번과 이름이 학생을 식별하는 복합 기본키(Primary Key)입니다. 그러나 이름과 과목에 중복된 정보가 있습니다. 정규화는 이 중복을 최소화하는데 도움이 됩니다. 중복을 최소화하는 방법에서는
1NF,2NF,3NF등이 있습니다.
💡 What is the Normal form?
Normal Form은 데이터베이스 설계에서 중복을 최소화하고 데이터의 일관성과 무결성을 유지하기 위한 규칙의 집합니다. 즉,Data Anomaly현상을 제거하기 위한 관계형 모델의 설계 지침입니다.
- 각각의 정규형을 위해 만족해야 하는 규칙

1~3 정규형은 계층적이기 때문에 위의 조건을 만족해야 합니다. 예를 들어, 2정규형은 1정규형 조건 + 2정규형 조건을 만족해야 합니다.
🔎 1NF에 대해서 설명해주세요
1NF는 모든 속성 원자값(Atomic Value)으로 구성되는 상태입니다.(1정규형 조건) 즉, 각 셀의 값은 더이상 분해할 수 없는 단일 값이어야 합니다.
- 원자성을 만족하는 테이블
| 학번 | 과목 | 성적 |
|---|---|---|
| 001 | 수학 | 90 |
| 001 | 영어 | 85 |
| 002 | 수학 | 95 |
| 002 | 영어 | 88 |
- 원자성을 만족하지 않는 테이블
| 학번 | 과목 | 성적 |
|---|---|---|
| 001 | 수학, 영어 | 90, 85 |
| 002 | 수학, 영어 | 95, 88 |
🔎 2NF에 대해서 설명해주세요
1 정규화 조건을 만족하면서 부분 함수적 종속을 제거(Partial dependency)합니다. 기본 키(Primary Key)의 일부 속성이 기본 키 전체에 종속되어서는 안됩니다. 부분 함수적 종속이란, 두 속성에 의해 다른 한속성이 결정되는 경우를 부분 함수적 종속이라고 합니다.
- 2 정규형을 만족하는 테이블
| 학번 | 과목 | 성적 |
|---|---|---|
| 001 | 수학 | 90 |
| 001 | 영어 | 85 |
| 002 | 수학 | 95 |
| 002 | 영어 | 88 |
이 경우에는 일단 1 정규형 조건을 만족함을 알 수 있다. 그리고 각 컬럼 간의 관계를 살펴보면, (학번, 과목)-> 성적 이렇게 종속하는 관계 임을 알 수 있다. 이 두 기본키의 조합이 성적이라는 기본키가 아닌 속성에 종속되었기 때문에 완전 함수적 종속이라는 조건을 만족한다. 그래서 2NF의 조건을 만족하는 테이블이라고 할 수 있다.
- 2 정규형을 만족하지 않는 테이블
| 학번 | 이름 | 과목 | 성적 |
|---|---|---|---|
| 001 | 홍길동 | 수학 | 90 |
| 001 | 홍길동 | 영어 | 85 |
| 002 | 이순신 | 수학 | 95 |
| 002 | 이순신 | 영어 | 88 |
두번째 경우는, 1 정규형은 만족함을 알 수 있습니다. 종속 관계를 살펴보면, 성적이 이름에도 종속하지만 학점이라는 기본키에도 종속하는 것을 알 수 있습니다. 그렇기 때문에 부분 함수적 종속 을 가지고 있음을 알 수 있습니다.
- 만족하는 형태로의 변환한 테이블
| 학번 | 이름 |
|---|---|
| 001 | 홍길동 |
| 001 | 홍길동 |
| 002 | 이순신 |
| 002 | 이순신 |
| 학번 | 과목 | 성적 |
|---|---|---|
| 001 | 수학 | 90 |
| 001 | 영어 | 85 |
| 002 | 수학 | 95 |
| 002 | 영어 | 88 |
이렇게 두개의 테이블로 분리하여 보면 제 2 정규형을 만족하는 테이블을 갖추게 된다.
🔎 3NF에 대해서 설명해주세요
제 2 정규형을 만족하면서 이행적 함수적 종속을 제거합니다. 즉, 어떤 속성이 Primary Key가 아닌 다른 비기본 키 속성에 종속되어서는 안됩니다. 여기서
이행적 함수적 종속이란 A가 B 함수에 종속이고 B가 C함수에 종속일때 A가 C에 이행적으로 종속하는 것을 말합니다.
제 2 정규형을 설명할 때 사용한 예시를 다시 한번 이용하면 이행적 함수적 종속관계가 없으려면 A->B, B->C , A->C 이런 관계를 가지면 안되는데 해당 테이블에서는 학번이라는 기본키를 통해 성적을 결정 할 수 있으므로 제 3정규형에 부합하지 않는다.
🔎 BCNF(Boyce-Codd)에 대해서 설명해주세요
제 3 정규형을 만족하면서 모든 결정자가 후보 키 집합에 속하여야 합니다. 즉, 모든 결정자가 슈퍼키인 상태를 의미한다.BCNF는 간단하게 3차 정규화를 조금 더 강화한 버전이라고 생각할 수 있다.
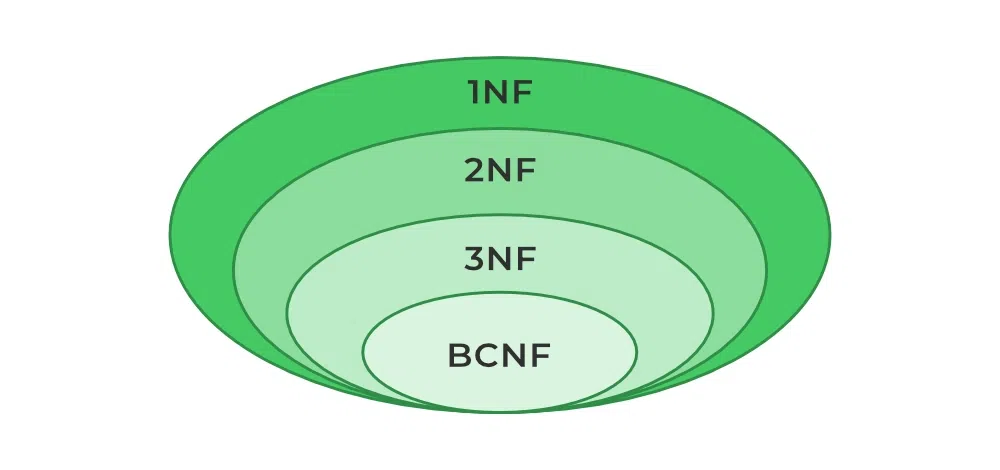
- 이렇게
제 3 정규형의 강화 버전이기에 모든 종속관계가 제거되어 후보키의 집합이어야 한다. 즉, 모든 결정자가 슈퍼키여야 한다.
🔎 De-Normalization에 대해서 설명해주세요
DE-NORMALIZATION은 성능 향상을 위해 NORMALIZATION된 데이터 모델을 다시 통합하는 과정입니다. 예를들어, 정규화된 과목 테이블과 교수 테이블이 존재 할때 과목 테이블에는 교수의 이름이 들어가 있지 않고 교수의 ID만이 존재하기 때문에 과목 테이블에 우리가 교수의 이름을 검색하면 나오지 않게 됩니다. 그래서 이때 두 테이블을 Join을 하게 되는데 이러한 과정을 반정규화라고 합니다.
- 반정규화의 장점
1. 조인 감소(쿼리 효율성 증가)
정규화는 데이터 중복을 최소화하기 위해 여러 테이블에 데이터를 분산시킵니다. 하지만 연관된 데이터를 처리하고 사용하기 위한 쿼리에서 조인 연산이 많이 발생 할 수 있습니다. 그러나 반정규화는 중복을 허용하므로 조인 연산을 줄일 수 있습니다.- 읽기 성능 향상
반정규화는 쓰기 성능을 희생하고 읽기 성능을 향상 시켜 불필요한 조인을 줄이고, 검색 속도를 향상 시킵니다. - 복잡성 감소
정규화된 구조는 복잡한 쿼리를 작성하는데 어려움을 줄 수 있는데, 이러한 어려움을 반정규화를 통해 쿼리 작성에 이점을 가질 수 있습니다. - 적절한 인덱스 활용
반정규화로 인해 테이블이 더 크고 넓어지더라도, 쿼리에서 자주 사용되는 데이터는 더 빠르게 검색할 수 있도록 인덱스를 효과적으로 활용 할 수 있습니다.
- 읽기 성능 향상
- 반정규화의 단점
1. 데이터 무결성 위협
중복이 많아지기 때문에 이로 인한 데이터 일관성을 지키기 힘들어져 오류가 발생할 가능성을 높일 수 있다.- 쓰기 작업의 복잡성 증가
이도 비슷한 맥락으로 중복이 증가하여 업데이트나 삭제를 할때 해당 데이터와 관련된 모든 테이블의 데이터를 업데이트, 삭제를 진행해야 하기 때문에 데이터 무결성을 지키기 힘들고 트랜젝션 관리에도 어려움이 있을 수 있습니다. - 데이터 일관성 위험
위와 같은 맥락이다. - 유지보수 어려움
데이터가 많아서 구조가 점점 복잡해지고 그로인해 유지보수가 복잡해집니다. 특히 데이터의 변경이 발생할 때 관련 모든 테이블을 업데이트 해야 합니다. - 조인의 감소로 인한 성능 저하
대량의 데이터를 다루게 될 경우에는 조인의 감소로 인한 성능 향상의 이점을 챙기지 못할 수 있습니다.
- 쓰기 작업의 복잡성 증가
References
1. Normalization info
2. BCNF
3. Geeks for Geek
4. Abonormaly examples
