이 모델도 시간이 꽤 지난 모델이고 이때부터 여러 LMM이 쏟아져 나오고있다...
예전에 해둔 리뷰를 지금에서야 여기에 옮겨 적는다...ㅠ
해당 모델을 연구한 경험으로 LLM, LMM 모델들을 사용하고 이해하는데 많은 도움이 되었었다...
LLaMA
이 모델의 시초인 LLaMA 부터 보자
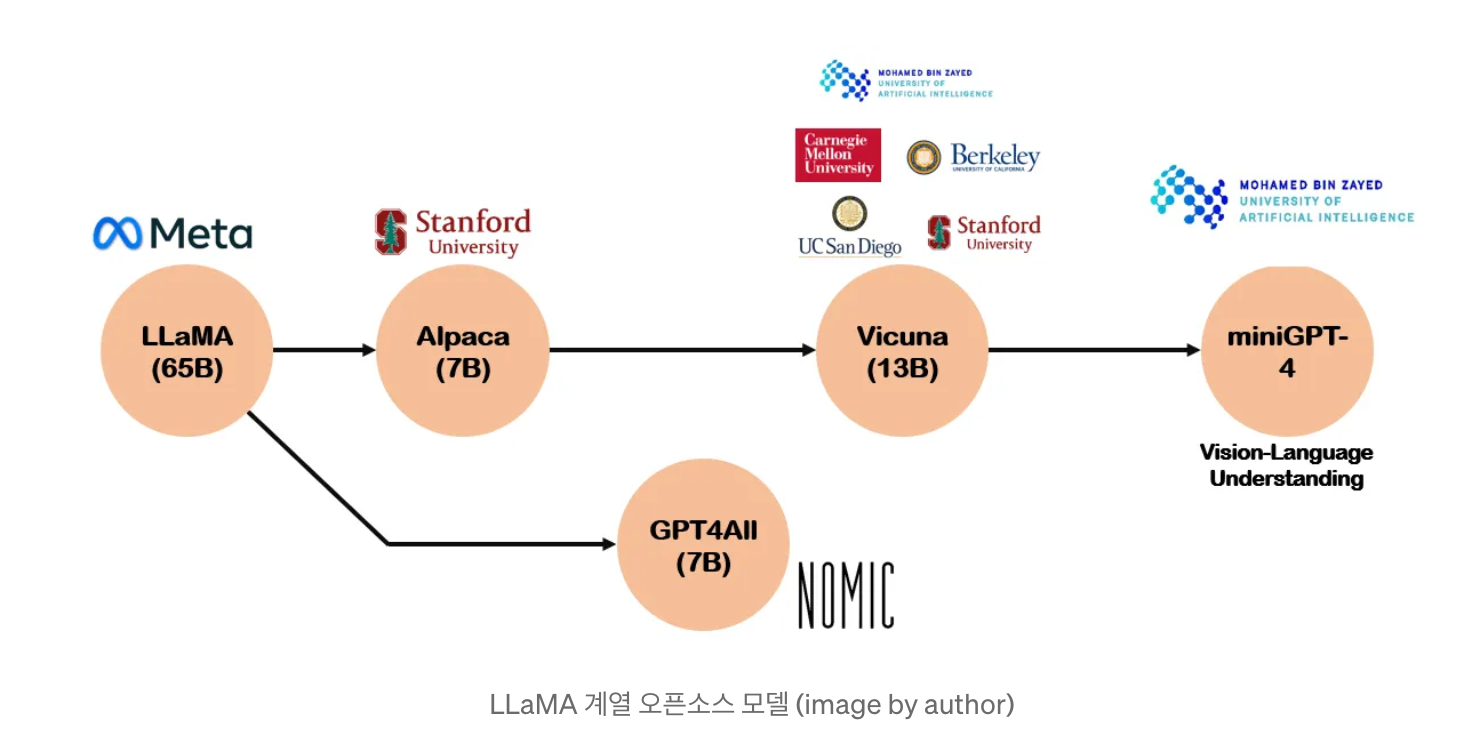
llama 계열의 발전 그래프
먼저 메타에서 llama를 오픈소스로 공개하였고, 이 모델을 바탕으로 오픈소스 LLM 이 발전한 계보가 있다.
초기 llava는 llama2 기반의 vicuna를 사용한다.
현재는 llama3 를 사용하는 llava 도 있고, meta 에서 공개한 llama3 자체 멀티모달모델도 있다
LLaVA (Visual Instruction Tuning)
LLaVA는 범용 시각 및 언어 이해를 위해 비전 인코더와 Vicuna를 결합한 새로운 엔드투엔드 훈련된 대규모 멀티모달 모델로, 멀티모달 GPT-4의 정신을 모방한 인상적인 채팅 기능을 달성하고 과학 QA에서 새로운 최첨단 정확도를 설정합니다.
- 저자가 강조하는 네가지
- Multimodal Instruct Data: We present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data.
- LLaVA Model: We introduce LLaVA (Large Language-and-Vision Assistant), an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.
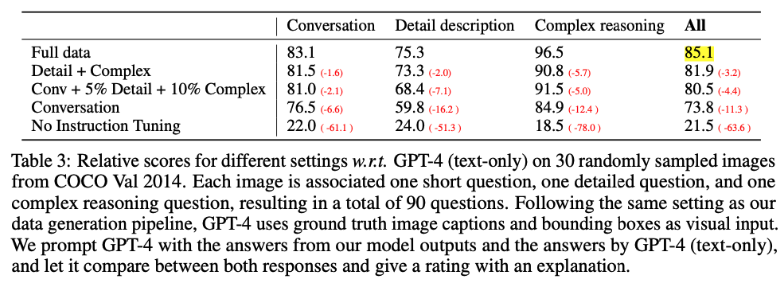
- Performance. Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%.
- Open-source. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.
요약
💡
1. 언어 전용 GPT-4를 사용하여 멀티모달 언어-이미지 명령어 팔로잉 데이터를 생성하는 첫 번째 시도를 소개합니다.
2. 비전인코더와 LLM을 연결하는 LLaVA 를 소개합니다
3. gpt4와 비슷한 성능
4. 우리는 GPT-4에서 생성된 시각적 명령 튜닝 데이터, 모델 및 코드 기반을 공개적으로 제공합니다.
데이터셋
158K 개의 유니크한 인스트럭션 데이터셋을 만들었다. 36.5%는 QA, 14.5%는 디테일한 설명, 49%는 컴플렉스 리즈닝 세트
liuhaotian/LLaVA-Instruct-150K · Datasets at Hugging Face
어떻게 만들었냐?
cc3m data 중 자기들이 균형잡힌 필터링으로 기초가 될 데이터를 만들었다함
cc3m data는 아래와 같은 구조를 가짐

이런식으로 질문형식을 만들어둔 후 아래와 같은 데이터형태를 만든다
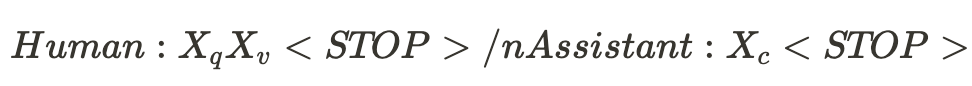
X_q는 위의 질문들, v는 이미지, c는 캡션
하지만 이 데이터셋의 문제는 다양성도 부족하고 깊은 대화와 resoning을 하지 못한다.

따라서, 저자는 위에있는 데이터형식을 참고하여 coco dataset으로 아래와 같은 데이터 형식을 만든다

# coco caption dataset
{
"id": "000000140289",
"image": "000000140289.jpg",
"captions": ["Two born bears walking though a forest surrounded by trees.", "Two full grown brown bears in a habitat.", "Two bears are roaming around in the woods.", "Two bears around logs in front of a large rock.", "Two big bears wandering through the woods together"],
"instances": [{"category": "bear", "bbox": [0.131, 0.269, 0.375, 0.65]}, {"category": "bear", "bbox": [0.568, 0.193, 0.809, 0.827]}]
}-
위에 데이터를 가지고 아래 세개의 형식의 프롬프트를 gpt 에 보내서 세가지 형태의 대화를 디자인한다.
보기쉽게 한국말로 해석한 예제이고, 대화 데이터의 예제를 가져왔으며, 깃헙에서 자세하게 확인이 가능하다
conversation
여러분은 인공지능 시각 도우미이며 하나의 이미지를 보고 있습니다. 현재 보고 있는 이미지와 동일한 이미지를 설명하는 다섯 개의 문장이 제공됩니다. 이미지를 보면서 모든 질문에 답하세요. 이 사진에 대해 질문하는 사람과 나 사이의 대화를 디자인합니다. 답변은 시각적 AI 비서가 이미지를 보고 질문에 답하는 듯한 어조로 작성해야 합니다. 다양한 질문을 하고 그에 맞는 답변을 제공하세요. 물체 유형, 물체 수 세기, 물체 동작, 물체 위치, 물체 간의 상대적 위치 등 이미지의 시각적 콘텐츠에 대해 묻는 질문을 포함하세요. 명확한 답이 있는 질문만 포함하세요: (1) 질문이 묻는 이미지의 내용을 볼 수 있고 자신 있게 대답할 수 있어야 합니다; (2) 이미지에 없는 것을 이미지에서 자신 있게 판단할 수 있는 경우. 자신 있게 대답할 수 없는 질문은 하지 마세요. 이미지 속 사물에 대한 배경 지식을 묻거나 이미지에서 일어난 사건에 대해 토론하도록 요청하는 등 이미지의 내용과 관련된 복잡한 질문도 포함하세요. 다시 말하지만, 불확실한 세부 사항에 대해서는 질문하지 마세요. 복잡한 질문에 답할 때는 자세한 답변을 제공하세요. 예를 들어, 자세한 예시나 추론 단계를 제시하여 내용을 더욱 설득력 있고 체계적으로 정리하세요. 필요한 경우 여러 단락을 포함할 수 있습니다.complex resoning
당신은 하나의 이미지를 분석할 수 있는 인공지능 시각 도우미입니다. 관찰 중인 동일한 이미지를 설명하는 다섯 개의 문장이 각각 주어집니다. 또한 이미지 내의 특정 물체 위치가 세부 좌표와 함께 제공됩니다. 이러한 좌표는 0에서 1 사이의 부동 소수점이 있는 (x1, y1, x2, y2)로 표시되는 경계 상자 형태입니다. 이 값은 왼쪽 위 x, 왼쪽 위 y, 오른쪽 아래 x, 오른쪽 아래 y에 해당합니다. 주어진 캡션과 바운딩 박스 정보를 사용하여 이미지에 대한 그럴듯한 질문을 만들고 그 답을 자세히 설명하는 것이 과제입니다. 장면을 설명하는 것 이상의 복잡한 질문을 만듭니다. 이러한 질문에 답하려면 먼저 시각적 콘텐츠를 이해한 다음, 배경 지식이나 추론을 바탕으로 왜 그런 일이 일어나는지 설명하거나 사용자의 요청에 따라 가이드와 도움말을 제공해야 합니다. 사용자가 먼저 추론해야 하는 시각적 콘텐츠의 세부 사항을 문제에 포함시키지 않음으로써 문제를 어렵게 만듭니다. 바운딩 박스 좌표를 직접 언급하는 대신 이 데이터를 활용하여 자연어를 사용하여 장면을 설명하세요. 객체 수, 객체의 위치, 객체 간의 상대적 위치와 같은 세부 정보를 포함하세요. 캡션과 좌표의 정보를 사용할 때는 장면을 직접 설명하고, 정보 출처가 캡션이나 경계 상자라는 사실을 언급하지 마세요. 항상 이미지를 직접 보고 있는 것처럼 답변하세요.detail description
당신은 하나의 이미지를 분석할 수 있는 인공지능 시각 도우미입니다. 관찰 중인 동일한 이미지를 설명하는 다섯 개의 문장이 각각 주어집니다. 또한 이미지 내의 특정 물체 위치가 세부 좌표와 함께 제공됩니다. 이러한 좌표는 0에서 1 사이의 부동 소수점이 있는 (x1, y1, x2, y2)로 표시되는 경계 상자 형태입니다. 이 값은 왼쪽 위 x, 왼쪽 위 y, 오른쪽 아래 x, 오른쪽 아래 y에 해당합니다. 제공된 캡션과 바운딩 박스 정보를 사용하여 장면을 자세히 설명합니다. 바운딩 박스 좌표를 직접 언급하는 대신 이 데이터를 활용하여 자연어를 사용하여 장면을 설명하세요. 객체 수, 객체의 위치, 객체 간의 상대적 위치와 같은 세부 정보를 포함하세요. 캡션과 좌표의 정보를 사용할 때는 장면을 직접 설명하고, 정보 출처가 캡션이나 경계 상자라는 사실을 언급하지 마세요. 항상 이미지를 직접 보고 있는 것처럼 답변하세요.
GPT4 를 거치는 데이터생성 파이프라인을 통하여 아래와 같은 대화 데이터가 디자인되어 만들어진다.
훈련
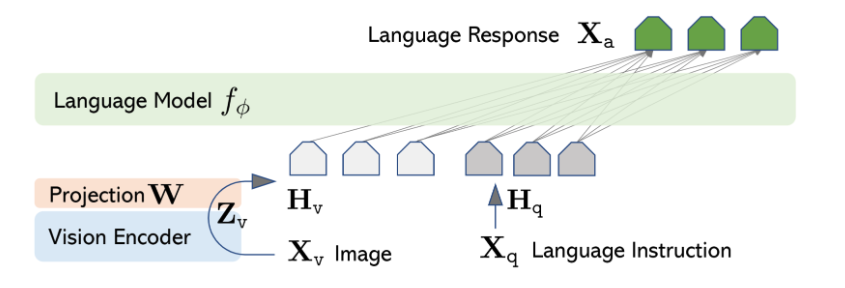
Vision Encoder: CLIP Vit-L/14
large language model: Vicuna
두가지 모델을 연결하여 사용하고, 이미지 피처를 워드 임베딩 스페이스와 연결하기 위해서 간단한 리니어 레이어를 도입했다.
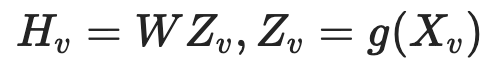
이미지를 비전 인코더에서 얻은 fetature 값을 LLM에 사용가능한 스페이스로 보낸다. → Sequence visual token이 된다. 저자는 <"image"> 토큰을 프롬프트 맨 앞이나 맨 뒤 적절하게 섞이게 만들었다.
모델은 두단계의 instruction-tuning을 거친다.
-
Pre-training for Feature Alignment
이 단계에서는 CC3M 데이터셋을 사용하는데 간단한 학습을 적용한다.(설명해줘-이미지-캡셔닝 이렇게만 이루어진)
visual encoder와 LLM의 가중치는 고정해둔다. 왜냐하면 이미지 피처 H_v가 LLM의 word embedding과 align될 수 있게 하는 것이 목표이기 때문.
오직 projection layer만 학습되며
LLM에 호환되는 visual tokenizer를 학습하는 과정이라고 볼 수 있다
-
End-to-End Fine-tuning
이 과정에서는 Visual Encoder 가중치는 고정해두고 LLM과 projection layer 두 모듈 학습한다
두 가지 시나리오 고려
- multimodal chatbot: coco를 사용하여 만든 instruction data 를 사용하여 만든 챗봇
- science QA: 각 질문에는 언어 혹은 이미지로 이루어진 context가 주어지고, 모델은 자연어로 추론 과정을 답하고 객관식에서 답을 선택하는 태스크
평가
저자는 이 모델의 평가를 GPT4를 활용하여 정량적 metric으로 측정하였다.
전에 만든 데이터 생성 파이프라인으로 COCO val 에서 random하게 30개의 이미지를 뽑은 후 세가지 형식의 대화를 생성해내고
LLaVA는 질문과 이미지를 기반으로 답변을 생성해낸다.
상대 모델인 GPT4는 bbox좌표와 캡션을 기반으로 예측을 생성한다
이렇게 두 모델로부터 얻은 두 응답을 GPT4에 다시 넣어준 후, 어시스턴트 응답의 유용성, 관련성, 정확성 및 세부 수준을 평가해 1~10 사이의 점수를 부여한다
현재는 llama3 를 사용하는 llava 도 있고, meta 에서 공개한 llama3 자체 멀티모달모델도 있다.
해당 모델을 바탕으로도 여러 튜닝 모델들이 쏟아져 나왔고, 지금까지도 이 모델을 사용한 경험을 바탕으로 최신 모델들을 리서치하고 잘 사용해보고있다
